这篇文章主要是对DeepSpeed Chat的功能做了一些了解,然后翻译了几个主要的教程了解了一些使用细节。最后在手动复现opt-13b做actor模型,opt-350m做reward模型进行的chatbot全流程训练时,踩了一些坑也分享出来了。最后使用训练后的模型做serving展示了一下对话效果并简要分析了一下chatbot的推理代码。后续,我会尝试深入到DeepSpeed Chat的三个训练阶段分别进行源码解读和理解,也许也会尝试一下其它的模型或者修改数据集来获得更好的chatbot效果。
0x0. 🐕 前言🐕¶
之前翻译了几篇DeepSpeed的教程,也使用Megatron-DeepSpeed走通了GPT2模型的训练和推理流程。这篇文章想记录一下复现DeepSpeed前段时间给出的DeepSpeed-Chat例子,训练一个经过监督指令微调和RLHF之后的对话模型。关于DeepSpeed的发布博客见:https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat ,官方也比较贴心的提供了中文版本:https://github.com/microsoft/DeepSpeed/blob/master/blogs/deepspeed-chat/chinese/README.md 。
0x1. 🐕 概述和BenchMark细节🐕¶
https://github.com/microsoft/DeepSpeed/blob/master/blogs/deepspeed-chat/chinese/README.md#1-%E6%A6%82%E8%BF%B0 这里概述了DeepSpeed-Chat的三个核心功能:

然后,博客给出了DeepSpeed-Chat在RLHF训练的第三步也就是基于人类反馈的强化学习阶段的一个BenchMark测试。
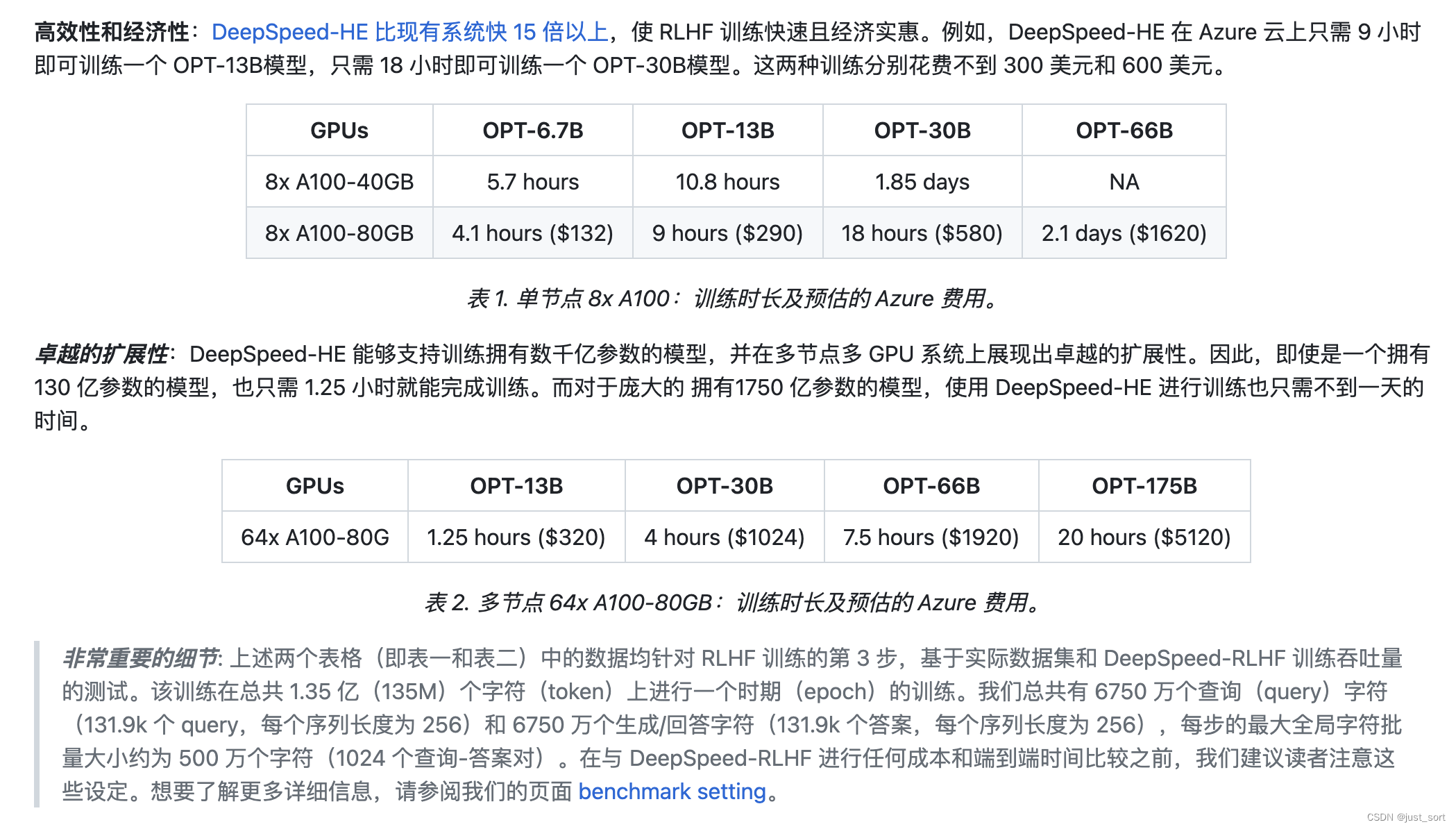
这个地方需要注意一些细节,也就是https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/BenckmarkSetting.md 中提到的内容,我这里翻译一下。
正如上面截图中非常重要的细节指出的,进行公平的比较对于机器学习社区来说至关重要,特别是在基准测试中。例如,将DeepSpeed-Chat的端到端训练时间与Alpaca和Vicuna(两者都专注于监督指令微调)进行比较是不公平的,因为它们并未包含完整的RLHF训练流程。因此,我们在这里进一步详细说明。
我们从六个开源训练数据集中随机选择了40%的训练数据,即 "Dahoas/rm-static","Dahoas/full-hh-rlhf","Dahoas/synthetic-instruct-gptj-pairwise","yitingxie/rlhf-reward-datasets","openai/webgpt_comparisons",以及 "stanfordnlp/SHP"。我们拥有的总训练样本数是264,292。我们将查询(prompt)序列长度固定为256,并生成固定长度256个token的答案。因此,每个训练阶段的总训练令牌数是135,317,504。在基准测试期间,我们将训练周期数设置为1。
如RLHF训练教程(https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/README.md#%F0%9F%99%8B-instablity-of-rlhf-training-and-others)中所提到的,我们发现使用生成的数据多次更新actor模型是不稳定的。因此,我们将所有基准测试结果的per_device_train_batch_size、per_device_mini_batch_size、ppo_epochs和generation_batch_numbers都设为1。在测试过程中,我们还为最大全局训练token设定了上限524,288(批量大小为1024,序列长度为512)。这是我们在探索过程中找到的能提供稳定RLHF训练体验的最大批量大小。用户和实践者可能会找到更好的训练超参数来进一步增加这个值。此外,在测试过程中,只要全局训练token批量大小不超过我们设定的上限524,288,我们总是使用不会导致内存溢出错误的最大训练批量大小来做基准测试的时间。
上面对DeepSpeed-Chat的功能以及BenchMark的细节做了介绍,接下来就跟着DeepSpeed-Chat源码里提供的教程来一步步复现模型,先从DeepSpeed-Chat的教程翻译开始。
0x2. 🐕DeepSpeed-Chat:简单、快速且经济的RLHF训练,适用于各种规模的类ChatGPT模型🐕¶
以下是在翻译 https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat 这个教程的时候尝试按照教程提供的方法一步步复现 DeepSpeed-Chat。
一个快速、经济、可扩展且开放的系统框架,使得在各种规模上生成高质量ChatGPT风格的端到端基于人类反馈的强化学习(RLHF)模型的训练体验成为可能。

🚀什么是DeepSpeed-Chat🚀¶
在推广ChatGPT风格模型及其能力的精神下,DeepSpeed自豪地推出了一个通用系统框架,名为DeepSpeed Chat,以实现ChatGPT-like模型的端到端训练体验。它可以自动地通过OpenAI InstructGPT风格的三个阶段,将你最喜欢的预训练大型语言模型转化为你自己的高质量ChatGPT风格模型。DeepSpeed Chat使得训练高质量的ChatGPT风格模型变得简单、快速、经济并且可扩展。
只需一键,你就可以在一台配备48GB内存的消费级NVIDIA A6000 GPU上,在1.36小时内训练、生成和运行一个13亿参数的ChatGPT模型。在一台配备8块NVIDIA A100-40G GPU的单个DGX节点上,DeepSpeed-Chat可以在13.6小时内训练一个130亿参数的ChatGPT模型。在多GPU多节点系统(云环境)中,例如,8个配备8块NVIDIA A100 GPU的DGX节点,DeepSpeed-Chat可以在不到9小时内训练一个660亿参数的ChatGPT模型。最后,它实现了相对于现有RLHF系统的15倍速度提升,并可以处理训练参数超过2000亿的ChatGPT-like模型:这是现有系统无法实现的。关于DeepSpeed-Chat支持的各种模型大小和低训练成本的全面讨论,请参阅发布博客(https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat)和训练性能评估(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat#-training-performance-evaluation-)。
除了这次发布之外,DeepSpeed 系统非常荣幸地作为系统后端,为一系列正在进行的快速训练/微调聊天风格模型(例如,LLaMA)的工作提供了加速。以下是一些由 DeepSpeed 支持的开源示例: - https://github.com/databrickslabs/dolly - https://github.com/OptimalScale/LMFlow - https://github.com/CarperAI/trlx - https://github.com/huggingface/peft
🧨 能力 🧨¶
