感觉这篇paper有几个亮点,首先把Megatron-LM的Self-Attention模块的模型并行方式变成序列并行,优化了通信量,同时通过计算和通信重叠近一步压缩了训练迭代时间。另外,在使用重计算的时候发现当前Huggingface/Megatron-LM的重计算策略和FlashAttentionV2同时工作的话会导致Transformer Layer多计算一次Flash Attention的forward,然后修正了这个问题,获得了很直接的性能提升。paper的代码实现基于Triton并且不算长,后面尝试讲解这里的代码,应该会先从这里的DISTATTN开始。
0x0. 前言¶
从 https://github.com/RulinShao/LightSeq 注意到这篇paper(https://arxiv.org/pdf/2310.03294.pdf),paper里面有一些比较有趣的发现并且这个paper的代码是基于Triton来实现的,所以激发了我阅读兴趣。我后续也会从源码的角度来解读这篇paper核心idea的代码实现,顺便学习下Triton。介于篇幅原因,这篇文章只读一下这篇paper,把握一下核心的Infra相关的idea。这篇paper应该还没有中会议,处于openreview阶段。
 从题目可以看出这是一个专注于提升LLM长文本训练长度的工作。
从题目可以看出这是一个专注于提升LLM长文本训练长度的工作。
0x1. 摘要¶
 提高大型语言模型(LLMs)训练时的上下文长度可以解锁根本性的新能力,但也显著增加了训练的内存占用。Megatron-LM通过模型并行以及并行计算注意力头引入了大量的通信,所以在继续增大模型规模时会受限(在介绍的部分会详细说这里的受限原因)。这篇paper介绍了一种针对长上下文LLMs训练的新方法,LIGHTSEQ。LIGHTSEQ有许多显著的优点。首先,LIGHTSEQ在序列维度上进行切分,所以对模型架构是无感的,且可直接应用于具有不同数量注意力头的模型,如Multi-Head、Multi-Query和Grouped-Query注意力。其次,LIGHTSEQ不仅在流行的LLMs上比Megatron-LM减少了高达4.7倍的通信量,而且还实现了通信与计算的重叠。为了进一步减少训练时间,LIGHTSEQ采用了一种新的Activation Checkpointing方案,以绕过内存高效的自注意力实现的前向过程(指的应该就是FlashAttention)。我们在Llama-7B及其变体上评估了LIGHTSEQ,序列长度从32K到512K。通过在单节点和跨节点训练上的全面实验,我们展示了LIGHTSEQ达到了高达1.24-2.01倍的端到端加速,并且与Megatron-LM相比,LIGHTSEQ在具有更少注意力头的模型上实现了2-8倍更长的序列长度。代码开源在https://github.com/RulinShao/LightSeq。
