我们推出了一个新的系列,对PytorchConference2023 的博客进行中文编译,会陆续在公众号发表。也可以访问下面的地址 https://www.aispacewalk.cn/docs/ai/framework/pytorch/PytorchConference2023/Harnessing+NVIDIA+Tensor+Cores_+An+Exploration+of+CUTLASS+++OpenAI+triton+ 阅读。
大纲¶
-
介绍Cutlass背景和应用场景
-
Cutlass工作原理
-
Cutlass在PyTorch生态中的应用
-
最新功能介绍
-
性能benchmark
-
未来发展计划
详细要点¶
1. 背景介绍¶
-
Cutlass是NVIDIA开源的深度学习库
-
用于在张量核上进行编程
-
起初用于Volta,现已广泛应用在生态系统中
2. 工作原理¶
-
构建于5个抽象层压缩灵活性
-
Cute简化线程数据映射
-
Collective和Tiled ops处理内核计算
3. Cutlass在PyTorch生态中的应用¶
-
在PyTorch中作为Inductor后端
-
AItemplate和Xformer使用Cutlass特性
-
PyTorch geometric应用Cutlass做group gemm
4. 最新功能¶
-
Python接口减少C++模板难度
-
EpilogueVisitor Tree配置复杂Epilogue
-
混合输入gemm支持不同数据类型
5. 性能测试¶
-
利用率达90%以上
-
版本优化中不断提升性能
6. 未来发展计划¶
-
更多优化如低对齐gemm
-
支持Hopper和Ada等新硬件
-
改进文档助力开发
嗨,我们要开始了。我叫马修·尼斯利。我是NVIDIA的深度学习compiler PM,今天我将介绍一些针对NVIDIA Tensorcores的使用方法。首先我要讲一下Cutlass。我会给你一些背景和概述,为什么你可能会使用它,一些最新和即将推出的功能,然后我会概述一下开放平台Triton。如果你刚刚参加了上一场讲座的话那你已经是懂哥了。

好的,Cutlass是我们在GitHub上的开源库,用于在张量核上进行编程。它最初于2017年发布,旨在改善Volta的可编程性。从那时起,它的应用逐渐增长。它已经从一个供深度学习从业者使用的研究工具转变为整个生态系统中广泛应用的生产资产。
Cutlass由构建模块组成,可以根据您的需要使用gemm,卷积等,无论是从现成的还是自己设计的内核。我们支持多种Epilogue模式以及在NVIDIA GPU上找到的所有数据计算类型。我们最近发布了一个Python接口,我稍后会详细介绍它。另外,我们还有一个性能分析器,你可以用它来找到最适合你使用情况的配置。Cutlass对于NVIDIA生态系统至关重要,你会在许多库中找到它,例如cublas、CUSPARSE、cuTENSOR和DALI等等。那么,它是如何工作的呢?

