【GiantPandaCV导语】本文是对MLIR的论文解读以及实践,这里的实践指的是把MLIR的要点在OneFlow Dialect中进行了对应,并解释了每个要点的实现方法以及这些要点的相关性,算是对MLIR学习过程的一个阶段总结。本文分为2大部分,第一部分为1-6节,主要是阅读MLIR论文,第7节是根据OneFlow Dialect解释论文中提到的MLIR基础架构中的要点如Type,Attribute,Operation,Trait,Interfaces,Region,Block等等。本文只是想起到抛砖引玉的效果让更多小伙伴了解MLIR这个编译架构,如果对你有帮助欢迎关注一下我这个从零开始学深度学习编译器的github仓库:https://github.com/BBuf/tvm_mlir_learn。
0x0. 前言¶
之前以MLIR的Toy Tutorials教程为起点了解了一点MLIR,然后又对MLIR的ODS,DRR要点以及Interfaces等知识进行了整理。在继续学习分享MLIR的相关知识前,我想对MLIR做一个总结。而要了解MLIR的全貌,阅读MLIR论文是一个不错的方式。这篇文章在论文阅读的基础上我还做了一个思维导图把MLIR实现Dialect的组件画出来了,再以OneFlow的Dialect为例子详解了这些组件是如何实现的以及它们的关系。相信看完本文会对不熟悉MLIR的小伙伴有一些帮助和启发。希望起一个入门效果。
本文阅读方法步骤大概是(数字代表先后顺序):
- 标题
- 摘要
- 引言
- 结论
- 相关工作
- MLIR设计相关
- 评论
- 参考文章
MLIR论文链接:https://arxiv.org/pdf/2002.11054.pdf
0x1. 标题¶

论文标题翻译为,MLIR: 摩尔定律终结的编译器基础结构 。从题目可以知道MLIR是一个编译器架构,终结摩尔定律这个不太好理解,我们需要往后看看。我们还可以发现MLIR是Chris大神(LLVM,CLang、Swift项目的发起人)领衔的,这让MLIR项目的质量有很大的保障,相信这也是目前MLIR编译架构非常流行的原因之一?
0x2. 摘要¶
这篇文章提出了MLIR,这是一种构建可重用、可扩展编译器基础结构的新方法。MLIR旨在解决软件碎片化,改进异构硬件的编译过程,大大降低了构建领域特定编译器的成本,并有助于和现有的其它编译器互相连接。MLIR还有助于在不同抽象级别、不同跨应用程序域、不同硬件目标和执行环境下改善code generators、translators和optimizers的设计和实现。贡献包括:(1) 讨论MLIR作为文本研究成果可能的扩展和进化,并指出这个新方法在设计、语义、优化规范、系统和工程等方面带来的挑战和机遇。(2) 评估MLIR作为可减少构建编译器成本的通用架构-通过描述各种用例,显示本文研究成果在未来编程语言、编译器、执行环境和计算机体系结构方面的研究和教学机会。 然后还介绍了MLIR设计基本原理、结构和语义。
这一节主要是讲了一下MLIR的卖点,即MLIR是一个新的编译器架构,它着力于解决软件碎片化并降低了构建特定领域编译器的成本。
其实今天来看软件碎片化问题MLIR是没有完全解决的,它只是把软件碎片化问题转移为各个Dialect间的碎片化,然后这些Dialect又属于同一种语言可以混用以此缓解了软件碎片化带来的影响。这里为什么是缓解而不是完全解决呢?首先我理解软件的碎片化应该就是针对N种前端框架(如TensorFlow,PyTorch...)和M种后端(GPU,CPU..)的适配问题,如果没有一个中间的IR表示那么这个适配的工作量是N * M,然后微软提出的ONNX尝试作为一个中间的IR使得这个N * M的问题变成M,即所有的前端框架都可以转换到ONNX,只需要适配ONNX的后端就可以了。但理想和现实往往不一样,ONNX为了适配各种前端框架捏了一系列更加通用的算子(opset)来匹配各个前端框架的算子语意,但这样做的后果就是前端框架和ONNX互转的时候往往引入了一些新的胶水Op使得IR变得更加复杂。说回MLIR,各个前端框架把自己的IR对接为MLIR的Dialect上之后要走相当多的DialectConversion才可以到可以做代码生成的LLVM IR。虽然各个Dialect可以混用这样就不会出现ONNX里面那种多出胶水Op的情况,但Dialect可以混用不代表DialectConversion的畅通无阻。假设Dialect A下有一个Op X我们要将其转换为Dialect B下的Op,并且Dialect B下面没有对应Op X语意的Op或Dialect B下对应Op X语意的Op和X的语意有一些差距那么我们必须对Dialect B进行扩展以满足需求,这和ONNX不断增加Opset似乎没什么两样,并且MLIR的Dialect链路可能会很长,所以这种情况下感觉会比ONNX更麻烦。但乐观的想,MLIR开源到现在就2-3年,相信随着各个Dialect的丰富,这种碎片化风险真的会逐渐变小。
而降低构建特定领域编译器成本应该指的是在MLIR的生态更加完善之后,理论上我们只需要在对应硬件上实现一个边界Dialect,然后在这个Dialect中定义硬件的Operation,之后就可以选取生态中已有的Dialect来构建一个完整的编译流程即可。
0x3. 引言¶
编译器设计是一个成熟的领域,包括许多广为人知的算法,可用于代码生成、静态分析、程序转换等。编译器设计领域已发展出许多成熟技术平台,这些平台现在已经在整个编译器社区大规模应用,包括LLVM编译器基础结构[25]、Java虚拟机(JVM)[26]等系统。这些流行系统的一个共同特征是它们的“one size fits all”方法,即与系统接口的是单一抽象级别,例如LLVM中间表示(IR)大致是“C with vectors”,JVM提供了一个“具有垃圾收集器的面向对象类型系统(object-oriented type system with a garbage collector)”抽象。这种“one size fits all”的方法非常有价值,因为从源语言(C/C ++和Java)到这些抽象领域的映射非常直接。
同时,一些问题在更高或者更低的抽象层级建模会更好,比如在LLVM IR上对C ++代码进行源代码级分析十分困难。注意到,许多语言(例如Swift,Rust,Julia,Fortran)都开发了自己的IR,以解决这些语言领域特定的问题,例如语言/库相关的优化、flow-sensitive 类型检查(例如线性类型)和优化lowering过程的实现。类似地,机器学习系统通常将“ML graphs”用作领域特定的抽象。
尽管领域特定IR的开发是一项已经被充分研究的技术,但其工程和实现成本仍然很高。对于这些系统的实现者而言,有时候基础结构的质量不一定是优先考虑的因素。这可能导致编译器系统的实现质量降低,包括一些用户常见的问题,例如编译时间慢、错误的实现、诊断质量欠佳、优化代码的调试体验差等等。
MLIR项目的目的就是要应对这些编程语言设计和实现方面的挑战---通过非常方便的定义和引入新的抽象级别,并提供“in the box”基础架构来解决常见的编译器工程问题。 MLIR的做法是:(1)标准化基于静态单赋值(SSA)的IR数据结构(2)提供用于定义IR dialect的声明系统,(3)提供广泛的通用基础结构(包括文档、解析和打印逻辑、位置跟踪、多线程编译支持、pass管理等)。
论文探讨了MLIR系统的各个设计要点,将作者们的经验应用于不同的问题,并讨论了这项工作可能对编程语言设计和教学产生的影响。
论文的贡献可以总结为如下几点:
- 描述了一种对工业界和学术界有重要应用价值的新型编译器基础结构。
- 提出了一种构建可扩展和模块化编译器系统的新方法。
- 选择了一些MLIR在不同领域的应用,说明了系统的通用性。
- 分享了在MLIR基础架构上开发编译系统的经验。
这一节还提到了MLIR的产生动机:
