0x0. 前言¶
接着【BBuf的CUDA笔记】十三,OpenAI Triton 入门笔记一 继续探索和学习OpenAI Triton。这篇文章来探索使用Triton写LayerNorm/RMSNorm kernel的细节。
之前在 【BBuf的CUDA笔记】十二,LayerNorm/RMSNorm的重计算实现 这篇文章我啃过Apex的LayerNorm实现,整个实现过程是非常复杂的,不仅仅需要手动管理Block内的共享内存,而且在每一行的具体计算时还需要以warp为视角做warp间和warp内的reduce以获得全局的均值和方差。如果没有十足的cuda开发经验是很难完成这个工作的,但Triton的出现让不熟悉cuda的人也有了做这件事情的机会,至于用Triton 来写LayerNorm kernel的难度如何,Triton实现出来的LayerNorm kernel性能相比于apex/PyTorch的实现如何,这都是本文将会讨论到的问题。
需要指出,本文解析的Triton LayerNorm kernel来自FlashAttention2仓库中的实现:https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/ops/triton/layer_norm.py 。相比于Triton LayerNorm kernel官方教程的实现:https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html ,这里的backward pass有一些区别,每个Block负责连续几行的dx,dw,db梯度累加,而不是像官方教程那样跨越不连续的行做计算和累加,整体的实现会更简单。
0x1. 性能对比¶
这里模拟一下大模型中输入给LayerNorm/RMSNorm的Tensor,假设输入Tensor的shape是[batch, seq_length, hidden_size],我这里固定batch=128,seq_length=1024,然后遍历一系列的hidden_size并在hidden_size维度做LayerNorm操作。我写了一个脚本用Triton的Benchmark框架来对比各种hidden_size下的PyTorch LayerNorm,Apex Efficient/Non Efficient,Triton LayerNorm kernel(https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/ops/triton/layer_norm.py)的性能。为了更好的模拟训练场景,我让LayerNorm做了前向之后也做一次反向计算,具体Benchmark结果图如下:
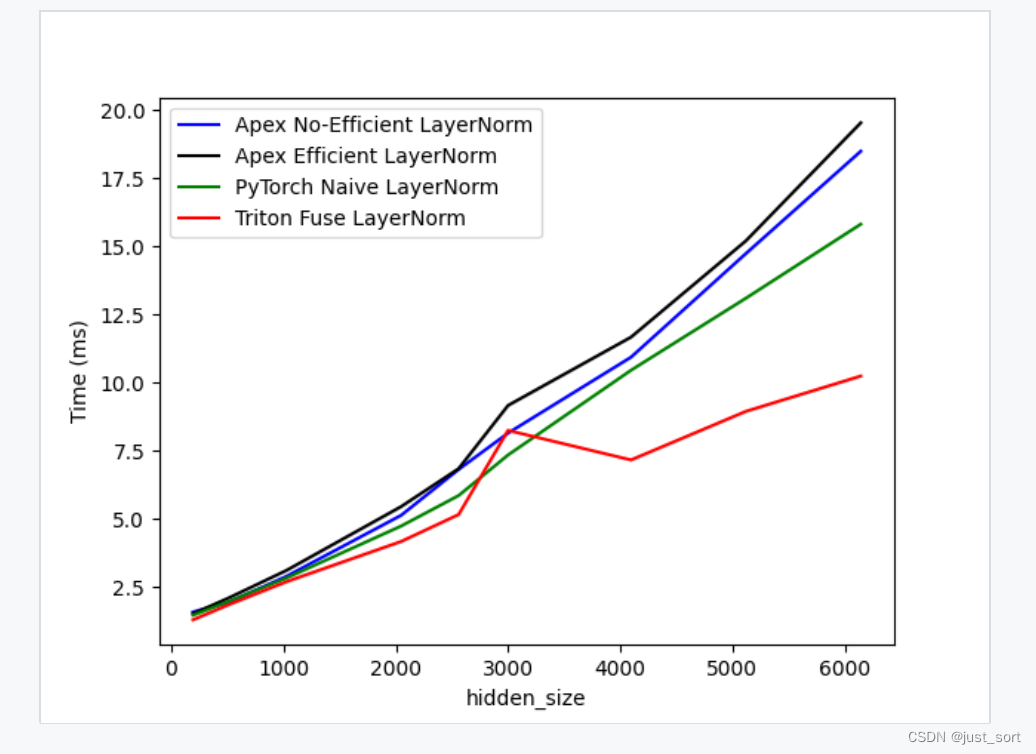 基准测试的代码我放在了这里:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/triton/benchmark_layernorm.py
基准测试的代码我放在了这里:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/triton/benchmark_layernorm.py
可以看到在这种情况下,对于几乎所有的hidden_size,Triton的LayerNorm kernel端到端耗时相比于Apex的版本都是持平或者有优势,另外值得注意的是这种情况下的PyTorch的LayerNorm的性能似乎已经比Apex的LayerNorm的性能更好了,当然这个也并不奇怪因为我使用的是最新的PyTorch release版本进行测试,而PyTorch已经参考着Apex把LayerNorm的性能优化得很好了。例如这个pr:https://github.com/pytorch/pytorch/pull/67977 就是率先引入了基于apex的优化方法并做了近一步优化:
 然后当我们把目光转到Triton的时候,发现在大多数情况下它的性能都不比PyTorch差,只在
然后当我们把目光转到Triton的时候,发现在大多数情况下它的性能都不比PyTorch差,只在hidden_size=3000附近会比PyTorch差一些,而随着hidden_size的增大Triton实现的LayerNorm kernel性能则具有更大的性能优势。
0x2. Triton LayerNorm kernel实现解析¶
下面对Triton的LayerNorm kernel实现进行解析:https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/ops/triton/layer_norm.py 。本文所有的代码解析都可以在 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/triton/layernorm.py 这里找到。
layer_norm_ref 函数解析¶
flash attention库里的Triton LayerNorm实现中有一个layer_norm_ref函数: https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/ops/triton/layer_norm.py#L19C5-L71 ,是一个naive的参考实现,我们先解析一下这个函数。
# x: 输入张量。
# weight, bias: LayerNorm时使用的可学习参数。
# residual: 可选的残差输入,如果提供,会在LayerNorm后与输出相加。
# x1, weight1, bias1: 第二路径的输入和对应的可学习参数,用于并行LayerNorm。
# eps: 用于LayerNorm的数值稳定性常数。
# dropout_p: Dropout概率。
# rowscale: 可选的行缩放因子。
# prenorm: 一个布尔值,指示是否在返回值中包括原始LayerNorm输入。
# dropout_mask, dropout_mask1: 可选的dropout掩码,用于指定哪些元素应当被置零。
# upcast: 布尔值,指示是否将输入和参数转换为浮点数(float)进行计算。
def layer_norm_ref(
x,
weight,
bias,
residual=None,
x1=None,
weight1=None,
bias1=None,
eps=1e-6,
dropout_p=0.0,
rowscale=None,
prenorm=False,
dropout_mask=None,
dropout_mask1=None,
upcast=False,
):
# 如果upcast为True,则将输入x、weight、bias及可选的residual、x1、weight1、bias1转换为float类型。
dtype = x.dtype
if upcast:
x = x.float()
weight = weight.float()
bias = bias.float() if bias is not None else None
residual = residual.float() if residual is not None else residual
x1 = x1.float() if x1 is not None else None
weight1 = weight1.float() if weight1 is not None else None
bias1 = bias1.float() if bias1 is not None else None
# 如果rowscale不为None,则对输入x进行行缩放。
if x1 is not None:
assert rowscale is None, "rowscale is not supported with parallel LayerNorm"
if rowscale is not None:
x = x * rowscale[..., None]
# 如果dropout_p大于0,根据提供的dropout_mask(如果有)或使用F.dropout对x(和x1,如果存在)应用dropout。
if dropout_p > 0.0:
if dropout_mask is not None:
x = x.masked_fill(~dropout_mask, 0.0) / (1.0 - dropout_p)
else:
x = F.dropout(x, p=dropout_p)
if x1 is not None:
if dropout_mask1 is not None:
x1 = x1.masked_fill(~dropout_mask1, 0.0) / (1.0 - dropout_p)
else:
x1 = F.dropout(x1, p=dropout_p)
# 如果x1不为None,将其与x相加。
if x1 is not None:
x = x + x1
# 如果提供了残差residual,将其添加到x上。
if residual is not None:
x = (x + residual).to(x.dtype)
# 对调整后的x执行LayerNorm,使用weight和bias作为参数。
out = F.layer_norm(x.to(weight.dtype), x.shape[-1:], weight=weight, bias=bias, eps=eps).to(
dtype
)
# 如果提供了weight1,对x执行第二次LayerNorm,使用weight1和bias1作为参数。
if weight1 is None:
return out if not prenorm else (out, x)
else:
# 根据prenorm标志和是否有第二路径的参数,函数可能返回不同的值组合:
# 如果没有第二路径参数,返回归一化的输出。
# 如果有第二路径参数,返回两个归一化输出。
# 如果prenorm为True,还会返回未归一化的x。
out1 = F.layer_norm(
x.to(weight1.dtype), x.shape[-1:], weight=weight1, bias=bias1, eps=eps
).to(dtype)
return (out, out1) if not prenorm else (out, out1, x)
这个函数是基于PyTorch提供的LayerNorm来实现了一个标准的layernorm接口,只不过相比于纯粹的LayerNorm还考虑到了常和它结合的dropout,残差连接等。
_layer_norm_fwd_1pass_kernel 函数解析¶
# @triton.autotune:自动调整装饰器,用于自动找到最佳配置(如num_warps)以优化性能。
# 这里配置了多个候选的配置,每个配置指定了不同数量的num_warps。
@triton.autotune(
configs=[
triton.Config({}, num_warps=1),
triton.Config({}, num_warps=2),
triton.Config({}, num_warps=4),
triton.Config({}, num_warps=8),
triton.Config({}, num_warps=16),
triton.Config({}, num_warps=32),
],
key=["N", "HAS_RESIDUAL", "STORE_RESIDUAL_OUT", "IS_RMS_NORM", "HAS_BIAS"],
)
# @triton.heuristics:启发式装饰器,用于根据输入参数动态调整 kernel 的行为。例如,如果B(偏置)不为None,则HAS_BIAS为真。
# @triton.heuristics({"HAS_BIAS": lambda args: args["B"] is not None})
# @triton.heuristics({"HAS_RESIDUAL": lambda args: args["RESIDUAL"] is not None})
@triton.heuristics({"HAS_X1": lambda args: args["X1"] is not None})
@triton.heuristics({"HAS_W1": lambda args: args["W1"] is not None})
@triton.heuristics({"HAS_B1": lambda args: args["B1"] is not None})
@triton.jit
# 输入参数解释
# X, Y:输入和输出的指针。
# W, B:权重和偏置的指针。
# RESIDUAL, X1, W1, B1, Y1:分别指向残差、第二输入、第二权重、第二偏置和第二输出的指针。
# RESIDUAL_OUT:指向用于存储输出残差的指针。
# ROWSCALE:行缩放因子的指针。
# SEEDS, DROPOUT_MASK:用于dropout的种子和掩码指针。
# Mean, Rstd:指向均值和标准差倒数的指针。
# stride_x_row等:指示如何在内存中移动以访问不同数据行的步长。其它几个变量类似。
# M, N:X的行数和列数。
# eps:用于数值稳定性的小常数。
# dropout_p:dropout概率。
# IS_RMS_NORM等:编译时常量,指示是否执行特定操作或使用特定数据。
def _layer_norm_fwd_1pass_kernel(
X, # pointer to the input
Y, # pointer to the output
W, # pointer to the weights
B, # pointer to the biases
RESIDUAL, # pointer to the residual
X1,
W1,
B1,
Y1,
RESIDUAL_OUT, # pointer to the residual
ROWSCALE,
SEEDS, # Dropout seeds for each row
DROPOUT_MASK,
Mean, # pointer to the mean
Rstd, # pointer to the 1/std
stride_x_row, # how much to increase the pointer when moving by 1 row
stride_y_row,
stride_res_row,
stride_res_out_row,
stride_x1_row,
stride_y1_row,
M, # number of rows in X
N, # number of columns in X
eps, # epsilon to avoid division by zero
dropout_p, # Dropout probability
IS_RMS_NORM: tl.constexpr,
BLOCK_N: tl.constexpr,
HAS_RESIDUAL: tl.constexpr,
STORE_RESIDUAL_OUT: tl.constexpr,
HAS_BIAS: tl.constexpr,
HAS_DROPOUT: tl.constexpr,
STORE_DROPOUT_MASK: tl.constexpr,
HAS_ROWSCALE: tl.constexpr,
HAS_X1: tl.constexpr,
HAS_W1: tl.constexpr,
HAS_B1: tl.constexpr,
):
