本文首发于我的知乎:https://zhuanlan.zhihu.com/p/120376337
之前写了关于海思NNIE的一些量化部署工作,笔者不才,文章没有写得很具体,有些内容并没有完全写在里面。好在目前看到了一些使用nniefacelib脱坑的朋友,觉得这个工程还是有些用的。为了完善这个工程,最近也增加一些一站式的解决方案。开始正题吧!
https://github.com/hanson-young/nniefacelib
1. 训练¶
PFLD 是一个精度高、速度快、模型小三位一体的人脸关键点检测算法。github上也有对其进行的复现工作,而这次要介绍的就是https://github.com/hanson-young/nniefacelib/blob/master/PFPLD/README.md 。
PFPLD (A Practical Facial Pose and Landmark Detector),对PFLD的微改版本,笔者对其进行了一些微小的改变,名字中间多了个”P“。其实是对pose branch进行了加强,同时让其关键点对遮挡、模糊、光照等复杂情况更加鲁棒。
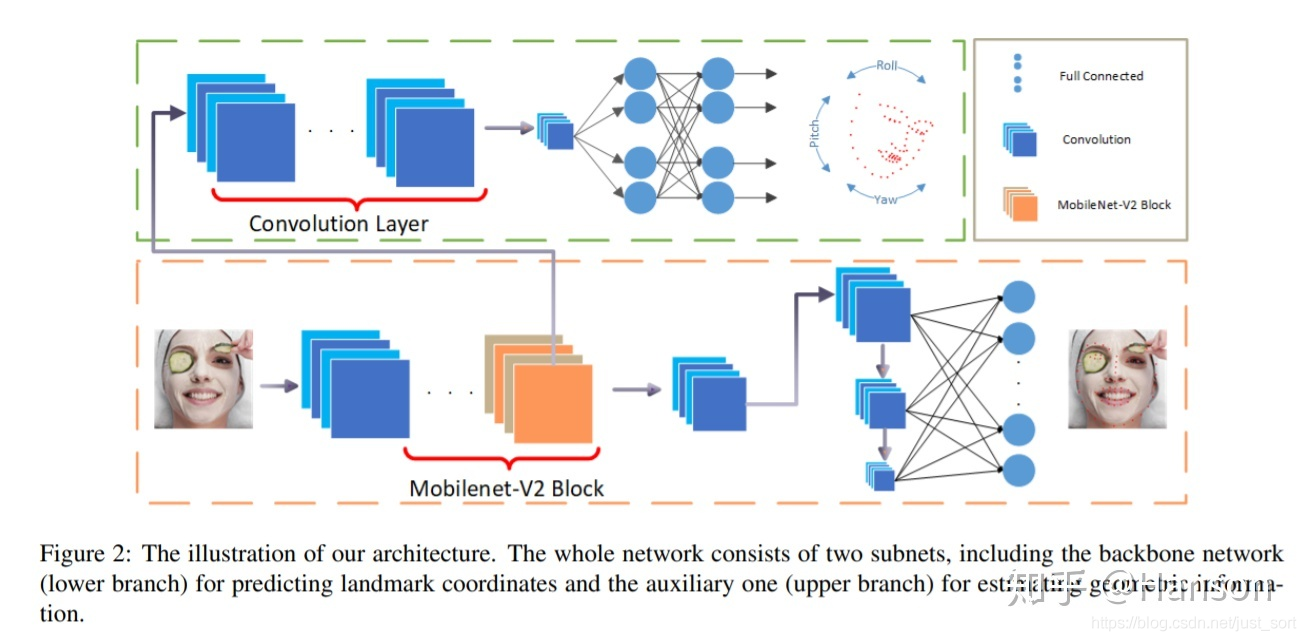
黄色虚线囊括的是主分支网络,用于预测关键点的位置;绿色虚线囊括的是head pose辅助网络。在训练时预测人脸姿态,从而修改loss函数,使更加关注那些稀有的,还有姿态角度过大的样本,从而提高预测的精度。同等规模的网络,只要精度上去,必然是可以想到很多办法来降低计算量的。
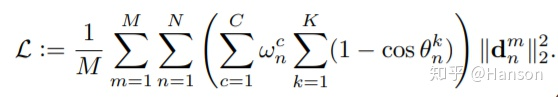
直观感受,这个loss的设计模式本质上是一种对抗数据不均衡的表达,和focal loss思想是一致的。但这类思想并不是对于每种工作都能work,笔者曾经回答过类似的问题。
深度学习的多个loss如何平衡 & 有哪些「魔改」损失函数,曾经拯救了你的深度学习模型?
