EagleEye:一种用模型剪枝的快速衡量子网络性能的方法
[GiantPandaCV导语]:模型剪枝算法核心在于找到“不重要”的参数并且实现裁剪。为寻找到较优的剪枝策略,我们往往需要尝试多种剪枝策略和剪枝策略性能评估。通常剪枝策略评估方法是将剪枝后的模型训练到收敛或者训练规定好数量epoch后进行性能比较。不管是人工调试剪枝策略还是自动搜索剪枝策略,都需要多次评估剪枝策略。剪枝策略的评估效率一定程度上影响了整体压缩效率。因此,本文提出了一种能够快速衡量剪枝后模型性能的方法,经实验能够对MobilenetV1减少50%的FLOPs情况下,仍能保证在Imagenet数据集上Top1精度达到70.9%。
论文链接:https://arxiv.org/abs/2007.02491
论文repo:https://github.com/anonymous47823493/EagleEye
引言¶
随着AI技术的发展,人们对于AI的需求也越发多样化。在手机端、嵌入式设备上部署模型的需求已经十分普遍。一般移动端、嵌入式设备无法满足神经网络的计算需求。因此,我们一般需要利用模型压缩技术,尽量不影响模型性能的前提下,减少模型的参数量和计算量,使其满足硬件的限制。
