自制深度学习推理框架-第7节-计算图中的表达式¶
什么是表达式¶
表达式就是一个计算过程,类似于如下:
output_mid = input1 + input2
output = output_mid * input3
用图形来表达就是这样的.
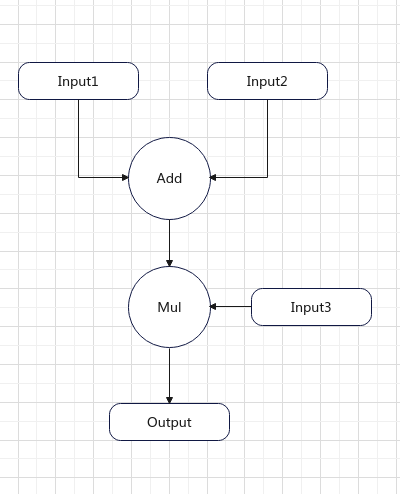
但是在PNNX的Expession Layer中给出的是一种抽象表达式,会对计算过程进行折叠,消除中间变量. 并且将具体的输入张量替换为抽象输入@0,@1等.对于上面的计算过程,PNNX生成的抽象表达式是这样的.
add(@0,mul(@1,@2)) 抽象的表达式重新变回到一个方便后端执行的计算过程(抽象语法树来表达,在推理的时候我们会把它转成逆波兰式)。
其中add和mul表示我们上一节中说到的RuntimeOperator, @0和@1表示我们上一节课中说道的RuntimeOperand. 这个抽象表达式看起来比较简单,但是实际上情况会非常复杂,我们给出一个复杂的例子:
add(add(mul(@0,@1),mul(@2,add(add(add(@0,@2),@3),@4))),@5)
这就要求我们需要一个鲁棒的表达式解析和语法树构建功能.
我们的工作¶
词法解析¶
词法解析的目的就是将add(@0,mul(@1,@2))拆分为多个token,token依次为add ( @0 , mul等.代码如下:
enum class TokenType {
TokenUnknown = -1,
TokenInputNumber = 0,
TokenComma = 1,
TokenAdd = 2,
TokenMul = 3,
TokenLeftBracket = 4,
TokenRightBracket = 5,
};
struct Token {
TokenType token_type = TokenType::TokenUnknown;
int32_t start_pos = 0; //词语开始的位置
int32_t end_pos = 0; // 词语结束的位置
Token(TokenType token_type, int32_t start_pos, int32_t end_pos): token_type(token_type), start_pos(start_pos), end_pos(end_pos) {
}
};
我们在TokenType中规定了Token的类型,类型有输入、加法、乘法以及左右括号等.Token类中记录了类型以及Token在字符串的起始和结束位置.
如下的代码是具体的解析过程,我们将输入存放在statement_中,首先是判断statement_是否为空, 随后删除表达式中的所有空格和制表符.
if (!need_retoken && !this->tokens_.empty()) {
return;
}
CHECK(!statement_.empty()) << "The input statement is empty!";
statement_.erase(std::remove_if(statement_.begin(), statement_.end(), [](char c) {
return std::isspace(c);
}), statement_.end());
CHECK(!statement_.empty()) << "The input statement is empty!";
下面的代码中,我们先遍历表达式输入
for (int32_t i = 0; i < statement_.size();) {
char c = statement_.at(i);
if (c == 'a') {
CHECK(i + 1 < statement_.size() && statement_.at(i + 1) == 'd')
<< "Parse add token failed, illegal character: " << c;
CHECK(i + 2 < statement_.size() && statement_.at(i + 2) == 'd')
<< "Parse add token failed, illegal character: " << c;
Token token(TokenType::TokenAdd, i, i + 3);
tokens_.push_back(token);
std::string token_operation = std::string(statement_.begin() + i, statement_.begin() + i + 3);
token_strs_.push_back(token_operation);
i = i + 3;
}
}
char c是当前的字符,当c等于字符a的时候,我们的词法规定在token中以a作为开始的情况只有add. 所以我们判断接下来的两个字符必须是d和 d.如果不是的话就报错,如果是i的话就初始化一个新的token并进行保存.