DeepSpeed Chat正在快速发展,以适应对系统级别加速支持的需求日益增长,这包括训练/微调以及服务新兴模型。请关注我们在路线图(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat#-deepspeed-chats-roadmap-)中即将到来的里程碑计划。
DeepSpeed Chat的概要包括: - DeepSpeed Chat:一个完整的端到端三阶段 OpenAI InstructGPT 训练策略,结合人工反馈的强化学习(RLHF),从用户喜欢的预训练的大型语言模型 Checkpoint 生成高质量的 ChatGPT 风格模型; - DeepSpeed Hybrid Engine:一种新的系统支持,用于在所有规模上进行快速、经济和可扩展的 RLHF 训练。它基于你喜欢的 DeepSpeed 的系统能力,如 ZeRO 技术和 DeepSpeed-Inference; - 轻松愉快的训练体验:一个单独的脚本,能够接受一个预训练的 Huggingface 模型,并将其运行通过 RLHF 训练的所有三个步骤。 - 一个通用系统支持当今 ChatGPT-like 模型训练:DeepSpeed Chat 可以作为系统后端,不仅用于三步骤的 instruct-base RLHF 管道,而且还用于当前的单一模型微调探索(例如,以 LLaMA 为中心的微调)以及各种模型和场景的通用 RLHF 训练。
清参考我们的博客(https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat)和文档和教程(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat#-documentation-and-tutorial-)来获取更多关于训练技术和新系统技术的细节。
☕ 快速开始 ☕¶
🐼 安装¶
pip install deepspeed>=0.9.0
git clone https://github.com/microsoft/DeepSpeedExamples.git
cd DeepSpeedExamples/applications/DeepSpeed-Chat/
pip install -r requirements.txt
🐼 一个单一的脚本就能完成 RLHF 训练的全部三个步骤,并生成你的首个 ChatGPT 模型¶
💛 DeepSpeed-Chat 的 RLHF 示例 1:用一杯咖啡时间训练一个 13 亿参数的 ChatGPT 模型¶
如果你只有大约1-2小时的咖啡或午餐休息时间,你也可以尝试使用 DeepSpeed-Chat 训练一个小型/玩具模型。例如,我们准备了一个针对单个数据集的13亿参数模型的训练示例,以便在你的消费级 GPU 上测试我们的框架。最好的部分是,当你从午餐休息回来时,你将有准备好的模型检查点可以玩。
python train.py --actor-model facebook/opt-1.3b --reward-model facebook/opt-350m --deployment-type single_gpu
请参阅以下表格,了解在单个普通的具有48GB内存的NVIDIA A6000 GPU上通过DeepSpeed-Chat训练一个13亿参数的ChatGPT模型的端到端时间分解。

执行了一下这个命令,有一个报错:
Setting ds_accelerator to cuda (auto detect)
[2023-06-29 05:59:44,683] [WARNING] [runner.py:196:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2023-06-29 05:59:44,736] [INFO] [runner.py:555:main] cmd = /home/zhangxiaoyu/miniconda3/envs/eval/bin/python -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMF19 --master_addr=127.0.0.1 --master_port=29500 --enable_each_rank_log=None main.py --model_name_or_path facebook/opt-1.3b --gradient_accumulation_steps 8 --lora_dim 128 --zero_stage 0 --deepspeed --output_dir /home/zhangxiaoyu/DeepSpeedExamples/applications/DeepSpeed-Chat/output/actor-models/1.3b
Setting ds_accelerator to cuda (auto detect)
[2023-06-29 05:59:46,247] [INFO] [launch.py:145:main] WORLD INFO DICT: {'localhost': [0]}
[2023-06-29 05:59:46,248] [INFO] [launch.py:151:main] nnodes=1, num_local_procs=1, node_rank=0
[2023-06-29 05:59:46,248] [INFO] [launch.py:162:main] global_rank_mapping=defaultdict(<class 'list'>, {'localhost': [0]})
[2023-06-29 05:59:46,248] [INFO] [launch.py:163:main] dist_world_size=1
[2023-06-29 05:59:46,248] [INFO] [launch.py:165:main] Setting CUDA_VISIBLE_DEVICES=0
Traceback (most recent call last):
File "/home/zhangxiaoyu/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/main.py", line 15, in <module>
from transformers import (
File "/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/transformers/__init__.py", line 26, in <module>
from . import dependency_versions_check
File "/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/transformers/dependency_versions_check.py", line 57, in <module>
require_version_core(deps[pkg])
File "/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/transformers/utils/versions.py", line 117, in require_version_core
return require_version(requirement, hint)