- 将剪枝后模型训练至收敛后,评估网络性能。
- 将剪枝后模型训练规定数量epoch后,评估网络性能。
- 直接对剪枝后的模型评估性能
当需要进行多次迭代尝试时,前两种方法所需要的时间成本都很较大,第三种办法常常面临不准确的问题。因此,EagleEye提出一种快速并且准确衡量子网络性能的方法,加快剪枝的过程。
EagleEye¶
动机
传统模型剪枝的三步流程是:模型预训练、模型剪枝和finetuning。为什么会需要finetuning这个环节呢?因为剪枝后模型精度下降比较明显,finetuning能够有效提升剪枝后模型精度。EagleEye论文中,对这一现象提出了两个问题:
- 裁剪的权重通常被认为是“不重要”的权重,为什么模型精度还会有如此大的下降?
- 未进行finetuning的模型精度和finetuning收敛后的模型精度是否成存在正相关?
针对这两个问题,EagleNet论文中进行了研究和实验。如下图,右图主要展示了在finetuning过程中模型权重的变化情况,其中x轴表示卷积核的L1范数大小,y轴表示卷积核数量,z轴表示不同epoch下权重分布情况。在finetuning过程中,权重分布只发生了一点偏移,但是finetuning前后模型性能发生巨大变化。