我们首先意识到现代机器学习框架由许多不同的编译器、图技术和运行时系统组成(请参见Figure 1),但是这些部分没有共享公共的基础结构或设计观点,而且有些部分没有遵循最佳编译器设计实践,导致的后果是用户可以明显感觉到不便,包括不完善的错误消息、边界情况下的错误、不可预测的性能,以及难以支持新硬件。
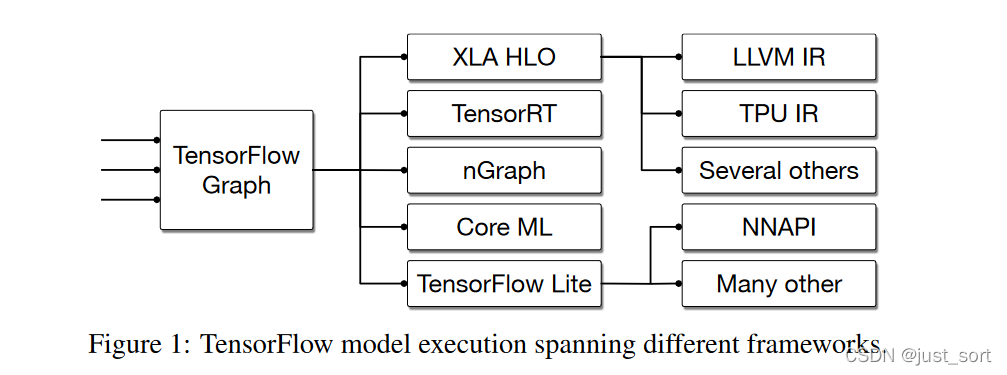
我们很快意识到,整个编译器行业都存在一个类似的问题,那就是,诸如LLVM之类的现有编译系统在跨多语言实现的统一和集成方面非常成功,但是现代高级语言通常最终会构建自己的高级IR,并重复发明许多相同的更高层抽象技术(请参见Figure2)。同时,在LLVM社区经常出现一些争论,比如,如何最好地表示并行结构,如何共享常见的前端Lowering基础架构实现(例如,用于C调用约定或诸如OpenMP之类的跨语言功能),但都没有得出令人满意的解决方案。
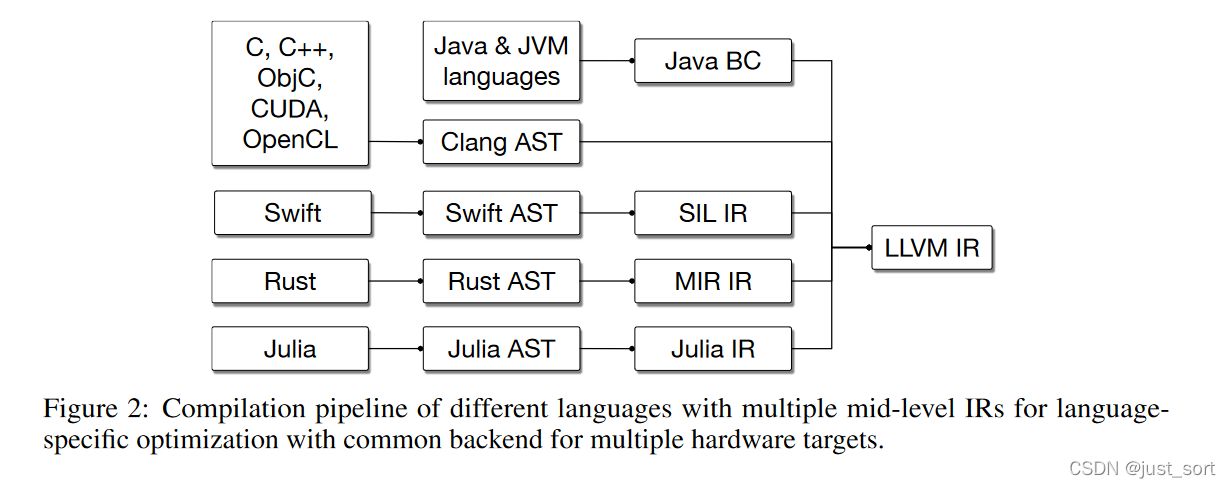
面对这些挑战,我们认为我们无法承担实现N个改进编译器的工作量,因此我们需要构建一个更通用的解决方案。我们可以花精力开发一套高质量的基础架构,这会让多个领域受益,会让我们能够逐步升级现有系统,让我们能够更轻松地解决眼下紧迫的问题,例如专用加速器的异构编译。现在,我们在构建和部署基于MLIR的系统方面积累了大量经验,可以回顾一下MLIR基础架构的原理和设计,并讨论为什么要朝这个方向发展。
这一节列举了一下相关工作以及MLIR的产生动机,以此加强说明MLIR的创新点和贡献。
0x4. 结论¶
本文介绍了MLIR,可用作构造编译器的灵活且可扩展的基础结构。本文描述了MLIR的具体设计,展示了其在一系列重要领域中的适用性,并描述了许多原创研究和工程意义。
展望未来,我们希望看到编译器社区(例如Clang C和C ++编译器)和不同领域的专家如何能从更高级的、语言特定IR中受益。我们也想知道,MLIR是否能为教授编译器和IR设计技术提供新的方法,并希望看到这种基础设施加速新领域的研究。
这里介绍了一系列未来的工作方向,感兴趣的可以自行看一下。由于我对这部分不太了解,这里就不继续看了。
0x5. 相关工作¶
MLIR是一个涵盖多个不同领域的项目。虽然其基础设施提供了一个新的系统,但组成基础设施的各个组件在相关文献中都已有类似模块。
MLIR是类似于LLVM[25]的编译器基础结构,但LLVM在标量优化和同构编译做得很好,而MLIR的目标是将各种数据结构和算法建模为第一优先级的值和Operations,包括张量代数和算法、图表示以及异构编译。MLIR 允许混合匹配优化将编译pass分解为组件并重新定义lowering。这主要归功于模式重写基础设施,将完整的变换捕获为小型局部模式的组合,并控制在单个操作的粒度上应用哪些模式进行重写。自动扩展、形式化和验证重写逻辑将是重要的下一步 [9, 27]。在后端,MLIR 的 DDR 类似于 LLVM 的指令选择基础设施,支持以多结果模式和规范作为约束的可扩展操作[49]。
许多编程语言和模型都解决了硬件异构问题。 同构编程模型OpenMP基于StarSs和OpenACC[34,31]等较早的建议,增加了对卸载(offloading)任务和加速器并行区域[32]的支持。 C++ AMP、HCC和SyCL利用传统的Clang/LLVM流程和C++为硬件加速提供高级抽象[46]。但是,所有这些例子都依赖于宿主语言(通常为C++)中的已有优化来减轻抽象造成的损失,从而将高级构造快速lower到对运行时执行环境的调用。扩展 LLVM IR 的并行中间表示解决了部分问题,但传统上专注于同构设置 [23, 42] 。迄今为止,最有雄心的工作可能是Liquid Metal[3],其中提供了协同设计的领域特定语言(DSL),以及将被管理对象的语义转换为静态的、向量的或可重配置硬件的编译流程。然而,在其Lime编译器中,大部分工作量都放在将round对象装配到square硬件中(Kou和Palsberg [24])。 MLIR通过可扩展的Operation和Type集合,为包含异构特性的高级语言提供直接嵌入手段,同时提供了一个通用基础结构,可逐步lowering这些结构,并最大程度地在不同目标之间重用通用组件。
解决语言异构性已成为元编程系统,尤其是多阶段编程的长期目标。Lightweight Modular Staging(LMS)[39]是最新的技术框架和运行时代码生成器,提供了可生成高效代码并将DSL嵌入Scala的核心组件库。 Delite[45]声称可以大幅提高DSL开发者的效率,同时支持并行和异构执行。我们认为这种方法是对MLIR的补充,为嵌入DSL提供了更高层次的抽象,并通过通用元编程构造实现了优化。
在语言语法上更进一步,ANTLR [33] 是一类解析器生成器,旨在使开发新的编译器前端变得容易。 MLIR 目前没有通用解析器生成,没有 AST 构造或建模功能。 将 MLIR 与 ANTLR 等系统相结合,可以生成从用户输入到代码生成的可重用编译器库。
XLA[57]、Glow[40]和TVM[11]通过在机器学习中的应用,解决类似的异构编译目标。但是这些技术都是很具体的代码生成实例,从图形抽象开始,针对的是加速器的多维矢量抽象。这些技术都可以将MLIR用作基础架构,在使用各自现有的代码生成策略的同时,充分利用MLIR的通用功能。同样,来自Halide[36]和TVM的循环嵌套元编程技术,较早的循环嵌套元编程文献[19,41,5,14],和全自动流程,如PolyMage[28]、Tensor Com-Phenhension[52]、Stripe[58]、Diesel[16]、Tiramisu[4]及其底层多面体编译技术[17,54,8,55],可以在基于MLIR的编译框架中以不同的代码生成路径共存。序列化和互操作性格式有不同的方法解决ML前端的多样性问题,例如,ONNX[48]的方法是通过提供不同框架都可以映射的通用op集合。ONNX会成为MLIR的一种dialect选择,其他op可以被降级为该dialect。
0x6. MLIR设计相关¶
0x6.1 设计原则¶
内置少,一切可定制(Little builtin, everything customizable) MLIR系统基于最少量的基本概念,大部分IR都完全可定制。在设计时,应当用少量抽象(类型、操作和属性,这是IR中最常见的)表示其它所有内容,从而可以使抽象更少、更一致,也让这些抽象易于理解、扩展和使用。广义上讲,可定制性确保编译系统可以适应不断变化的需求,并且更有可能适用于未来的问题。从这个意义上讲,我们应该将IR构建为支持其中间语言的语法和语义、具有可重用组件和编程抽象的基础结构。定制化成功的标准是可以表达多种抽象,包括机器学习图、ASTs、数学抽象(例如多面体)、控制流图(CFGs)和指令级IR(例如LLVM IR),而且从这些抽象到编译系统无需使用任何硬编码的概念。当然,由于兼容性不佳,可定制性会带来内部碎片化的风险。 虽然不可能有一种纯粹的技术解决方案来解决生态系统碎片化问题,但系统应鼓励设计可重用抽象,并假定这些抽象会在设计的预料范围之外被使用。
SSA and regions 静态单赋值形式[15]是编译器IR中广泛使用的表示形式。它提供了许多优点,包括使数据流分析简单和稀疏,因其与continuation-passing风格的关系而被编译器社区广泛理解,并在主要框架中应用。尽管许多现有的IR使用扁平的,线性CFG,但代表更高级别的抽象却推动将嵌套区域(nested regions)作为IR中的第一概念。这超越了传统的region形式,提升了抽象级别(例如,loop trees),加快了编译过程、指令提取或SIMD并行性[22,21,37]。为了支持异构编译,系统必须支持结构化控制流、并发构造、源语言中的闭包等等。一个具体的挑战就是在嵌套区域之上构造基于CFG的分析和转换。
