[GaintPandaCV导语]
传统的卷积神经网络基本都是乘法密集型运算堆叠起来的,而无论哪种硬件实现这些乘法运算都需要消耗大量的能量和计算资源,同时使得运行的延时无法显著降低,如何用更廉价的操作来代替乘法运算也成为模型加速比较火的方向。前段时间有两篇华为联合出品的神经网络高效计算的论文AdderNet和DeepShift很有意思,主要想法都是研究如何用更廉价的运算来代替神经网络中昂贵密集的乘法运算,如加法或者移位+符号位翻转,鉴于我们课题组也是主要做的AI加速方面的工作,所以仔细阅读了论文,想看看其中端倪,并尝试获得一些启发。
论文链接:
- AdderNet(
https://arxiv.org/pdf/1912.13200.pdf)。 - DeepShift(
https://arxiv.org/abs/1905.13298)。
代码链接:
- AdderNet(
https://github.com/huawei-noah/AdderNet)。 - DeepShift(
https://github.com/mostafaelhoushi/DeepShift)。
1. AdderNet¶
1.1 原理介绍¶
目前深度神经网络中广泛使用的卷积是互相关的计算,用来测量输入特征和卷积滤波器之间的相似性,虽然有效,但涉及大量的浮点乘法运算:
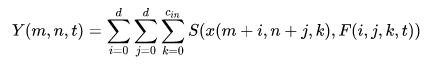
其中S()是相似性度量函数, 输入 R^{H\times W\times C_{in}} 权重 R^{d\times d\times C_{in}\times C_{out}} 输出 R^{H^{'} \times W^{'}\times C_{out}}
本文针对这点提出了一个新的基于加法的相似度计算方法,即将输入特征和卷积滤波器之间的L1范数距离作为相似性的度量:
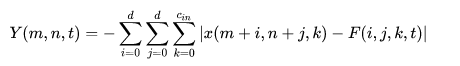
