前言¶
从这里开始,我会不定期的更新一些人脸识别的有趣算法和小demo算法,源码也会开放出来,自己在学习的过程中希望也能帮助到公众号中对这方面感兴趣的小伙伴,无论是从源码角度,还是从原理角度,我说清楚了,对在看的你有帮助就是我最大的幸福。
人脸识别的需要的数据集可以自己制作,也可以从网上免费下载。我这里选了人脸识别中入门级别的一个数据集ORL人脸库,不得不说,我是在CSDN下载的这个库,花了我7个金币来着。我把下载好的数据集放到百度网盘了,地址如下:https://pan.baidu.com/s/1lU8XJIcdiPE1thk7s5qP1Q 。这个数据库包含40个人的每人10张人脸,并且每张图片的大小是92\times 112,同时为了让算法更有趣,我采集一下自己的人脸做一个小demo出来。
制作数据集¶
通过摄像头采集我们自己的人脸,并将我们的人脸保存到F盘下面的ORL文件夹中,这个文件夹下已经保存了40个人的人脸,我们在这下面新建一个名字为zxy的文件夹,保存我们采集到的图片,只要10张就够了,ORL文件目录如下:
然后人脸识别的时候需要判断一张图像是不是人脸,opencv可以使用Harr特征的分类器或者LBP特征的分类器,我们这里使用Harr特征的人脸级联分类器,对应的xml格式的模型文件可以在opencv项目中找到,具体地址是 https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml。这里我下载下来放到F盘的一个文件夹里,后面要加载,文件目录结构为:
人脸采集的代码如下:
#coding=utf-8
# shutil的解释: os模块不仅提供了新建文件、删除文件、查看文件属性的操作功能,
# 还提供了对文件路径的操作功能。但是,对于移动、复制、打包、压缩、解压文件
# 及文件夹等操作,os模块没有提供相关的函数,此时需要用到shutil模块。shutil
# 模块是对os模块中文件操作的补充,是Python自带的关于文件、文件夹、压缩文件
# 的高层次的操作工具,类似于高级API。
import numpy as np
import cv2
import shutil
import os
# 生成自己的人脸数据
def generator(data):
name = input('Input Name: ')
# 如果路径存在则删除
path = os.path.join(data, name)
if os.path.isdir(path):
shutil.rmtree(path) #递归删除文件夹
# 创建文件
os.mkdir(path)
# 创建一个级联分类器,加载一个xml分类器文件,它既可以是Harr特征也可以是LBP特征的分类器
face_cascade = cv2.CascadeClassifier('F:\\face_recognize\\haarcascade_frontalface_default.xml')
# 打开摄像头
camera = cv2.VideoCapture(1)
cv2.namedWindow('Face')
# 计数
count = 1
while True:
# 读取一帧图像
ret, frame = camera.read()
# 判断图片是否读取成功
if ret:
gray_img = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#人脸检测
faces = face_cascade.detectMultiScale(gray_img, 1.3, 5)
for (x,y,w,h) in faces:
# 在原图像上绘制矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
# 调整图像大小 和ORL人脸库图像一样大小
f = cv2.resize(frame[y:y+h,x:x+w],(92,112))
# 保存人脸
cv2.imwrite('%s/%s.bmp'%(path,str(count)),f)
count += 1
cv2.imshow('Face', frame)
#如果按下q键则退出
if cv2.waitKey(100) & 0xff == ord('q') :
break
camera.release()
cv2.destroyAllWindows()
if __name__=='__main__':
data = 'F:\\ORL'
generator(data)
我采集了自己的10张人脸,放在F:\ORL目录下(人脸打了马赛克)。
人脸识别¶
