论文:XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks 链接:https://arxiv.org/abs/1603.05279 代码:http://allenai.org/plato/xnornet
1. 前言¶
前面已经介绍了2篇低比特量化的相关文章,分别为:基于Pytorch构建一个可训练的BNN 以及 基于Pytorch构建三值化网络TWN 。在讲解那2篇文章的时候可能读者会发现某些小的知识点出现的比较突兀,今天要介绍的这一篇论文可以看做对前两篇文章的理论部分进行查漏补缺。
2. 概述¶
这篇论文中提出了两种二值化网络Binary-Weight-Networks和XNOR-Networks 。BNN在前些日子讲过了,今天再回顾一下然后和XNOR-Networks做一个对比。下面的Figure1展示了这两种网络和标准CNN的差别,这里使用的是AlexNet作为基础网络。
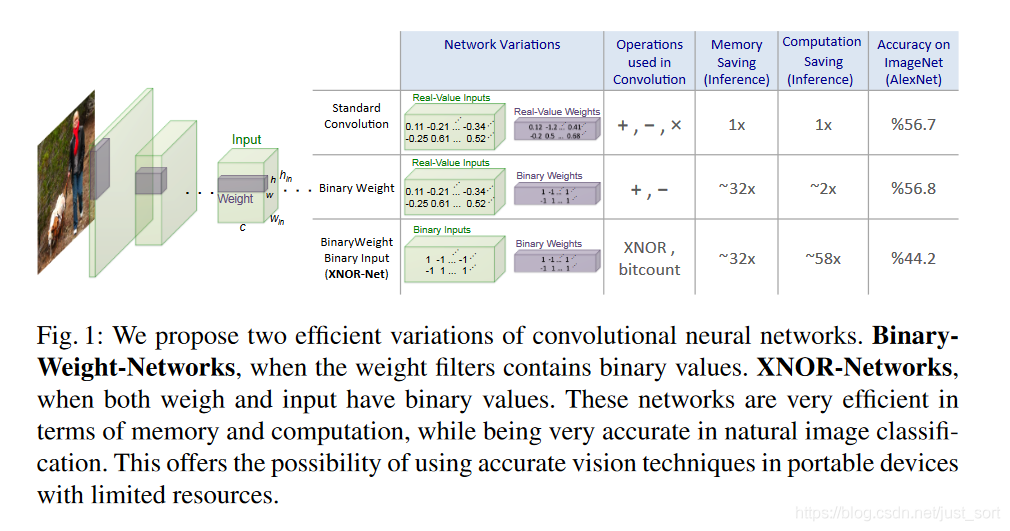 BNN是通过对权重W做二值化操作来达到减小模型存储空间的目的,准确率影响并不明显(56.7%->56.8%,但从实验部分ResNet18上的结果来看影响还是比较大的)。而XNOR-Networks对权重W和激活值I 同时做了二值化,既可以减少模型存储空间,又可以加速模型,但是准确率降了很多。
BNN是通过对权重W做二值化操作来达到减小模型存储空间的目的,准确率影响并不明显(56.7%->56.8%,但从实验部分ResNet18上的结果来看影响还是比较大的)。而XNOR-Networks对权重W和激活值I 同时做了二值化,既可以减少模型存储空间,又可以加速模型,但是准确率降了很多。
本文介绍的这两种网络里面提到的权重指的是卷积层的权重或者全连接层的权重,由于全连接可以用1\times 1卷积代替,所以这里统一认为是卷积层的权重。
3. Binary-Weight-Networks¶
Binary-Weight-Networks的目的是将权重W的值都用二值来表示,也即是说W的值要么为-1,要么为1。在网络的前向传播和反向传播中一直遵循这个规则,只不过在参数更新的时候还是使用原来的权重W,因为更新参数需要更高的精度(位宽,例如float就是32位)。
下面来看一下论文的公式推导过程以及如何实现权重的二值化,首先约定卷积层的操作可以用I*W来表示,其中I表示输入,维度是c\times w_{in}\times h_{in},其中W表示卷积核的权重,维度是c\times w\times h。那么当使用二值卷积核B乘以一个尺度参数\alpha代替原来的卷积核W,就可以获得下面的等式:
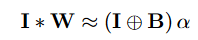
中间那个圆圈带加号的符号表示没有乘积的卷积运算,这里W \approx \alpha B
注意,这里的\alpha默认是个正数,\alpha和B是相对的,因为如果\alpha和B都取相反数它们的乘积是不变的。
现在希望用一个尺度参数\alpha和二值矩阵B来代替原来的权重W,那么我们肯定想前者尽可能的等于后者,因此就有了下面的优化目标函数:
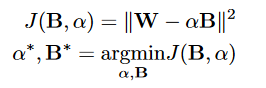
我们的目的是让这个J越小越好,这种情况的下\alpha和B就是我们需要的值,另外这里将矩阵W和B变换成了向量,也即是说W和B的维度都是1*n,其中n=c*w*h。
接下来,我们的目的就是求出\alpha和B的最优值,使其满足上面的优化目标。我们可以将上面的优化函数展开,写成下面的形式:
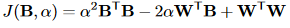
因为B是一个1*n的向量,里面的值要么是-1,要么是1,因此:
B^TB=n
即一个常量。并且W是已知的,所以:W^T*W仍然是一个常量。另外,\alpha是一个正数,这些常量在优化函数中都可以去掉,不影响优化的最终结果。就可以得到B的最优值的计算公式:
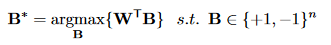
显然,根据这个式子,B的最优值就是W的符号。即:
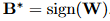
也就是说,当W中某个位置的值是正数时,B中对应位置的值就是+1,反之为-1。(这不就是之前我们将基于Pytorch构建BNN中使用的基本原理吗)
知道了B的最优值之后,接下来就可以求\alpha的最优值。我们使用上面第二个J函数表达式对\alpha求导,并让导数等于0,从而获得最优值,等式如下:
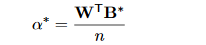
然后将前面获取到的B^*带入上面的等式,就可以获得下面这个求\alpha最优值的最终式子:
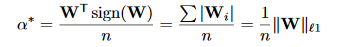
也就是说\alpha的最优值是W的每个元素的绝对值之和的均值,其中 || || 表示L1范数。
最后Binary-Weight-Networks 算法可以总结如下:
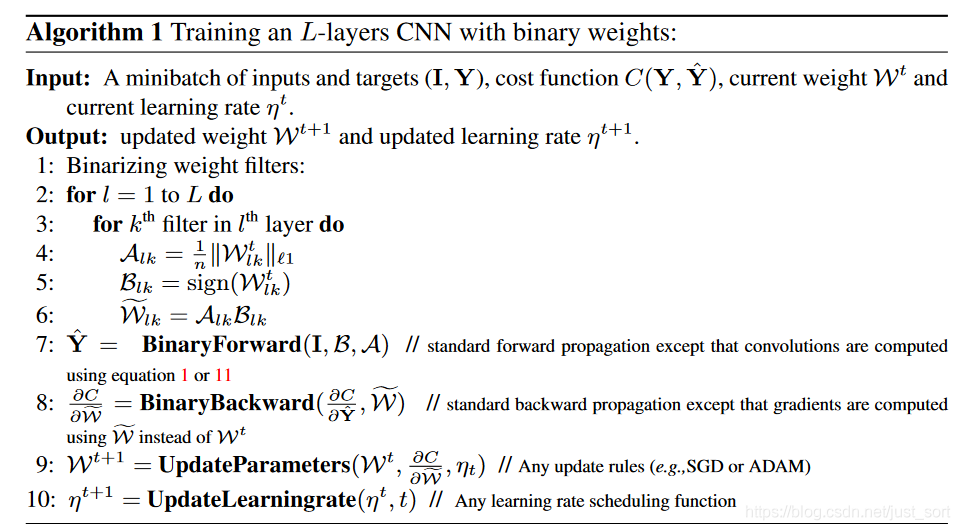
第一个for循环是遍历所有的层,第二个for循环是遍历某一层的所有卷积核。通过获得A_{lk}和B_{lk}就可以近似等于原始的权重W_{lk}了,另外在backward过程中的梯度计算也是基于二值权重。
4. XNOR-Networks¶
前面的BNN只是将权重W的值用二值表示,而下面要引入的XNOR-Networks不仅将权重W用二值表示,并且也将输入用二值表示。XNOR即同或门,假设输入是0或1,那么当两个输入相同时输出为1,当两个输入不同时输出为0。
然后我们知道卷积就是使用卷积核去点乘输入的某个区域获得最后的特征值,这里假设输入为X,卷积核是W,那么我们就希望得到\beta,H,\alpha,B使得下式成立:
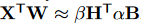
即用\beta H近似输入X,另外:
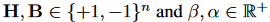
然后就有了下面这个优化等式:
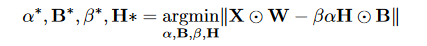