提高大型语言模型(LLMs)训练时的上下文长度可以解锁根本性的新能力,但也显著增加了训练的内存占用。Megatron-LM通过模型并行以及并行计算注意力头引入了大量的通信,所以在继续增大模型规模时会受限(在介绍的部分会详细说这里的受限原因)。这篇paper介绍了一种针对长上下文LLMs训练的新方法,LIGHTSEQ。LIGHTSEQ有许多显著的优点。首先,LIGHTSEQ在序列维度上进行切分,所以对模型架构是无感的,且可直接应用于具有不同数量注意力头的模型,如Multi-Head、Multi-Query和Grouped-Query注意力。其次,LIGHTSEQ不仅在流行的LLMs上比Megatron-LM减少了高达4.7倍的通信量,而且还实现了通信与计算的重叠。为了进一步减少训练时间,LIGHTSEQ采用了一种新的Activation Checkpointing方案,以绕过内存高效的自注意力实现的前向过程(指的应该就是FlashAttention)。我们在Llama-7B及其变体上评估了LIGHTSEQ,序列长度从32K到512K。通过在单节点和跨节点训练上的全面实验,我们展示了LIGHTSEQ达到了高达1.24-2.01倍的端到端加速,并且与Megatron-LM相比,LIGHTSEQ在具有更少注意力头的模型上实现了2-8倍更长的序列长度。代码开源在https://github.com/RulinShao/LightSeq。
0x2. 介绍¶
感觉这里的介绍对理解paper的工作是有好处的,就精准翻译一下。
具有长上下文能力的 Transformer 已经使得一些全新的应用成为可能,例如全面的文档理解、生成完整的代码库以及扩展的互动聊天(Osika, 2023; Liu 等人, 2023; Li 等人, 2023)。然而,训练能处理长序列的大型语言模型(LLMs)会导致大量的Activation内存占用,给现有的分布式系统带来了新的挑战。减少这些大量Activation内存占用的一个有效方法是将Activation切分到不同的设备上。为了实现这一点,现有系统如 Megatron-LM(Korthikanti 等人, 2023; Shoeybi 等人, 2019)通常会切分注意力头。然而,这种设计强假设注意力头的数量必须能被并行度整除,这对许多模型架构来说并不成立。例如,Llama-33B 有 52 个注意力头,这个数量不能被 NVIDIA 集群的常选并行度,如 8、16 和 32 整除。此外,分割注意力头限制了最大并行度不能大于注意力头的数量。然而,许多受欢迎的大型语言模型并没有足够的注意力头来实现并行度扩展,例如 CodeGen模型(Nijkamp 等人, 2022)只有 16 个注意力头。更有甚者,许多研究表明未来的 Transformer 架构设计可能会有更少的注意力头。例如,Bian 等人(2021)展示了单头 Transformer 在性能上超越了多头对应的版本,这对像 Megatron-LM 这样的解决方案来说是一个挑战。为了解除注意力头数的限制,我们提出仅分割输入tokens(即序列并行),而不是注意力头。我们提出了一个与模型架构无关且具有最大并行度随序列长度而随之扩展的解决方案。 具体来说,我们引入了一个可并行化且内存高效的精确注意力机制,DISTATTN(§3.1)。我们的设计使得重叠成为可能,我们可以将通信隐藏进注意力计算中(§ 3.2)。我们还提出了一种负载平衡技术,以避免因工作负载不平衡而导致的在因果语言模型中的计算bubble(§3.2)。在将 FlashAttention(Dao, 2023)算法扩展到 DISTATTN 的过程中,我们找到了一种利用底层重新计算逻辑显著提高gradient checkpointing训练速度的方法(§ 3.3)。这项技术也适用于非分布式使用的内存高效注意力,在我们的实验中转化为额外的 1.31× 速度提升(§ 4.3)。