File "/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/transformers/utils/versions.py", line 111, in require_version
_compare_versions(op, got_ver, want_ver, requirement, pkg, hint)
File "/home/zhangxiaoyu/miniconda3/envs/eval/lib/python3.9/site-packages/transformers/utils/versions.py", line 44, in _compare_versions
raise ImportError(
ImportError: accelerate>=0.20.3 is required for a normal functioning of this module, but found accelerate==0.19.0.
Try: pip install transformers -U or pip install -e '.[dev]' if you're working with git main
[2023-06-29 05:59:48,260] [INFO] [launch.py:314:sigkill_handler] Killing subprocess 1633528
[2023-06-29 05:59:48,261] [ERROR] [launch.py:320:sigkill_handler] ['/home/zhangxiaoyu/miniconda3/envs/eval/bin/python', '-u', 'main.py', '--local_rank=0', '--model_name_or_path', 'facebook/opt-1.3b', '--gradient_accumulation_steps', '8', '--lora_dim', '128', '--zero_stage', '0', '--deepspeed', '--output_dir', '/home/zhangxiaoyu/DeepSpeedExamples/applications/DeepSpeed-Chat/output/actor-models/1.3b'] exits with return code = 1
提示accelerate的版本需要>=0.20.3,而当前的版本是0.19.0。通过升级的方式解决了一下这个错误,训练程序就顺利启动起来了。
💚 DeepSpeed-Chat的RLHF示例2:在单个普通GPU节点上训练一个130亿参数的ChatGPT模型,只需半天时间¶
如果你只有大约半天的时间并且只有一个服务器节点,我们建议使用以下单个脚本中的预训练OPT-13B作为actor模型,OPT-350M作为reward模型,生成一个最终的130亿参数的ChatGPT风格模型:
python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --deployment-type single_node
请参阅以下表格,了解使用具有8个NVIDIA A100-40G GPU的单个DGX节点,通过DeepSpeed-Chat训练一个130亿参数的ChatGPT模型的端到端时间分解。

💙 DeepSpeed-Chat的RLHF示例3:低成本云训练用于更大的66B ChatGPT模型¶
想尝试不同的模型大小和配置吗?你可以得到!使用DeepSpeed-Chat,用户可以轻松做到这一点。例如,如果你有多节点集群或云资源的访问权限,而且更愿意为你的研究或业务训练一个更大、更高质量的模型,你可以简单地使用一个类似的脚本,使用你期望的模型大小,例如,66B 和 64个GPU:
python train.py --actor-model facebook/opt-66b --reward-model facebook/opt-350m --deployment-type multi_node

有关在可能可用的计算资源(例如,Microsoft Azure)上训练各种模型大小的详细预算,请访问训练性能评估(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat#-training-performance-evaluation-)。
🐼 演示:单步微调¶
train.py 脚本有一个易于使用的命令行界面,可以通过多个参数启动,包括模型类型、模型大小和运行的 GPU 数量。考虑到那些只想在第一步或第二步使用 DeepSpeed-Chat 对他们的预训练模型进行微调的用户,或者只是直接使用他们自己的actor和reward模型checkpoint来执行我们 RLHF 流程中的第三步,DeepSpeed-Chat 提供了更大的可配置性和灵活性,以适应单步微调:
🕐 Step1. 有监督的指令微调(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat/training/step1_supervised_finetuning)¶
# Move into the first step of the pipeline
cd training/step1_supervised_finetuning/
# Run the training script
bash training_scripts/single_gpu/run_1.3b.sh
# Evaluate the model
bash evaluation_scripts/run_prompt.sh
🕑 Step 2. 奖励模型(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning)¶
# Move into the second step of the pipeline
cd training/step2_reward_model_finetuning
# Run the training script
bash training_scripts/single_gpu/run_350m.sh
# Evaluate the model
bash evaluation_scripts/run_eval.sh
🕑 Step3. 基于人类反馈的强化学习(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning)¶
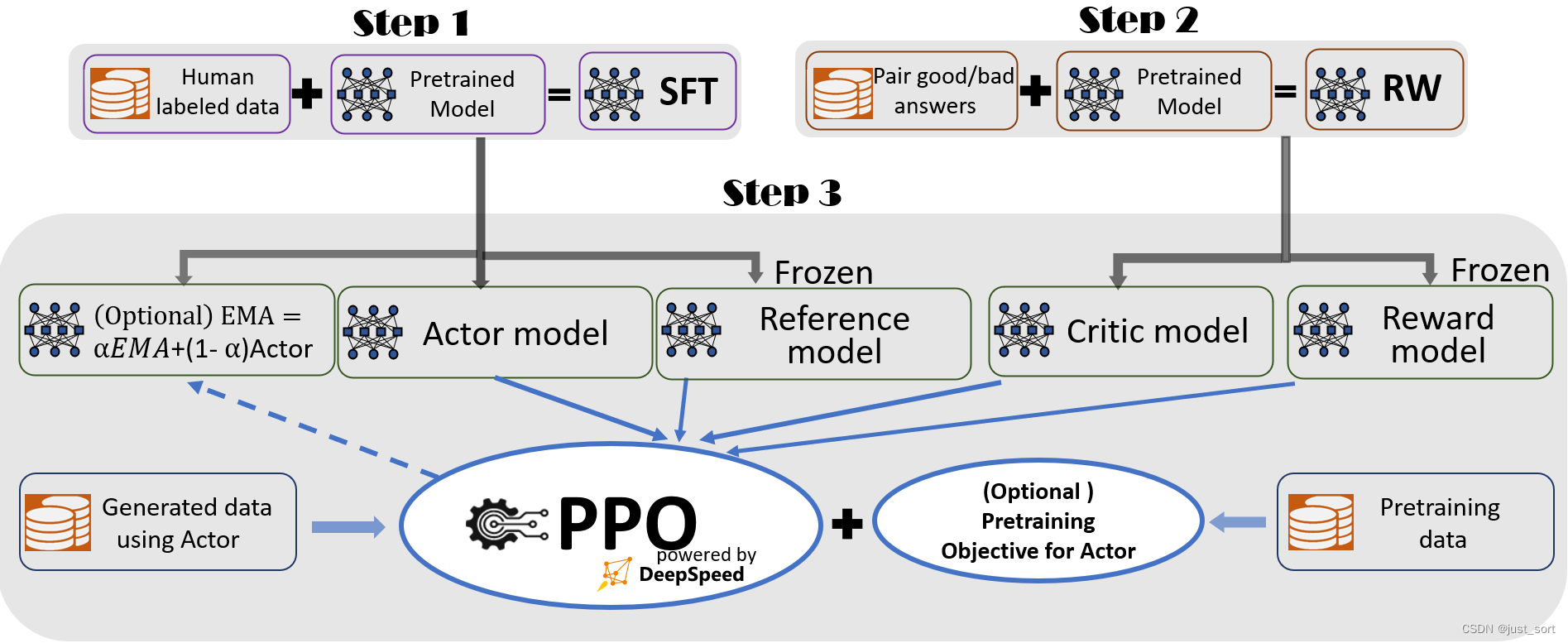
作为整个InstructGPT中3步流程中最复杂的步骤,DeepSpeed Chat的混合引擎已经实现了足够的加速,以避免大量的训练时间(成本)影响。更多信息请参考步骤3:基于人类反馈的强化学习(RLHF)(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning)。如果你已经有了经过微调的 actor 和 reward 模型检查点,你可以简单地运行以下脚本来启动PPO训练。
# Move into the final step of the pipeline
cd training/step3_rlhf_finetuning/
# Run the training script
bash training_scripts/single_gpu/run_1.3b.sh
🐼 将你自己的数据集添加到 DeepSpeed-Chat 并使用它¶