考虑到正常卷积的运算输出值是有正有负的,而本文的L1范数是取两个值之差的绝对值的负数,只能输出非正值,因此为了考虑激活函数的使用以及与传统输出范围的统一,这里使用Batch Normalization来进行规范化的操作,将输出调整至合适范围,那么这里大家就比较疑惑了?说好的没有乘法呢?Batch Normalization是不可能避免乘除法的,论文的解释是传统卷积神经网络中,卷积部分的计算复杂度是O(d^2C_{in}C_{out}HW),而BN的计算复杂度是O(C_{out}H^{'}W^{'}),两者差距比较大,BN的乘法运算相比于卷积而言几乎可以忽略,这个意思就是说本文我只取代调卷积部分的乘法,其他部分的乘法我还是需要继续使用的,但这么回头看看题目,感觉过于扎眼。
然后为了保证这种度量方式能够有效地学习到数据的特征,作者又特地改进了BP的计算方式:
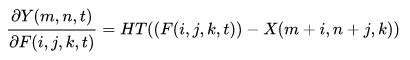
其中HT()是HardTanh函数:
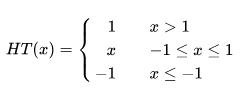
并且考虑到不同层的学习情况不同,设计了自适应学习率的方法,第l层的学习率:
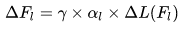
其中γ是全局的学习率,\alpha_{l}=\frac{\eta \sqrt{k}}{||\Delta L(F_l)||_2} 是第l层局部的学习率,第三项是第l层的梯度。
1.2 训练流程¶

最后一句"with almost no multiplication"这句话的说法感觉还需要商榷,BN的运算量是固定的,相比于正常的卷积运算来说确实很小,但是将卷积中的乘法替换成L1范数计算后,BN的ops在整个AdderNet网络中是否还是占少数,如果还是占少数的话那么说"with almost no multiplication"还挺可信,但是据我了解,加法相对于乘法占用的计算资源是小很多的,所以作者应该在这块再给个证明。
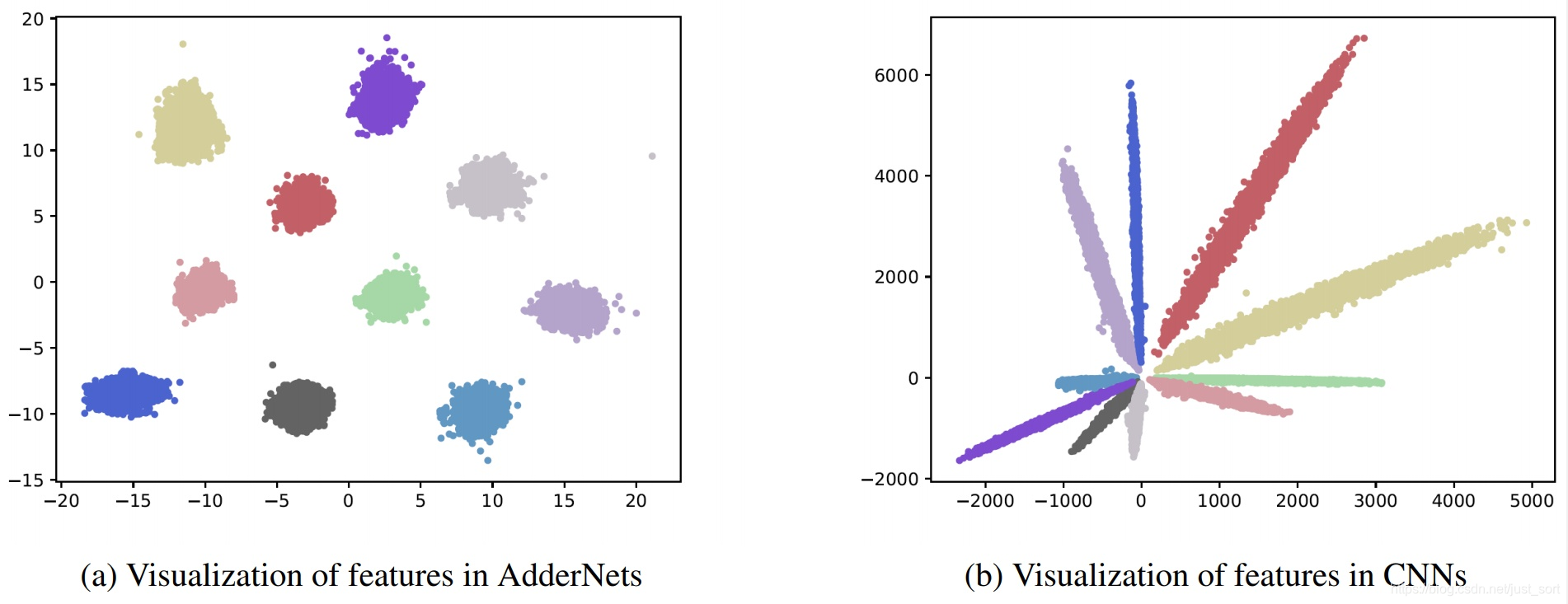
最后作者还基于MNIST数据集(10分类)对传统卷积神经网络和本文的AdderNet的特征进行了可视化,结果表明CNNs这张计算输入与滤波器之间互相关的方式,卷积操作相当于在求两者的余弦距离(输入和滤波器都进行归一化的情况下),所以分类结果是以角度进行划分的,而AdderNet这张基于L1范数的相似度计算方式表现为聚类的效果。
1.3 疑问¶