Cutlass由五个抽象层构成,其目的是最大限度地提高灵活性。首先,我们几个月前发布了版本3,它有一个新的后端称为Cute,极大地简化了线程数据映射,并允许核心开发人员专注于张量和算法的逻辑描述。(CuTe is a collection of C++ CUDA template abstractions for defining and operating on hierarchically multidimensional layouts of threads and data.)所以,分解这些抽象层,底层是原子,包含着PTX。tiled的MMA和copy;过了collective层,接下来是kernel层,在这里你可以将collective mainloop and a collective epilogue结合在一起。最后,在设备层面上,你会找到内核配置、启动工具和设备层面保证的可移植性。
(⭐译者吐槽:这里如果不看官方文档很多概念其实是看不懂的。。。。所以插播一下其他知识以便不会觉得太突兀。如果你不想看可以跳过,转载自官方文档 https://github.com/NVIDIA/cutlass/blob/main/media/docs/cutlass_3x_backwards_compatibility.md
Collective mainloop和epilogue是CUTLASS中用于执行集合矩阵乘累加(MMA)操作的关键组件。
Collective mainloop(集合主循环)是一个循环结构,用于在多个线程中执行MMA操作。它负责将输入矩阵切分成小块,并在多个线程之间协调数据传输和计算操作。主循环使用MMA指令对这些小块执行矩阵乘累加操作,利用硬件的并行性和局部性来加速计算。主循环还处理线程同步和通信,以确保正确的数据依赖关系和结果的一致性。
Epilogue(收尾)是主循环之后的一系列操作,用于处理主循环的输出结果。它可以执行各种操作,如对结果进行修正、缩放、舍入等。Epilogue的目的是将主循环的输出转换为最终的矩阵乘累加结果。CUTLASS提供了不同类型的Epilogue,可以根据具体需求选择适当的Epilogue类型。
通过将Collective mainloop和Epilogue组合在一起,CUTLASS能够高效地执行集合MMA操作,利用硬件的并行性和局部性来提高计算效率。这种组合的灵活性使得CUTLASS可以适应不同的硬件架构和应用需求,并提供高性能的矩阵乘累加功能。
这里假设以一个gemm说明为例:
```Plain Text // cutlass::gemm::kernel::GemmUniversal: ClusterTileM and ClusterTileN loops // are either rasterized by the hardware or scheduled by the kernel in persistent kernels. // Parallelism over thread block clusters for (int cluster_m = 0; cluster_m < GemmM; cluster_m += ClusterTileM) { for (int cluster_n = 0; cluster_n < GemmN; cluster_n += ClusterTileN) {