为了这样做,会牺牲LLVM的归一化(normalization),有时甚至牺牲其规范化(canonicalization)属性。能够将各种数据和控制结构降级为更小的归一化(normalized)表示集合,这对于控制编译器的复杂性至为重要。具有pre-header、header、latch、body的规范循环(canonical loop)结构是前端语言中各种循环构造的线性化控制流表示的典型情况。MLIR的目的是为用户提供一种选择,即,根据编译流程中pass的编译算法,可以将嵌套循环捕获为嵌套region或线性化控制流。通过提供这种选择,我们可以脱离LLVM的normalization-only方向,同时保留了在必要时处理更高级别抽象的能力。反过来,采用MLIR的这些方法也产生了如何控制抽象规范化(normalization)的问题,这是下一段的主题。
渐进式降级(Progressive lowering) 编译系统应支持渐进式lower,即,以较小的步幅,依次经过多个抽象级别,从较高级别的表示降低到最低级别。需要多层抽象是因为通用编译器基础结构必须支持多种平台和编程模型。以前的编译器已经在其pipeline中引入了多个固定的抽象级别,例如Open64 WHIRL表示[30]具有五个级别,Clang/LLVM编译器从AST降级到LLVM IR、SelectionDAG、MachineInstr和MCInst。上述降级实现方式较为僵化,因而需要更灵活的设计来支持抽象级别的可扩展性。这对转换的相位排序有深刻的影响。随着编译器专家们实现越来越多的变换pass,这些pass之间开始出现复杂交互。实际情况表明,将优化pass结合起来运行可以使编译器发现更多的程序有用信息。能说明组合pass好处的例子有混合常量传播、值编号(value numbering)和死代码消除的尝试[13]。一般而言,编译器pass可大致分为四个角色:(1)优化变换(2)使能变换(3)lowering(4)cleanup。编译系统应该允许在单个操作的粒度上混合和匹配这些角色,而不是在整个编译单元上顺序执行这些pass。
保持高层级语意(Maintain higher-level semantics) 系统需要保留分析或优化性能所需的高级语义和计算结构。一旦降低语义再试图提高语义会很难成功,并且将这种信息强行塞进一个低层次IR的环境中通常都有破坏性(例如,在使用调试信息来记录结构的情况下,所有pass都需要进行验证/重新访问)。相反,系统应保持计算结构并逐步lowering到硬件抽象。这时,可以有意识的丢弃结构信息,并且这种丢弃只在不再需要此结构来匹配基础执行模型的情况下才会发生。例如,系统应在整个相关转换过程中保留结构化的控制流,例如循环结构。删除此结构,即转到基于CFG的控制流,实质上意味着将不再在此级别上执行任何变换。 在编译器开发中对并行计算结构进行建模的最新技术突出了该任务通常可能是多么困难[23, 42]。
为了允许编译系统的一部分IR保留较高层级的抽象,而另一部分被降低IR层级,在同一IR中混合不同级别的抽象和不同概念必然成为系统的关键属性。比如,自定义加速器的编译器可以在IR中复用系统定义的一些高级结构和抽象,IR同时也可表达加速器特有的基本标量/矢量指令。
IR验证(IR validation) 生态系统的开放性要求有宽泛的验证机制。验证和测试不仅对于检测编译器错误很有用,而且在可扩展的系统中,对验证方法和工具健壮性的需求也在不断提高。验证机制应使得定义简洁和实用,并可以作为正确结果的唯一来源。一个长期目标是复现成功的变换验证 [35、29、50、51] 和现代编译器测试方法 [12] 。在可扩展的编译器生态系统中,验证和测试都还是有待解决的两个问题。
声明式重写模式(Declarative rewrite patterns) 定义表示修饰符应该和定义新抽象一样简单。通用变换应实现为声明式表达的重写规则,并以机器可分析的格式推理出重写的属性,例如复杂性和完成度。重写系统的健全性和效率很高,因此被广泛研究,并已被应用于从类型系统(type systems)到指令选择的众多编译问题。我们(MLIR)的目标是实现前所未有的可扩展性和渐进lowering功能,可以通过许多途径将程序变换建模为重写系统。它还提出了有关如何表示重写规则和策略,以及如何构建能够通过多个抽象级别引导重写策略的机器描述的有趣问题。系统需要在解决这些问题的同时,保持可扩展性并执行合理、单调和可复制的行为。
源位置跟踪和可追溯性(Source location tracking and traceability) 操作的来源(包括其原始位置和应用的变换)应易于在系统中追溯。这是为了解决在复杂编译系统中常见的缺乏透明性问题,而在复杂编译系统中,很难了解最终表示是如何从原始表示中构造出来的完整过程。在编译安全性至关重要的敏感应用程序时,这是一个突出的问题,在这类程序中,跟踪lowering和优化步骤是软件认证程序的重要组成部分[43]。当使用安全代码(例如加密协议,或对隐私敏感的数据进行操作的算法)进行操作时,编译器常会碰到看似冗余或繁琐的计算,这些计算会嵌入未被源程序的功能语义完全捕获的安全性或私有属性,而安全代码可以防止旁路暴露或加强代码以防止网络攻击或故障攻击。优化可能会改变或使此类保护完全失效[56];这种缺乏透明性在安全编译中称为WYSINWYX[6]。准确地将高层次信息传播到较低层的一个间接目标就是帮助实现安全且可回溯的编译过程。
这一小节实际上说明MLIR具有的宏观特性,它是一个具有多层IR结构的编译架构,实际上就是多层Dialect,各个Dialect分别对不同的层级概念进行建模。比如LLVM Dialect负责系统级别的转换,Linalg,Tensor,Vector等Dialect负责协同生成代码,而Affine,Math等Dialect用来描述底层计算。
0x6.2 IR设计细节¶
本节根据上一节中阐述的原理,介绍MLIR中IR的设计。
Operations(操作)¶
MLIR中的语义单位是一个“操作”,称为Op。在MLIR系统中,从指令到函数再到模块,一切都建模为Op。 MLIR没有固定的Op集合,因此允许并鼓励用户自定义扩展Op。编译器pass会保守地对待未知Op,并且MLIR支持通过特征(traits)、特殊的Operation hooks和Interfaces等方式为pass描述Op语义。
Op(见Figure3)具有唯一的操作码(opcode)。从字面上看,操作码是一个字符串,用于标识它所在的dialect和操作。Op可以有零个或多个值作为操作数和结果,并以静态单赋值的形式(SSA)维护操作数和结果。所有值都有一个类型,类似于LLVM IR。除了操作码、操作数和结果外,Op还可能具有属性、区域、块参数和位置信息(Attributes, Regions, Block Arguments, and Location Information)。Figure4说明了值和Op,%标识符是命名值(包),如果包中有多个值,:后指定包中值的数量(注:如Figure3中的%results:2,表示返回值有2个),而“#”表示特定值。在一般的文本表示形式中,操作名称是用引号括起来的字符串,后跟括号括起来的操作数。


Attributes(属性)¶
MLIR属性是结构化的编译期静态信息,例如整数常量值、字符串数据或常量浮点值列表。属性有类型,每个Op实例都有一个从字符串名称到属性值的开放键值对字典映射。在通用语法描述中,属性在Op操作数和其类型之间,键值对列表中的不同键值对用逗号分隔,并用大括号将整个键值对列表括起来。(如Figure3中的{attribute="value" : !d.type}以及Figure4的{lower_bound = () -> (0), step = 1 : index, upper_bound = #map3})。其中,lower_bound、step和upper_bound是属性名称。() -> (0)标识用于内联仿射形式,在这个例子中是产生常数0的仿射函数。#map3标识用于属性别名,该属性别名允许将属性值与标签预先关联,并可以在任何需要属性值的地方使用标签。与操作码一样,MLIR没有固定的属性集。属性的含义由Op语义或与属性相关的dialect 中得出。属性也是可扩展的,允许直接引用外部数据结构,这对于和现有系统集成很有帮助。例如,某个属性可以引用ML系统中(在编译期已知的)数据存储的内容。