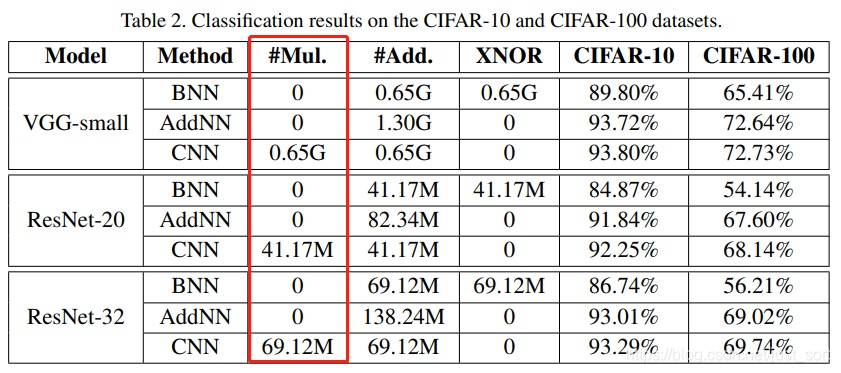
- 这篇文章其实主要思想还是用加法来代替卷积/全连接中的乘法运算,但是在Batch Normalization,或者一些特殊激活函数这块其实仍然还存在一部分乘法操作,而这些操作最后在实验结果呈现这块也都一起忽略掉,有种搞噱头的嫌疑;
-
相同数量的乘法和加法在实际硬件中的运行速度其实是不一样的,但是针对卷积运算特定设计的硬件同样也是跑的很快的,其实乍一看这篇论文,我们第一感觉都会认为AdderNet可以大大加速模型前向推断的过程,但本文的实验部分只是在CPU上进行了实验,而且Latency:AdderNet 1.7M vs CNN 2.6M 感觉没有想象中快了很多嘛,而且GPU部分一句Cudnn没有优化该部分所以未进行实际推断时间的比较就给忽略了,说明他们做了实验结果是差不多的,实在拿不出手就不加这个了,所以感觉还需要更多实际硬件部署的实验来论证用加法取代大部分的乘法是真正可以推动模型加速的;
-
可视化相关实验中的说法感觉过于主观,特征可视化->余弦距离/聚类没有数学上的解释,只是肉眼观察的结果,CNNs和AdderNet训练后滤波器的可视化文章说similar,都是小尺寸的灰度图,肉眼看上去其实并没有什么感觉,你说similar就similar?
-
本文是运算加速,实际的模型参数量并丝毫没有减少,且实验对比的都是本身冗余较大的VGG和ResNet网络,那么如果对AdderNet进行轻量化设计或者模型压缩/量化的话,对性能影响如何,这其实也是AdderNet模型能力验证的一个方面;
2. DeepShift¶
2.1 原理¶
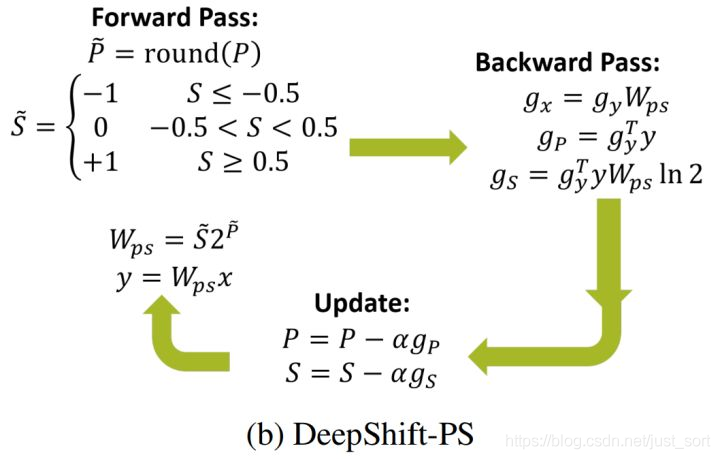
这篇文章也是针对传统CNNs中大量密集的乘法运算带来的高计算消耗和能量消耗的问题,考虑用逐点移位和标志位翻转来代替乘法操作,移位操作代替绝对值乘法运算,标志位翻转代替正负符号运算,并且提出了两种不同的训练方式DeepShift-Q和DeepShift-PS。在硬件电路中移位和标志位01翻转是相对于加法更简单的操作,所以对于模型加速也是很有意义的。
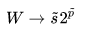