举个简单的例子只有可能是add,没有可能是axc之类的组合.
else if (c == 'm') {
CHECK(i + 1 < statement_.size() && statement_.at(i + 1) == 'u')
<< "Parse add token failed, illegal character: " << c;
CHECK(i + 2 < statement_.size() && statement_.at(i + 2) == 'l')
<< "Parse add token failed, illegal character: " << c;
Token token(TokenType::TokenMul, i, i + 3);
tokens_.push_back(token);
std::string token_operation = std::string(statement_.begin() + i, statement_.begin() + i + 3);
token_strs_.push_back(token_operation);
i = i + 3;
}
同理当c等于字符m的时候,我们的语法规定token中以m作为开始的情况只有mul. 所以我们判断接下来的两个字必须是u和l. 如果不是的话,就报错,是的话就初始化一个mul token进行保存.
} else if (c == '@') {
CHECK(i + 1 < statement_.size() && std::isdigit(statement_.at(i + 1)))
<< "Parse number token failed, illegal character: " << c;
int32_t j = i + 1;
for (; j < statement_.size(); ++j) {
if (!std::isdigit(statement_.at(j))) {
break;
}
}
Token token(TokenType::TokenInputNumber, i, j);
CHECK(token.start_pos < token.end_pos);
tokens_.push_back(token);
std::string token_input_number = std::string(statement_.begin() + i, statement_.begin() + j);
token_strs_.push_back(token_input_number);
i = j;
} else if (c == ',') {
Token token(TokenType::TokenComma, i, i + 1);
tokens_.push_back(token);
std::string token_comma = std::string(statement_.begin() + i, statement_.begin() + i + 1);
token_strs_.push_back(token_comma);
i += 1;
}
当输入为ant时候,我们对ant之后的所有数字进行读取,如果其之后不是操作数,则报错.当字符等于(或者,的时候就直接保存为对应的token,不需要对往后的字符进行探查, 直接保存为对应类型的Token.
语法解析¶
当得到token数组之后,我们对语法进行分析,并得到最终产物抽象语法树(不懂的请自己百度,这是编译原理中的概念).语法解析的过程是递归向下的,定义在Generate_函数中.
struct TokenNode {
int32_t num_index = -1;
std::shared_ptr<TokenNode> left = nullptr;
std::shared_ptr<TokenNode> right = nullptr;
TokenNode(int32_t num_index, std::shared_ptr<TokenNode> left, std::shared_ptr<TokenNode> right);
TokenNode() = default;
};
抽象语法树由一个二叉树组成,其中存储它的左子节点和右子节点以及对应的操作编号num_index. num_index为正, 则表明是输入的编号,例如@0,@1中的num_index依次为1和2. 如果num_index为负数则表明当前的节点是mul或者add等operator.
std::shared_ptr<TokenNode> ExpressionParser::Generate_(int32_t &index) {
CHECK(index < this->tokens_.size());
const auto current_token = this->tokens_.at(index);
CHECK(current_token.token_type == TokenType::TokenInputNumber
|| current_token.token_type == TokenType::TokenAdd || current_token.token_type == TokenType::TokenMul);
因为是一个递归函数,所以index指向token数组中的当前处理位置.current_token表示当前处理的token,它作为当前递归层的第一个Token, 必须是以下类型的一种.
TokenInputNumber = 0,
TokenAdd = 2,
TokenMul = 3,
如果当前token类型是输入数字类型, 则直接返回一个操作数token作为一个叶子节点,不再向下递归, 也就是在add(@0,@1)中的@0和@1,它们在前面的词法分析中被归类为TokenInputNumber类型.