Location information (位置信息)¶
MLIR提供了位置信息的紧凑表示形式,并鼓励在整个系统中处理和传播位置信息。位置信息可用于保留产生Op的源程序堆栈踪迹,用以生成调试信息。位置信息使编译器产生诊断信息的方式变得标准化,并可用于各种测试工具。位置信息也是可扩展的,允许编译器引用现有的位置跟踪系统、高级AST节点、LLVM风格的文件-行-列(file-line-column )地址、DWARF调试信息或其它高质量编译实现所需的信息。
上面三个要点我们可以基于Toy语言的transpose Op来加深理解:
%t_tensor = "toy.transpose"(%tensor) {inplace = true} : (tensor<2x3xf64>) -> tensor<3x2xf64> loc("example/file/path":12:1)
结构拆分解释:
%t_tensor:这个Operation定义的结果的名字,前面的%是避免冲突,见https://mlir.llvm.org/docs/LangRef/#identifiers-and-keywords 。一个Operation可以定义0或者多个结果(在Toy语言中,只有单结果的Operation),它们是SSA值。该名称在解析期间使用,但不是持久的(例如,它不会在 SSA 值的内存表示中进行跟踪)。"toy.transpose":Operation的名字。它应该是一个唯一的字符串,Dialect 的命名空间前缀为“.”。 这可以理解为Toy Dialect 中的transpose Operation。(%tensor):零个或多个输入操作数(或参数)的列表,它们是由其它操作定义的SSA值或block参数的引用。{ inplace = true }:零个或多个属性的字典,这些属性是始终为常量的特殊操作数。 在这里,我们定义了一个名为“inplace”的布尔属性,它的常量值为 true。(tensor<2x3xf64>) -> tensor<3x2xf64>:函数形式表示的操作类型,前者是输入,后者是输出。<2x3xf64>号中间的内容描述了张量的尺寸2x3和张量中存储的数据类型f64,中间使用x连接。loc("example/file/path":12:1):此操作的源代码中的位置。
Regions and Blocks(区域和块)¶
Op的实例可能附有一系列附加区域。区域为MLIR中的嵌套结构提供了实现机制:一个区域包含一系列块,一个块包含一系列操作(操作中可能又包含区域,如Figure3所示)。与属性一样,区域的语义由其附加的操作定义,但是区域内部的块(如果有多个)可形成控制流图(CFG)。例如,Figure4中的affine.for操作是一个循环,其中位于({和})定界符之间的单独块是一个区域。 Op指定了跨区域的控制流。在这个例子中,重复执行主体直到达到循环上限。每个区域的主体是一系列块,每个块以终止符(terminator)操作结尾,终止符操作可能具有后继块,控制流可以转移到后继块。每个终止符(例如“switch”,“conditional branch”或“unwind”)定义自己的语义。终止符可以选择将控制流转移到同一区域中的另一个块,或将其返回到包含该区域的Op。后续块的图定义了CFG,从而允许区域内有基于标准静态单赋值(SSA)的控制流。MLIR不使用\phi节点,而是使用静态单赋值(SSA)的函数形式。其中,终止符将值传给后继块定义的块参数(block arguments)。每个块都有一个(可能为空)类型化的块参数列表,这些参数是常规值并符合静态单赋值。终止符Op的语义定义了在控制权转移后该块的参数会采用的值。对于该区域的第一个(入口)块,值由包含Op的语义定义。例如,affine.for使用入口块参数%arg4作为循环归纳变量。
这里表达的意思就是一个Operation可能有多个Region,然后Region又是由一系列Block组成,然后Block又包含一系列Op。这样就形成了一个嵌套的关系,可以表达作用域和控制流关系。
Value dominance and visibility¶
Op只能使用作用域内的值,即根据SSA支配、嵌套和包含Operation的语义限制可见的值。如果值遵循标准的SSA支配关系,则在CFG中可以看到这些值,在这些值中,可以确保控件在使用前先经过定义。
基于区域的可见性是根据区域的简单嵌套来定义的:如果Op的操作数在当前区域之外,则必须在使用的区域上方用外部词法对其进行定义,这允许affine.for操作中的Op使用外部作用域中定义的值。
MLIR还允许将操作定义为与上方隔离,表明该操作是作用域barrier(scope barrier)。例如, “std.func” Op定义了一个函数,该函数内的操作不能引用该函数外定义的值。除了提供有用的语义检查之外,由于没有use-def链可以跨过隔离障碍(isolation barriers),包含与上方隔离(isolated-from-above)的Op的Module也可以由ML编译器并行处理。这对于利用多核计算机进行的编译很重要。
Symbols and symbol tables¶
Op还可以附加一个符号表。这个符号表是将名称(以字符串表示)与IR对象(称为符号)相关联的标准方法。 IR没有规定符号的用途,而是交由Op定义。对于无需遵守静态单赋值规则的命名实体,符号很有用。符号不能在同一表中重复定义,但是可以在定义之前使用符号。例如,全局变量、函数或命名模块可以表示为符号。没有这种机制,就不可能定义递归函数(在定义中引用自己)。如果附带符号表的Op的关联区域包含相似的Op,那么符号表可以嵌套。 MLIR提供了一种机制来引用Op中的符号,包括嵌套符号。
Dialects¶
MLIR使用Dialect管理可扩展性。Dialect在一个唯一的命名空间下提供Ops、属性和类型的逻辑分组。Dialect本身并未引入任何新的语义,而是用作逻辑分组机制,并且可用于提供Dialect通用Op支持(例如,dialect中所有op的常量折叠行为)。Dialect命名空间在操作码中是以“.”分隔的前缀,例如,Figure 4使用的affine和std dialect。
概念上可以将Ops、类型和属性抽象为Dialect,这类似于设计一组模块化库。例如,某种Dialect可以包含用于对硬件向量进行操作的Op和类型(例如,shuffle、insert/extract元素、掩码等),而另一种Dialect可以包含用于对代数向量进行操作的Op和类型(例如,绝对值、点积等 )。两种dialect是否使用相同的向量类型以及该类型属于哪一个,可以由MLIR用户在设计时决定。
我们也可以将所有Op、类型和属性放在一个dialect中,但容易想到,这必然很快就会因为大量概念和名称冲突等问题,导致Dialect变得难以管理。尽管每个Op、类型和属性都只属于一个dialect,但是MLIR明确支持多种dialect的混合以便能实现渐进式lowering。来自不同dialect的Op可以在IR的任何级别共存,可以使用在不同dialect中定义的类型,等等。Dialect的混合可以加强重用性、可扩展性和灵活性。
类型系统¶
MLIR中的每个值都有类型,该类型在产生该值的Op或将值定义为参数的Block中指定。类型为IR提供了编译期语义。 MLIR中的类型系统是用户可扩展的,并且可以引用已有外部类型系统(例如llvm::Type或clang::Type)。 MLIR强制执行严格的类型等价检查,并且不提供类型转换规则。Op使用类似尾函数的语法列出其输入和结果类型。Figure4中,affine.load从内存引用和索引类型映射到加载的值的类型。从类型理论的角度来看,MLIR仅支持非依赖类型,包括trivial类型、参数类型、函数类型、求和和乘积类型。