// cutlass::gemm::collective::CollectiveMma: mainloop that iterates over all k-tiles
// No loop unrolling is performed at this stage
for (int k_tile = 0; k_tile < size<2>(gmem_tensor_A); k_tile++) {
// loops inside cute::gemm(tiled_mma, a, b, c); Dispatch 5: (V,M,K) x (V,N,K) => (V,M,N)
// TiledMma uses the hardware instruction provided through its Mma_Atom
// TiledMma's atom layout, value layout, and permutations define the iteration order
for (int tiled_mma_k = 0; tiled_mma_k < size<2>(A); tiled_mma_k++) {
for (int tiled_mma_m = 0; tiled_mma_m < size<1>(A); tiled_mma_m++) {
for (int tiled_mma_n = 0; tiled_mma_n < size<1>(B); tiled_mma_n++) {
// TiledMma's vector mode dispatches to the underlying instruction.
mma.call(d, a, b, c);
} // tiled_mma_n
} // tiled_mma_m
} // tiled_mma_k
} // k_tile mainloop
} // cluster_m
} // cluster_n
CUTLASS使用以下组件来表示上述循环嵌套(上面是一个gemm),这些组件针对数据类型、布局和数学指令进行了专门化。
|API level|API Class and/or function names|
|-|-|
|Device|`cutlass::gemm::device::GemmUniversalAdapter`|
|Kernel|`cutlass::gemm::kernel::GemmUniversal`|