在左图中,我们可以看出finetuning前后的模型性能分布差别较大,finetuning前后模型的精度没有较强的正相关

那么问题的答案是什么呢?EagleNet论文认为是网络中的BN层对于模型的精度评估有较强的影响。在没有进行finetuning的模型,模型的BN层参数继承于原模型,和当前模型的权重参数并不match,影响了模型的精度,并且导致finetuning前后模型精度不成正相关的问题在finetuning的过程,模型的精度逐渐在上升,是因为其参数在逐渐被优化,BN层的参数也在逐渐“适应”新的网络结构。但是这种方法并不高效,因此论文中引出Adaptive Batch Normalization结构,解决这个问题。
Adaptive Batch Normalization
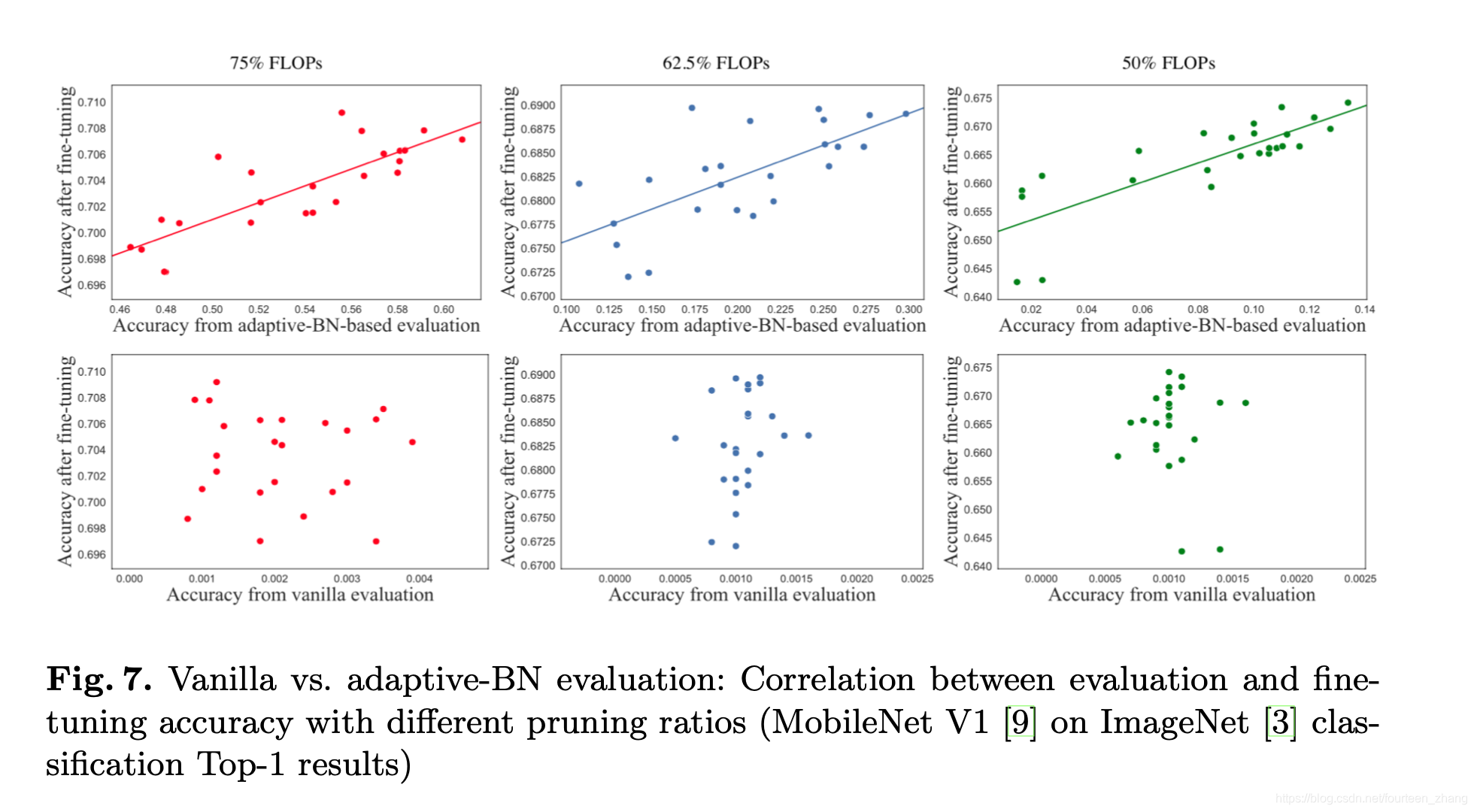