标准类型¶
此外,MLIR提供了一组标准化的常用类型,包括任意精度整数、标准浮点类型和简单的通用容器,如元组(tuple)、多维矢量和张量。这些类型仅是方便Dialect开发者,但是不要求一定使用。
Functions and modules(函数和模块)¶
与常规IR相似,MLIR通常被构造为函数和模块,这些不是MLIR的新概念。函数和模块在builtin dialect中作为Op实现。模块是一个具有单独区域的Op,这个区域包含了一个单独的块。模块被一个不转移控制流的dummy Op终止。
模块定义了一个可以被引用的符号。像任何块一样,其主体包含一系列Op,这些Op可以是函数、全局变量、编译器元数据或其它顶级构造。函数是具有单个区域的Op,其参数对应于函数参数。
函数定义了一个可以按名称引用的符号。使用函数调用Op可以将控制流转移到函数中。 一旦进入内部,控制流程遵循区域中各个块的CFG。 “return”终止符没有后继,而是终止区域执行,从而将控制流转移回函数的调用方。 “return”终止符Op的任何操作数都是函数的返回值。
上面介绍了MLIR的IR设计细节,可以结合MLIR官方文档的语法规则来更好的熟悉:https://mlir.llvm.org/docs/LangRef/。
0x6.3 IR基础设施¶
除了IR本身之外,MLIR还提供了用于定义IR元素(如dialect、Ops、 pattern rewrite、验证和可重用passes)的基础结构。 当定义新的抽象并将MLIR用作优化工具包时,MLIR的基础结构对于提供可扩展性和易用性至关重要。
0x6.3.1 Operation description(操作描述)¶
MLIR使用TableGen[47]规范定义操作描述(Operation Descriptions, ODS),以声明的方式定义Op的结构及其验证程序组件。 TableGen是一种在LLVM中广泛使用的数据建模工具,目的是帮助定义和维护领域特定( domain-specific)信息的记录。 ODS可以看作是嵌入TableGen语言并用来定义MLIR Op的DSL。因此ODS语法由TableGen规定,但MLIR特定的语义由ODS规定。 ODS定义最终会转换为C++代码,这些代码可以与编译系统的其余部分互操作。
MLIR使用TableGen Op类在ODS中对Op进行建模。Figure 5显示了Op 用ODS定义的示例。每个Op定义都有一个名称,该名称是唯一标识符。Op的特征(trait)列表描述了Op属性。Op的argument(参数)列表指定Op的操作数和属性。Op定义中还有一个result(结果)列表。Op的参数和结果具有名称和类型约束(例如float或int32的固定形状张量)。 Op定义还可以指定人类可读的Op描述。当Op需要定义比ODS提供的更精细的控制时,可以通过builder、printer、parser、verifier语句注入额外C++代码。Op trait可以是通用的,例如“has no side-effects”,也可以是特定于Dialect或ODS的,例如“has custom exporter”。 ODS中的traits可以由定义trait行为的C++类支持。MLIR没有固定的trait集合,但是有些trait或者optimizer(对应论文的6.1节)对ODS来说是已知的(例如,“shape result and operand type”表示对于给定输入类型完全捕获输出类型的约束)。
类型约束会检查参数/结果类型的属性,并且由用户/dialect扩展。 MLIR基础结构还提供了许多预定义的类型约束,例如“any type”、““tensor with element satisfying the given constraint”、““vector of given rank”等。ODS对自动推断操作数结果的返回类型的支持很有限,这些操作数使用了由特征带来的约束。更多信息请参见下一节(对应论文的4.2节)。

0x6.3.2 Declarative rewrites(声明式重写)¶
许多MLIR变换涉及Op操作,尽管某些变换需要对IR进行复杂的修改,但许多其它转换可以表示为对静态单赋值 use-def 关系定义DAG的简单重写。 MLIR提供了一个图重写框架,并辅以声明性重写规则(Declarative Rewrite Rule, DRR)系统,使得模式(pattern)表达变得简单。
与ODS相似,DRR是嵌入到TableGen语言中的DSL。 DRR表示源和目标DAG pattern以及约束(包括动态约束[49])并从pattern优先优先级中受益。pattern可以捕获和重用Op的参数。从概念上讲,DRR表示在特定约束下DAG的等效性。Figure 6给出了DRR模式的示例,该模式将Fiugure 5中定义的Op转换为由compare和select组成的通用低级别实现。

DRR被转换为C++代码,可以使用通用图重写框架将其与直接在C++中定义的更复杂的模式混合。通过这项功能,MLIR可以使常见用例保持简洁,且不会限制框架的通用性。
0x6.3.3 Pass Manager¶
MLIR pass管理器以各种粒度组织并处理IR pass序列,保证pass的高效执行。现有编译系统中的pass管理通常是按照固定的粒度(例如,模块、函数或循环 pass管理器)定义的。但在MLIR中,模块和函数并无特殊,它们只是具有区域的Ops,并且有多种变体。因此,MLIR pass管理器也不专门针对固定的Op集合,而是针对任意嵌套级别的任意Op。
并行编译 MLIR的一个重要需求是利用多核计算机来加快编译速度。pass管理器支持并发遍历和修改IR,这可以通过Op的“与上方隔离(isolated-from-above)”属性提供的不变量来实现,因为静态单赋值 use-def链无法跨越这些op的区域边界,因此具有这种行为的Op(例如“ std.func” Op)定义了可以并行处理的区域树。
这个需求也是MLIR不具有whole-module use-def链的原因(这与LLVM相反)。全局对象通过符号表条目进行引用,而常量则由具有关联属性的Op实现。
0x6.4.4 可相互变换的IR文本表示形式¶
MLIR中的IR和Op具有文本表示形式,可以完全反映内存中的IR表示,这对于调试、理解变换期间的IR以及编写测试用例至关重要。Figure4所示的原始IR表示冗长且难以理解,因此MLIR允许用户为Op定义定制的打印和解析格式,这使得示例可以如Figure 8所示进行打印和解析,这更容易使用。两种形式可以完全相互转换,并且可以使用文本形式作为输入和输出,分别测试每个编译器pass。由于没有隐藏状态,因此运行单个pass的结果与在完整pass pipeline中运行相同pass的结果相同。这种方法对用户友好,因为可以手动创建IR格式,并可方便跟踪IR转换。

0x6.4.5 文档¶
Dialect、Op和Interfaces都有从其对应ODS描述生成的文档。除了summary和更易读懂的description之外,生成的文档还包括参数和结果类型约束。由于验证代码和文档使用相同的来源,因此文档可以与运行时行为保持同步。
0x6.4.6 验证器¶
验证器用于增强 IR 的结构正确性和 Op 的不变性 让pass确定已验证的IR不变式是经过检查的,并且还可以用作调试工具。验证过程以MLIR总体结构属性检查开始,比如,检查类型必须完全匹配,值仅定义一次且遵守支配规则和可见性,符号名称在符号表中是唯一的,所有块均以终结符Op结尾,等等。之后,应用各个Op和属性的验证器。每个Op可以定义一组检查结构和语义有效性规则。例如,二元Op会检查是否有两个操作数,一些Op只接受特定类型的值,而一些Op需要附加特定的属性或区域。同样,Dialect属性只能在特定的Op上被允许使用,或者通过这些属性对其所附加的Op做进一步的限制。例如,Dialect属性可以要求Op仅使用Dialect中定义的类型,即使Op本身更通用。验证失败被视为invariant violation并中止编译。