这里对于注意力头的切分描述我觉得很怪,一般Megatron不是按照TP大小来切分自注意力头吗,而TP大小一般不会超过8的。感觉这里说的TP 16,TP 32是很不常见的设置。
paper的贡献总结如下:
- 我们设计了 LIGHTSEQ,这是一个基于序列级并行的长上下文大型语言模型(LLM)训练原型。我们开发了一种分布式内存高效精确注意力机制 DISTATTN,采用了新的负载平衡和用于因果语言模型的计算和通信重叠调度。
- 我们提出了一种新的检查点策略,当使用内存高效注意力与gradient checkpointing训练时,可以绕过一个注意力前向传播。
- 我们在 Llama-7B 及其不同注意力头模式的变体上评估了 LIGHTSEQ,并展示了与 Megatron-LM 相比,在长上下文训练中高达 2.01× 的端到端加速。我们进一步展示了 LIGHTSEQ 能够超越注意力头的数量,实现 2-8× 更长序列的训练。
0x3. 相关工作¶
这里涉及到对内存高效的自注意力,序列并行,模型并行,FSDP,Gradient checkpointing等技术的简介,由于只是简要介绍,没有干货,这里就略过了。
0x4. 方法¶
这是paper最核心的部分,需要仔细理解。在本节中,我们描述了 LIGHTSEQ 中关键组件的设计。我们首先介绍了一种分布式内存高效注意力机制,DISTATTN(§3.1),它沿序列维度并行化计算。然后,我们引入了一种用于因果语言建模的负载平衡调度,以减少计算bubble,以及一种异步通信设计,将通信与计算重叠(§3.2)。最后,我们提出了一种rematerialization-aware checkpointing 策略(§3.3),有效地减少了在Gradient checkpointing中的重计算时间。
0x4.1 分布式高效自注意力计算¶
 DISTATTN 的核心思想是将包含 N 个token的输入序列沿着序列维度均匀分割到 P 个 worker(例如 GPU)上。因此,每个 worker 只负责计算 N/P 个 token 的前向传递和后向传递。对于像前馈层(FFN)、层标准化(LN)和 Embedding 层这样的模块,token 可以独立计算,无需协调,并且工作在 worker 之间平衡。不幸的是,对于自注意力模块,其中本地 token 可能需要关注远程 token,需要协调。为了解决这个问题,每个 worker 需要收集(gather)与其它 token 关联的所有 key 和 value。为了应对通过收集所有其它 key 和 value 引入的内存压力,这个过程通过在线流式传输,即从拥有靠前 tokens 的 workers 向拥有靠后 tokens 的 workers 传输 key 和 value 来完成。更正式地,用 q_p、k_p、v_p 表示持有在 p (p\in {1, ..., P})个worker上的query、key、value输入,用 𝑎𝑡𝑡𝑛(q𝑝, k𝑝′, v𝑝′) 表示针对 𝑝-th query块和 𝑝′-th key value块的注意力计算,用 p_{local}\in {1, ..., P}表示本地排名,用 p_{remote}\in {1, ..., P} 表示远程排名。