Adaptive Batch Normalization方法是非常的朴素,论文提出的思路是将网络中的其他参数冻住,然后利用训练集(不是测试集)的样本进行前向计算,修正“继承”来的BN层参数。Adaptive Batch Normalization的方法效果对比图如下:

图中横纵坐标分别是finetuning前后模型的精度。其中,左图是没有采用Adpative BN的finetuning模型前后的模型精度关系,右图则是使用adpative BN之后的表现,可以看出成比较明显的正相关。
工作流程¶
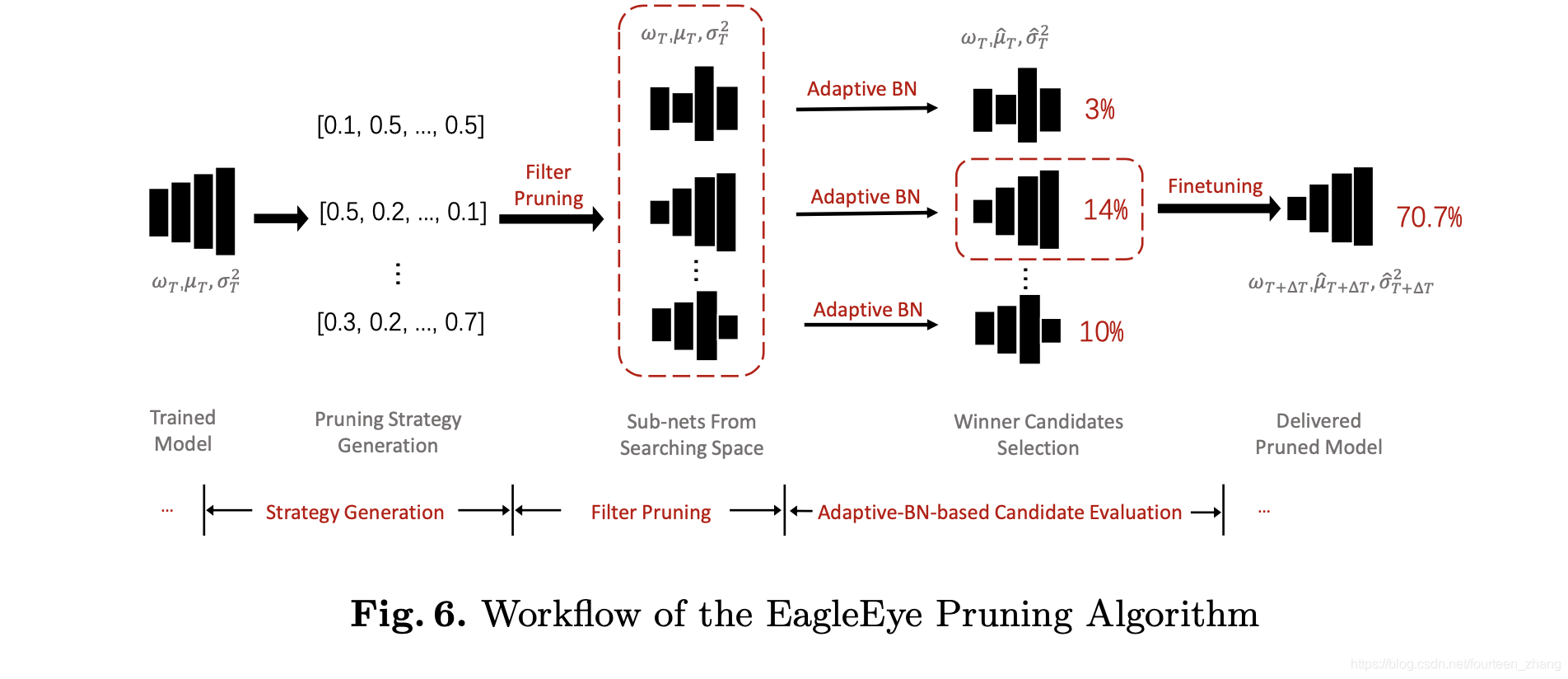
EagleEye的核心点在于利用Adaptive BN方法,一定程度上解决了传统剪枝工作流下,finetuning前后模型精度弱相关的问题。Finetuning前后模型精度具备强相关性的话,我们就能省去传统finetuning的过程,极大的加速整个迭代流程。
EagleEye的整体工作流程如下:
- 采用随机策略生成大量的剪枝方案
- 对于不同的剪枝策略,修正其BN层参数
- 对于不同的剪枝策略,衡量其剪枝策略的精度,并且选取最优的剪枝策略。
- 对于最优的剪枝策略进行finetuning,精度恢复。
实验效果¶
- 相似性实验