0x6.5 评估:MLIR的应用¶
MLIR系统的目的是统一和驱动各种不同类型的编译器项目,因此我们的主要评估指标是展示MLIR已被哪些项目采用。本节提供了用户社区活动的简介,并详细描述了一些用例,突出说明MLIR的通用性和可扩展性,并展示MLIR如何能很好地实现定制设计原则。
目前,MLIR还是一个不断发展的开源项目,其用户社区遍布学术界和工业界。来自4个不同国家的4个国家实验室和16个大学的人士参加了在高性能计算(HPC)中使用MLIR的学术研讨会。 MLIR还得到了14家跨国公司的认可。在LLVM Developer Meeting上,超过100个业界开发人员参加了有关MLIR的圆桌会议。有超过26种dialect正在开发中,并且来自不同公司的7个项目正在用MLIR替换自定义编译器基础结构。这表明了对MLIR的真实需求,并认可了MLIR的可用性。
0x6.5.1 TensorFlow graphs¶
尽管大多数编译器开发人员也都熟悉其它表示形式,但是MLIR的关键用例之一是支持机器学习框架的开发。机器学习框架的内部表示通常基于具有动态执行语义的数据流图[53]。
TensorFlow[1]是这种框架的一个例子。TensorFlow的表示是高级数据流计算,其中的节点是可以放置在各种设备(包括特定的硬件加速器)上的各种计算过程。
TensorFlow使用MLIR对该内部表示进行建模,并针对Figure1所示的用例进行转换,将简单的代数优化转换为能在(硬件加速器的)数据中心集群上并行执行的、新形式的图,并将IR lowering为能使用XLA[57]这类工具生成高效本地代码、适合移动端部署的表示。 MLIR中的TensorFlow Graph表示如图7所示:

0x6.5.2 Polyhedral code generation 多面体代码生成¶
MLIR的最初动机之一是探索加速器的多面体代码生成。affine dialect是简化的多面体表示形式,设计目的是实现渐进式IR lowering。尽管对设计要点的全面探讨不在本文的讨论范围之内,本文还是说明了affine dialect的几个方面,以展示MLIR的建模能力,并将affine dialect与过去的一些表示形式进行了对比[17、19、54、55、52] 。
共同点¶
MLIR affine dialect可以对所有内存访问的结构化多维类型做操作 。在默认情况下,这些结构化类型是注入的(injective),保证不同的索引不会因构造而混叠,这是多面体依赖分析的常见前提。
Affine modeling可分为两个部分。属性用于在编译时对仿射图和整数集建模,而Op则用于对代码应用仿射约束。即,affine.for Op是一个“for”循环,其边界表示为值的仿射图,并且这些值要求在函数中保持不变。因此,循环具有静态控制流。与此类似,affine.if是受仿射整数集限制的条件语句。循环和条件语句的主体是区域,这些区域使用affine.load和affine.store将索引限制为循环迭代器的仿射形式。这样可以进行精确的仿射依赖分析,同时避免了从低级表示中推断仿射形式。
区别¶
MLIR与现有多面体代码生成框架之间的差异很多,可以将其分为以下四类: (1)丰富的类型:MLIR结构化的内存引用类型包含了一个将缓冲区索引空间连接到实际地址空间的布局图。这两种空间的分隔可以改善循环和数据转换的组合,因为对数据布局的修改不会影响到代码,也不会污染依赖关系分析。文献[38]已经探讨过这种转换混合,但并不常见。 (2)抽象的混合:MLIR中的仿射循环体可以通过类型化(typed )静态单赋值的Op来表示。因此,所有传统的编译器分析和转换过程仍然适用,并且可以与多面体转换交错使用。相反,多面体编译器经常将这些细节完全抽象掉,这使得多面体编译器难以操作某些对象,例如向量类型。 (3)较小的表示差异:多面体模型的主要特征之一是能够表示类型系统中循环迭代的顺序。但是,多面体转换会将IR提升为与原始IR完全不同的表示形式[20,10]。此外,从变换后的多面体到循环的转换在计算上很困难[7]。基于MLIR的表示在低级表示中保持了高级循环结构,因而不再需要提升IR。 (4)如第0x6.3.3 Pass Manager节所述,编译速度是MLIR的关键目标,但现有大多数多面体方法并不关注编译速度。这些多面体方法严重依赖指数复杂度的算法:依赖整数线性编程自动推导出循环顺序和依赖多面体扫描算法将IR转换回循环。 MLIR采用的方法不依赖多面体扫描,因为循环保留在IR中。
论文还举了一些例子用来说明MLIR在领域特定编译器的应用以及基于MLIR开发的Fortran IR,这里就不再阅读了,感兴趣的可以看下原文了解。
0x6.6 MLIR设计的成果¶
MLIR设计有助于对新语言和编译抽象进行建模,同时有助于重用现有的、通用的相关编译方法。MLIR对很多问题的有效解决方法是“添加新操作、新类型”,如果可能,将其收集到“某个新dialect”中。对于编译器工程而言,这是重大的设计转变,产生了新的机遇,挑战和见解。本节将探讨其中部分观点。
0x6.6.1 可重用的编译器Pass¶
在一个 IR 中可以表示多个抽象级别的能力自然产生了编写跨多个抽象级别工作的pass的想法。 关于MLIR的一个常见问题是,既然MLIR具有可扩展的操作和类型系统,那么如何编写编译器pass?虽然编译器pass可能总是以保守、正确的方式处理未知结构,但MLIR的目标是生成高性能代码,主要有四种方法:
基本操作特征 一些“bread and butter”编译器pass(如“死代码消除”和“通用子表达式消除”)只依赖我们定义为Op traits简单属性(例如“has no side effect”或“is commutative”)。ODS中Op的定义允许Op的开发者指定这些特征,并且pass可以使用此信息来保持操作在许多不同抽象域都适用。
MLIR的可扩展性体现为包含一些结构属性,其中包括下述信息:是否知道某个操作是控制流终止符,是否知道某个操作包含的区域是与上方隔离的(isolated-from-above)等等。这些信息可用于函数、闭包、模块和其他代码结构的建模和处理。
Privileged operation hooks(Op的特殊钩子)虽然某些特征可以用单比特建模,但是其它很多特征则需要C++代码实现,例如常量折叠逻辑。 MLIR对适用于大量pass的某些hook提供了最好的支持。这些hook可以基于每个操作实现,也可以在dialect对象中实现。后一种方法对支持诸如TensorFlow ops的常量折叠之类pass很方便,在这种情况下,很容易实现对现有逻辑的委托。
尽管常量折叠是非常重要的功能,但更有意思的hook是getCanonicalizationPatterns,这个hook允许指定应用于操作的折叠模式。这使得重要的代数简化形式(例如x − x→0,min(x,y,y)→min(x,y)等)具有可扩展性,并可帮助将普通“规范化(Canonicalization)”pass应用到所有dialect 。这些都使得单一的可扩展系统可以包含像“InstCombine”、“DAGCombine”、“PeepholeOptimizer”、“SILCombine”这类pass,以及LLVM生态系统(和其它编译器)中的其它特殊用途pass。
Optimization interfaces (优化接口) MLIR的主要目标是可扩展性,不仅在Op和类型方面,而且在转换方面也要有可扩展性。虽然规范化(canonicalization)和常量折叠是关键操作,但仍需要以某些方式对许多标准转换进行参数化设置,才能描述转换的特定属性,才能实现代码模型等。
