Deformable DETR: Deformable Transformers for End-to-End Object Detection¶
1. 论文信息¶
标题:Deformable DETR: Deformable Transformers for End-to-End Object Detection
作者:Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai
原文链接:https://arxiv.org/abs/2010.04159
代码链接:https://github.com/ShoufaChen/DiffusionDet
2. 引言¶
现代object detector采用了许多handcraft的模块来达成相应的目的,例如anchor generation, rule-based training target assignment, non-maximum suppression这些后处理的方法。其实都是因为需要基于特征假设来生成一些proposal,来预测bounding box,所以以RCNN系列为代表的之前的目标检测方法其实都不完全是端到端的。
全新的DETR目的就是消除对这种手工提取的特征模块对于模块设计的限制,在我的理解里,这是第一次完成完全端到端的object detector。基于Transformers的端到端目标检测,没有NMS后处理步骤、真正的没有anchor,且对标超越Faster RCNN。他们利用Transformers的多功能和强大的关系建模能力,在适当设计的训练信号下,取代手工制作的特征选取规则。主要组成部分是基于集合的全局损失函数,该损失函数通过二分匹配和transformer编码器-解码器体系结构强制进行唯一的预测。给定一个固定的学习对象查询的小集合,DETR会考虑目标对象与全局图像上下文之间的关系,并直接并行输出最终的预测集合。虽然DETR第一次实现了几乎完全端到端的目标检测,但它也存在一些问题:
-
收敛速度较慢,训练持续时间长。由于训练过程中计算了目标可能存在的位置的统计与分配,需要进行全局的attention遍历,时间消耗较大。
-
由于DETR的全局注意力带来的高计算复杂度,导致其很难处理大分辨率图像,所以对于面积较小的物体,其检测性能较差。
