使用Msnhnet实现最优化问题(1)一(无约束优化问题)
使用Msnhnet实现最优化问题(1)一(无约束优化问题)¶
1. 预备知识¶
范数¶
L_1范数: \Vert{x}\Vert_1=\sum_{i=1}^n \mid{x_i}\mid
L_2范数: \Vert{x}\Vert_2=\sqrt{\sum_{i=1}^n \mid{x_i}\mid }
L_\infty 范数: \Vert{x}\Vert_\infty= \max{\mid x_i \mid, i\in\{1,2,3,...,n\}}
sL_p 范数:\Vert{x}\Vert_p= (\sum_{i=1}^n \mid{x_i}\mid^p)^{\frac{1}{p}}, p\in[1,\infty)
范数之间的关系:\Vert{x}\Vert_\infty \le \Vert{x}\Vert_2 \le \Vert{x}\Vert_1
梯度、Jacobian矩阵和Hessian矩阵¶
1.梯度: f(x)多元标量函数一阶连续可微
2.Jacobian矩阵: f(x)多元向量函数一阶连续可微
3.Hessian矩阵: f(x)二阶连续可微
注: 二次函数f(x)=\frac{1}{2}x^TAx+x^Tb+c,其中A\in R^{n\times n},b\in R^N, c \in R,对称矩阵则:
Taylor公式¶
如果f(x)在x_k处是一阶连续可微,令x-x_k=\delta,则其Maclaurin余项的一阶Taylor展开式为L:
如果f(x)在x_k处是二阶连续可微,令x-x_k=\delta,则其Maclaurin余项的二阶Taylor展开式为:
或者:
2. 凸函数判别准则¶
一阶判别定理¶
设在开凸集F\subseteq R^n内函数f(x)一阶可微,有:
1.f(x)在凸集F上为凸函数,则对于任意x,y\in F ,有:
f(y)−f(x) \ge \nabla f(x)^T(y−x)
2.f(x)在凸集F上为严格凸函数,则对于任意x,y\in F有
f(y)−f(x)\ge \nabla f(x)^T(y−x)
二阶判别定理¶
设在开凸集F\subseteq R^n内函数f(x)二阶可微,有:
1.f(x)在凸集F上为凸函数,则对于任意x\in F,Hessian矩阵半正定
2.f(x)在凸集F上为严格凸函数,则对于\forall x \in F,Hessian矩阵正定
矩阵正定判定¶
1.若所有特征值均大于零,则称为正定
2.若所有特征值均大于等于零,则称为半正定
3. 无约束优化¶
无约束优化基本架构¶
step1.给定初始点x_0 \in R^n, k=0以及最小误差\xi
step2.判断x_k是否满足终止条件,是则终止
step3.确定f(x)在点x_k的下降方向d_k
step4.确定下降步长\alpha_k, \alpha_k>0, 计算f_{k+1}=f(x_k+\alpha_k d_k),满足 f_{k+1} < f_k
step5.令x_{k+1}=x_k+\alpha_kd_k,k=k+1 ; 返回step2
终止条件: \Vert\nabla f(x_k)\Vert_2\le\xi\quad or\quad \Vert f_k-f_{k+1}\Vert\le\xi\quad or \quad \Vert x_k - x_{k+1}\Vert_2 \le \xi
4. 梯度下降法¶
\alpha在梯度下降算法中被称作为学习率或者步长;\nabla f(x_k)梯度的方向
梯度下降不一定能够找到全局最优解,有可能是局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
step1.给定初始点x_0 \in R^n, k=0,学习率\alpha和最小误差\xi ;
step2.判断x_k是否满足终止条件,是则终止;
step3.确定f(x)在点x_k的下降方向d_k = -\Delta f(x_k);
step5.令x_{k+1}=x_k+\alpha d_k,k=k+1;返回step2
举例¶
y = 3x_1^2+3x_2^2-x_1^2+x_2,初始点(1.5,1.5),\xi=10^{-3}
#include <Msnhnet/math/MsnhMatrixS.h>
#include <Msnhnet/cv/MsnhCVGui.h>
#include <iostream>
using namespace Msnhnet;
class SteepestDescent
{
public:
SteepestDescent(double learningRate, int maxIter, double eps):_learningRate(learningRate),_maxIter(maxIter),_eps(eps){}
void setLearningRate(double learningRate)