问题的解决方案是称为“优化接口”的子系统。考虑一下MLIR内联pass,我们希望inliner可以处理TensorFlow图、Flang函数、函数语言的闭包等,但是inliner不知道调用方是什么,甚至不知道被调用方是什么。inliner需要了解的核心特性是:
- 将给定操作内联到给定区域是否有效;
- 如何处理内联后终止于块中间的终止符操作。
为了了解这些属性,Inliner pass定义了Figure 10中的接口。各个操作和dialect可以向MLIR注册该接口在操作和dialect中的实现,并从通用的Innerer pass中获益。如果某个操作或dialect没有提供接口,则相应的优化pass将会保守地对待该操作。这种设计让dialect的开发者能快速启动开发并运行dialect。随着时间的推移,通过将更多的精力投入到接口的开发,可以从系统中获得更多收益。

优化接口还为核心编译器提供了模块化优势,因为dialect特定的逻辑是在dialect自身内部实现,而不是在核心转换中实现。
Dialect特定pass 最后,定义特定dialect可以定义专用pass,MLIR系统中的这些pass和在其它编译器系统中的pass一样都很有用。比如说,如果想让代码生成器根据特定的机器约束对机器指令进行自定义调度,就可以通过专用pass达到目的。这可当作开发新转换pass的起点,不需要考虑pass的通用性。
0x6.6.2 Dialect的混合¶
MLIR中一个最根本(也是最难理解)的部分是允许并鼓励将来自不同dialect的操作混合在一个程序中。尽管在某些情况下(例如,将主机和加速器的计算保存在同一模块中),这样做很容易理解,但最有趣的情况是,在MLIR中可以将dialect直接混合(因为这样可以实现整个类的重用),这在其它系统中是见不到的。
考虑第0x6.5.2节中描述的affine dialect。affine控制流和affine映射的定义与affine区域中包含的操作的语义无关。在我们的案例中,我们将affine dialect与“standard” dialect结合起来,以目标无关的形式(如同LLVM IR)表示简单算术,也可以针对内部加速器,将affine dialect与多个目标相关机器指令dialect结合。也有人将affine dialect与其它问题领域的抽象相结合。
重用通用多面体变换(使用Op Interface获取特定转换中操作的语义)的能力是分解编译器基础结构的一种有力方法。另一个例子是,可以在各种源语言IR中使用和重用OpenMP dialect。
0x6.6.3 互操作性¶
本文的工作涉及与大量现有系统的互操作,例如,protobuff格式的机器学习graphs、包括LLVM IR在内的编译器IR、各种专有指令集等。任何一种表示形式不可避免都有各种缺陷,虽然这些缺陷在某个现有系统的适用场景下是合理的,但是MLIR的表达能力使MLIR成为一种更好的表示形式。因为importer和exporters的测试难度很大(测试用例通常是二进制格式),因此我们希望确保其复杂性最低。
问题的解决方案是尽可能定义与外部系统直接相对应的dialect,从而能以一种简单且可预测的方式来回转换该格式。一旦将IR导入MLIR格式中,就可以使用MLIR基础结构中所有转换,将导入的IR升级或降级为某种更适合的IR格式,并允许对这些转换pass进行类似于所有其它MLIR pass的测试。
这类dialect的例子很多,包括:a)LLVM dialect,可将LLVM IR映射为MLIR; b)TensorFlow的图表示形式,提出这种表示是为了简化TensorFlow中“切换和合并(switch and merge)”节点相关的分析和转换;c )函数式控制流运算符。“functional while”和“functional if”在机器学习图中很常见,在这种情况下,将其代码主体作为区域而不是外联(out-of-line)函数更方便。
这种方法对我们来说效果很好,并且MLIR工具对于编写外来二进制文件格式的测试用例也很有用。
0x6.6.4 非标准化设计带来了新挑战¶
虽然MLIR允许开发者定义几乎任意的抽象,但MLIR也几乎没有提供相关指导,比如,在实践中哪种方法效果更好或更差?现在,一些工程师和研究人员已经有这方面的经验,并且已经意识到,编译器IR设计和抽象设计的“艺术”在编译器和语言领域并未得到很好的理解。许多人在已建立系统的约束下工作,但是相对而言,很少人有机会自己定义抽象。
这是一个挑战,但也是未来研究的机遇。MLIR社区正在通过这些抽象设计积累专业知识,随着时间的推移,这将是一个硕果累累的研究领域。
0x6.6.5 期望¶
在构建并将MLIR应用于许多不同的系统之后,可以发现MLIR的设计与其它编译器基础结构有很大不同。我们相信仍有很多应用领域有待发现,完全理解MLIR所有设计要点并建立最佳实践,需要更多的研究时间。例如,out-of-tree dialect的兴起、前端使用MLIR的源语言数量的增加、在抽象语法树上的可能应用,以及对结构化数据(如JSON,协议缓冲区等)的应用,这些都还处于很早期,可能会从中发现许多有趣的新挑战和机遇。
0x7. 评论(以OneFlow Dialect为例)¶
以上就是MLIR论文的大致内容。把MLIR论文中的提到的组件画成一张思维导图大概为:
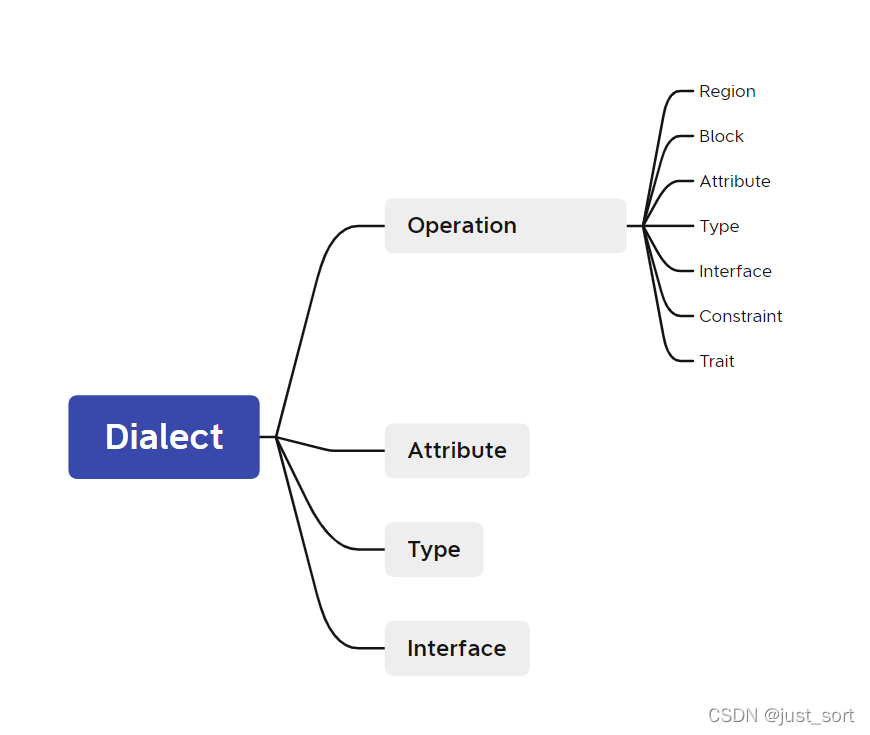
下面我以OneFlow Dialect为例来讲解这张图。
正如论文提到的,在MLIR中Operation是MLIR的一个基本语意单位。定义了一个新的Dialect后我们首先就要考虑Operation的定义,要定义Operation必须先定义Attribute和Type。OneFlow Dialect的定义在oneflow/ir/include/OneFlow/OneFlowDialect.td这个文件中,它基于ODS规则设置了description,cppNamespce等关键信息,然后依靠mlir-tblgen可执行文件(MLIR提供)自动生成了OneFlow Dialect的C++代码。
def OneFlow_Dialect : Dialect {
let name = "oneflow";
let summary = "OneFlow MLIR dialect.";
let description = [{
This dialect is the IR of OneFlow.
}];
let cppNamespace = "::mlir::oneflow";
let dependentDialects = [
"StandardOpsDialect"
];
}
然后Type的定义在oneflow/ir/include/OneFlow/OneFlowBase.td和oneflow/ir/include/OneFlow/OneFlowEnums.td这两个文件中,分别对OneFlow的Tensor类型以及后续Operation指定Attribute需要的Type进行定义,需要说明的是OneFlow的Operation定义中除了下面定义的Type类型还大量使用了MLIR中提供的基础Type:
def OneFlow_Tensor : TensorOf<[AnyType]>;
def SI32ArrayAttr : TypedArrayAttrBase<SI32Attr, "signed 32-bit integer array attribute"> {}
def SI64ArrayAttr : TypedArrayAttrBase<SI64Attr, "signed 64-bit integer array attribute"> {}
def ShapeAttr : TypedArrayAttrBase<SI64Attr, ""> {}
...