# Map the program id to the row of X and Y it should compute.
# 获取当前程序实例(program ID)负责处理的行号。
row = tl.program_id(0)
# 调整输入X的指针,使其指向当前行
X += row * stride_x_row
# 调整输出Y的指针,使其指向当前行。
Y += row * stride_y_row
# 条件性地调整其它指针(如RESIDUAL, X1, Y1等),以处理残差、第二输入路径等。
if HAS_RESIDUAL:
RESIDUAL += row * stride_res_row
if STORE_RESIDUAL_OUT:
RESIDUAL_OUT += row * stride_res_out_row
if HAS_X1:
X1 += row * stride_x1_row
if HAS_W1:
Y1 += row * stride_y1_row
# Compute mean and variance
# 生成一个从0到BLOCK_N的列索引数组。
cols = tl.arange(0, BLOCK_N)
# 从X加载当前行的元素,超出列数N的部分用0填充。
x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
# 如果启用了行缩放(HAS_ROWSCALE),则对加载的x进行行缩放。
if HAS_ROWSCALE:
rowscale = tl.load(ROWSCALE + row).to(tl.float32)
x *= rowscale
# 如果启用了dropout(HAS_DROPOUT),则计算dropout掩码并应用于x,并根据条件存储dropout掩码。
if HAS_DROPOUT:
# Compute dropout mask
# 7 rounds is good enough, and reduces register pressure
# 使用7轮随机生成操作(减少寄存器压力)生成dropout掩码。tl.rand根据给定的种子为每个元素生成随机值,
# 如果这个值大于dropout概率dropout_p,则该元素保持,否则为0。
keep_mask = tl.rand(tl.load(SEEDS + row).to(tl.uint32), cols, n_rounds=7) > dropout_p
# 应用dropout掩码到输入x,未被dropout的元素按(1.0 - dropout_p)进行缩放,以保持其总体期望值。
x = tl.where(keep_mask, x / (1.0 - dropout_p), 0.0)
# 如果需要,将计算出的dropout掩码存储起来。
if STORE_DROPOUT_MASK:
tl.store(DROPOUT_MASK + row * N + cols, keep_mask, mask=cols < N)
# 检查是否存在第二输入路径。
if HAS_X1:
# 加载第二输入路径X1的元素。
x1 = tl.load(X1 + cols, mask=cols < N, other=0.0).to(tl.float32)
# 如果启用行缩放,应用行缩放因子rowscale到x1。
if HAS_ROWSCALE:
rowscale = tl.load(ROWSCALE + M + row).to(tl.float32)
x1 *= rowscale
# 对x1应用dropout处理,逻辑与x相同。
if HAS_DROPOUT:
# Compute dropout mask
# 7 rounds is good enough, and reduces register pressure
keep_mask = (
tl.rand(tl.load(SEEDS + M + row).to(tl.uint32), cols, n_rounds=7) > dropout_p
)
x1 = tl.where(keep_mask, x1 / (1.0 - dropout_p), 0.0)
if STORE_DROPOUT_MASK:
tl.store(DROPOUT_MASK + (M + row) * N + cols, keep_mask, mask=cols < N)
# 将处理后的x1加到x上。
x += x1
# 如果存在残差输入,将其加到x上。
if HAS_RESIDUAL:
residual = tl.load(RESIDUAL + cols, mask=cols < N, other=0.0).to(tl.float32)
x += residual
# 如果需要,将x(可能包括加上了x1和残差后的值)存储为残差输出。
if STORE_RESIDUAL_OUT:
tl.store(RESIDUAL_OUT + cols, x, mask=cols < N)
# 如果不使用RMS归一化,则按照常规方法计算均值mean和方差var。
if not IS_RMS_NORM:
# 计算x的均值。
mean = tl.sum(x, axis=0) / N
# 将计算出的均值mean存储起来。
tl.store(Mean + row, mean)
# 计算中心化后的x(即xbar)。
xbar = tl.where(cols < N, x - mean, 0.0)
# 计算x的方差。
var = tl.sum(xbar * xbar, axis=0) / N
else:
# 如果使用RMS归一化,方差的计算略有不同,不从x中减去均值。
xbar = tl.where(cols < N, x, 0.0)
var = tl.sum(xbar * xbar, axis=0) / N
# 计算反标准差rstd,eps用于数值稳定性。
rstd = 1 / tl.sqrt(var + eps)
# 将计算出的反标准差rstd存储起来。
tl.store(Rstd + row, rstd)
# Normalize and apply linear transformation
# 创建一个布尔掩码,用于标识哪些列索引在输入X的有效范围内。这确保只有有效的数据被处理,避免越界访问。
mask = cols < N
# 以浮点32位格式加载权重W。通过应用掩码mask,仅加载每行有效列的权重。
w = tl.load(W + cols, mask=mask).to(tl.float32)
# 如果HAS_BIAS为真,表明存在偏置项,同样以浮点32位格式加载偏置B。
if HAS_BIAS:
b = tl.load(B + cols, mask=mask).to(tl.float32)
# 计算归一化后的数据x_hat。如果不是进行RMS归一化(即正常层归一化),
# 则从x中减去均值mean后乘以反标准差rstd。如果是RMS归一化,直接将x乘以rstd。
x_hat = (x - mean) * rstd if not IS_RMS_NORM else x * rstd
# 将归一化后的数据x_hat乘以权重w,如果存在偏置b,则加上偏置。这完成了对每个元素的线性变换。
y = x_hat * w + b if HAS_BIAS else x_hat * w
# Write output
# 将线性变换后的结果y存储到输出张量Y的相应位置。通过使用掩码mask,确保只有有效数据被写入。
tl.store(Y + cols, y, mask=mask)
# 处理第二路径(如果存在):
if HAS_W1:
w1 = tl.load(W1 + cols, mask=mask).to(tl.float32)
if HAS_B1:
b1 = tl.load(B1 + cols, mask=mask).to(tl.float32)
y1 = x_hat * w1 + b1 if HAS_B1 else x_hat * w1
tl.store(Y1 + cols, y1, mask=mask)
这个函数是使用Triton实现LayerNorm 前向kernel的实现,给我最大的感觉就是太pythonic了,现在不需要操心使用多少个warp来处理LayerNorm的一行元素,也不需要手动管理Block的共享内存,也不需要我们去做warp间和warp内的reduce了,除了几个Triton特殊的语法之外很像写普通的Python那样,写起来逻辑很顺。
_layer_norm_fwd 函数解析¶