OpenCV有3种人脸识别算法,Eigenfaces,Fisherfaces和Local Binary Pattern Histogram。这几个算法都需要对图像或视频中检测到的人脸进行分析,并在识别到人脸的情况下给出人脸类别的概率。我们在实际应用中可以通过卡阈值来完成最后的识别工作。这篇文章主要是介绍特征脸法,特征脸法,本质上其实就是PCA降维,这种算法的基本思路是,把二维的图像先灰度化,转化为一通道的图像,之后再把它首尾相接转化为一个列向量,假设图像大小是20*20的,那么这个向量就是400维,理论上讲组织成一个向量,就可以应用任何机器学习算法了,但是维度太高算法复杂度也会随之升高,所以需要使用PCA算法降维,然后使用简单排序或者KNN都可以。
准备数据¶
这里先准备训练需要的数据,这里我们需要的数据格式是将训练的图像,每个图像对应的标签,以及每个标签对应的真实姓名。不难写出如下数据加载函数:
# 读取
def LoadData(data):
# data表示训练数据集所在的目录,要求图片尺寸一致
# images:[m, height, width] 其中m代表样本个数,height代表图片高度,width代表宽度
# names: 名字的集合
# labels: 标签
images = []
labels = []
names = []
label = 0
#过滤所有的文件夹
for subDirname in os.listdir(data):
subjectPath = os.path.join(data,subDirname)
if os.path.isdir(subjectPath):
#每一个文件夹下存放着一个人的照片
names.append(subDirname)
for fileName in os.listdir(subjectPath):
imgPath = os.path.join(subjectPath,fileName)
img = cv2.imread(imgPath,cv2.IMREAD_GRAYSCALE)
images.append(img)
labels.append(label)
label += 1
images = np.asarray(images)
labels = np.asarray(labels)
return images,labels,names
构建人脸识别模型¶
就调用特征脸法开始拟合数据,然后人脸识别并打印到摄像头窗口上即可。代码如下:
def FaceRecognize():
#加载训练数据
X,y,names=LoadImages('F:\\ORL')
model = cv2.face.EigenFaceRecognizer_create()
model.train(X,y)
face_cascade = cv2.CascadeClassifier('F:\\face_recognize\\haarcascade_frontalface_default.xml')
#打开摄像头
camera = cv2.VideoCapture(1)
cv2.namedWindow('Face')
while(True):
# 读取一帧图像
ret,frame = camera.read()
#判断图片读取成功
if ret:
gray_img = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#人脸检测
faces = face_cascade.detectMultiScale(gray_img,1.3,5)
for (x,y,w,h) in faces:
#在原图像上绘制矩形
frame = cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray_img[y:y+h,x:x+w]
try:
#宽92 高112
roi_gray = cv2.resize(roi_gray,(92,112),interpolation=cv2.INTER_LINEAR)
params = model.predict(roi_gray)
print('Label:%s,confidence:%.2f'%(params[0],params[1]))
cv2.putText(frame,names[params[0]],(x,y-20),cv2.FONT_HERSHEY_SIMPLEX,1,255,2)
except:
continue
cv2.imshow('Face',frame)
#如果按下q键则退出
if cv2.waitKey(100) & 0xff == ord('q') :
break
camera.release()
cv2.destroyAllWindows()
注意这里运行可能会报错,提示AttributeError: module 'cv2.cv2' has no attribute 'Tracker_create'。这可能是因为你没有安装python opencv contriub模块。安装下就好了,安装命令如下:
pip3 install opencv-contrib-python
结果¶
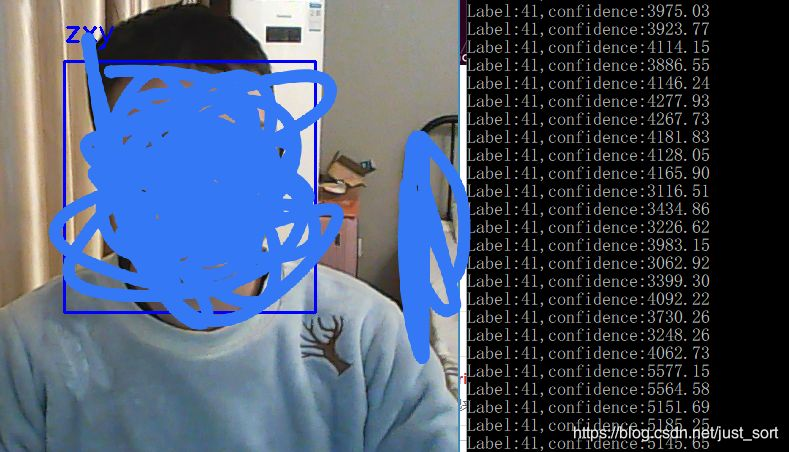
给自己人脸打了马赛克。
特征脸法原理¶
还记得我们前面讲的机器学习算法之PCA降维吗?特征脸法就是利用PCA算法。如果把我之前讲的那篇文章弄懂了,这都是不是事了。机器学习算法之PCA算法的讲解地址如下:https://mp.weixin.qq.com/s/2ZVneGPLF7a73JG-aVlH1g 。PCA算法的大致思路如下:
- 对图片进行预处理:将图片灰度化,调整到统一尺寸,进行光照归一化等。
- 将图片转换为一个向量:经过灰度化处理的图片是一个矩阵,将这个矩阵中的每一行连到一起,则可以变为一个向量,将该向量转换为列向量。
- 将数据集种的所有图片都转换为向量后,这些数据可以组成一个矩阵,在此基础上进行零均值化处理,就是将所有人脸在对应的维度求平均,得到一个平均脸(average face)向量\Phi,每一个人脸向量减去该向量,从而完成零均值化处理。
- 将经过零均值化处理的图像向量组合在一起,可以得到一个矩阵。通过该矩阵可以得到PCA算法中的协方差矩阵。
- 计算协方差矩阵的特征值和特征向量,每一个特征向量的维度与原始图像向量的维度是一致的,因此这些特征向量可以看成是一致的,因此这些特征向量就是所谓的特征脸。
上面描述的算法实际上就是我们的PCA算法,前面我们说过,这些图像的维度很大,这就造成执行PCA算法对协方差矩阵求特征向量时会很耗时。因此,在求特征向量时,特征脸法在PCA的基础上进行修改,不去对协方差矩阵求特征向量。在绝大多数情况下,图片的数量n远小于图片的维度m,故在PCA算法执行的过程中,起作用的只有m-1个,这个过程简要描述如下: 设协方差矩阵如下:
C=XX^T
其中X矩阵为经过零均值化后的由n张图片组成的矩阵,设原始图片向量的维度为m,则该矩阵为m行n列。显然PCA算法是对协方差矩阵C求特征向量,这个协方差矩阵是m行m列的方阵,其中m代表图像的像素点数量。这个维度是很高的。而实际上特征脸法是对下述矩阵求特征向量。
C'=X^TX
这个C'是n行n列的方阵,n代表图片数据的数量,由于这个数值远远小于m,故对该矩阵求特征向量的速度是快很多的。
特征脸法的复现代码如下(转自https://blog.csdn.net/freedom098/article/details/52088064):
#encoding=utf-8
import numpy as np
import cv2
import os
class EigenFace(object):
def __init__(self,threshold,dimNum,dsize):
self.threshold = threshold # 阈值暂未使用
self.dimNum = dimNum
self.dsize = dsize
def loadImg(self,fileName,dsize):
'''
载入图像,灰度化处理,统一尺寸,直方图均衡化
:param fileName: 图像文件名
:param dsize: 统一尺寸大小。元组形式
:return: 图像矩阵
'''
img = cv2.imread(fileName)
retImg = cv2.resize(img,dsize)
retImg = cv2.cvtColor(retImg,cv2.COLOR_RGB2GRAY)
retImg = cv2.equalizeHist(retImg)
# cv2.imshow('img',retImg)
# cv2.waitKey()
return retImg
def createImgMat(self,dirName):
'''
生成图像样本矩阵,组织形式为行为属性,列为样本
:param dirName: 包含训练数据集的图像文件夹路径
:return: 样本矩阵,标签矩阵
'''
dataMat = np.zeros((10,1))
label = []
for parent,dirnames,filenames in os.walk(dirName):
# print parent
# print dirnames
# print filenames
index = 0
for dirname in dirnames:
for subParent,subDirName,subFilenames in os.walk(parent+'/'+dirname):
for filename in subFilenames:
img = self.loadImg(subParent+'/'+filename,self.dsize)
tempImg = np.reshape(img,(-1,1))
if index == 0 :