接下来将介绍一些笔者对其微改的地方:
在github上的代码分为了两个分支,下面单独做一下讲解
二、V1.1.1分支¶
- 用PRNet(
https://github.com/YadiraF/PRNet)标注人脸图像的姿态数据,比原始通过solvePNP得到的效果要好很多,这也直接增强了模型对pose的支持。PRNet是一个非常优秀的3D人脸方面的项目。论文也写的很精彩,强烈推荐去看。目前在活体检测领域用其渲染的depth map作为伪标签进行训练,已经成为了一种标配性的存在。所以当人脸姿态估计算法性能接近于它,证明训练的姿态已经非常不错了。如果想要得到更好的表现,用更加特殊的方法采集人脸姿态数据进行炼丹也是行得通的(吐槽:大部分开源姿态数据标注规范并不统一)。 - 在整个实验中pfld loss收敛速度比较慢,慢也是有原因的,过于重点关注少量复杂的样本,会使得对整体的grad调节不明显,因此对多种loss(mse, pfld, smoothl1 and wing)进行了对比,结果得出,wing loss的效果更加明显,收敛速度也比较快。
- 改进了pfld网络结构,让关键点和姿态角度都能回归的比较好,将landmarks branch合并到pose branch中。由于两个任务相关性较强, 这样做可以让其更加充分的影响。对于这种多任务之间正向促进的例子,通过对网络结构以及辅助监督信号的改进,可以使其结果并不会太过于依赖loss函数的设计。这并不是笔者在的主观判断,感兴趣,可以参考我之前的一个回答,如有不同之处,欢迎一起讨论相关话题。
深度学习的多个loss如何平衡 & 有哪些「魔改」损失函数,曾经拯救了你的深度学习模型?
三,master分支¶
分支V1.1.1也存在一些问题,比如最大的一个问题就是闭眼的时候效果并不好,显然眼睛部分的关键点已经出现过拟合了。而master分支改进的效果为右列,得到了一些优化。
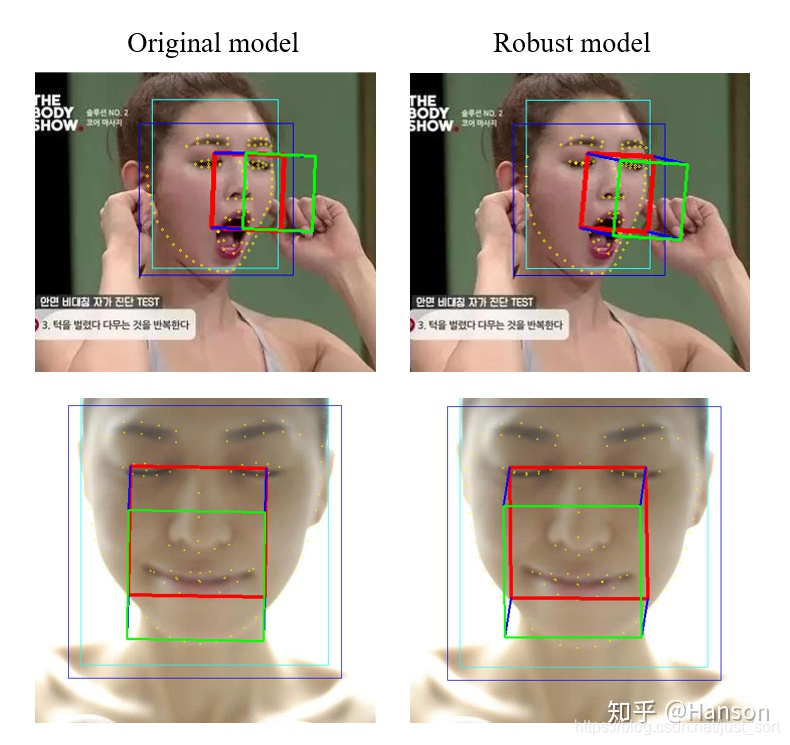
我们也发现一个规律,分别用WLFW 98个点,LAPA 106个点的数据集进行训练,闭眼效果都不行,而300WLP上的却没问题。这或许是一个通病,我也试了其他的算法,也有这些问题,比如
为什么会出现这个现象呢?这其实和训练数据集里面闭眼图片的数量过少有关系,加强眼部的训练并不能抵抗这种情况,因为不是一个维度的事情,最佳的方式依然是添加闭眼数据。同时也建议大家在制作数据集的时候考虑数据的均衡性
详细的讨论如下:
https://github.com/hanson-young/nniefacelib/issues/13
另外一个问题是PRNet的pose预测在抬头时候不精确,因此V1.1.1中直接用PRNet去标注也不是一种理想方式