{
_learningRate = learningRate;
}
void setMaxIter(int maxIter)
{
_maxIter = maxIter;
}
virtual int solve(MatSDS &startPoint) = 0;
void setEps(double eps)
{
_eps = eps;
}
const std::vector<Vec2F32> &getXStep() const
{
return _xStep;
}
protected:
double _learningRate = 0;
int _maxIter = 100;
double _eps = 0.00001;
std::vector<Vec2F32> _xStep;
protected:
virtual MatSDS calGradient(const MatSDS& point) = 0;
virtual MatSDS function(const MatSDS& point) = 0;
};
class NewtonProblem1:public SteepestDescent
{
public:
NewtonProblem1(double learningRate, int maxIter, double eps):SteepestDescent(learningRate, maxIter, eps){}
MatSDS calGradient(const MatSDS &point) override
{
MatSDS dk(1,2);
// df(x) = (2x_1,2x_2)^T
double x1 = point(0,0);
double x2 = point(0,1);
dk(0,0) = 6*x1 - 2*x1*x2;
dk(0,1) = 6*x2 - x1*x1;
dk = -1*dk;
return dk;
}
MatSDS function(const MatSDS &point) override
{
MatSDS f(1,1);
double x1 = point(0,0);
double x2 = point(0,1);
f(0,0) = 3*x1*x1 + 3*x2*x2 - x1*x1*x2;
return f;
}
int solve(MatSDS &startPoint) override
{
MatSDS x = startPoint;
for (int i = 0; i < _maxIter; ++i)
{
_xStep.push_back({(float)x[0],(float)x[1]});
MatSDS dk = calGradient(x);
std::cout<<std::left<<"Iter(s): "<<std::setw(4)<<i<<", Loss: "<<std::setw(12)<<dk.L2()<<" Result: "<<function(x)[0]<<std::endl;
if(dk.L2() < _eps)
{
startPoint = x;
return i+1;
}
x = x + _learningRate*dk;
}
return -1;
}
};
int main()
{
NewtonProblem1 function(0.1, 100, 0.001);
MatSDS startPoint(1,2,{1.5,1.5});
int res = function.solve(startPoint);
if(res < 0)
{
std::cout<<"求解失败"<<std::endl;
}
else
{
std::cout<<"求解成功! 迭代次数: "<<res<<std::endl;
std::cout<<"最小值点:"<<res<<std::endl;
startPoint.print();
std::cout<<"此时方程的值为:"<<std::endl;
function.function(startPoint).print();
#ifdef WIN32
Gui::setFont("c:/windows/fonts/MSYH.TTC",16);
#endif
std::cout<<"按\"esc\"退出!"<<std::endl;
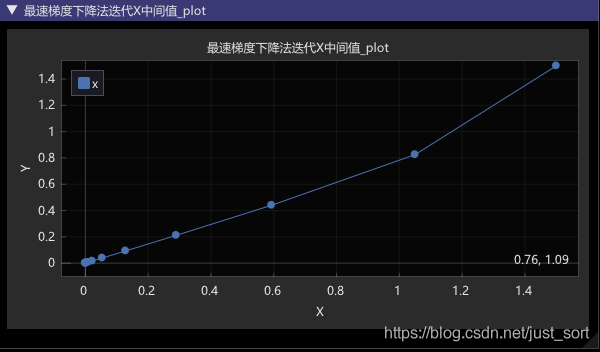
Gui::plotLine(u8"最速梯度下降法迭代X中间值","x",function.getXStep());
Gui::wait();
}
}
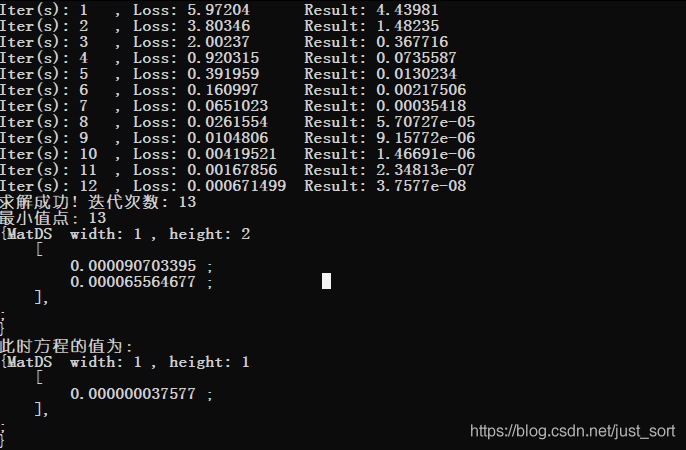
结果:迭代次数13次,求得最小值点
4. 牛顿法¶
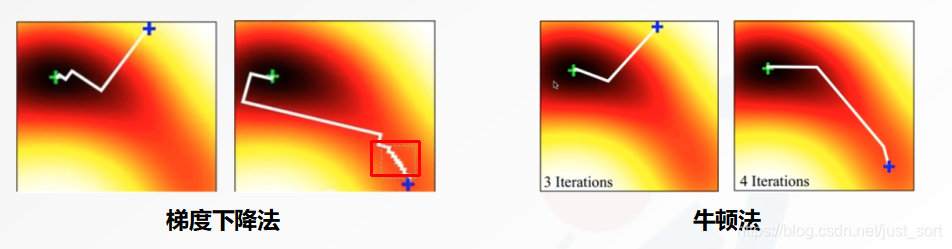
梯度下降法初始点选取问题, 会导致迭代次数过多, 可使用牛顿法可以处理.