if (current_token.token_type == TokenType::TokenInputNumber) {
uint32_t start_pos = current_token.start_pos + 1;
uint32_t end_pos = current_token.end_pos;
CHECK(end_pos > start_pos);
CHECK(end_pos <= this->statement_.length());
const std::string &str_number =
std::string(this->statement_.begin() + start_pos, this->statement_.begin() + end_pos);
return std::make_shared<TokenNode>(std::stoi(str_number), nullptr, nullptr);
}
else if (current_token.token_type == TokenType::TokenMul || current_token.token_type == TokenType::TokenAdd) {
std::shared_ptr<TokenNode> current_node = std::make_shared<TokenNode>();
current_node->num_index = -int(current_token.token_type);
index += 1;
CHECK(index < this->tokens_.size());
// 判断add之后是否有( left bracket
CHECK(this->tokens_.at(index).token_type == TokenType::TokenLeftBracket);
index += 1;
CHECK(index < this->tokens_.size());
const auto left_token = this->tokens_.at(index);
// 判断当前需要处理的left token是不是合法类型
if (left_token.token_type == TokenType::TokenInputNumber
|| left_token.token_type == TokenType::TokenAdd || left_token.token_type == TokenType::TokenMul) {
// (之后进行向下递归得到@0
current_node->left = Generate_(index);
} else {
LOG(FATAL) << "Unknown token type: " << int(left_token.token_type);
}
}
如果当前Token类型是mul或者add. 那么我们需要向下递归构建对应的左子节点和右子节点.
例如对于add(@1,@2),再遇到add之后,我们需要先判断是否存在left bracket, 然后再向下递归得到@1, 但是@1所代表的 数字类型,不会再继续向下递归.
当左子树构建完毕之后,我们将左子树连接到current_node的left指针中,随后我们开始构建右子树.此处描绘的过程体现在current_node->left = Generate_(index);中.
index += 1;
// 当前的index指向add(@1,@2)中的逗号
CHECK(index < this->tokens_.size());
// 判断是否是逗号
CHECK(this->tokens_.at(index).token_type == TokenType::TokenComma);
index += 1;
CHECK(index < this->tokens_.size());
// current_node->right = Generate_(index);构建右子树
const auto right_token = this->tokens_.at(index);
if (right_token.token_type == TokenType::TokenInputNumber
|| right_token.token_type == TokenType::TokenAdd || right_token.token_type == TokenType::TokenMul) {
current_node->right = Generate_(index);
} else {
LOG(FATAL) << "Unknown token type: " << int(left_token.token_type);
}
index += 1;
CHECK(index < this->tokens_.size());
CHECK(this->tokens_.at(index).token_type == TokenType::TokenRightBracket);
return current_node;
例如对于add(@1,@2),index当前指向逗号的位置,所以我们需要先判断是否存在comma, 随后开始构建右子树.右子树中的向下递归分析中得到了@2. 当右子树构建完毕后,我们将它(Generate_返回的节点,此处返回的是一个叶子节点,其中的数据是@2) 放到current_node的right指针中.
串联起来的例子¶
简单来说,我们复盘一下add(@0,@1)这个例子.输入到Generate_函数中, 是一个token数组.
- add
- (
- @0
- ,
- @1
- )
Generate_数组首先检查第一个输入是否为add,mul或者是input number中的一种.
CHECK(current_token.token_type == TokenType::TokenInputNumber||
current_token.token_type == TokenType::TokenAdd || current_token.token_type == TokenType::TokenMul);
第一个输入add,所以我们需要判断其后是否是left bracket来判断合法性, 如果合法则构建左子树.
else if (current_token.token_type == TokenType::TokenMul || current_token.token_type == TokenType::TokenAdd) {
std::shared_ptr<TokenNode> current_node = std::make_shared<TokenNode>();
current_node->num_index = -int(current_token.token_type);
index += 1;
CHECK(index < this->tokens_.size());
CHECK(this->tokens_.at(index).token_type == TokenType::TokenLeftBracket);
index += 1;
CHECK(index < this->tokens_.size());
const auto left_token = this->tokens_.at(index);
if (left_token.token_type == TokenType::TokenInputNumber
|| left_token.token_type == TokenType::TokenAdd || left_token.token_type == TokenType::TokenMul) {
current_node->left = Generate_(index);
}
处理下一个token, 构建左子树.
if (current_token.token_type == TokenType::TokenInputNumber) {
uint32_t start_pos = current_token.start_pos + 1;
uint32_t end_pos = current_token.end_pos;
CHECK(end_pos > start_pos);
CHECK(end_pos <= this->statement_.length());
const std::string &str_number =
std::string(this->statement_.begin() + start_pos, this->statement_.begin() + end_pos);
return std::make_shared<TokenNode>(std::stoi(str_number), nullptr, nullptr);
}
递归进入左子树后,判断是TokenType::TokenInputNumber则返回一个新的TokenNode到add token成为左子树.