其中圆圈里面带一个点的符号代表element-wise product,即点乘运算。如果用Y代替XW,C代替HB,\gamma=\beta \alpha,那么优化等式可以重写为:
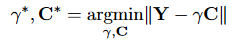
然后这个式子和第三节的优化等式形式类似,即:
因此可以利用Binary-Weight-Networks的推导结果来解这个优化式子。根据前面\alpha和B的计算公式,可以得到C和\gamma的计算公式:
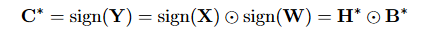
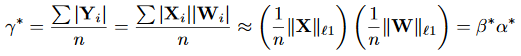
这里因为|X_i|和|W_i|是相互独立的,所以 可以直接拆开。
上面两个等式右边的结果就是4个参数的最优解。
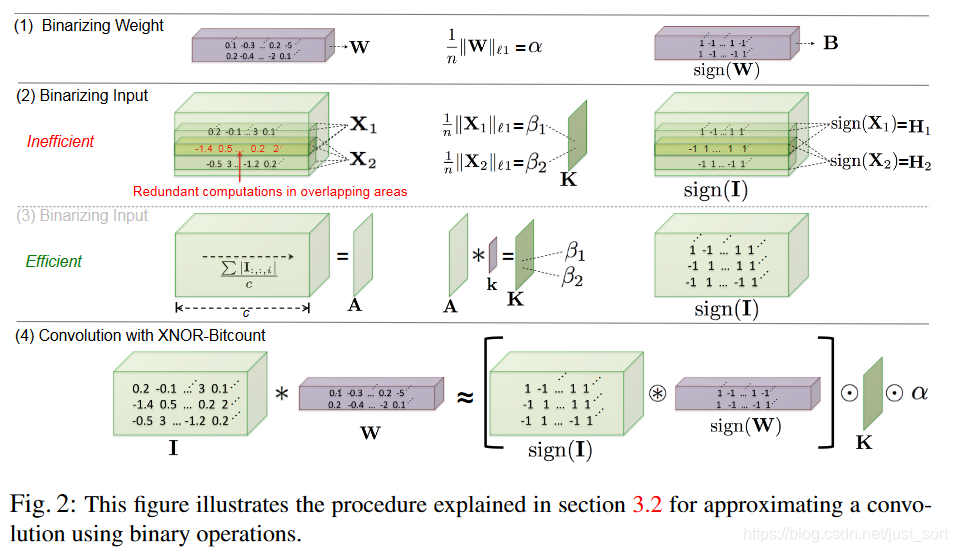
下面的Figure2展示了具体的二值化操作。第一行即是Binary-Weight-Networks的最优值求解。第二行是XNOR-Networks的最优值求解,不过由于存在重复计算,所以采用第三行的方式,其中c表示通道数,A表示通过对输入I求均值得到的。第四行和第三行的含义一样,更加完整的表达XNOR-Net的计算过程,这里K就是第三行计算得到的K,中括号里面的内容就是最优的C即C^*。
然后第四行里面的*符号代表的是convolutional opration using XNOR and bitcount operation。即如果两个二值矩阵之间的点乘可以将点乘换成XNOR-Bitcounting操作,将32位float数之间的操作变成1位的XNOR门操作,这就是加速的核心点。
下面的Figure3右侧展示了添加XNOR量化方法后的网络结构:

5. 实验结果¶
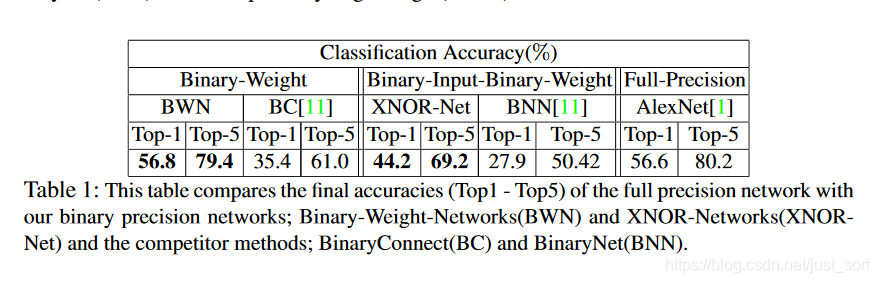
下面的Table1是上面两种二值化方式和同期其它的二值化方式的对比结果,其中Full-Precision是不经过二值化的模型准确率。
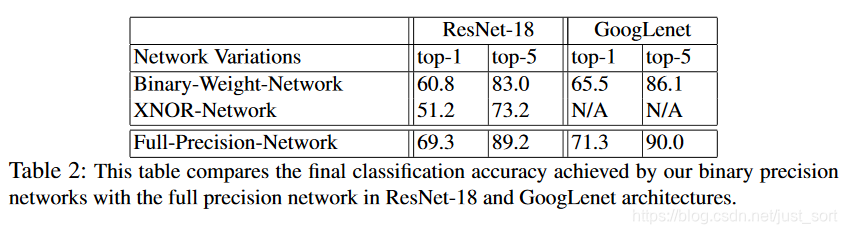
然后下面还提供了本文的两种二值化方式和正常的ResNet-18的准确率对比,可以看出在ResNet18上Binary-Weight-Networks对准确率的影响更大 (和AlexNet相比)。这个原因大概是因为ResNet的残差结构导致的。
6. 总结¶
本文从理论角度提出了两种二值化方法,即BWN和XNOR-Net,背后的理论推导相对是比较简单的,但没看这篇文章去理解之前已经发过的几篇文章是相对困难的,所以希望这篇文章会给对低比特量化感兴趣的读者带来帮助。同时,从实验结果仍然可以看到BNN要落地还是有一大段路(准确率掉得厉害),笔者暂时也了解不多,后面学习一些更solid的方法也会及时在公众号更新。
最后再提一句,看完这篇文章详细读者都知道为什么之前构建BNN的时候使用根据符号来进行二值化了的吧,个人认为任何一算法背后的理论支撑都是不可或缺的。
7. 参考¶
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次