|Collective|`cutlass::gemm::collective::CollectiveMma` `cutlass::epilogue::collective::DefaultEpilogue` `cutlass::epilogue::collective::Epilogue` |
|Tiled (MMA and Copy)|`cute::TiledMma` and `cute::TiledCopy` `cute::gemm()` and `cute::copy()`|
|Atom|`cute::Mma_Atom` and `cute::Copy_Atom`|
在CUTLASS 3.0中,我们通过首先在内核层面组合collective mainloop(cutlass::gemm::collective::CollectiveMma: mainloop that iterates over all k-tiles)和collective epilogue ,然后使用主机端转换器将它们包装成一个GEMM内核的handle 。
以下部分按照用户实例化它们的顺序描述了组装一个内核需要的组件,这个顺序是:
1. 组装所需的collective mainloop and epilogues。
2. 将它们组合在一起构建一个内核类型。
3. 使用设备层转换器包装内核。
**Collective是“mma atoms和copy atoms 被切分到的最大线程集合”。也就是说,它是一个最大数量的线程网格,通过利用硬件特性进行加速通信和同步来进行协作。**这些硬件特性包括:
- 异步数组复制(例如,从全局内存到共享内存);
- 用于位于共享内存中的小块的MMA指令;
- 用于集群、线程块和/或warp的同步操作;和/或
硬件加速(例如屏障),以确保满足异步操作之间的数据依赖关系。
Collective使用TiledMma和TiledCopy API(来访问在块上执行复制和MMA操作。
cutlass::gemm::collective::CollectiveMma类是集合矩阵乘累加(MMA)mainloop的主要接口。这里的“主循环”指的是在伪代码中靠近本文顶部的“cluster tile k”循环。算法可能需要对多个块进行循环的情况会在这里发生。
更多请自行查看文档
(⭐从这里开始回到正文讲座)

为什么要使用Cutlass呢?这可能是最常见的问题。cublas将拥有最佳的开箱体验。它将有更快的上市时间。它在不同架构之间提供了可移植性保证。它有一组基于您的参数选择最佳内核的启发式算法。所以我告诉很多客户的是,如果cublas能满足您的需求,就使用它。
(译者:以防看不懂放上GPT的解释:
CUTLASS和CUBLAS是两个用于在NVIDIA GPU上进行矩阵运算的库,它们有以下区别:
1. 开发者:CUTLASS是由NVIDIA开发和维护的开源项目,而CUBLAS是NVIDIA官方提供的闭源库。
2. 灵活性和可配置性:CUTLASS提供了更高级别的灵活性和可配置性,允许用户自定义和优化矩阵运算的细节。它提供了底层的矩阵运算原语和算法的实现,使用户可以根据特定需求进行定制和优化。CUBLAS则提供了更高级别的抽象和易用性,适用于常见的矩阵运算任务。