检查下一个token是否为逗号,也就是在add(@0,@1)的@0是否为,
CHECK(this->tokens_.at(index).token_type == TokenType::TokenComma);
index += 1;
CHECK(index < this->tokens_.size());
下一步是构建add token的右子树
index += 1;
CHECK(index < this->tokens_.size());
const auto right_token = this->tokens_.at(index);
if (right_token.token_type == TokenType::TokenInputNumber
|| right_token.token_type == TokenType::TokenAdd || right_token.token_type == TokenType::TokenMul) {
current_node->right = Generate_(index);
} else {
LOG(FATAL) << "Unknown token type: " << int(left_token.token_type);
}
index += 1;
CHECK(index < this->tokens_.size());
CHECK(this->tokens_.at(index).token_type == TokenType::TokenRightBracket);
return current_node;
current_node->right = Generate_(index); /// 构建add(@0,@1)中的右子树
Generate_(index)递归进入后遇到的token是@1 token,因为是Input Number类型所在构造TokenNode后返回.
if (current_token.token_type == TokenType::TokenInputNumber) {
uint32_t start_pos = current_token.start_pos + 1;
uint32_t end_pos = current_token.end_pos;
CHECK(end_pos > start_pos);
CHECK(end_pos <= this->statement_.length());
const std::string &str_number =
std::string(this->statement_.begin() + start_pos, this->statement_.begin() + end_pos);
return std::make_shared<TokenNode>(std::stoi(str_number), nullptr, nullptr);
}
至此, add语句的抽象语法树构建完成.
struct TokenNode {
int32_t num_index = -1;
std::shared_ptr<TokenNode> left = nullptr;
std::shared_ptr<TokenNode> right = nullptr;
TokenNode(int32_t num_index, std::shared_ptr<TokenNode> left, std::shared_ptr<TokenNode> right);
TokenNode() = default;
};
在上述结构中, left存放的是@0表示的节点, right存放的是@1表示的节点.
一个复杂点的例子¶
我们提出这个例子是为了让同学更加透彻的理解Expression Layer, 我们举一个复杂点的例子:
add(mul(@0,@1),@2),我们将以人工分析的方式去还原词法和语法分析的过程.
例子中的词法分析¶
我们将以上的这个输入划分为多个token,多个token分别为
add | left bracket| |mul|left bracket|@0|comma|@1|right bracket| @2 |right bracket
例子中的语法分析¶
在ExpressionParser::Generate_函数对例子add(mul(@0,@1),@2),如下的列表为token 数组.
- add
- (
- mul
- (
- @0
- ,
- @1
- )
- ,
- @2
-
)
-
index = 0, 当前遇到的
token为add, 调用层为1 -
index = 1, 根据以上的流程,我们期待
add token之后的token为left bracket, 否则就报错. 调用层为1 -
开始递归调用,构建add的左子树.从层1进入层2
-
index = 2, 遇到了
mul token. 调用层为2. -
index = 3, 根据以上的流程,我们期待
mul token之后的token是第二个left bracket. 调用层为2. -
开始递归调用用来构建
mul token的左子树. -
index = 4, 遇到
@0,进入递归调用,进入层3, 但是因为操作数都是叶子节点,构建好之后就直接返回了,得到mul token的左子节点.放在mul token的left指针上. -
index = 5, 我们希望遇到一个逗号,否则就报错
mul(@0,@1)中中间的逗号.调用层为2. -
index = 6, 遇到
@2,进入递归调用,进入层3, 但是因为操作数是叶子节点, 构建好之后就直接返回到2,得到mul token的右子节点. -
index = 7, 我们希望遇到一个右括号,就是
mul(@1,@2)中的右括号.调用层为2. -
到现在为止
mul token已经构建完毕,返回形成add token的左子节点,add token的left指针指向构建完毕的mul树. 返回到调用层1....