目标函数argmin f({x})在{x}_k处进行二阶泰勒展开:
目标函数变为:
关于{d}_k求导,并让其为0,可以得到步长:
与梯度下降法比较,牛顿法的好处:
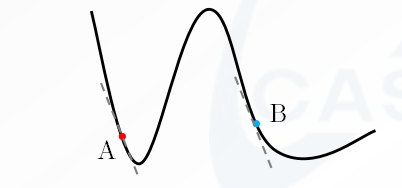
A点的Jacobian和B点的Jacobian值差不多, 但是A点的Hessian矩阵较大, 步长比较小, B点的Hessian矩阵较小,步长较大, 这个是比较合理的.如果是梯度下降法,则梯度相同, 步长也一样,很显然牛顿法要好得多. 弊端就是Hessian矩阵计算量非常大.
步骤¶
step1.给定初始点{x_0} \in R^n, k=0,学习率\alpha和最小误差\xi
step2.判断{x_k}是否满足终止条件,是则终止
step3.确定f({x})在点{x_0}的下降方向d_k = -H({x}_k)^{-1}J{x}_k
step4.令{x}_{k+1}={x}_k+\alpha {d}_k,k=k+1 返回step2
举例¶
y = 3x_1^2+3x_2^2-x_1^2+x_2,初始点(1.5,1.5)和(0,-3),\xi=10^{-3}
#include <Msnhnet/math/MsnhMatrixS.h>
#include <iostream>
#include <Msnhnet/cv/MsnhCVGui.h>
using namespace Msnhnet;
class Newton
{
public:
Newton(int maxIter, double eps):_maxIter(maxIter),_eps(eps){}
void setMaxIter(int maxIter)
{
_maxIter = maxIter;
}
virtual int solve(MatSDS &startPoint) = 0;
void setEps(double eps)
{
_eps = eps;
}
//正定性判定
bool isPosMat(const MatSDS &H)
{
MatSDS eigen = H.eigen()[0];
for (int i = 0; i < eigen.mWidth; ++i)
{
if(eigen[i]<=0)
{
return false;
}
}
return true;
}
const std::vector<Vec2F32> &getXStep() const
{
return _xStep;
}
protected:
int _maxIter = 100;
double _eps = 0.00001;
std::vector<Vec2F32> _xStep;
protected:
virtual MatSDS calGradient(const MatSDS& point) = 0;
virtual MatSDS calHessian(const MatSDS& point) = 0;
virtual bool calDk(const MatSDS& point, MatSDS &dk) = 0;
virtual MatSDS function(const MatSDS& point) = 0;
};
class NewtonProblem1:public Newton
{
public:
NewtonProblem1(int maxIter, double eps):Newton(maxIter, eps){}
MatSDS calGradient(const MatSDS &point) override
{
MatSDS J(1,2);
double x1 = point(0,0);
double x2 = point(0,1);
J(0,0) = 6*x1 - 2*x1*x2;
J(0,1) = 6*x2 - x1*x1;
return J;
}
MatSDS calHessian(const MatSDS &point) override
{
MatSDS H(2,2);
double x1 = point(0,0);
double x2 = point(0,1);
H(0,0) = 6 - 2*x2;
H(0,1) = -2*x1;
H(1,0) = -2*x1;
H(1,1) = 6;
return H;
}
bool calDk(const MatSDS& point, MatSDS &dk) override
{
MatSDS J = calGradient(point);
MatSDS H = calHessian(point);
if(!isPosMat(H))
{
return false;
}
dk = -1*H.invert()*J;
return true;
}
MatSDS function(const MatSDS &point) override
{