相比于上面的_layer_norm_fwd_1pass_kernel Triton LayerNorm kernel具体实现,这个函数则是更加上层的函数,它最终会调用上面的_layer_norm_fwd_1pass_kernel Triton LayerNorm kernel来做具体计算。我们来解析一下:
# 这段代码定义了一个函数 _layer_norm_fwd,它执行层归一化(Layer Normalization)操作,
# 并提供了对残差连接、第二路径输入、行缩放、dropout等高级功能的支持。
# x: 输入张量,是需要进行层归一化的数据。
# weight, bias: 归一化后的数据要乘以的权重和加上的偏置。
# eps: 一个很小的数,用于防止除以零,增加数值稳定性。
# residual: 可选的残差输入,用于实现残差连接。
# x1, weight1, bias1: 第二路径的输入张量、权重和偏置,允许函数并行处理两个不同的输入。
# dropout_p: dropout概率,用于在训练过程中随机丢弃一部分神经元,以防止过拟合。
# rowscale: 行缩放因子,用于对输入数据的每一行进行缩放。
# out_dtype, residual_dtype: 指定输出和残差的数据类型。
# is_rms_norm: 布尔标志,指示是否使用RMS归一化。
# return_dropout_mask: 布尔标志,指示是否返回dropout掩码。
def _layer_norm_fwd(
x,
weight,
bias,
eps,
residual=None,
x1=None,
weight1=None,
bias1=None,
dropout_p=0.0,
rowscale=None,
out_dtype=None,
residual_dtype=None,
is_rms_norm=False,
return_dropout_mask=False,
):
# 如果提供了残差输入residual,函数会记录其数据类型到residual_dtype变量。这对于确保输出和残差的数据类型一致性很重要。
if residual is not None:
residual_dtype = residual.dtype
# 通过x.shape获取输入张量x的形状,其中M是批次大小或行数,N是特征数量或列数。
M, N = x.shape
# 通过assert x.stride(-1) == 1确保输入张量x在最内层维度(即列维度)的内存布局是连续的。
assert x.stride(-1) == 1
# 如果提供了残差输入,执行以下检查:
if residual is not None:
# 确保残差输入在最后一个维度上的步长为1,这意味着它在内存中是连续的。
assert residual.stride(-1) == 1
# 确保残差输入的形状与主输入x相匹配,这是为了确保可以直接在残差和主输入之间进行元素级操作。
assert residual.shape == (M, N)
# 确保权重向量的形状正确,即长度为N,与输入x的特征数量相匹配。
assert weight.shape == (N,)
# 确保权重向量在内存中是连续的。
assert weight.stride(-1) == 1
# 对于偏置bias,如果它被提供了,进行类似的检查。
if bias is not None:
assert bias.stride(-1) == 1
assert bias.shape == (N,)
# 如果提供了第二路径的输入,执行以下检查:
if x1 is not None:
# 确保第二输入x1的形状与主输入x相同。
assert x1.shape == x.shape
# 当存在第二输入时,不支持行缩放,因此rowscale应为None。
assert rowscale is None
# 确保x1在最后一个维度上的步长为1。
assert x1.stride(-1) == 1
# 对于第二组权重weight1和偏置bias1,如果它们被提供了,进行与第一组相同的形状和内存连续性检查。
if weight1 is not None:
assert weight1.shape == (N,)
assert weight1.stride(-1) == 1
if bias1 is not None:
assert bias1.shape == (N,)
assert bias1.stride(-1) == 1
# 如果提供了行缩放向量,执行以下检查:
if rowscale is not None:
# 确保行缩放向量在内存中是连续的。
assert rowscale.is_contiguous()
# 确保行缩放向量的长度与输入x的行数M相匹配。
assert rowscale.shape == (M,)
# allocate output
# 根据输入x的形状和类型(或指定的out_dtype)分配输出张量y。
y = torch.empty_like(x, dtype=x.dtype if out_dtype is None else out_dtype)
assert y.stride(-1) == 1
# 如果提供了第二组权重,则同样分配第二输出张量y1。
if weight1 is not None:
y1 = torch.empty_like(y)
assert y1.stride(-1) == 1
else:
y1 = None
# 如果满足以下任一条件,分配残差输出张量residual_out:
# 提供了残差输入。
# 指定的残差数据类型与输入x的数据类型不同。
# 指定了dropout概率大于0。
# 提供了行缩放向量或第二输入路径。
if (
residual is not None
or (residual_dtype is not None and residual_dtype != x.dtype)
or dropout_p > 0.0
or rowscale is not None
or x1 is not None
):
# residual_out 的形状为(M, N),类型为指定的residual_dtype或输入x的类型。
residual_out = torch.empty(
M, N, device=x.device, dtype=residual_dtype if residual_dtype is not None else x.dtype
)
assert residual_out.stride(-1) == 1
else:
residual_out = None
# mean和rstd张量被创建用于存储每个样本的均值和反标准差。
# 如果不是RMS归一化(is_rms_norm为False),则mean被分配内存;否则,mean设置为None。
mean = torch.empty((M,), dtype=torch.float32, device=x.device) if not is_rms_norm else None
rstd = torch.empty((M,), dtype=torch.float32, device=x.device)
# 如果指定了dropout概率(dropout_p > 0.0),则生成一个随机种子张量seeds。
# 如果存在第二输入x1,种子张量的大小会加倍(2 * M),以支持两个输入路径。
if dropout_p > 0.0:
seeds = torch.randint(
2**32, (M if x1 is None else 2 * M,), device=x.device, dtype=torch.int64
)
else:
seeds = None
# 如果需要返回dropout掩码(return_dropout_mask为True),并且dropout概率大于0,
# 则创建dropout_mask张量,其形状取决于是否存在第二输入路径x1。
if return_dropout_mask and dropout_p > 0.0:
dropout_mask = torch.empty(M if x1 is None else 2 * M, N, device=x.device, dtype=torch.bool)
else:
dropout_mask = None
# Less than 64KB per feature: enqueue fused kernel
# MAX_FUSED_SIZE定义了每个特征可以使用的最大内存大小。BLOCK_N是选择的用于操作的列数的最小2的幂,
# 且不超过MAX_FUSED_SIZE定义的限制。如果N超过了BLOCK_N,则抛出运行时错误,表示特征维度超出了支持的最大值。
MAX_FUSED_SIZE = 65536 // x.element_size()