其中:
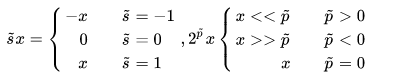
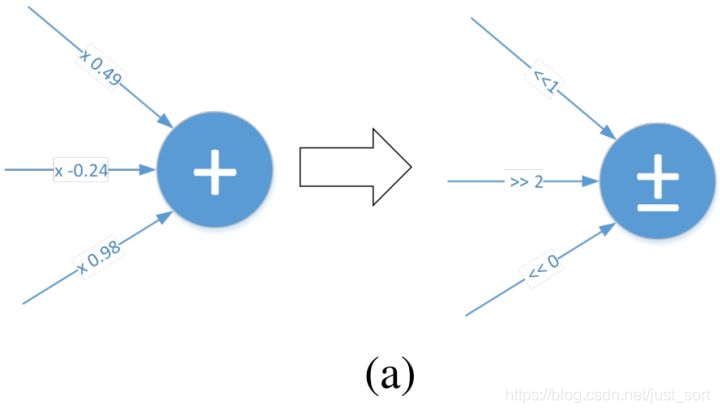
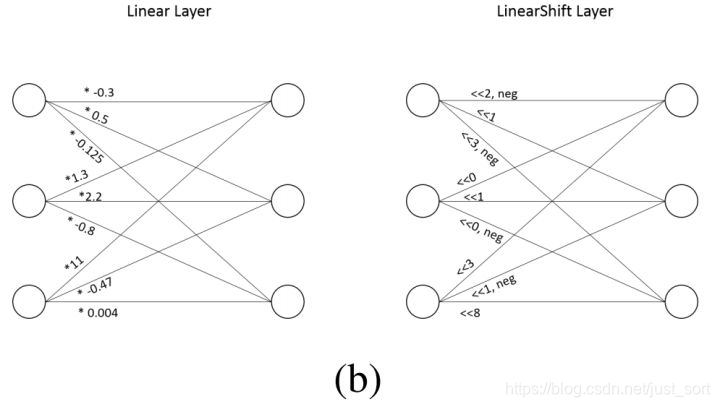
2.2 训练方法一:DeepShift-Q¶
训练方法和训练常规的CNN相同,只是权重矩阵被round到最近的2的次幂上
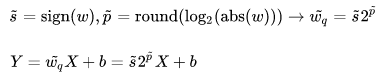
然后梯度更新方式也同时进行一些修改,并且设定round函数的梯度为1
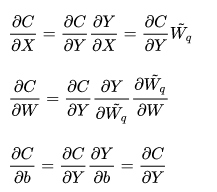
这里的训练参数仍然是原始的W和b,只是在实际运行的时候会round到附近的2的次幂值上,所以和之前的网络比差异不是特别大,很容易理解,我在做8bit量化的时候也经常这么干。

2.3 训练方法二:DeepShift-PS¶
区别于DeepShift-Q的方法,DeepShift-PS直接使用p和s用于训练参数更新
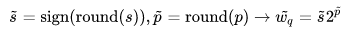
其中
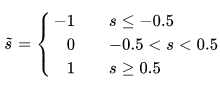
且设置\overline{s}对s的梯度为1。
梯度更新的计算公式为:
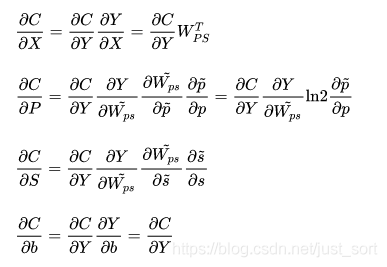
同样其中遇到sign()函数和round函数的梯度都设为1。
2.4 实验¶
DeepShift-Q和DeepShift-PS的训练流程和正常的CNNs的训练方式相同,只是参数和梯度更新计算公式需要根据设定的来,实验中同样将权重加入loss作为L2正则化项,对于DeepShift-PS,\sum W_{ps}^2=\sum 2^p s^2,而非\sum p^2+\sum s^2,本文实验比较充分,既在CPU上实验,也特定设计了一个GPU的计算核,并且对比实验做的很充分。
2.5 疑问¶
- 我们可知,2的次幂数,在小于1的情况下比较密集,但是当值越来越大的时候就越来越稀疏,比如2, 4, 8 16……,这样的话DeepShift-Q对w的近似误差就越来越大,是否合适?