论文中进行了更为详细的相似性实验,其中分别是在不同FLOPs限制的剪枝策略前提下,Adaptive BN方法效果的对比图。从实验结果,我们可以看出其方法在多种FLOPs限制下,都保持了较好的效果。
- 对比实验
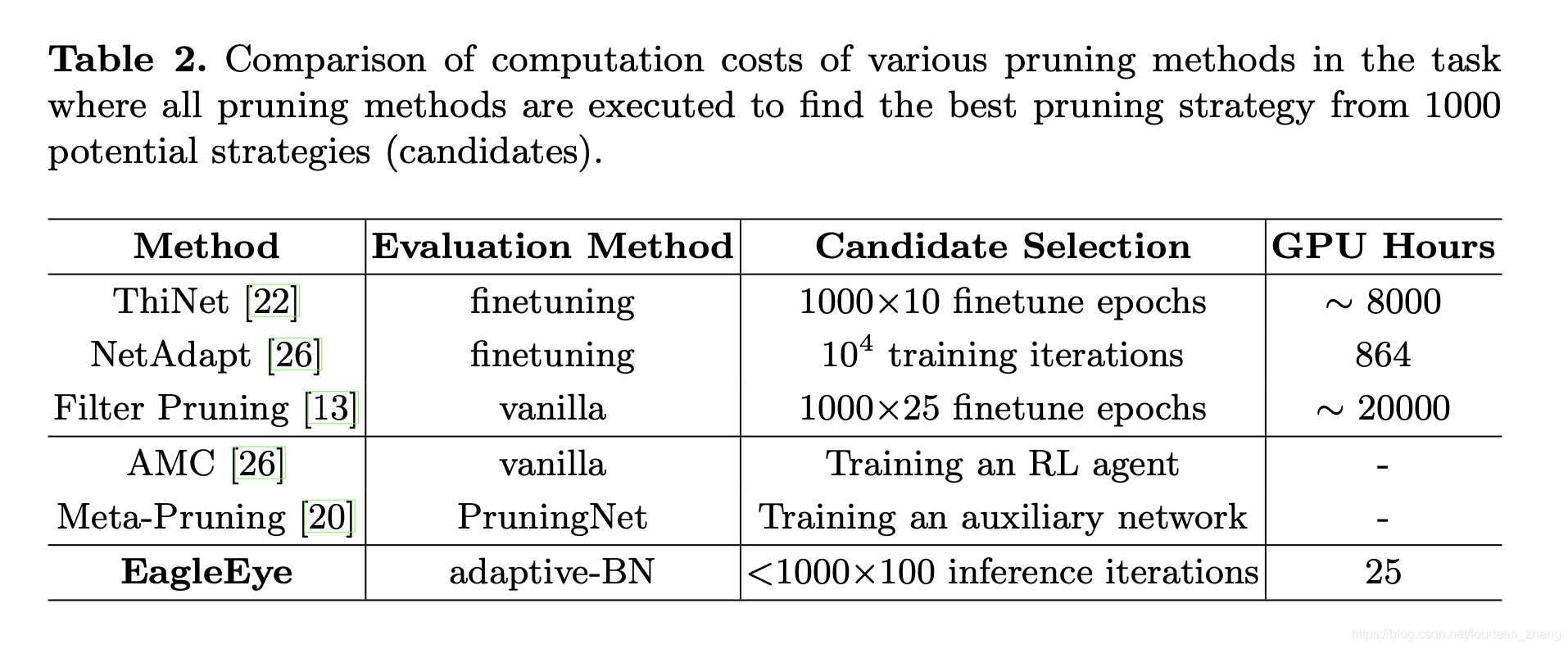
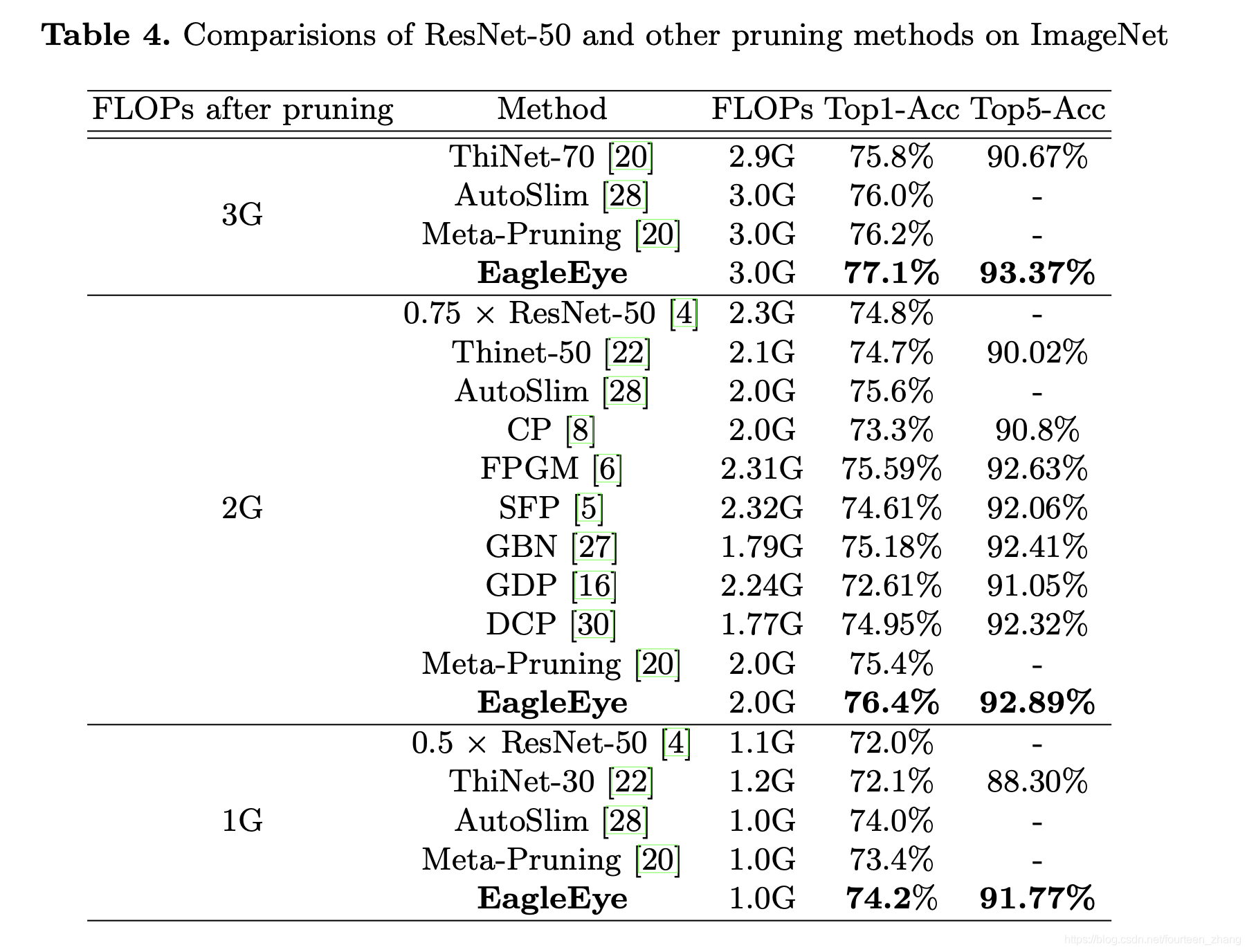
效率方面
EagleEye主要的优势在于其省掉了finetuning步骤,在剪枝效率方面有很大的优势。其中,我们可以看出与ThiNet、AMC和Meta-Pruning方法进行对比,EagleEye所需要的GPU Hours完全不再一个数量级。
总结¶
EagleEye论文的思想比较简单,但是其一定程度上解释了剪枝后模型精度下降的原因,并且提出了修正finetuning前后模型精度弱相关的办法,从而省去了评估剪枝策略中finetuning模型过程,极大地加快剪枝迭代速度。另外,由于其方法简单,能够很方便的应用在其他剪枝算法中,提升剪枝算法速度。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次