为了解决上面两个后面发现的问题,为了解决数据的均衡性,我们挑选出LAPA 106个关键点的数据集中闭眼的数据,加入WLFW中用于解决闭眼问题,引入300WLP用于解决pose问题),新的代码对 dataloader以及wing loss函数进行了优化,目前数据集已经整理好放出来了!请使用PFPLD-Dataset数据集进行训练!欢迎尝鲜!
虽然融合大法好,但是,我们发现一个问题,网上已经开源了很多的关键点数据集,而这些数据集的标注点数并不一致,有没有办法将这些数据都利用起来呢?比如上述WLFW 98点、LAPA 106点、300WLP 68点。答案是肯定的,我们可以有针对性的选择其中的一些点对眼睛、鼻子、轮廓进行单独加强!在实际操作上,LAPA相对于WLFW增加了部分关键点,而且是完全兼容的,这样就可以先对WLFW和LAPA进行一个融合,姑且叫做WLFW2。
而融合300WLP就会面临一些困难,因为点的对应上没法完全兼容,因此需要参考标注标准挑选一些能兼容的点进行训练。下面是对loss的一些修改。
class WingLoss(nn.Module):
def __init__(self):
super(WingLoss, self).__init__()
self.num_lds = 98
self.size = self.num_lds * 2
self.w = 10.0
self.s = 5.0
# 挑选出WLFW2中的眼睛关键点
self.eye_index = [60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75]
# 挑选出300WLP中与WLFW2想对应的部分关键点
self.pts_68_to_98 = [33,34,35,36,37,42,43,44,45,46,51,52,53,54,55,56,57,58,59,60,64,68,72,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95]
self.pts_onehot = [i for i in range(98)]
for i in self.pts_onehot:
if i in self.pts_68_to_98:
self.pts_onehot[i] = True
else:
self.pts_onehot[i] = False
self.epsilon = 2.0
def forward(self, attribute_gt, landmark_gt, euler_angle_gt, type_flag , angle, landmarks, train_batchsize):
landms_const = torch.tensor(-2).cuda()
pose_68landms_const = torch.tensor(0).cuda()
# WLFW2中98个点的loss
pos1 = type_flag == landms_const