Figure 1(“平衡前”)展示了 DISTATTN 的原始版本,其中每个worker计算 q_{p_{local}} 的注意力,并遍历本地和远程的key 和 value 块。我们在计算 attn(q_{p_{local}}, k_{p_{remote}}, v_{p_{remote}})之前从排名 p_{remote} 拉取(应该是通信?) k_{p_{remote}} 和 v_{p_{remote}}。在附录 A 中,我们提供了如何在有 P 个总workers的第 p 个 worker 上使用 DISTATTN 的伪代码。
DISTATTN 的核心思想是将包含 N 个token的输入序列沿着序列维度均匀分割到 P 个 worker(例如 GPU)上。因此,每个 worker 只负责计算 N/P 个 token 的前向传递和后向传递。对于像前馈层(FFN)、层标准化(LN)和 Embedding 层这样的模块,token 可以独立计算,无需协调,并且工作在 worker 之间平衡。不幸的是,对于自注意力模块,其中本地 token 可能需要关注远程 token,需要协调。为了解决这个问题,每个 worker 需要收集(gather)与其它 token 关联的所有 key 和 value。为了应对通过收集所有其它 key 和 value 引入的内存压力,这个过程通过在线流式传输,即从拥有靠前 tokens 的 workers 向拥有靠后 tokens 的 workers 传输 key 和 value 来完成。更正式地,用 q_p、k_p、v_p 表示持有在 p (p\in {1, ..., P})个worker上的query、key、value输入,用 𝑎𝑡𝑡𝑛(q𝑝, k𝑝′, v𝑝′) 表示针对 𝑝-th query块和 𝑝′-th key value块的注意力计算,用 p_{local}\in {1, ..., P}表示本地排名,用 p_{remote}\in {1, ..., P} 表示远程排名。Figure 1(“平衡前”)展示了 DISTATTN 的原始版本,其中每个worker计算 q_{p_{local}} 的注意力,并遍历本地和远程的key 和 value 块。我们在计算 attn(q_{p_{local}}, k_{p_{remote}}, v_{p_{remote}})之前从排名 p_{remote} 拉取(应该是通信?) k_{p_{remote}} 和 v_{p_{remote}}。在附录 A 中,我们提供了如何在有 P 个总workers的第 p 个 worker 上使用 DISTATTN 的伪代码。
这一节比较核心的观点就是在不同的GPU上因为负责了不同的token部分,导致在一个GPU上计算注意力的时候需要从其它GPU上通信收集key和value,来计算得到当前GPU token的完整注意力结果。至于相比于Megatron-LM的通信量大小分析我们继续阅读paper。
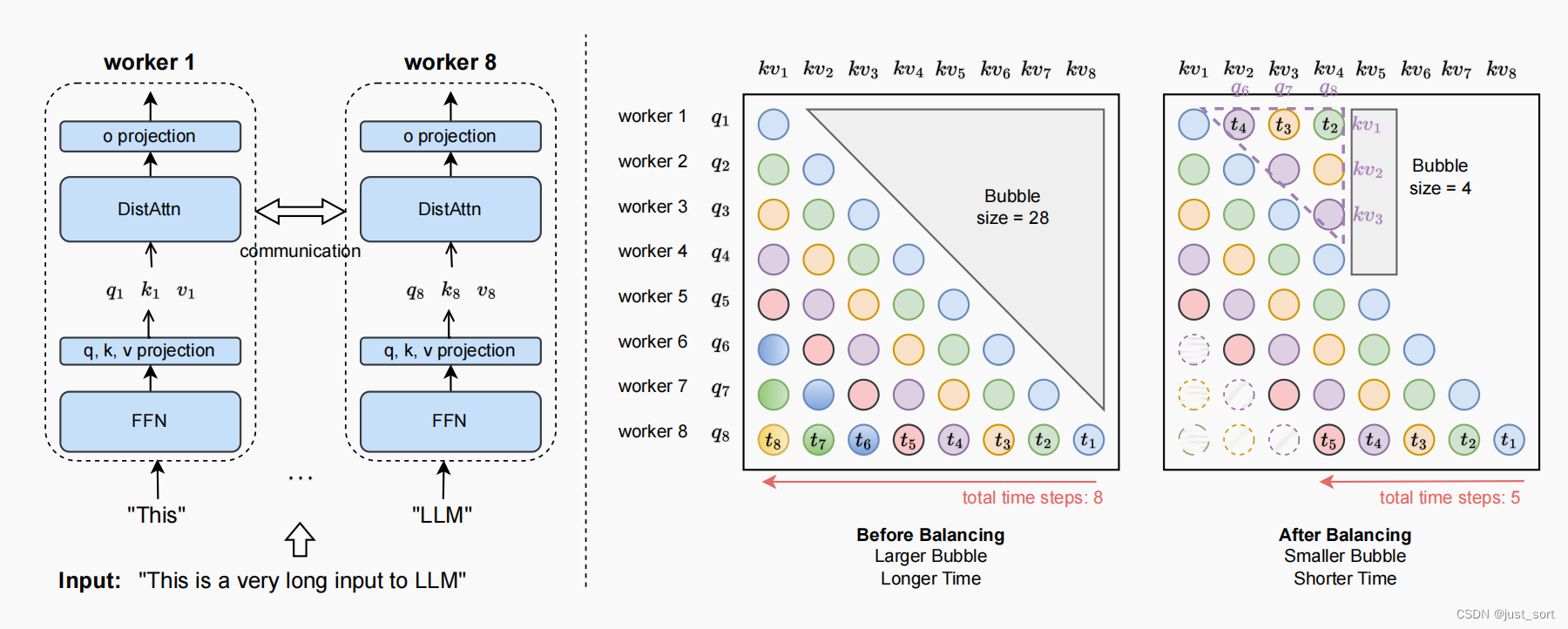 图 1:左:LIGHTSEQ 中的序列并行性。输入序列沿序列维度被分割成块并分发给不同的worker(示例中有 8 个worker)。在前向和后向过程中,只有注意力模块 DISTATTN 需要对 k,v 这种中间 Tensor 进行通信。为了简化,一些模块比如 LayerNorm 在图中被忽略。右:负载均衡调度的示意图。“Bubble size” 代表 worker 空闲的次数。因果语言模型自然引入了不均衡的工作负载,例如,worker 1 从时间步 2 到时间步 8 在平衡前是空闲的。我们通过将计算从繁忙的worker(例如,工作器 8)分配给空闲的worker(例如,工作器 1),来减少Bubble size分数,所以在平衡后worker 1 只在时间步 5 空闲。