dataMat = tempImg
else:
dataMat = np.column_stack((dataMat,tempImg))
label.append(subParent+'/'+filename)
index += 1
return dataMat,label
def PCA(self,dataMat,dimNum):
'''
PCA函数,用于数据降维
:param dataMat: 样本矩阵
:param dimNum: 降维后的目标维度
:return: 降维后的样本矩阵和变换矩阵
'''
# 均值化矩阵
meanMat = np.mat(np.mean(dataMat,1)).T
print '平均值矩阵维度',meanMat.shape
diffMat = dataMat-meanMat
# 求协方差矩阵,由于样本维度远远大于样本数目,所以不直接求协方差矩阵,采用下面的方法
covMat = (diffMat.T*diffMat)/float(diffMat.shape[1]) # 归一化
#covMat2 = np.cov(dataMat,bias=True)
#print '基本方法计算协方差矩阵为',covMat2
print '协方差矩阵维度',covMat.shape
eigVals, eigVects = np.linalg.eig(np.mat(covMat))
print '特征向量维度',eigVects.shape
print '特征值',eigVals
eigVects = diffMat*eigVects
eigValInd = np.argsort(eigVals)
eigValInd = eigValInd[::-1]
eigValInd = eigValInd[:dimNum] # 取出指定个数的前n大的特征值
print '选取的特征值',eigValInd
eigVects = eigVects/np.linalg.norm(eigVects,axis=0) #归一化特征向量
redEigVects = eigVects[:,eigValInd]
print '选取的特征向量',redEigVects.shape
print '均值矩阵维度',diffMat.shape
lowMat = redEigVects.T*diffMat
print '低维矩阵维度',lowMat.shape
return lowMat,redEigVects
def compare(self,dataMat,testImg,label):
'''
比较函数,这里只是用了最简单的欧氏距离比较,还可以使用KNN等方法,如需修改修改此处即可
:param dataMat: 样本矩阵
:param testImg: 测试图像矩阵,最原始形式
:param label: 标签矩阵
:return: 与测试图片最相近的图像文件名
'''
testImg = cv2.resize(testImg,self.dsize)
testImg = cv2.cvtColor(testImg,cv2.COLOR_RGB2GRAY)
testImg = np.reshape(testImg,(-1,1))
lowMat,redVects = self.PCA(dataMat,self.dimNum)
testImg = redVects.T*testImg
print '检测样本变换后的维度',testImg.shape
disList = []
testVec = np.reshape(testImg,(1,-1))
for sample in lowMat.T:
disList.append(np.linalg.norm(testVec-sample))
print disList
sortIndex = np.argsort(disList)
return label[sortIndex[0]]
def predict(self,dirName,testFileName):
'''
预测函数
:param dirName: 包含训练数据集的文件夹路径
:param testFileName: 测试图像文件名
:return: 预测结果
'''
testImg = cv2.imread(testFileName)
dataMat,label = self.createImgMat(dirName)
print '加载图片标签',label
ans = self.compare(dataMat,testImg,label)
return ans
if __name__ == '__main__':
eigenface = EigenFace(20,50,(50,50))
print eigenface.predict('d:/face','D:/face_test/1.bmp')
本文总阅读量次