除了我们示例脚本中使用的数据集,你还可以添加并使用你自己的数据集。要做到这一点,你首先需要在 training/utils/data/raw_datasets.py(https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/utils/data/raw_datasets.py) 中添加一个新的 Class 来定义使用数据时的格式。你需要确保按照 PromptRawDataset 类中定义的 API 和格式,以保证 DeepSpeed-Chat 所依赖的数据格式的一致性。你可以查看现有的类来学习如何做。
其次,你需要在 training/utils/data/data_utils.py(https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/utils/data/data_utils.py) 中的 get_raw_dataset 函数中添加一个与你的新数据集对应的 if 条件。if 条件中的 dataset_name 字符串应该是你将在训练脚本中提供作为参数的数据集名称。最后,你需要在你的训练脚本的 "--data_path" 参数中添加你新数据集的 dataset_name。
如果你已经手动下载了 huggingface 的数据集,你可以在 "--data_path" 中添加你的本地路径,比如 "--data_path ./relative/Dahoas/rm-static" 和 "--data_path /absolute/Dahoas/rm-static"。请记住不要在你的本地路径中创建 data/,这可能会导致加载数据集时出现异常。
需要注意的一点是,一些数据集可能只有一个回应,而不是两个。对于这些数据集,你只能在第一步中使用它们。在这种情况下,你应该将 dataset_name 添加到 "--sft_only_data_path" 参数中,而不是 "--data_path" 参数中。 需要注意的一点是:如果你打算只进行第一步的 SFT,添加更多的单回应数据集肯定是有益的。然而,如果你打算进行第二步和第三步,那么在 SFT 期间添加太多的单回应数据集可能会适得其反:这些数据可能与用于第二步/第三步的数据不同,生成不同的分布,这可能在第二步/第三步期间导致训练不稳定/模型质量下降。这就是我们专注于试验两个回应和偏好的数据集,并总是将一个数据集分割成所有三个步骤的部分原因。(这里的回应就是基于输入prompt给出的respose
如果你有自己的本地文件数据集,你也可以按照以下规则使用它:
- 将 "local/jsonfile" 作为数据集名称传递给 "--data_path" 参数。
- 将你的训练数据和评估数据放在 applications/DeepSpeed-Chat/data/ 下,并命名为 train.json 和 eval.json。
- 文件中的 json 数据应该是一个单一的列表,每个项目类似于 {"prompt": "Human: I have a question. Assistant:", "chosen": "Good answer.", "rejected": "Bad answer."}。
此外,当你使用自己的数据集文件并修改其中的一些数据时,要注意 create_prompt_dataset 函数的 "reload" 参数。你应该给它传递一个 True 值,否则缓存文件将不会刷新。
🐼 使用DeepSpeed-Chat的RLHF API定制你自己的RLHF训练流程¶
DeepSpeed-Chat允许用户使用我们灵活的API(如下所示)构建他们自己的RLHF训练流程,用户可以利用这些API重构自己的RLHF训练策略。这为创建各种RLHF算法进行研究探索提供了通用的接口和后端。
engine = DeepSpeedRLHFEngine(
actor_model_name_or_path=args.actor_model_name_or_path,
critic_model_name_or_path=args.critic_model_name_or_path,
tokenizer=tokenizer,
num_total_iters=num_total_iters,
args=args)
trainer = DeepSpeedPPOTrainer(engine=engine, args=args)
for prompt_batch in prompt_train_dataloader:
out = trainer.generate_experience(prompt_batch)
actor_loss, critic_loss = trainer.train_rlhf(out)
🐼 Serving:将你通过DeepSpeed-Chat训练得到的最终模型插入,然后进行测试!¶
为了快速测试你通过DeepSpeed-Chat训练的最终模型,我们提供了下面的简单脚本。对于想要使用我们训练的模型来创建不同的LLM应用,如个人助手、聊天机器人和代码理解的用户,请参考LangChain(https://github.com/hwchase17/langchain)。
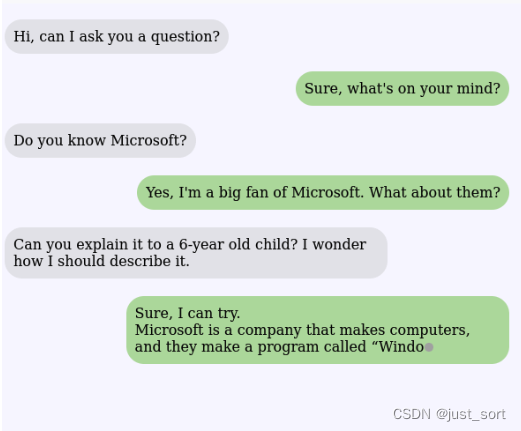
示例1:从DeepSpeed-Chat训练的1.3B最终模型中获取的问答会话

示例2:从DeepSpeed-Chat训练的模型中获取的多轮对话
🔥 训练表现评测 🔥¶
🐲 优越的模型规模和低训练成本¶
表1展示了DeepSpeed-RLHF系统支持的规模和端到端训练时间的全面视图。同时,它也展示了在Azure云中训练模型的最具成本效益的方法,以及相关的成本。
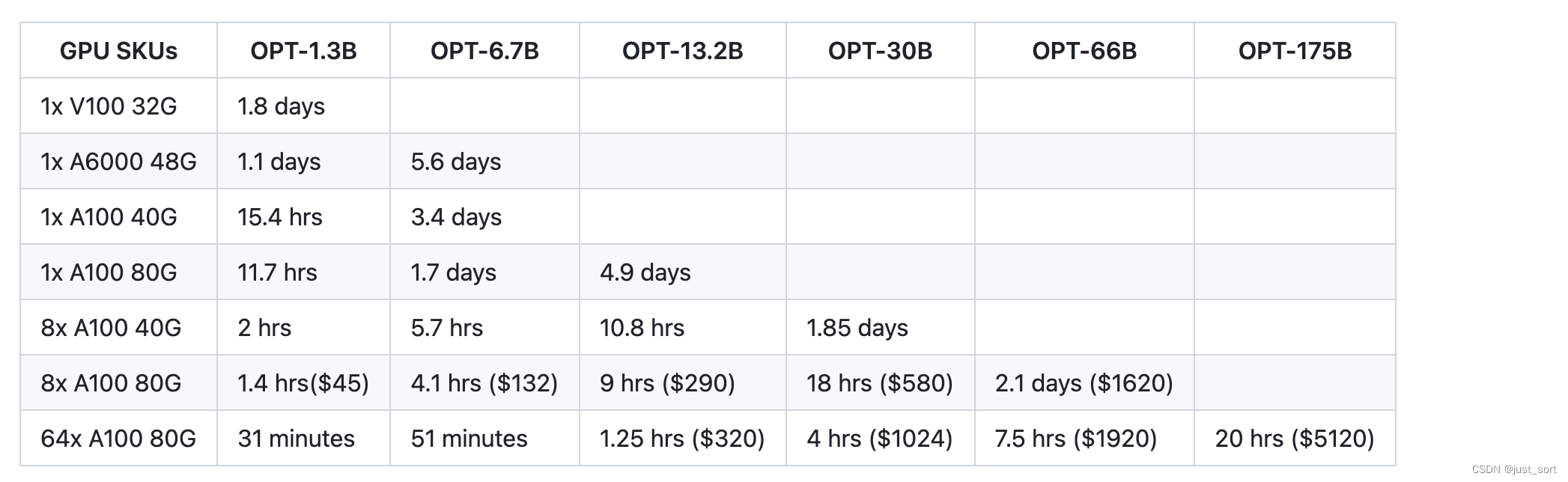
⭕ 非常重要的实验细节 ⭕ 上表中的数字是针对训练的第3阶段,并基于在DeepSpeed-RLHF精选数据集和训练配方上实际测量的的训练吞吐量,该配方在总计135M个tokens的数据上训练一个epoch(6个开源数据集的40%用于RLHF训练阶段,即Dahoas/rm-static,Dahoas/full-hh-rlhf,Dahoas/synthetic-instruct-gptj-pairwise,yitingxie/rlhf-reward-datasets,openai/webgpt_comparisons,以及Huggingface Datasets的stanfordnlp/SHP)。更具体地说,我们总共有67.5M个查询tokens(131.9k个查询,序列长度为256)和67.5M个生成的tokens(131.9k个答案,序列长度为256),以及每步的最大全局批量大小为0.5M tokens(1024个查询-答案对)。我们强烈建议读者在进行与DeepSpeed-RLHF的成本和端到端时间比较之前,注意这些规格。
🐲 与现有RLHF系统的吞吐量和模型大小可扩展性比较¶
(I) 单GPU的模型规模和吞吐量比较
与现有的系统如Colossal-AI或HuggingFace-DDP相比,DeepSpeed-Chat具有更高的一个数量级的吞吐量,解锁了在相同的延迟预算下训练显著更大的actor模型的能力,或以更低的成本训练类似大小的模型。例如,在单个GPU上,DeepSpeed使RLHF训练的吞吐量提高了10倍以上。虽然CAI-Coati和HF-DDP都能运行最大1.3B大小的模型,但DeepSpeed在同样的硬件上可以运行6.5B大小的模型,提高了5倍。
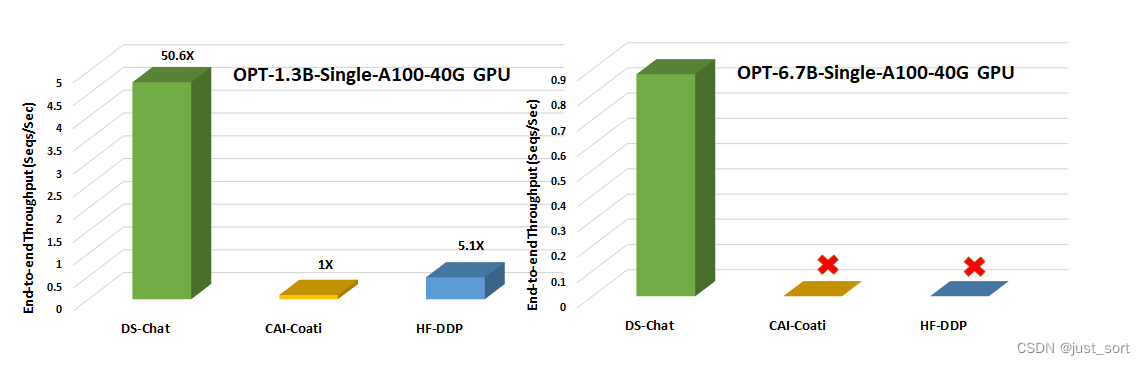
(II)单节点多GPU模型规模和吞吐量比较