landm_p = landmarks.reshape(-1, self.num_lds, 2)[pos1]
landm_t = landmark_gt.reshape(-1, self.num_lds, 2)[pos1]
lds_98_loss = 0
if landm_p.shape[0] > 0:
x = landm_t - landm_p
c = self.w * (1.0 - math.log(1.0 + self.w / self.epsilon))
absolute_x = torch.abs(x)
weight_attribute = landm_p*0.0 + 1.0
weight_attribute[:,self.eye_index] *= self.s
absolute_x = torch.mul(absolute_x, weight_attribute)
lds_losses = torch.where(self.w > absolute_x, self.w * torch.log(1.0 + absolute_x / self.epsilon), absolute_x - c)
lds_98_loss = torch.mean(torch.sum(lds_losses, axis=[1, 2]), axis=0)
# 300WLP 中部分关键点的loss和姿态的loss
pos2 = type_flag == pose_68landms_const
pose_p = angle.view(-1, 3)[pos2]
pose_t = euler_angle_gt.view(-1, 3)[pos2]
pose_loss = 0
if pose_p.shape[0] > 0:
pose_loss = F.smooth_l1_loss(pose_p, pose_t, reduction='mean')
landm_p = landmarks.reshape(-1, self.num_lds, 2)[pos2]
landm_t = landmark_gt.reshape(-1, self.num_lds, 2)[pos2]
lds_68_loss = 0
if landm_p.shape[0] > 0:
landm_p = landm_p[:, self.pts_onehot]
landm_t = landm_t[:, self.pts_onehot]
x = landm_t - landm_p
absolute_x = torch.abs(x)
c = self.w * (1.0 - math.log(1.0 + self.w / self.epsilon))
lds_losses = torch.where(self.w > absolute_x, self.w * torch.log(1.0 + absolute_x / self.epsilon), absolute_x - c)