其实这两者都是由于DETR采用了全局注意力,导致计算复杂度非常高。因此本文提供了一种很有趣的角度来解决这些问题。
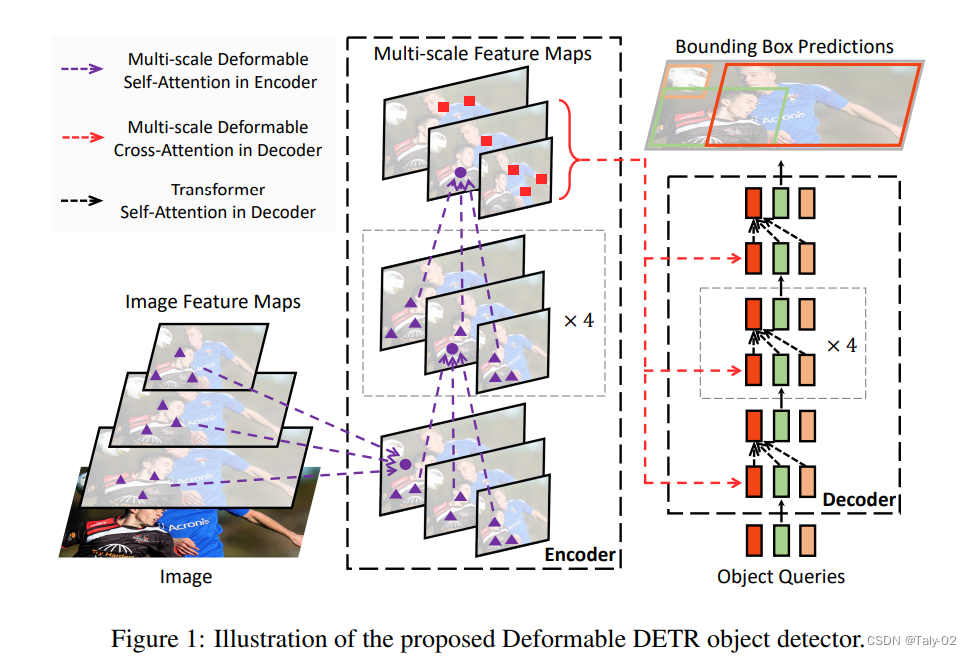
如上图所示,针对上述全局注意力带来的问题,本文提出的方法整体可以概括为:使用编码器输出的一些预测框来初始化解码器中的物体特征;使用多尺度特征和可变形卷积来细化检测框。其注意力模块只关注参考周围的一小组关键采样点。这样做的motivation在于:让encoder初始化的权重不再是统一分布,让其不必与所有的key都计算相似度,而是与更有意义的key计算相似度,而deformable convolution就是一种有效关注稀疏空间定位的方式;利用deformable DETR,融合deformable conv的稀疏空间采样与transformer相关性建模,从而在整体feature map的像素中,使得模型去关注小序列的采样位置,从而检测出小物体。
Deformable DETR可以实现比DETR更好的性能(特别是在小目标上),训练时间减少10倍。COCO基准的大量实验证明了算法的有效性。
3. 方法¶
首先回顾下标准的DETR计算attention的方法:

上式中 m 为端口,A 为 QK 的注意力图,计算复杂度是 Nq* Nk * C,复杂度正是来自于每个 Q 的 K 和 注意力图包含了所有位置。实际上全局注意力没有太有必要,因为注意力主要还是稀疏的,所以需要利用特殊的操作来避免这种过度计算带来的复杂度提升。这里,DCN的思想就显得非常有意义了:
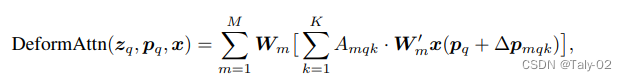
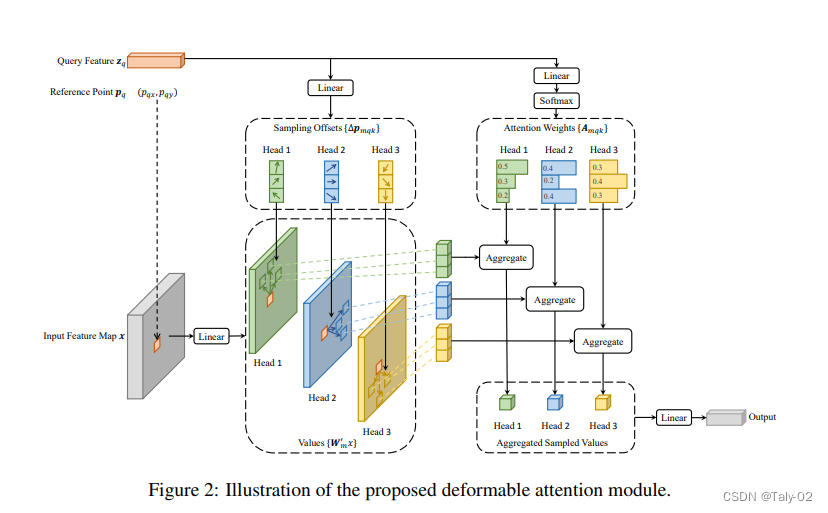
与MultiHeadAttn不同,k的取值有原先的整个集合具体为K个近邻点,那么最近邻点的位置怎么获得呢?那就是通过\delta p_{mqk}的学习,来得到可变行的地方。而再通过数据,进行softmax后得到注意力A_{mqk},其实思路还是比较直接的。
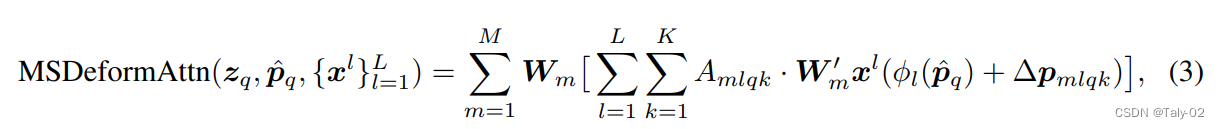