3. 性能优化:CUTLASS注重性能优化和硬件特性的利用。它提供了更多的配置选项和优化策略,使用户能够根据具体的硬件架构和应用需求进行性能优化。CUTLASS还提供了针对深度学习任务的特殊优化,如半精度浮点计算(FP16)和Tensor Core加速。CUBLAS也进行了一些性能优化,但它更注重提供易用性和通用性。
4. 支持的功能:CUTLASS提供了更多的功能和算法选项,包括矩阵乘累加(MMA)、卷积等。CUBLAS则提供了一组预定义的矩阵运算函数,如矩阵乘法、矩阵向量乘法等。
5. 开源性:CUTLASS是开源的,用户可以访问其源代码并参与社区贡献和讨论。CUBLAS是闭源的,用户无法访问其底层实现。)
如果您需要最大的灵活性,比如自定义epilogue,在cublas中并不存在,那么就使用Cutlass。虽然它需要花费一些时间来启动和运行,但您可以对数据传输和操作拥有最大的控制权。
在PyTorch生态系统中,你在哪里可以找到Cutlass呢?在高层级上,你会在eager模式下找到一些稠密和稀疏操作,并且目前有一个PR正在将Cutlass作为Inductor的另一种后端添加进去。AItemplate(meta的torch backend codegen工具)在开发过程中使用了每一层的一些特性。Xformer的内存高效注意力是在Cutlass上开发的。 最后,PyTorch geometric是我们group Gemm的早期采用者之一。
我之前提到了Python接口。Cutlass的最大痛点之一是C++模板。通过我们的Python接口,我们大大减少了开始所需的默认值。这是一个基本的gemm示例,你可以看到它可能是所需参数的三分之一多。Plain Text
using Gemm = typename gemm::kernel::DefaultGemmUniversal<
half, layout::RowMajor, ComplexTransform::kNone,
half, layout::RowMajor, ComplexTransform::kNone,
half, layout::RowMajor,
arch::OpClassTensorOp, arch::Sm8e,
gemm::GemmShape<256, 128, 64>,
gemm::GemmShape<64, 64, 64>,
gemm::GemmShape<16, 8, 16>,
epilogue::thread::LinearCombination
```Plain Text
创建GEMM plan¶
plan = cutlass.op.Gemm(element=torch.float16, layout=cutlass.LayoutType.RowMajor)
更改swizzling functor¶