lds_68_loss = torch.mean(torch.sum(lds_losses, axis=[1, 2]), axis=0)
return lds_98_loss + lds_68_loss, pose_loss*1000
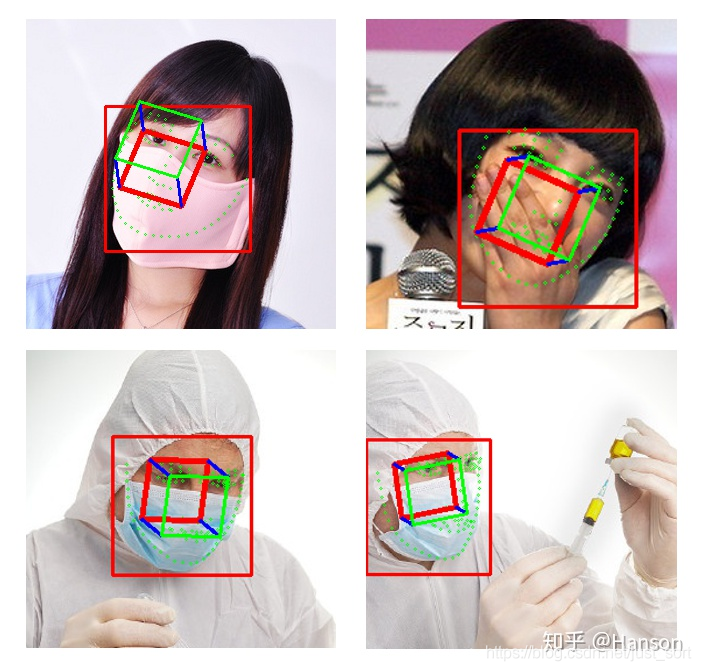
疫情当下,口罩遮挡,玄学优化,美图共赏
四、量化¶
过去一周,笔者对训练代码进行了整理,完成了多种版本的转换工作,包括
- pytorch
- caffe
- ncnn
- nnie
听说有小伙伴将这套模型跑到了ios上,说不定之后会放出来。
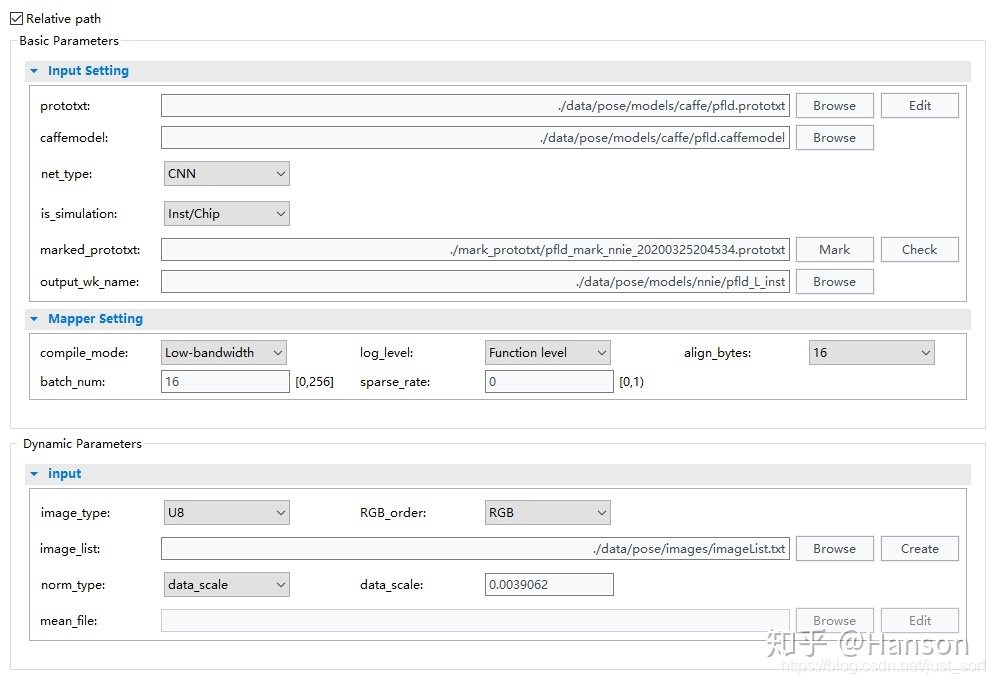
扯了一大堆,那开始介绍下本文最核心的NNIE。有首先我们要选择一个比较优秀的训练框架,比如,我们选择了pytorch。然后要将模型转换为caffe,那我们选择了onnx作为过度环节
python convert_to_onnx.py
python3 -m onnxsim ./models/onnx/checkpoint_epoch_final.onnx ./models/onnx/pfpld.onnx
cd cvtcaffe
python convertCaffe.py
可以看得出来,经过了很少的步骤,一个被图优化过的caffe模型就出来了,包括merge bn,inplace等优化,"工具人"onnx在其中起到了很重要的作用。
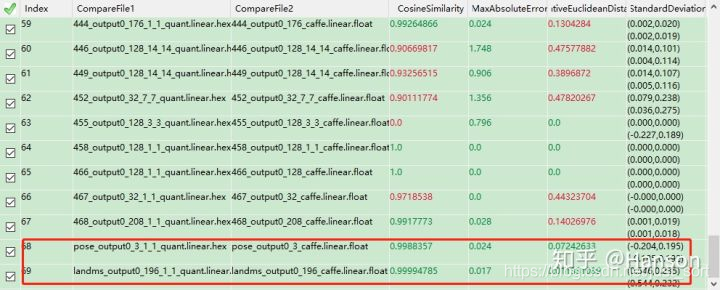
之前也提到过batchnorm会对精度造成一些不知所以的影响,所以
无论我们遇到什么困难,都不要怕,微笑着面对它,消除恐惧的最好办法就是避开恐惧,避开,才会胜利,加油,奥利给!
另外,笔者自己训练模型的时候是不会考虑减均值这种操作的,只会做data_scale处理,为什么这么做,因为放弃思考真得很香。记性不好,不想遇到问题的时候去查,也不太相信减均值能带来明显收益!
为了感谢读者们的长期支持,我们今天将送出三本由北京大学出版社提供《TensorFlow 深度学习实战大全》,有需要学习TensorFlow的同学可以在下方留言板随意留言,笔者将随机挑选三人赠出数据。

另外,近期由一流科技(公众号作者梁德澎,zzk均是一流科技成员)打造的国产框架 One-Flow 已经开源,设计理念十分新颖,运行速度超过了TensorFlow和Pytorch,建议大家在Github标星并尝鲜一下。 Github地址如下:
https://github.com/Oneflow-Inc/oneflow
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次