BLOCK_N = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
if N > BLOCK_N:
raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
# 确保操作在正确的CUDA设备上执行。
with torch.cuda.device(x.device.index):
# _layer_norm_fwd_1pass_kernel内核函数被调用,
# 传入了所有必要的参数,包括输入、输出、权重、偏置、残差、随机种子和dropout掩码等。
# kernel函数的调用采用了Triton的语法,[(M,)]表示program实例个数,即并行执行的分组数量。
_layer_norm_fwd_1pass_kernel[(M,)](
x,
y,
weight,
bias,
residual,
x1,
weight1,
bias1,
y1,
residual_out,
rowscale,
seeds,
dropout_mask,
mean,
rstd,
x.stride(0),
y.stride(0),
residual.stride(0) if residual is not None else 0,
residual_out.stride(0) if residual_out is not None else 0,
x1.stride(0) if x1 is not None else 0,
y1.stride(0) if y1 is not None else 0,
M,
N,
eps,
dropout_p,
is_rms_norm,
BLOCK_N,
residual is not None,
residual_out is not None,
bias is not None,
dropout_p > 0.0,
dropout_mask is not None,
rowscale is not None,
)
# residual_out is None if residual is None and residual_dtype == input_dtype and dropout_p == 0.0
# 如果dropout_mask不为None且存在第二输入路径x1,则dropout_mask会被分为两部分,分别用于两个输入路径。
if dropout_mask is not None and x1 is not None:
dropout_mask, dropout_mask1 = dropout_mask.tensor_split(2, dim=0)
else:
dropout_mask1 = None
# y和y1:第一和第二路径的归一化、线性变换后的输出。
# mean和rstd:计算得到的均值和反标准差(如果进行了这些计算)。
# residual_out:如果有残差输出则返回,否则返回原始输入x。
# seeds:用于dropout的随机种子。
# dropout_mask和dropout_mask1:应用于第一和第二路径的dropout掩码(如果有)。
return (
y,
y1,
mean,
rstd,
residual_out if residual_out is not None else x,
seeds,
dropout_mask,
dropout_mask1,
)
这个函数是LayerNorm实现的上层接口,向上去对接PyTorch的数据结构,而_layer_norm_fwd_1pass_kernel则是具体的kernel实现,对接的是Tensor的数据指针。
_layer_norm_bwd_kernel 函数解析¶
_layer_norm_bwd_kernel会对LayerNorm过程中涉及到的X,W,B的梯度进行求取,这里涉及到一些公式推导,为了更加直观的理解kernel,这里先对DX,DW,DB的求解过程尝试进行推导。
权重梯度dw和偏置梯度db¶
在LayerNorm中,给定的输出y是通过对输入x进行归一化,然后乘以权重w并加上偏置b得到的。即:
y = (x_{\text{hat}})w + b
其中,x_{\text{hat}}是归一化后的输入。根据链式法则,权重梯度dw可以表示为:
dw = \frac{\partial L}{\partial w} = \frac{\partial L}{\partial y} \frac{\partial y}{\partial w} = dy \cdot x_{\text{hat}}
这里,L是损失函数,dy = \frac{\partial L}{\partial y}是输出相对于损失的梯度。
类似地,偏置梯度db可以通过对b的偏导得到:
db = \frac{\partial L}{\partial b} = \frac{\partial L}{\partial y} \frac{\partial y}{\partial b} = dy
输入梯度dx¶
这个地方我纠结了很久,还是没搞清楚出LayerNorm中输入梯度dx是如何推导出来的,尝试问ChatGPT得到的回答如下:

 它指出了这个公式背后有非常复杂的数学推导,因为x_{hat,i}对x_i的梯度被均值和方差本身间接影响。虽然不知道为什么,但是公式推导出的结果和代码能对上。数学比较好的大佬如果清楚这里可以在评论区留言。
它指出了这个公式背后有非常复杂的数学推导,因为x_{hat,i}对x_i的梯度被均值和方差本身间接影响。虽然不知道为什么,但是公式推导出的结果和代码能对上。数学比较好的大佬如果清楚这里可以在评论区留言。
另外,Triton的官方教程里面也是直接给出了公式,我没找到推导的来源:

代码解析¶
# 这段代码定义了一个用于执行 LayerNorm 的反向传播(backward pass)操作的 Triton kernel函数 _layer_norm_bwd_kernel。
# @triton.autotune: 该装饰器用于自动寻找最佳的执行配置,如num_warps(每个program 实例中的并行线程束数量)。
@triton.autotune(
configs=[
triton.Config({}, num_warps=1),
triton.Config({}, num_warps=2),
triton.Config({}, num_warps=4),
triton.Config({}, num_warps=8),
triton.Config({}, num_warps=16),
triton.Config({}, num_warps=32),
],
key=["N", "HAS_DRESIDUAL", "STORE_DRESIDUAL", "IS_RMS_NORM", "HAS_BIAS", "HAS_DROPOUT"],
)
# @triton.heuristics({"HAS_BIAS": lambda args: args["B"] is not None})
# @triton.heuristics({"HAS_DRESIDUAL": lambda args: args["DRESIDUAL"] is not None})
# @triton.heuristics({"STORE_DRESIDUAL": lambda args: args["DRESIDUAL_IN"] is not None})
# 启发式装饰器根据输入参数的特定条件动态调整内核的行为。例如,HAS_BIAS通过检查B是否为None来决定是否存在偏置项。
@triton.heuristics({"HAS_ROWSCALE": lambda args: args["ROWSCALE"] is not None})
@triton.heuristics({"HAS_DY1": lambda args: args["DY1"] is not None})
@triton.heuristics({"HAS_DX1": lambda args: args["DX1"] is not None})
@triton.heuristics({"HAS_B1": lambda args: args["DB1"] is not None})
@triton.heuristics({"RECOMPUTE_OUTPUT": lambda args: args["Y"] is not None})
@triton.jit