-
add token开始构建right token,但是因为@2是一个输入操作数,所以直接递归就返回了,至此得到add的右子树,并用right指针指向.
所以构建好的抽象语法树如图:
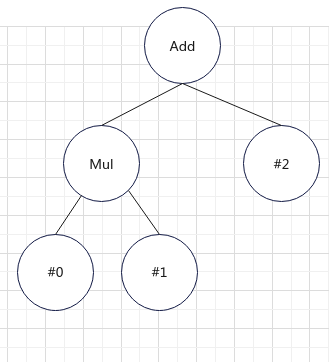 ¶
¶
实验部分¶
需要完成test/tet_expression.cpp下的expression3函数
TEST(test_expression, expression3) {
using namespace kuiper_infer;
const std::string &statement = "add(@0,div(@1,@2))";
ExpressionParser parser(statement);
const auto &node_tokens = parser.Generate();
ShowNodes(node_tokens);
}
static void ShowNodes(const std::shared_ptr<kuiper_infer::TokenNode> &node) {
if (!node) {
return;
}
ShowNodes(node->left);
if (node->num_index < 0) {
if (node->num_index == -int(kuiper_infer::TokenType::TokenAdd)) {
LOG(INFO) << "ADD";
} else if (node->num_index == -int(kuiper_infer::TokenType::TokenMul)) {
LOG(INFO) << "MUL";
}
} else {
LOG(INFO) << "NUM: " << node->num_index;
}
ShowNodes(node->right);
}
TEST(test_expression, expression1) {
using namespace kuiper_infer;
const std::string &statement = "add(mul(@0,@1),@2)";
ExpressionParser parser(statement);
const auto &node_tokens = parser.Generate();
ShowNodes(node_tokens);
}
最后会打印抽象语法树的中序遍历:
Could not create logging file: No such file or directory
COULD NOT CREATE A LOGGINGFILE 20230115-223854.21496!I20230115 22:38:54.863226 21496 test_main.cpp:13] Start test...
I20230115 22:38:54.863480 21496 test_expression.cpp:23] NUM: 0
I20230115 22:38:54.863488 21496 test_expression.cpp:20] MUL
I20230115 22:38:54.863492 21496 test_expression.cpp:23] NUM: 1
I20230115 22:38:54.863497 21496 test_expression.cpp:18] ADD
I20230115 22:38:54.863502 21496 test_expression.cpp:23] NUM: 2
如果语句是一个更复杂的表达式 add(mul(@0,@1),mul(@2,@3))
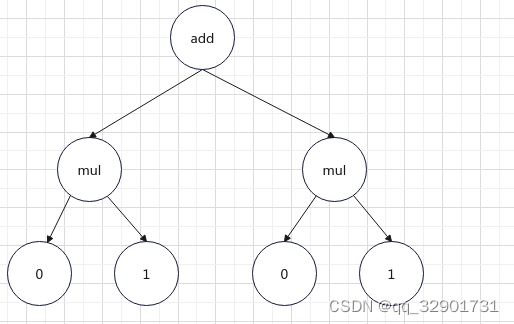
我们的单元测试输出为:
I20230115 22:48:22.086627 23767 test_expression.cpp:23] NUM: 0
I20230115 22:48:22.086635 23767 test_expression.cpp:20] MUL
I20230115 22:48:22.086639 23767 test_expression.cpp:23] NUM: 1
I20230115 22:48:22.086644 23767 test_expression.cpp:18] ADD
I20230115 22:48:22.086649 23767 test_expression.cpp:23] NUM: 2
I20230115 22:48:22.086653 23767 test_expression.cpp:20] MUL
I20230115 22:48:22.086658 23767 test_expression.cpp:23] NUM: 3
本文总阅读量次