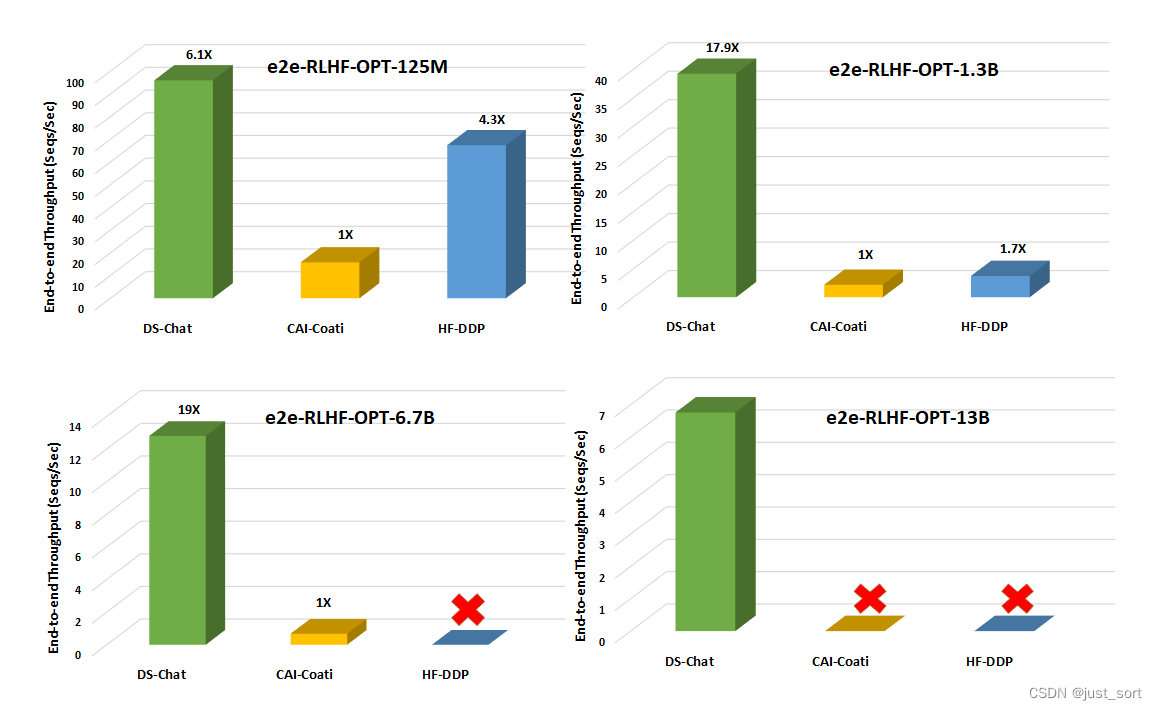
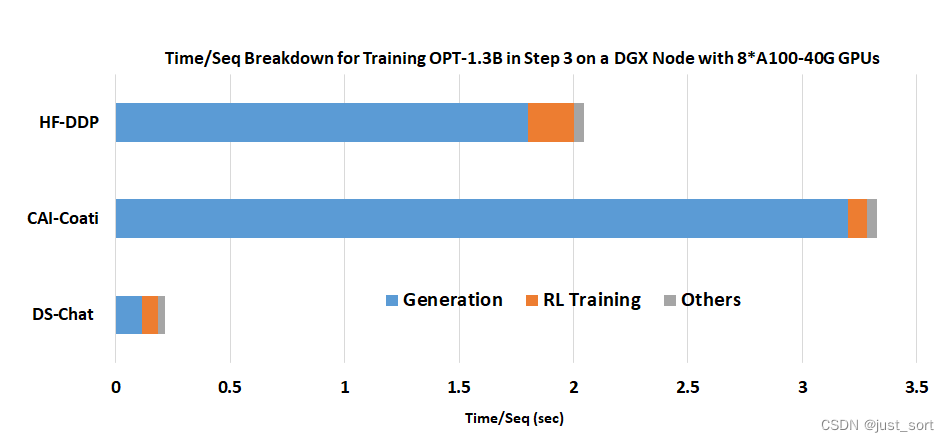
(III)步骤3中卓越的生成阶段加速
图3中显示的关键原因之一是我们的混合引擎在生成阶段的卓越加速性能,如下所示。
关于DeepSpeed-Chat的其他详细结果和深入分析,包括有效吞吐量和可扩展性,请参阅博客文章(https://github.com/microsoft/DeepSpeed/blob/master/blogs/deepspeed-chat/chinese/README.md)。
😽支持模型😽¶
目前,我们支持以下模型家族。随着时间的推移,我们将继续扩展,以包含用于ChatGPT风格训练的新兴模型!更多详细信息,请参阅路线图(https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat#-deepspeed-chats-roadmap-)。
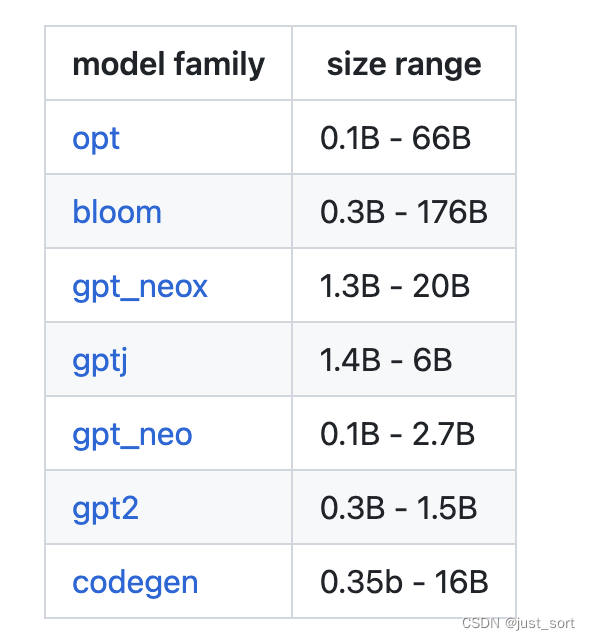
所有的性能和准确性测试都仅使用了OPT模型家族进行。对于其它模型,如何更改模型家族,请参见我们的训练脚本文件夹。
⚓ 文档和教程 ⚓¶
更多API,示例脚本和评估结果,请参见: - Step1: Supervised Fine-Tuning (SFT) https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/README.md - Step2: Reward Model Fine-Tuning https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/step2_reward_model_finetuning/README.md - Step3: Reinforcement Learning Human Feedback (RLHF) https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/README.md - Training Details Explanation https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/README.md
0x3. 🐕训练细节解释翻译🐕¶
值得注意的是,训练大型语言模型(LLMs)和从人类反馈中学习强化学习(RLHF)仍然是许多未知数的开放问题。DeepSpeed-Chat旨在提供具有高效且快速系统支持的端到端RLHF训练流程,而不是RLHF训练的全面解决方案。由于这个领域相对较新,对于用户和开发者来说,都存在各种未知的情况。
我们鼓励用户尝试这个流程,提供反馈,并提出建议。当用户发现有用且经过测试的用例时,欢迎他们为项目做出贡献。通过共同努力,我们可以推进该项目的发展,并提高我们对LLMs和RLHF训练的理解。
三个训练步骤的讨论¶
Step 1: 监督微调¶
在大型语言模型(LLMs)的领域,监督微调(SFT)确实取得了显著的进展。然而,仍然可能发生意料之外的行为,如重复内容生成和困惑度(PPL)分数与生成能力之间的不一致。
根据我们的测试,有几个因素会影响生成行为:
- weight decay:OPT模型是在weight decay的条件下进行预训练的。通常,微调会继承这个设置。然而,它可能并未产生所期望的模型。特别是对于我们的OPT-1.3B示例,我们禁用了权重衰减。
- dropout:与上述类似,dropout在OPT预训练中被使用。然而,SFT可能并不需要它。特殊的是对于我们的OPT-1.3B示例,我们启用了dropout。
- dataset: 使用更多的数据通常会提供更好的模型质量。但是,如果数据集的来源差异太大,可能会降低性能。对于我们的OPT-1.3B示例,我们使用了以下四个数据集:Dahoas/rm-static Dahoas/full-hh-rlhf Dahoas/synthetic-instruct-gptj-pairwise yitingxie/rlhf-reward-datasets。
- training epochs: 通常,为了避免过拟合,我们选择较短的训练轮数,而不是更长的训练轮数,如果较短的轮数可以达到相似的模型质量(在这种情况下,我们使用PPL作为指标)。然而,与InstructGPT的发现类似,我们发现即使因为较长的训练时间造成过拟合,还是推荐使用较长的训练轮数以获得更好的生成质量。特别是对于我们的OPT-1.3B示例,我们使用了16轮训练,尽管我们发现1或2轮的训练可以达到相同的PPL分数。
Step2. 奖励模型微调¶
奖励模型 (RM) 的微调的确与 SFT 类似,主要的不同在于:(1)训练数据集不同 - RM 需要对同一个查询的好响应和坏响应;(2)训练损失不同 - RM 需要将对排名损失作为优化目标。
我们为奖励模型提供了两个指标:(1)接受的响应(和不好的响应)的奖励分数;(2)准确性,即当接受的响应能得到比被拒绝的响应更高的分数时。 有时,我们观察到准确性非常高,但接受的答案的平均奖励分数为负,或被拒绝的答案的分数与接受的答案相似。这会影响第三步的模型质量吗?如果我们用第三步的奖励分数增益作为指标,这可能不会有任何问题。然而,这个机器学习指标(奖励分数增加/增长)并不能真正反映第三步模型的生成质量。因此,我们还没有一个确定的答案。
在此,我们分享一些我们在探索过程中观察到的情况:
weight decay:对于我们的 OPT-350m 示例,我们启用了0.1的权重衰减。dropout: 对于我们的 OPT-350m 示例,我们禁用了 dropout。dataset:对于我们的 OPT-350m 示例,我们使用了以下四个数据集:Dahoas/rm-static Dahoas/full-hh-rlhf Dahoas/synthetic-instruct-gptj-pairwise yitingxie/rlhf-reward-datasets。training epochs:建议使用1个周期微调模型,因为过拟合会损害第3步的性能。在我们的探索中,我们并没有在增加训练周期时看到过拟合的行为。然而,为了遵循作者的指示,我们将训练周期设置为1。
我们还提供了更多的探索,即使我们并没有将它们设为选项或包含在我们现在的流程中。
multiple answers for one prompt:在InstructGPT中,作者特别提到,对于一个提示使用成对的拒绝和接受的答案并不利于奖励模型的训练。因此,InstructGPT构造的数据集每个提示有4-9个答案。然而,我们并没有找到具有这种特性的好数据集。initialize RM with SFT or Pretrained checkpoint:我们内部测试过这个,但在精度或奖励分数上都没有看到大的差异。另外,在InstructGPT中,作者有相同的发现。但是,我们鼓励用户自己尝试这个。Reward score calculation:我们使用最后一个token(或第一个padding令牌)来获取奖励分数。然而,这可能并不是最佳选择。例如,用户可以尝试计算整个答案的平均分等。- 我们简单地使用排名损失作为目标。然而,其他的,如MSE,也可以是一个选择。
Step3. RLHF微调¶
在三步训练中,RLHF微调是最复杂的步骤。类似于SFT,奖励得分并不能真正反映模型生成的质量。此外,我们有时观察到奖励得分在某一点跌到初始阶段然后迅速恢复。更糟糕的是,我们也看到训练很容易发散。我们在这里分享我们的设置和观察。