CNN重要的思想就是多尺度,获取不同感受野上不同层级的特征信息。所以本文提出的方法还采取了多尺度的形式,q 是多尺度图拼在一起的,而 K 则同时采样不同尺度的特征图。也就是在每张图像中选 4 个点,经过标准化后,将其置于 [0,1] 区间内。公式如上图所示。
4. Experiments¶
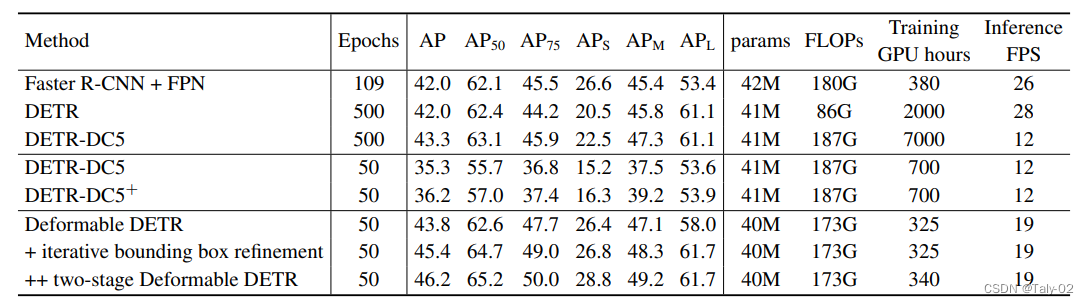
可以发现得益于可形变卷积避免全局attention,减少了运算量和进行多尺度融合使得方法具有处理不同分辨率的目标的能力,Deformable DETR较好地解决了上述提到的两个问题,带来了训练周期的大幅缩短以及对小目标精度的提升。另外还可以发现两个变种模型,性能提升都比较明显,表明先验知识其实有利于模型的精度,这应该是显然的,因为学习这种比较发散的统计规律精度还是没有专门给的先验好。
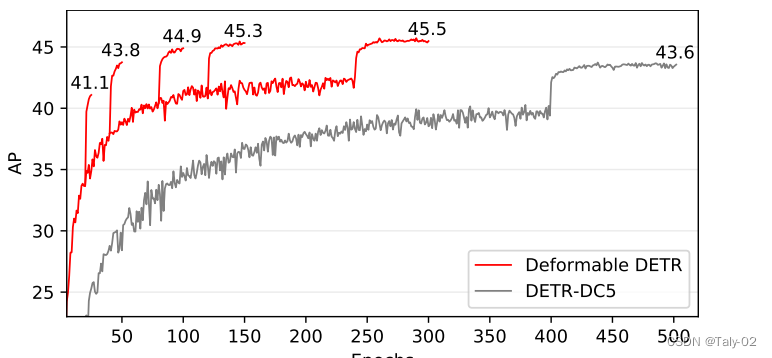
收敛速度来看也有也比较明显的改变。

为了研究Deformable-DETR在给出最终检测结果时所依据的是什么,论文绘制了最终预测中每个项目(即物体中心的x/y坐标、物体包围框的宽度/高度、该物体的类别评分)相对于图像中每个像素的梯度范数,如图5所示。根据泰勒定理,梯度范数可以反映输出相对于像素的摄动会发生多大的变化,从而可以告诉我们模型主要依靠哪些像素来预测每个项目。可视化结果表明,变形DETR通过观察对象的极端点来确定其边界框,这与DETR中的观察结果类似。更具体地说,Deformable-DETR关注对象的左/右边界(x坐标和宽度),上/下边界(y坐标和高度)。与此同时,与DETR不同的是,新的Deformable-DETR也会通过观察物体内部的像素来预测其类别。
5. Conclusion¶
本工作是对DETR的一种改进。重要的点包括:使用deformable cnn的思想实现local attention替代了全局的attention,这个模块感觉对于检测任务或者分割任务是比较有用的,但对于图像分类这种任务估计作用不是很大。另外就是multi-scale特征在encoder中通过deformable attention进行了融合,避免了FPN结构。当然本文还提出了一些更进一步的变种,比如迭代策略和两阶段策略。这两种策略的本质都是引入了更好的先验知识,所以性能能进一步的提升。由于这种训练时间的所见,使得DETR训练的门槛大大降低,非常有意义。
本文总阅读量次