Attribute的定义在每个Operation定义中,使用let attrs=来指定。下面以LeakyReLU为例看一下OneFlow Dialect的Operation定义(在oneflow/ir/include/OneFlow/OneFlowUserOps.td):
def OneFlow_LeakyReluOp : OneFlow_BaseOp<"leaky_relu", [NoSideEffect, DeclareOpInterfaceMethods<UserOpCompatibleInterface>]> {
let input = (ins
OneFlow_Tensor:$x
);
let output = (outs
OneFlow_Tensor:$y
);
let attrs = (ins
DefaultValuedAttr<F32Attr, "0.">:$alpha
);
let has_logical_tensor_desc_infer_fn = 1;
let has_physical_tensor_desc_infer_fn = 1;
let has_get_sbp_fn = 1;
let has_data_type_infer_fn = 1;
}
可以看到OneFlow_LeakyReluOp继承了OneFlow_BaseOp,并声明了输入输出和Attribute,最下面的4个标记是OneFlow在llvm的table-gen上做的一点扩展方便自动生成Op一些信息推导的接口这里可以不关心。
上面讲到了Attribute,Type和Interface,接下来我们讲一讲OneFlow Dialect中Operation的Trait和Constrait。在MLIR中Trait(特征)和Constrait(约束)的基类为OpTrait类,特征和约束通常用来指定Operation的特殊属性和约束,比如Operation是否具有副作用,Op的输出是否与输入是否具有相同的形状等。
在OneFlow的Operation定义中不仅使用了MLIR提供的特征如Leaky-ReLU中的 NoSideEffect,还自定义了特征如IsOpConfCompatible。在oneflow/ir/include/OneFlow/OneFlowBase.td中def OneFlow_IsOpConfCompatible : NativeOpTrait<"IsOpConfCompatible">;的这句话就是使用MLIR提供的ODS方法NativeOpTrait声明了一个自定义的特征用来检查OneFlow Dialect定义的Op是否有某些共用属性例如OpName,DeviceDagAttr等等。这里只是在ODS中声明了自定义的属性,它真正定义在oneflow/ir/include/OneFlow/OneFlowOpTraits.h。这里简单摘出来看一下:
template<typename ConcreteType>
class IsOpConfCompatible : public TraitBase<ConcreteType, IsOpConfCompatible> {
public:
static StringRef getOpNameAttr() { return "op_name"; }
static StringRef getDeviceTagAttr() { return "device_tag"; }
static StringRef getDeviceNameAttr() { return "device_name"; }
static StringRef getScopeSymbolIDAttr() { return "scope_symbol_id"; }
static StringRef getHierarchyAttr() { return "hierarchy"; }
static LogicalResult verifyTrait(Operation* op) { return impl::VerifyIsOpConfCompatible(op); }
};
LogicalResult VerifyIsOpConfCompatible(Operation* op) {
for (auto attr : {
IsOpConfCompatible<void>::getOpNameAttr(),
IsOpConfCompatible<void>::getDeviceTagAttr(),
}) {
if (!op->hasAttrOfType<StringAttr>(attr)) {
return op->emitError("expected operation to have attribute: " + attr);
}
}
if (!op->hasAttrOfType<ArrayAttr>(IsOpConfCompatible<void>::getDeviceNameAttr())) {
return op->emitError("expected operation to have attribute: "
+ IsOpConfCompatible<void>::getDeviceNameAttr());
}
return success();
}
除了Trait之外,OneFlow还使用了MLIR提供的一些特征如SameOperandsAndResultType。在oneflow/ir/include/OneFlow/OneFlowBase.td的OneFlow_UnaryBaseOp定义这里:
class OneFlow_UnaryBaseOp<string mnemonic, list<Trait> traits = []> :
OneFlow_BaseOp<mnemonic, !listconcat(traits, [SameOperandsAndResultType, NoSideEffect])> {
let summary = "";
let input = (ins AnyType:$x);
let output = (outs AnyType:$y);
let has_logical_tensor_desc_infer_fn = 1;
let has_physical_tensor_desc_infer_fn = 1;
let has_get_sbp_fn = 1;
let has_data_type_infer_fn = 1;
}
这个特征表达的意思就是继承了UnaryBaseOp的Operation的操作数和结果的类型都是相同的。当然特征也可以和约束一样自定义,也是用NativeOpTrait在td文件中指明,然后实现也在oneflow/ir/include/OneFlow/OneFlowOpTraits.h。
经过上面的讲解,相信大家对MLIR里面的Type,Attribute,Operation,Trait,Constrait都有所认识了。接下来我们要说一说Interfaces,Interfaces可以翻译成接口,MLIR的Interfaces提供了和IR交互的通用方式。Interfaces的设计目标是可以不用侵入到具体某个Dialect下的特定Operation和Dialect的特定知识就达到可以转换和分析MLIR表达式。这样就可以将转换,分析和新增一个Dialect和对应的Operation 进行解耦,大大增强MLIR的可扩展性。为了说明Interfaces的重要性,我再这个专题实际上结合官方文档专门写了一篇文章来介绍,可以参考:【从零开始学深度学习编译器】十八,MLIR中的Interfaces。
在OneFlow中,各个自定的Interfaces在oneflow/ir/include/OneFlow/OneFlowInterfaces.td这里。我们以UserOpCompatibleInterface为例来看一下Interface的具体实现:
def UserOpCompatibleInterface : OpInterface<"UserOpCompatible"> {
let description = [{
Interface to getting the hard-coded bn
}];
let methods = [
StaticInterfaceMethod<"",
"const std::vector<std::string>*", "inputKeys", (ins), [{
static std::vector<std::string> val(mlir::oneflow::support::GetInputKeys(ConcreteOp::getOperationName().split('.').second.str()));
return &val;
}]>,
StaticInterfaceMethod<"",
"const std::vector<std::string>*", "outputKeys", (ins), [{
static std::vector<std::string> val(mlir::oneflow::support::GetOutputKeys(ConcreteOp::getOperationName().split('.').second.str()));
return &val;
}]>,
InterfaceMethod<"",
"std::pair<unsigned, unsigned>", "getODSOperandIndexAndLength", (ins "unsigned":$index), [{
return $_op.getODSOperandIndexAndLength(index);
}]>,
InterfaceMethod<"",
"std::pair<unsigned, unsigned>", "getODSResultIndexAndLength", (ins "unsigned":$index), [{
return $_op.getODSResultIndexAndLength(index);
}]>
];
}
可以看到UserOpCompatibleInterface使用了Interface ODS规范中的StaticInterfaceMethod和InterfaceMethod为这个Interface指定了获取Operation输入操作数名字,输出操作数名字,操作数以及长度,结果以及长度等方法。然后在OneFlow的oneflow/ir/include/OneFlow/OneFlowUserOps.td中使用DeclareOpInterfaceMethods<UserOpCompatibleInterface>来将其指定为Operation层次的Interface,在生成的Operation代码中就会带上这个Interface声明。
那么这样做有什么好处吗?第一点就是由于OneFlow的UserOp都带上了UserOpCompatibleInterface,只要我们为OneFlow的UserOp实现一个通用的GetInputKeys函数,那么所有UserOp派生出来的Operation都拥有了这个函数的功能,因为它们都带上了UserOpCompatibleInterface这个接口。
关于Interface更加通用和经典的一个例子是基于Interface来开发一些通用pass,比如内联和形状推导pass,这个属于Dialect层次的Interface应用。具体见【从零开始学深度学习编译器】十三,如何在MLIR里面写Pass?
思维导图中还剩下Block和Region没有讲了,实际上MLIR论文中对Region和Block的解释我觉得已经到位了。一个Op会附加一系列Region,Region为MLIR的嵌套结构提供了实现机制:一个Operation有一系列Region,然后Region又是由一系列Block组成,然后Block又包含一系列Op。这样就形成了一个嵌套的关系,可以表达作用域和控制流关系。在OneFlow的Dialect中对Region和Block的应用目前主要是在函数相关的语意中,例如在oneflow/ir/lib/OneFlow/Passes.cpp里面实现了一个OutlineMulCast的Pass可以将IR中指令的op模式外联到一个FuncOp类型的Operation中进行执行,就使用到了Block来确定这个FuncOp要插入到IR中的位置。再举一个例子,要访问FuncOp的参数时也需要用到Block,如oneflow/ir/lib/OneFlow/OneFlowOps.cpp里为Job Op实现了一个verify函数,来验证函数的参数列表和入口Block的参数列表是否对齐:
static LogicalResult verify(Job op) {
// If this function is external there is nothing to do.
if (op.isExternal()) return success();
// Verify that the argument list of the function and the arg list of the entry
// block line up. The trait already verified that the number of arguments is
// the same between the signature and the block.
auto fnInputTypes = op.getType().getInputs();
Block& entryBlock = op.front();
for (unsigned i = 0, e = entryBlock.getNumArguments(); i != e; ++i)
if (fnInputTypes[i] != entryBlock.getArgument(i).getType())
return op.emitOpError("type of entry block argument #")
<< i << '(' << entryBlock.getArgument(i).getType()
<< ") must match the type of the corresponding argument in "
<< "function signature(" << fnInputTypes[i] << ')';
return success();
}
我们在Job这个Op的定义也可以发现,它通过let regions = (region AnyRegion:$body);绑定一个名为body的Region,所以上面verify函数中访问FuncOp的Block时隐式访问了Block对应的Region,即将op.front()改成op.body().front()是等价的效果。
Region和Block相当于MLIR中的作用域,可以通过它们来实现MLI中复杂结构的控制流关系,并且将普通Op和FuncOp,ModuleOp区分开,实现在MLIR中Operation统一性原则。
至于OneFlow Dialect中涉及到的Pass机制我在以OneFlow为例探索MLIR的实际开发流程 这里已经介绍过了,这里暂时不重复写了。
总的来说MLIR是一个可重用、可扩展性都比较好的编译基础设施,至少从工程开发的角度来看是值得跟进的。这部分我介绍了OneFlow Dialect中的各种组件以及它们的关系,但还没有介绍OneFlow Dialect和其它各种Dialect的关系,以及目前Dialect的lowering流程。实际上MLIR还有相当多的技术细节需要深入研究和学习,所以这里主要起到一个小结和启发的作用。
0x8. 相关参考文章¶
本文参考了https://arxiv.org/pdf/2002.11054.pdf MLIR原论文和这篇https://zhuanlan.zhihu.com/p/336543238翻译。
本文总阅读量次