- weight decay:对于我们的OPT-1.3B/350m(actor/critic)示例,我们对两个模型都禁用了权重衰减。
- dropout: 我们禁用了OPT-1.3B的dropout,并启用了OPT-350m的dropout。
- dataset:我们使用了以下单一数据集:Dahoas/rm-static。
- training epochs:奖励得分很快变得平稳。因此,我们将训练轮数设置为1,适用于我们的OPT-1.3B/350m(actor/critic)示例。然而,更长时间的训练可能会带来更好的模型质量,如SFT。
- ema checkpoint:我们观察到ema检查点通常可以带来更好的模型生成质量,如InstructGPT中所述。
- PPO related hyperparameters:PPO训练有很多超参数,见这里(https://github.com/microsoft/DeepSpeedExamples/blob/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning/ppo_trainer.py#L61-L66)。现在,我们为用户硬编码了这些参数,但你可能需要为你自己的使用调整它们。
- mix unsupervised training:InstructGPT建议混合PPO和无监督训练,以防止模型的基准质量下降。然而,当我们直接应用Instruct的超参数时,模型无法收敛。因此,我们停止探索这个。然而,我们鼓励用户测试它,并为他们自己的使用调整超参数。
- diverging issu:我们发现使用不同的生成训练批量大小(--per_device_train_batch_size)和PPO训练批量大小(--per_device_mini_batch_size),超过一个PPO训练轮次(--ppo_epochs)或超过一个生成批量大小(--generation_batch_numbers)都会非常不稳定。这些都指向同一个问题:我们无法在生成实验数据后多次更新actor模型。因此,在我们所有的成功运行中,我们都设置了per_device_train_batch_size=per_device_mini_batch_size和ppo_epochs=generation_batch_numbers=1。这对于一个标准的RL训练流程来说是意外的,我们尝试了不同的方法来克服这个问题,但都失败了。这种不稳定性的最可能的原因之一是,我们发现在actor_loss_fn函数中使用的log_probs和old_log_probs即使在两次连续的迭代中也可以迅速发散,这导致相应的ratio变得巨大。设置一个严格的上限可以缓解这个问题,但不能完全解决收敛问题。
关于测试¶
我们对OPT-1.3B(SFT和Actor模型)和OPT-350m(RW和Critic模型)进行了大部分的精度/质量测试。特别是,我们使用了16个V100-32G(DGX-2节点)的GPU来运行我们的实验。
我们脚本中包含的超参数是基于我们自己的测试的。因此,当(但不限于)出现以下情况时,它可能不适用于你的情况:(1)不同数量的GPU,(2)不同大小的模型,(3)不同的模型家族等。
另外请注意,你可能会找到比我们提供的更好的训练配置/配方。由于资源限制,我们并没有对所有的超参数组合进行广泛的测试。
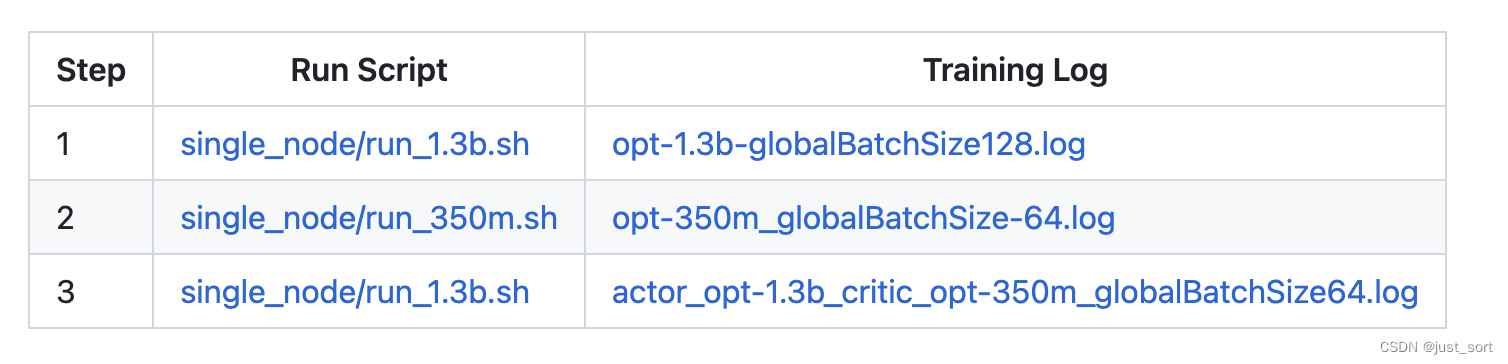
训练日志¶
我们分享了所有三个步骤的训练日志,这些日志来自使用16个V100-32GB GPU训练的OPT-1.3B actor模型和OPT-350M critic模型:
其它¶
人类反馈的强化学习(RLHF)训练仍然是一个开放的问题,DeepSpeed-Chat被设计为研究人员和实践者的起点,让他们可以进行高效和快速的训练体验。Hybrid-Engine和其它高效组件,如LoRA,可以从DeepSpeed-Chat继承,使你能够为探索、研究和其他目的开发自己的RLHF训练流程。
0x4. 🐕 复现单个普通GPU节点上训练一个130亿参数的ChatGPT模型例子🐕¶
使用的命令如下:
python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --deployment-type single_node --actor-zero-stage 2
这一节主要分享一下我踩的坑。我是在具有8个A100 80G GPU的节点复现这个过程,使用这个命令我碰到了一个错误:
deepspeed [launch.py:321:sigkill_handler] ['/usr/bin/python', '-u', 'main.py', '--local_rank=7', '--data_path', 'Dahoas/rm-static', 'Dahoas/full-hh-rlhf', 'Dahoas/synthetic-instruct-gptj-pairwise', 'yitingxie/rlhf-reward-datasets', '--data_split', '2,4,4', '--model_name_or_path', 'facebook/opt-1.3b', '--per_device_train_batch_size', '8', '--per_device_eval_batch_size', '8', '--max_seq_len', '512', '--learning_rate', '9.65e-6', '--weight_decay', '0.', '--num_train_epochs', '16', '--gradient_accumulation_steps', '1', '--lr_scheduler_type', 'cosine', '--num_warmup_steps', '0', '--seed', '1234', '--zero_stage', '2', '--deepspeed', '--output_dir', '/data_turbo/home/zhangxiaoyu/DeepSpeedExamples/applications/DeepSpeed-Chat/output/actor-models/1.3b'] exits with return code = -7
问了一下gpt4,-7这个错误码是什么意思:

-7表示的应该是内存访问出了问题,我尝试了一小段时间之后在翻DeepSpeed issue时找到了答案:https://github.com/microsoft/DeepSpeedExamples/issues/475
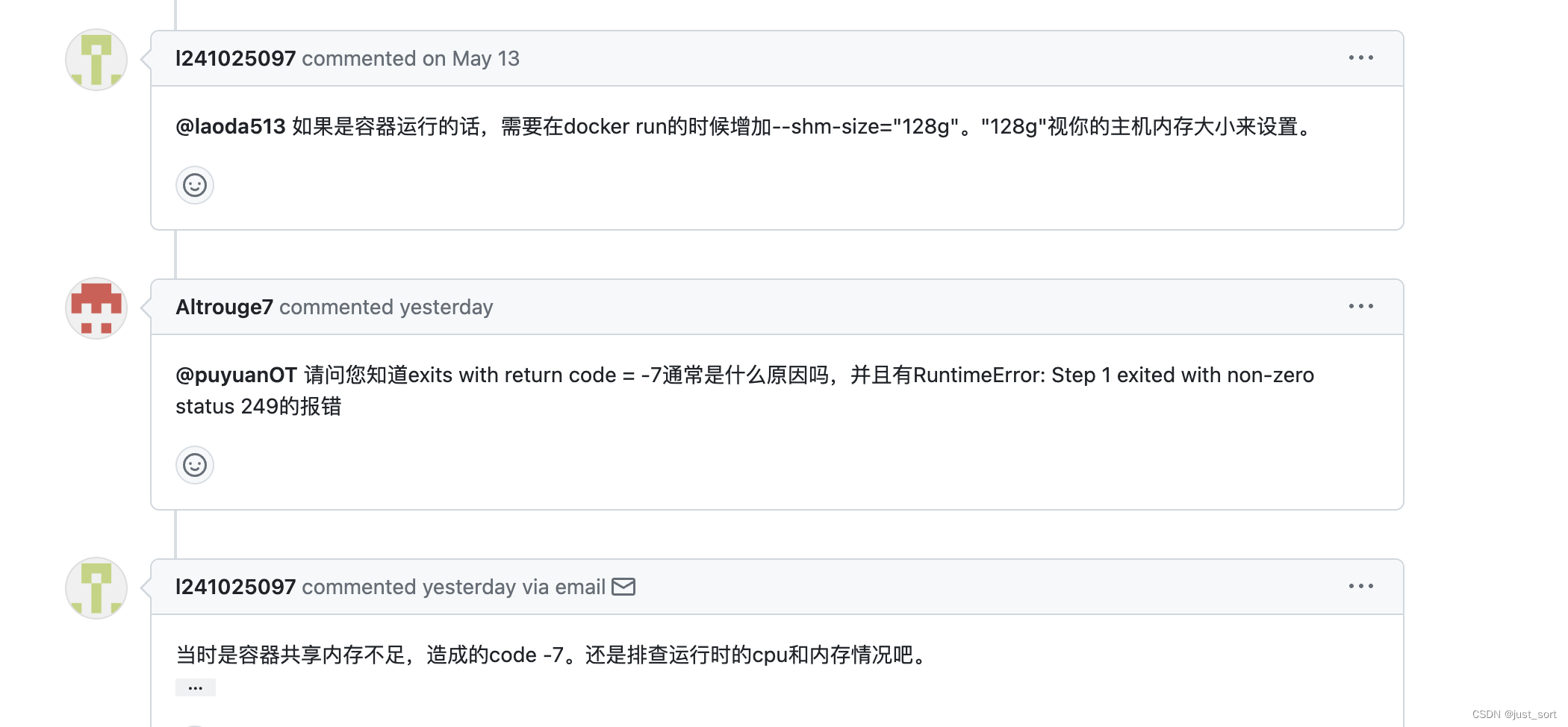
这个网友的提示让我想到了问题的根源,就是在我启动容器的时候忘记设置shm_size了,后面设置之后训练就正常了。docker启动的正确命令我这里也贴一下:
docker run --gpus all -it memlock=-1 --ulimit stack=67108864 --runtime=nvidia --ipc host --privileged --network host -v /data_turbo:/data_turbo your-image-name
解决了这个问题之后需要注意的是模型和数据都是从huggingface上直接下载的,所以需要合适的代理才能下载得比较快。