MatSDS f(1,1);
double x1 = point(0,0);
double x2 = point(0,1);
f(0,0) = 3*x1*x1 + 3*x2*x2 - x1*x1*x2;
return f;
}
int solve(MatSDS &startPoint) override
{
MatSDS x = startPoint;
for (int i = 0; i < _maxIter; ++i)
{
_xStep.push_back({(float)x[0],(float)x[1]});
MatSDS dk;
bool ok = calDk(x, dk);
if(!ok)
{
return -2;
}
x = x + dk;
std::cout<<std::left<<"Iter(s): "<<std::setw(4)<<i<<", Loss: "<<std::setw(12)<<dk.L2()<<" Result: "<<function(x)[0]<<std::endl;
if(dk.LInf() < _eps)
{
startPoint = x;
return i+1;
}
}
return -1;
}
};
int main()
{
NewtonProblem1 function(100, 0.01);
MatSDS startPoint(1,2,{1.5,1.5});
try
{
int res = function.solve(startPoint);
if(res == -1)
{
std::cout<<"求解失败"<<std::endl;
}
else if(res == -2)
{
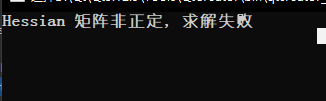
std::cout<<"Hessian 矩阵非正定, 求解失败"<<std::endl;
}
else
{
std::cout<<"求解成功! 迭代次数: "<<res<<std::endl;
std::cout<<"最小值点:"<<res<<std::endl;
startPoint.print();
std::cout<<"此时方程的值为:"<<std::endl;
function.function(startPoint).print();
#ifdef WIN32
Gui::setFont("c:/windows/fonts/MSYH.TTC",16);
#endif
std::cout<<"按\"esc\"退出!"<<std::endl;
Gui::plotLine(u8"牛顿法迭代X中间值","x",function.getXStep());
Gui::wait();
}
}
catch(Exception ex)
{
std::cout<<ex.what();
}
}
结果:对于初始点 (1.5,1.5) 迭代次数6次,求得最小值点,迭代次数比梯度下降法少了一半

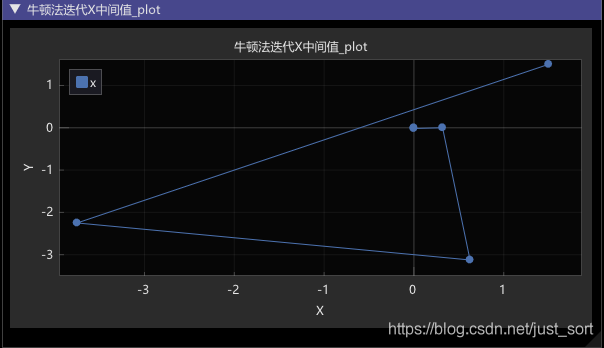
结果:二对于初始点 (0,3), 由于在求解过程中会出现hessian矩阵非正定的情况,故需要对newton法进行改进.(这个请看下期文章)
5. 源码¶
https://github.com/msnh2012/numerical-optimizaiton(https://github.com/msnh2012/numerical-optimizaiton)
6. 依赖包¶
https://github.com/msnh2012/Msnhnet(https://github.com/msnh2012/Msnhnet)
7. 参考文献¶
- Numerical Optimization. Jorge Nocedal Stephen J. Wrigh
- Methods for non-linear least squares problems. K. Madsen, H.B. Nielsen, O. Tingleff.
- Practical Optimization_ Algorithms and Engineering Applications. Andreas Antoniou Wu-Sheng Lu
- 最优化理论与算法. 陈宝林
- 数值最优化方法. 高立
网盘资料下载:链接:https://pan.baidu.com/s/1hpFwtwbez4mgT3ccJp33kQ 提取码:b6gq
8. 最后¶
- 欢迎关注我们维护的一个深度学习框架Msnhnet:
- https://github.com/msnh2012/Msnhnet Msnhnet除了是一个深度网络推理库之外,还是一个小型矩阵库,包含了矩阵常规操作,LU分解,Cholesky分解,SVD分解。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次