- 梯度近似计算中,round()函数和sign()函数本身不可导,本文将他们的梯度设为1,round函数在x较大的时候是合理且误差较小的,在值较小时误差也是1以内,但是DeepShift-PS方法中s的梯度计算 s=\begin{cases} -1 & s<=-0.5 \\ 0 & -0.5 < s < 0.5 \\ 1 & s >= 0.5 \end{cases} 在s较大时误差较大,在s较小时误差相对小,但是当属于[-1,1]时,-1,0和1的区间大小又不一样,偏向于0的区间显然更大。所以这种梯度近似的方法是不是有些粗糙。
- 和第一篇相同,本文实验也是基于经典冗余网络VGG和ResNet进行的,结果是精度损失很小或甚至有超过原始网络的,那么这种方法进行轻量级设计会同样有效吗?
- DeepShift权重都用移位值和正负标志位来表示,那么在实际参数存储中应该会大幅度降低,因为单纯存移位值的话权重的每个值可能5-8bit就完全够用了,而标志位也就是1bit,相对于原先的32bit是巨大的优势,为何没有作为重点讲一下?
- 每一层是否进行了Batch Normalization的操作,就是说实际的网络运算消耗只有bitwise shift、sign flipping和add吗?shift+sign flip相对于乘法操作运算量降低了很多,但最终在优化的GPU核上只快了25%,是不是有其他计算瓶颈?当然后面说了代码还会继续优化,一些GPU指令还不是很适合这种设计,希望作者继续加油!
2.6 启发¶
乘法是目前通用的深度神经网络设计中不可或缺的一部分,但同样也是由于大量密集的乘法运算,使得算法模型在嵌入式/移动端设备上很难部署,而加法在硬件中几乎是最廉价的计算之一了,如何利用加法,移位,标志位翻转、与或非位运算等廉价操作来代替神经网络中的乘法操作还是可以进一步进行探究的。并且这些廉价操作的替换同时也会带来训练上的复杂性——梯度、优化器、学习率需要重新设计,毕竟牵一发而动全身,各个环节都需要小心翼翼。
同时考虑到模型落地应用的话,参数量的压缩是一个很重要的方面,模型落地有两个大的角度:轻量化网络设计(KD暂时纳入其中)和模型压缩/量化。轻量化网络的设计需要网络本身有强大的表征能力,基于乘法运算的CNNs已经被证明是有这样的能力的,如SqueezeNet,ShuffleNet和MobileNet,这两篇论文实验都是VGG和ResNet这中本身冗余性比较大的网络,那么能否推广到更轻量级的网络,使得保持学习能力的同时还能减少模型参数量,或者能否在训练好的基础上进一步进行参数的压缩或量化。如果像AdderNet和DeepShift这种基于廉价操作的方法既可以减少了参数量又降低了运算所需的ops,我想NVIDIA应该会第一时间去更新他的cudnn吧,因为这是非常具有革命性的,说明基于加法或移位+标志位翻转的模型具有强大的学习能力,可以完全取代传统的CNNs。
所以我认为此类方法的进一步研究是:
- 模型表达能力的验证,可以进行轻量化设计或者推广到检测分割任务;
- 模型在硬件中的落地应用实践,特定或通用硬件的优化,模型参数的压缩/量化,来证明可以在真实硬件中大幅度提速;
以上就是我对这两篇论文的解读和拙见,希望有兴趣的读者读完原论文的可以私下继续交流一下。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次