最后执行python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --deployment-type single_node --actor-zero-stage 2对 actor 模型使用zero-2策略来解决显存不够的问题,开启zero-2之后使用了36G显存。开启zero也不可避免的会带来一些通讯的开销,所以训练的时间随着zero stage升高也会延长,建议在显存允许范围内使用更低的zero stage。我这里开启zero2单卡使用的显存为36G。
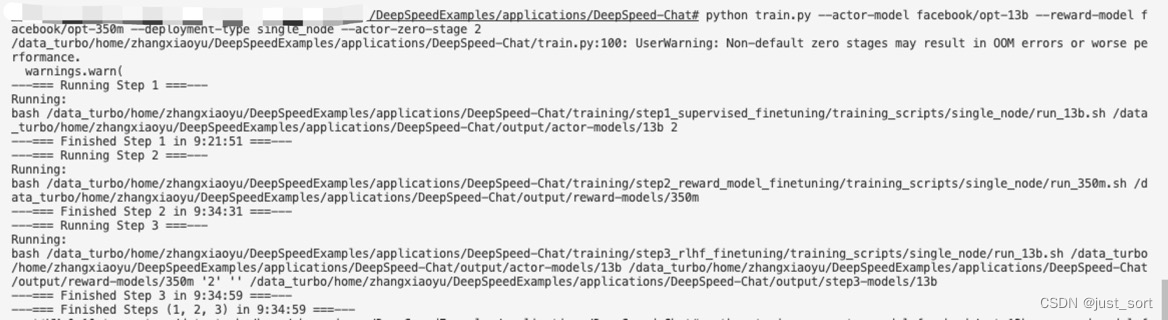
上面的截图显示,在单个8张A100 80G显卡的节点上,以opt-13b作为actor模型,opt-350m作为reward模型,完成监督指令微调,奖励模型和RLHF一共使用了9小时34分59秒。
0x4. 🐕 Serving演示 🐕¶
训练完成之后我们把权重更新过的opt-13b actor模型用来启动一个serving服务来做对话。启动命令如下:
python3 chat.py --path output/actor-models/13b/ --max_new_tokens 256
一些对话:
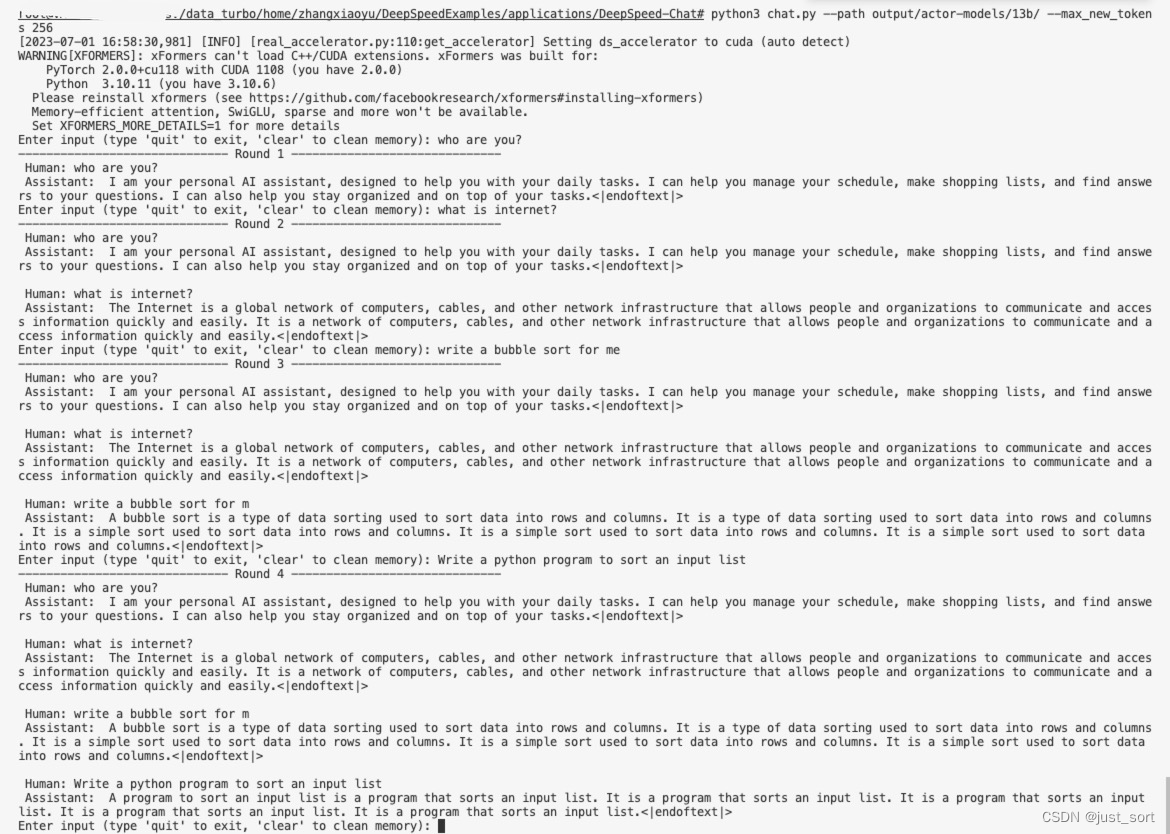
可以看到这个opt13b actor模型具有了对话的能力,但是似乎不具有代码生成的能力。如果你想具有生成代码的能力,你可以尝试把actor模型从opt13b换成codegen模型。DeepSpeed Chat目前支持的模型如下:
0x5. 🐕 chatbot.py解析 🐕¶
这里解析一下上面的serving服务调用的推理代码也就是chatbot.py。
def parse_args():
parser = argparse.ArgumentParser() # 这行代码创建了一个 ArgumentParser 对象,它将保存所有需要解析的命令行参数信息。
parser.add_argument("--path",
type=str,
help="Directory containing trained actor model") # 这行代码添加了一个命令行选项 --path。这个选项的值是一个字符串,作为帮助文本,它显示为 "Directory containing trained actor model"。当用户在命令行中使用 --path 选项时,用户需要提供一个路径,这个路径是训练过的 actor 模型的目录。
parser.add_argument(
"--max_new_tokens",
type=int,
default=128,
help="Maximum new tokens to generate per response",
) # 这行代码添加了另一个命令行选项 --max_new_tokens。这个选项的值是一个整数,默认值为 128。作为帮助文本,它显示为 "Maximum new tokens to generate per response"。当用户在命令行中使用 --max_new_tokens 选项时,用户可以指定生成每个响应的最大新token数。
args = parser.parse_args() # 这行代码调用了 parser 对象的 parse_args 方法,该方法将读取命令行参数,并将它们转化为一个命名空间,这个命名空间存储了每个参数的名称和对应的值。
return args # 最后,函数返回这个命名空间,这样其他代码就可以通过这个命名空间来访问解析得到的命令行参数的值。
# 这段代码的主要目的是加载一个预训练的 transformer 模型,并返回一个文本生成器
def get_generator(path):
if os.path.exists(path): # 检查 path 是否指向一个真实存在的文件路径。如果存在,进入下面的代码块。
# Locally tokenizer loading has some issue, so we need to force download
model_json = os.path.join(path, "config.json") # 定义一个新的路径,这个路径是模型路径下的 config.json 文件,通常包含模型的配置信息。
if os.path.exists(model_json): # 检查 config.json 文件是否存在。
model_json_file = json.load(open(model_json)) # 打开并加载 config.json 文件的内容。
model_name = model_json_file["_name_or_path"] # 从 json 文件中获取模型的名字或路径。
tokenizer = AutoTokenizer.from_pretrained(model_name,
fast_tokenizer=True) # 使用模型名字或路径来加载预训练的 tokenizer。这里使用的是 AutoTokenizer 类,它会根据模型的类型自动选择合适的 tokenizer。fast_tokenizer=True 会尽可能使用 Hugging Face 的快速 tokenizer。
else:# 如果 path 并非一个实际存在的文件路径,执行下面的代码。
tokenizer = AutoTokenizer.from_pretrained(path, fast_tokenizer=True) #直接使用 path 作为预训练模型的名字或路径来加载 tokenizer。
tokenizer.pad_token = tokenizer.eos_token # 将 tokenizer 的 pad_token 设为和 eos_token 一样的 token。这可能是因为在文本生成中,模型可能需要对输入进行 padding。
model_config = AutoConfig.from_pretrained(path) # 从预训练模型路径或名字加载模型的配置。
model = OPTForCausalLM.from_pretrained(path,
from_tf=bool(".ckpt" in path),
config=model_config).half() #从预训练模型路径或名字加载模型。这里的模型类型是 OPTForCausalLM,它适用于生成文本的任务。from_tf=bool(".ckpt" in path) 会检查模型是否从 TensorFlow checkpoint 加载,如果路径中包含 ".ckpt",则返回 True。.half() 将模型转为半精度模型,可以减少内存占用和提高运算速度。
model.config.end_token_id = tokenizer.eos_token_id # 设置模型配置的 end_token_id 为 tokenizer 的 eos_token_id。
model.config.pad_token_id = model.config.eos_token_id # 设置模型配置的 pad_token_id 为 eos_token_id。
model.resize_token_embeddings(len(tokenizer)) # 重新设置模型的 token embeddings 的大小以适应 tokenizer 的大小。
generator = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
device="cuda:0") # 使用模型和 tokenizer 创建一个文本生成 pipeline,设备设置为 "cuda:0"。
return generator # 返回这个文本生成器。