# 输入X、权重W、偏置B,以及需要重计算的输出Y。
# DY: 输出梯度的指针。
# DX, DW, DB: 分别指向输入梯度、权重梯度和偏置梯度的指针。
# DRESIDUAL, W1, DY1, DX1, DW1, DB1, DRESIDUAL_IN: 支持第二路径和残差梯度的额外参数。
# ROWSCALE: 行缩放因子的指针
# SEEDS: Dropout种子。
# Mean, Rstd: 分别指向均值和反标准差的指针。
# stride_x_row等: 指定当从一行移动到下一行时,指针应该增加的距离。
# M, N: 输入张量的行数和列数。
# eps: 用于数值稳定性的小常数。
# dropout_p: Dropout概率。
# rows_per_program: 每个program应处理的行数。
# IS_RMS_NORM等: 编译时常量,控制内核行为的标志。
def _layer_norm_bwd_kernel(
X, # pointer to the input
W, # pointer to the weights
B, # pointer to the biases
Y, # pointer to the output to be recomputed
DY, # pointer to the output gradient
DX, # pointer to the input gradient
DW, # pointer to the partial sum of weights gradient
DB, # pointer to the partial sum of biases gradient
DRESIDUAL,
W1,
DY1,
DX1,
DW1,
DB1,
DRESIDUAL_IN,
ROWSCALE,
SEEDS,
Mean, # pointer to the mean
Rstd, # pointer to the 1/std
stride_x_row, # how much to increase the pointer when moving by 1 row
stride_y_row,
stride_dy_row,
stride_dx_row,
stride_dres_row,
stride_dy1_row,
stride_dx1_row,
stride_dres_in_row,
M, # number of rows in X
N, # number of columns in X
eps, # epsilon to avoid division by zero
dropout_p,
rows_per_program,
IS_RMS_NORM: tl.constexpr,
BLOCK_N: tl.constexpr,
HAS_DRESIDUAL: tl.constexpr,
STORE_DRESIDUAL: tl.constexpr,
HAS_BIAS: tl.constexpr,
HAS_DROPOUT: tl.constexpr,
HAS_ROWSCALE: tl.constexpr,
HAS_DY1: tl.constexpr,
HAS_DX1: tl.constexpr,
HAS_B1: tl.constexpr,
RECOMPUTE_OUTPUT: tl.constexpr,
):
# Map the program id to the elements of X, DX, and DY it should compute.
# 获取当前kernel 实例的program ID,用于确定处理的数据。
row_block_id = tl.program_id(0)
# 计算当前 kernel 开始处理的行号。
# rows_per_program是每个线程块负责处理的行数,这允许将数据划分成多个小块并行处理。
row_start = row_block_id * rows_per_program
# Do not early exit if row_start >= M, because we need to write DW and DB
cols = tl.arange(0, BLOCK_N)
mask = cols < N
# 这些行通过增加指针位置来实现,stride_x_row等变量表示在内存中
# 跳过一个数据行需要跳过的元素数量,确保每个线程块正确地访问到它应该处理的数据行。
X += row_start * stride_x_row
if HAS_DRESIDUAL:
DRESIDUAL += row_start * stride_dres_row
if STORE_DRESIDUAL:
DRESIDUAL_IN += row_start * stride_dres_in_row
DY += row_start * stride_dy_row
DX += row_start * stride_dx_row
if HAS_DY1:
DY1 += row_start * stride_dy1_row
if HAS_DX1:
DX1 += row_start * stride_dx1_row
if RECOMPUTE_OUTPUT:
Y += row_start * stride_y_row
# 加载权重W,mask确保只加载有效的列数据,超出N范围的列将不被加载。
w = tl.load(W + cols, mask=mask).to(tl.float32)
# 如果需要重计算输出并且有偏置(HAS_BIAS),则同样加载偏置B。
if RECOMPUTE_OUTPUT and HAS_BIAS:
b = tl.load(B + cols, mask=mask, other=0.0).to(tl.float32)
# 检查是否存在第二组输出梯度DY1。如果存在,意味着需要处理第二路径的权重W1。
if HAS_DY1:
# 在这种情况下,加载第二组权重W1,使用与加载第一组权重W相同的列索引和掩码。
w1 = tl.load(W1 + cols, mask=mask).to(tl.float32)
# 初始化权重梯度 dw 为零。这将用于累积当前 线程块 负责的所有行对权重的梯度。
dw = tl.zeros((BLOCK_N,), dtype=tl.float32)
# 如果存在偏置项,也初始化对应的偏置梯度 db 为零。
if HAS_BIAS:
db = tl.zeros((BLOCK_N,), dtype=tl.float32)
if HAS_DY1:
dw1 = tl.zeros((BLOCK_N,), dtype=tl.float32)
if HAS_B1:
db1 = tl.zeros((BLOCK_N,), dtype=tl.float32)
# 计算当前线程块的结束行。这是为了确保在处理数据的最后一个块时,不会超出总行数M。
row_end = min((row_block_id + 1) * rows_per_program, M)
for row in range(row_start, row_end):
# Load data to SRAM
# x和dy分别加载当前行的输入X和输出梯度DY,如果存在第二输出梯度DY1,也加载dy1。
x = tl.load(X + cols, mask=mask, other=0).to(tl.float32)
dy = tl.load(DY + cols, mask=mask, other=0).to(tl.float32)
if HAS_DY1:
dy1 = tl.load(DY1 + cols, mask=mask, other=0).to(tl.float32)
# mean和rstd根据是否使用RMS归一化加载均值和反标准差。
if not IS_RMS_NORM:
mean = tl.load(Mean + row)
rstd = tl.load(Rstd + row)
# Compute dx
# xhat计算归一化后的输入,根据是否使用RMS归一化进行调整。
xhat = (x - mean) * rstd if not IS_RMS_NORM else x * rstd
xhat = tl.where(mask, xhat, 0.0)
# 如果需要重计算输出Y,则根据归一化后的输入xhat和权重w(以及偏置b,如果有)计算y,并将其存储。
if RECOMPUTE_OUTPUT:
y = xhat * w + b if HAS_BIAS else xhat * w
tl.store(Y + cols, y, mask=mask)
# wdy计算权重和输出梯度的乘积,用于后续计算输入梯度DX。
wdy = w * dy
# dw和db分别累加权重梯度和偏置梯度。
dw += dy * xhat
if HAS_BIAS:
db += dy
# 如果存在第二路径,则对dy1、dw1和db1执行类似操作。
if HAS_DY1:
wdy += w1 * dy1
dw1 += dy1 * xhat
if HAS_B1:
db1 += dy1
if not IS_RMS_NORM:
# 首先计算xhat与权重梯度乘积wdy的均值(c1),以及wdy的均值(c2)。
# 然后,根据这些均值调整wdy并乘以反标准差rstd以得到DX。
c1 = tl.sum(xhat * wdy, axis=0) / N
c2 = tl.sum(wdy, axis=0) / N
dx = (wdy - (xhat * c1 + c2)) * rstd
else:
# 仅需计算xhat与wdy的均值(c1),然后使用这个均值调整wdy并乘以反标准差rstd。
c1 = tl.sum(xhat * wdy, axis=0) / N
dx = (wdy - xhat * c1) * rstd
# 如果存在残差梯度(HAS_DRESIDUAL),则将其加载并加到DX上,以合并残差的影响。
if HAS_DRESIDUAL:
dres = tl.load(DRESIDUAL + cols, mask=mask, other=0).to(tl.float32)
dx += dres
# Write dx
# 如果需要存储残差梯度(STORE_DRESIDUAL),则将计算得到的DX存储到DRESIDUAL_IN。
if STORE_DRESIDUAL:
tl.store(DRESIDUAL_IN + cols, dx, mask=mask)
# 如果存在第二输入梯度(HAS_DX1):
if HAS_DX1:
# 如果应用了Dropout(HAS_DROPOUT),使用相应的种子生成掩码,然后调整DX以仅包含未被Dropout的单元,否则直接使用DX。
if HAS_DROPOUT:
keep_mask = (
tl.rand(tl.load(SEEDS + M + row).to(tl.uint32), cols, n_rounds=7) > dropout_p
)
dx1 = tl.where(keep_mask, dx / (1.0 - dropout_p), 0.0)
else:
dx1 = dx
# 将结果存储到DX1。
tl.store(DX1 + cols, dx1, mask=mask)
# 如果应用了Dropout,对DX再次应用Dropout掩码和调整。
if HAS_DROPOUT:
keep_mask = tl.rand(tl.load(SEEDS + row).to(tl.uint32), cols, n_rounds=7) > dropout_p
dx = tl.where(keep_mask, dx / (1.0 - dropout_p), 0.0)
# 如果使用了行缩放(HAS_ROWSCALE),则加载行缩放因子并应用到DX上。
if HAS_ROWSCALE:
rowscale = tl.load(ROWSCALE + row).to(tl.float32)
dx *= rowscale
tl.store(DX + cols, dx, mask=mask)
# 更新X、DY、DX等指针位置,以及DRESIDUAL、DRESIDUAL_IN(如果存在残差梯度处理)、
# Y(如果重计算输出)、DY1和DX1(如果处理第二路径)的指针,为处理下一行数据做准备。
X += stride_x_row
if HAS_DRESIDUAL:
DRESIDUAL += stride_dres_row
if STORE_DRESIDUAL:
DRESIDUAL_IN += stride_dres_in_row
if RECOMPUTE_OUTPUT:
Y += stride_y_row
DY += stride_dy_row
DX += stride_dx_row
if HAS_DY1:
DY1 += stride_dy1_row
if HAS_DX1:
DX1 += stride_dx1_row
# 储计算得到的权重梯度dw、偏置梯度db、以及可能存在的第二路径权重梯度dw1和偏置梯度db1。
tl.store(DW + row_block_id * N + cols, dw, mask=mask)
if HAS_BIAS:
tl.store(DB + row_block_id * N + cols, db, mask=mask)
if HAS_DY1:
tl.store(DW1 + row_block_id * N + cols, dw1, mask=mask)
if HAS_B1:
tl.store(DB1 + row_block_id * N + cols, db1, mask=mask)
_layer_norm_bwd 函数解析¶
类似于_layer_norm_fwd,我们也有_layer_norm_bwd函数的解析:
# dy: 损失函数相对于层输出的梯度。
# x: 层的原始输入。
# weight: LayerNorm中用到的权重。
# bias: 层归一化中用到的偏置。
# eps: 用于数值稳定性的值。
# mean: 前向传播中计算的均值。
# rstd: 前向传播中计算的反标准差。
# dresidual: 如果有残差连接,这是残差相对于损失的梯度。
# dy1, weight1, bias1: 第二路径的相关参数。
# seeds: 用于Dropout操作的随机种子。
# dropout_p: Dropout概率。
# rowscale: 行缩放因子。
# has_residual, has_x1, is_rms_norm, x_dtype, recompute_output: 控制标志和选项。
def _layer_norm_bwd(
dy,
x,
weight,
bias,
eps,
mean,
rstd,
dresidual=None,
dy1=None,
weight1=None,
bias1=None,
seeds=None,
dropout_p=0.0,
rowscale=None,
has_residual=False,
has_x1=False,
is_rms_norm=False,
x_dtype=None,
recompute_output=False,
):
# 首先校验输入参数的一致性和合理性,包括形状、步长(连续性),以及是否所有需要的条件都满足。
M, N = x.shape
assert x.stride(-1) == 1
assert dy.stride(-1) == 1
assert dy.shape == (M, N)
if dresidual is not None:
assert dresidual.stride(-1) == 1
assert dresidual.shape == (M, N)
assert weight.shape == (N,)
assert weight.stride(-1) == 1
if bias is not None:
assert bias.stride(-1) == 1
assert bias.shape == (N,)
if dy1 is not None:
assert weight1 is not None
assert dy1.shape == dy.shape
assert dy1.stride(-1) == 1
if weight1 is not None:
assert weight1.shape == (N,)
assert weight1.stride(-1) == 1
if bias1 is not None:
assert bias1.shape == (N,)
assert bias1.stride(-1) == 1
if seeds is not None:
assert seeds.is_contiguous()
assert seeds.shape == (M if not has_x1 else M * 2,)
if rowscale is not None:
assert rowscale.is_contiguous()
assert rowscale.shape == (M,)
# allocate output
# 根据x的形状和类型(或指定的x_dtype)分配一个同样形状和类型的空张量,用于存储计算得到的输入梯度。
dx = (
torch.empty_like(x)
if x_dtype is None
else torch.empty(M, N, dtype=x_dtype, device=x.device)
)
# 如果存在残差连接且有额外条件(如不同的数据类型、使用了Dropout或行缩放、有第二路径输入),则分配空间存储残差梯度的计算结果。
dresidual_in = (