plan.swizzling_functor = cutlass.swizzle.ThreadblockSwizzlestreamk
添加fused ReLU¶
plan.activation = cutlass.epilogue.relu ```
Python接口的另一个目标是改善与PyTorch等框架的集成。可以通过新的Cutlass emit PyTorch方法来实现。右侧您将看到可以使用Python接口声明PyTorch中的group gemm并给出PyTorch CUDA扩展。

之后我们将负责生成源代码,为PyTorch扩展提供输入,并提供一个脚本来生成该PyTorch扩展。
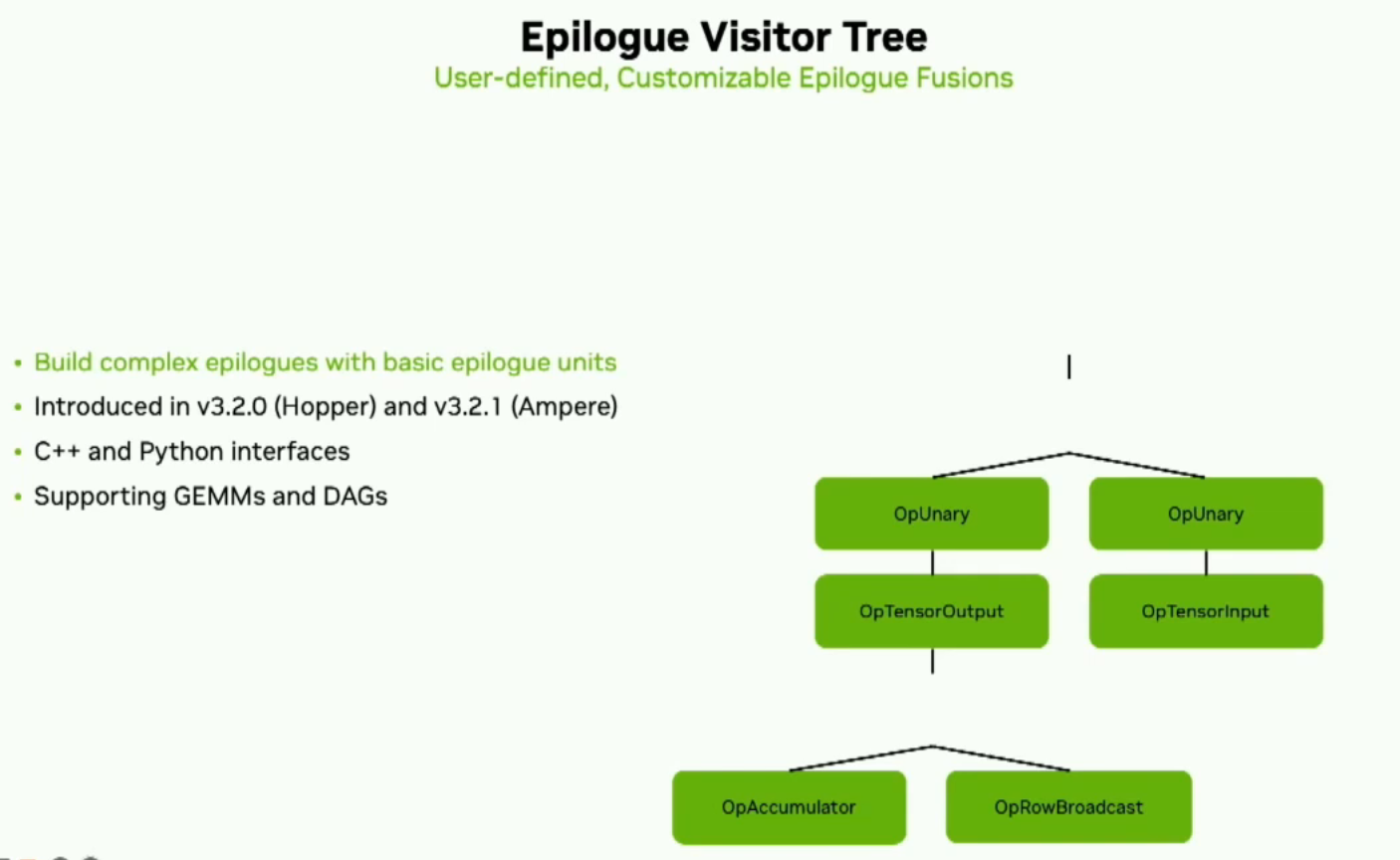
在Cutlass中最新的功能是我们称为epilogueVisitor Tree。这将允许用户使用基本的epilogue单元来开发复杂的epilogue。它是一组小的计算、加载和存储操作,可以生成常见或自定义的epilogue。它在Ampere和Hopper架构上和C++和Python接口中已经可以使用。我们在现有的配置中,利用峰值效果非常好。下面是一个示例,在最新版本的Cutlass 3.2和Cuda Toolkit 12.2以及H100上使用性能分析器和默认参数。
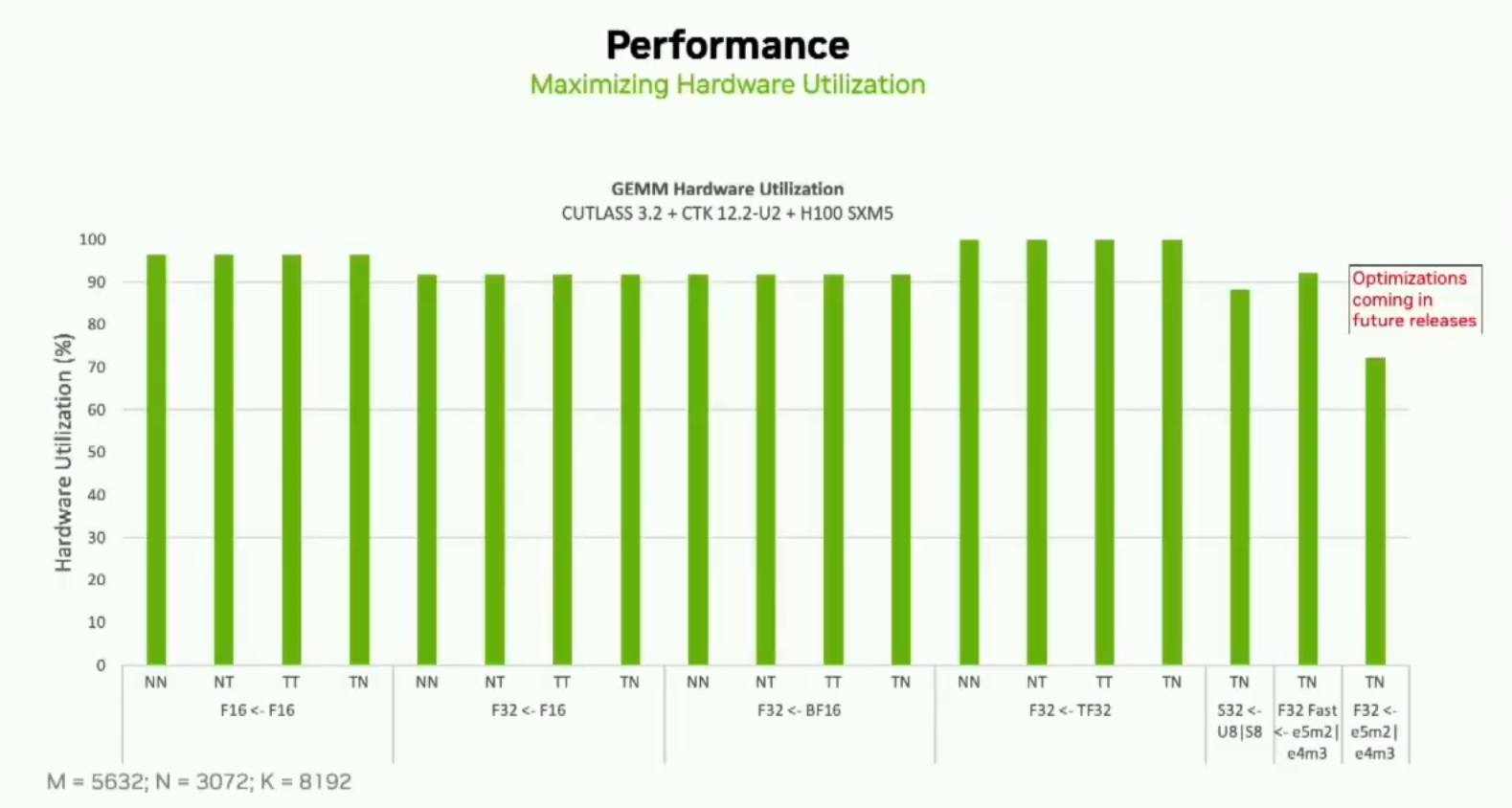
您可以看到对于所有这些用例,我们大约达到了90%的峰值利用率。我们还努力确保没有性能下降,并会定期发布优化版本。
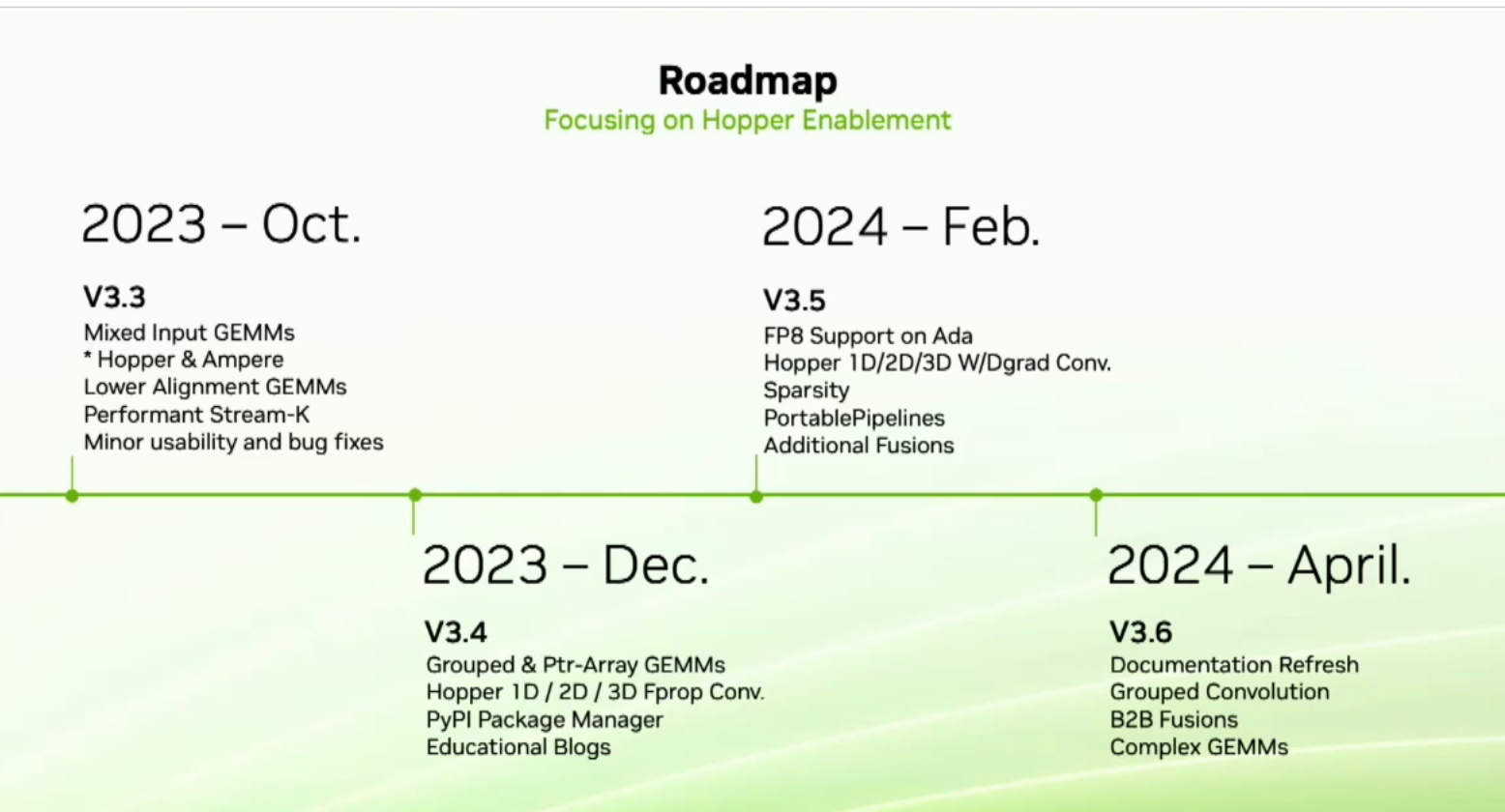
我们的下一个发布版本是3.3。3.3中最重要的功能是我们称之为混合输入gemm。这是一个常见的需求,在这个功能下,你可以为A和B矩阵使用不同的数据类型。例如,A可以是FP16。B可以是int8,而在gemm中,我们将向上转换到BF16的操作。我们还对我们的lower alignment gemm进行了性能改进。然后在今年12月,我们将推出grouped 和 ptr-array gemm,以及为Hopper优化的四个性能卷积。明年年初,我们将为Ada提供FP8支持。我们将进行卷积的权重和偏差(W&D grad)优化,支持稀疏数据。我们还有一个称为portablepipeline的新功能。portablepipeline是我们为希望在架构上实现可移植性的用户提出的建议。在GTC Talk上会有更多关于这个功能的信息。最后,在明年第二季度,Cutlass开发者和初学者需要的是更好的文档。我们会进行全面更新,这将涵盖C++和Python接口。
OpenAI Triton是一个令人兴奋的新的类似于Python的编程语言,供用户开发在Python中针对NVIDIA TensorCores的内核。这样一来,开发者可以专注于更高级别的逻辑。OpenAI Triton Compiler会处理许多性能优化,让开发者不用操心。NV和openai在大力合作推进一切中。
到此结束,谢谢。
本文总阅读量次