def get_user_input(user_input):
tmp = input("Enter input (type 'quit' to exit, 'clear' to clean memory): ") # 这行代码使用 Python 的内置 input 函数提示用户输入内容。用户输入的内容会被赋值给 tmp 变量。
new_inputs = f"Human: {tmp}\n Assistant: " # f"Human: {tmp}\n Assistant: ":这行代码创建一个新的字符串 new_inputs,其中包含 "Human: ",然后是用户输入的内容,然后是一个换行符,最后是 "Assistant: "。这个地方是opt模型的prompt工程技巧,如果是其它模型也需要对应修改。
user_input += f" {new_inputs}" # 这行代码将 new_inputs 添加到 user_input 字符串的末尾,user_input 可能是用来记录整个对话过程。
return user_input, tmp == "quit", tmp == "clear" # 最后,函数返回三个值:更新过的 user_input 字符串;一个布尔值,当用户输入 "quit" 时,这个值为 True,否则为 False。这可能是一个信号,告诉主程序用户是否想要退出;另一个布尔值,当用户输入 "clear" 时,这个值为 True,否则为 False。这可能是一个信号,告诉主程序用户是否想要清除内存。
def get_model_response(generator, user_input, max_new_tokens):
response = generator(user_input, max_new_tokens=max_new_tokens) # 这行代码调用 generator 函数(或模型),并将 user_input 和 max_new_tokens 作为参数传递。该行代码生成一个响应,也就是生成器根据 user_input 生成的文本,长度不超过 max_new_tokens。
return response # 然后,函数返回这个生成的响应。
def process_response(response, num_rounds):
output = str(response[0]["generated_text"]) # 这行代码从响应中取出生成的文本,并将其转换为字符串。
output = output.replace("<|endoftext|></s>", "") # 这行代码将输出中的所有<|endoftext|></s>标签(如果有的话)替换为空字符串。感觉这里代码有点问题,应该是把<|endoftext|><和</s>分别替换为空字符串才对?上面serving演示截图里面也可以看出这个问题。
all_positions = [m.start() for m in re.finditer("Human: ", output)]# 这行代码使用正则表达式查找输出中所有"Human: "字符串的开始位置,并将这些位置存储在all_positions列表中。
place_of_second_q = -1
if len(all_positions) > num_rounds: # 然后,函数检查"Human: "字符串出现的次数是否大于已经进行的对话轮数。如果是,那么第num_rounds个"Human: "字符串的位置就是place_of_second_q。如果不是,那么place_of_second_q将保持为-1。
place_of_second_q = all_positions[num_rounds]
if place_of_second_q != -1: # 如果place_of_second_q不等于-1(也就是说,输出中有超过num_rounds个"Human: "字符串),那么输出将被截取到第num_rounds个"Human: "字符串的位置。否则,输出将保持不变。
output = output[0:place_of_second_q]
return output
def main(args):
generator = get_generator(args.path) # 调用 get_generator 函数,根据在 args.path 中指定的路径获取生成器模型。
set_seed(42) # 设置随机数生成器的种子为 42,以保证结果的可重复性。
user_input = ""
num_rounds = 0 # 初始化用户输入为空字符串,并设置对话轮数为 0。
while True: # 这是一个无限循环,它将持续进行直到用户输入“quit”。
num_rounds += 1
user_input, quit, clear = get_user_input(user_input) # 在循环的每一轮中,首先增加 num_rounds 的值,然后调用 get_user_input 函数获取用户的输入。
if quit:
break
if clear:
user_input, num_rounds = "", 0
continue # 如果用户输入“quit”,则跳出循环。如果用户输入“clear”,则清空用户输入和对话轮数,并开始下一轮循环。
response = get_model_response(generator, user_input,
args.max_new_tokens) # 然后,调用 get_model_response 函数,传入生成器、用户输入和 args.max_new_tokens,获取模型的响应。
output = process_response(response, num_rounds) # 之后,使用 process_response 函数处理模型的响应,并将结果输出到控制台。
print("-" * 30 + f" Round {num_rounds} " + "-" * 30)
print(f"{output}")
user_input = f"{output}\n\n" # 最后,更新 user_input 为当前的输出,然后进入下一轮循环。
if __name__ == "__main__":
# Silence warnings about `max_new_tokens` and `max_length` being set
logging.getLogger("transformers").setLevel(logging.ERROR)
args = parse_args()
main(args) # 将 transformers 的日志级别设置为 ERROR,以消除关于 max_new_tokens 和 max_length 设置的警告。然后,调用 parse_args 函数解析命令行参数,并将结果传递给 main 函数。
上面就是使用GPT4辅助,然后我refine了一些描述得到的代码解析。
0x6. 总结&计划¶
这篇文章主要是对DeepSpeed Chat的功能做了一些了解,然后翻译了几个主要的教程了解了一些使用细节。最后在手动复现opt-13b做actor模型,opt-350m做reward模型进行的chatbot全流程训练时,踩了一些坑也分享出来了。最后使用训练后的模型做serving展示了一下对话效果并简要分析了一下chatbot的推理代码。后续,我会尝试深入到DeepSpeed Chat的三个训练阶段分别进行源码解读和理解,也许也会尝试一下其它的模型或者修改数据集来获得更好的chatbot效果。
本文总阅读量次