torch.empty_like(x)
if has_residual
and (dx.dtype != x.dtype or dropout_p > 0.0 or rowscale is not None or has_x1)
else None
)
# 如果存在第二路径且应用了Dropout,为第二路径的输入梯度分配空间。
dx1 = torch.empty_like(dx) if (has_x1 and dropout_p > 0.0) else None
# 如果需要重计算输出(recompute_output=True),为重新计算的输出分配空间。
y = torch.empty(M, N, dtype=dy.dtype, device=dy.device) if recompute_output else None
if recompute_output:
assert weight1 is None, "recompute_output is not supported with parallel LayerNorm"
# Less than 64KB per feature: enqueue fused kernel
# 代码通过 MAX_FUSED_SIZE 确保每个特征的大小小于 64KB,以满足 GPU 计算的内存限制。
# 如果特征维度 N 超过这个限制,将抛出运行时错误。
MAX_FUSED_SIZE = 65536 // x.element_size()
# BLOCK_N 是通过取 N 的下一个2的幂次方数和 MAX_FUSED_SIZE 之间的最小值来确定的,确保了kernel执行的效率。
BLOCK_N = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
if N > BLOCK_N:
raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
# 通过 sm_count 获取当前 CUDA 设备的流处理器数量,用于后续计算每个流处理器上运行的程序数。
sm_count = torch.cuda.get_device_properties(x.device).multi_processor_count
# 为权重梯度 _dw、偏置梯度 _db、第二路径权重梯度 _dw1 和第二路径偏置梯度 _db1 分配临时存储空间。
# 这些张量按流处理器数量和 N 的维度分配,以便在多个流处理器上并行累加梯度。
_dw = torch.empty((sm_count, N), dtype=torch.float32, device=weight.device)
_db = (
torch.empty((sm_count, N), dtype=torch.float32, device=bias.device)
if bias is not None
else None
)
_dw1 = torch.empty_like(_dw) if weight1 is not None else None
_db1 = torch.empty_like(_db) if bias1 is not None else None
rows_per_program = math.ceil(M / sm_count)
grid = (sm_count,)
# 使用 with torch.cuda.device(x.device.index): 确保kernel在正确的 CUDA 设备上执行。
with torch.cuda.device(x.device.index):
# _layer_norm_bwd_kernel[grid]: 调用预定义的 Triton kernel进行并行梯度计算。
# grid 参数定义了kernel执行的并行度,这里设置为流处理器的数量 sm_count。
# 传递给kernel的参数包括输入 x、权重 weight、偏置 bias、中间结果如均值 mean、
# 反标准差 rstd、输出梯度 dy、输入梯度 dx 以及其他控制和配置参数。
_layer_norm_bwd_kernel[grid](
x,
weight,
bias,
y,
dy,
dx,
_dw,
_db,
dresidual,
weight1,
dy1,
dx1,
_dw1,
_db1,
dresidual_in,
rowscale,
seeds,
mean,
rstd,
x.stride(0),
0 if not recompute_output else y.stride(0),
dy.stride(0),
dx.stride(0),
dresidual.stride(0) if dresidual is not None else 0,
dy1.stride(0) if dy1 is not None else 0,
dx1.stride(0) if dx1 is not None else 0,
dresidual_in.stride(0) if dresidual_in is not None else 0,
M,
N,
eps,
dropout_p,
rows_per_program,
is_rms_norm,
BLOCK_N,
dresidual is not None,
dresidual_in is not None,
bias is not None,
dropout_p > 0.0,
)
# 在内核执行完成后,对每个流处理器计算的临时梯度 _dw、_db、_dw1 和 _db1 进行沿第0维的累加,
# 以获得最终的梯度 dw、db、dw1 和 db1。这个累加操作将多个流处理器上的梯度贡献合并起来。
dw = _dw.sum(0).to(weight.dtype)
db = _db.sum(0).to(bias.dtype) if bias is not None else None
dw1 = _dw1.sum(0).to(weight1.dtype) if weight1 is not None else None
db1 = _db1.sum(0).to(bias1.dtype) if bias1 is not None else None
# Don't need to compute dresidual_in separately in this case
# 如果存在残差连接且满足特定条件(dx.dtype == x.dtype 且 dropout_p == 0.0 且 rowscale 为 None),
# 直接使用 dx 作为残差梯度 dresidual_in。
if has_residual and dx.dtype == x.dtype and dropout_p == 0.0 and rowscale is None:
dresidual_in = dx
# 如果有第二路径且 dropout_p == 0.0,则将 dx 直接用作第二路径的输入梯度 dx1。
if has_x1 and dropout_p == 0.0:
dx1 = dx
# 根据是否需要重计算输出 y,函数返回计算得到的梯度 dx、dw、db、dresidual_in,以及(如果有的话)
# 第二路径的梯度 dx1、dw1、db1,以及(如果 recompute_output 为 True)重计算的输出 y。
return (
(dx, dw, db, dresidual_in, dx1, dw1, db1)
if not recompute_output
else (dx, dw, db, dresidual_in, dx1, dw1, db1, y)
)
相比于_layer_norm_bwd_kernel来说,_layer_norm_bwd是更上层的接口,负责和PyTorch的Tensor进行交互。需要注意的细节是在启动kernel的时候,这里启动了SM个数个Block,每个Block会负责M处以SM个数这么多连续行的计算。
代码解析到这里就已经结束了,剩下的几个函数都是基于上面的接口和torch.autograd.Function来实现提供给其它上层库使用的算子接口。
0x3. 总结¶
这篇文章解析的东西其实很少,主要是梳理了一遍FlashAttention2仓库中的LayerNorm Triton kernel实现:https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/ops/triton/layer_norm.py 并做了一个个人笔记,希望对感兴趣的读者有帮助,谢谢。
本文总阅读量次