图 1:左:LIGHTSEQ 中的序列并行性。输入序列沿序列维度被分割成块并分发给不同的worker(示例中有 8 个worker)。在前向和后向过程中,只有注意力模块 DISTATTN 需要对 k,v 这种中间 Tensor 进行通信。为了简化,一些模块比如 LayerNorm 在图中被忽略。右:负载均衡调度的示意图。“Bubble size” 代表 worker 空闲的次数。因果语言模型自然引入了不均衡的工作负载,例如,worker 1 从时间步 2 到时间步 8 在平衡前是空闲的。我们通过将计算从繁忙的worker(例如,工作器 8)分配给空闲的worker(例如,工作器 1),来减少Bubble size分数,所以在平衡后worker 1 只在时间步 5 空闲。
0x4.2 负载均衡调度与通信和计算重叠¶

因果语言模型目标是大型语言模型(LLMs)最普遍的目标之一,其中每个token只关注其前面的token。这自然在我们的块状注意力中引入了worker之间的工作不平衡:如上面的Figure 1(“平衡前”)所示,在一个 8 worker(P = 8)的场景中,最后一个 worker 需要关注其他所有 7 个 worker 的token,而第一个 worker 在关注其本地 token 后就闲置了,这导致了总共 28 的空闲时间。一般形式下,空闲比例为 \frac{P^2-P}{2P^2}(当 𝑃 → ∞时,→ ½),这意味着大约一半的 worker 是空闲的。为了减少这种空闲时间(也称为气泡时间),我们让早期完成本地计算的 q_{p_{local}} worker 帮助计算后来的 q_{p_{remote}} worker。例如,我们让worker 1 计算 attn(q_8, k_1, v_1) 并将结果发送给 worker 8。当 worker 数量为奇数时,空闲比例为 0。当 worker 数量为偶数时,空闲比例为 \frac{1}{2P},当扩展到更多 worker 数量时,这个比例渐进地接近 0。

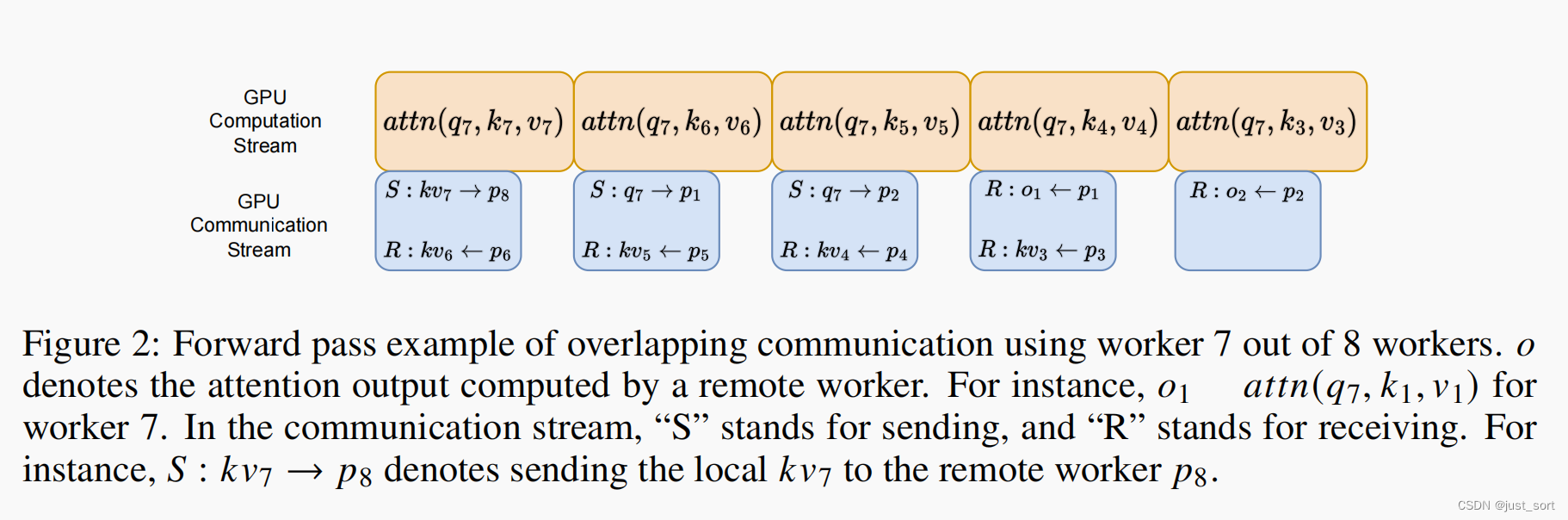
DISTATTN 在计算对应的注意力块之前,依靠点对点(P2P)通信从远程设备获取 k、v(或在负载平衡调度中的 q 分块)。然而,这些通信可以与前一块的计算轻松重叠。例如,当第一个 worker 正在为其本地 token 计算注意力时,它可以预先获取下一时间步所需的下一块 token。在现代加速器中,这可以通过将注意力计算 kernel 放置在主 GPU Stream中,而将 P2P 通信 kernel 放置在另一个 Stream 中来实现,其中它们可以并行运行(赵等,2023)。我们在Figure 2 中展示了 8 个 worker 中 worker 7 的重叠调度示例。根据经验,我们发现这种优化大大减少了通信开销(§4.3)。
0x4.3 REMATERIALIZATION-AWARE CHECKPOINTING 策略¶
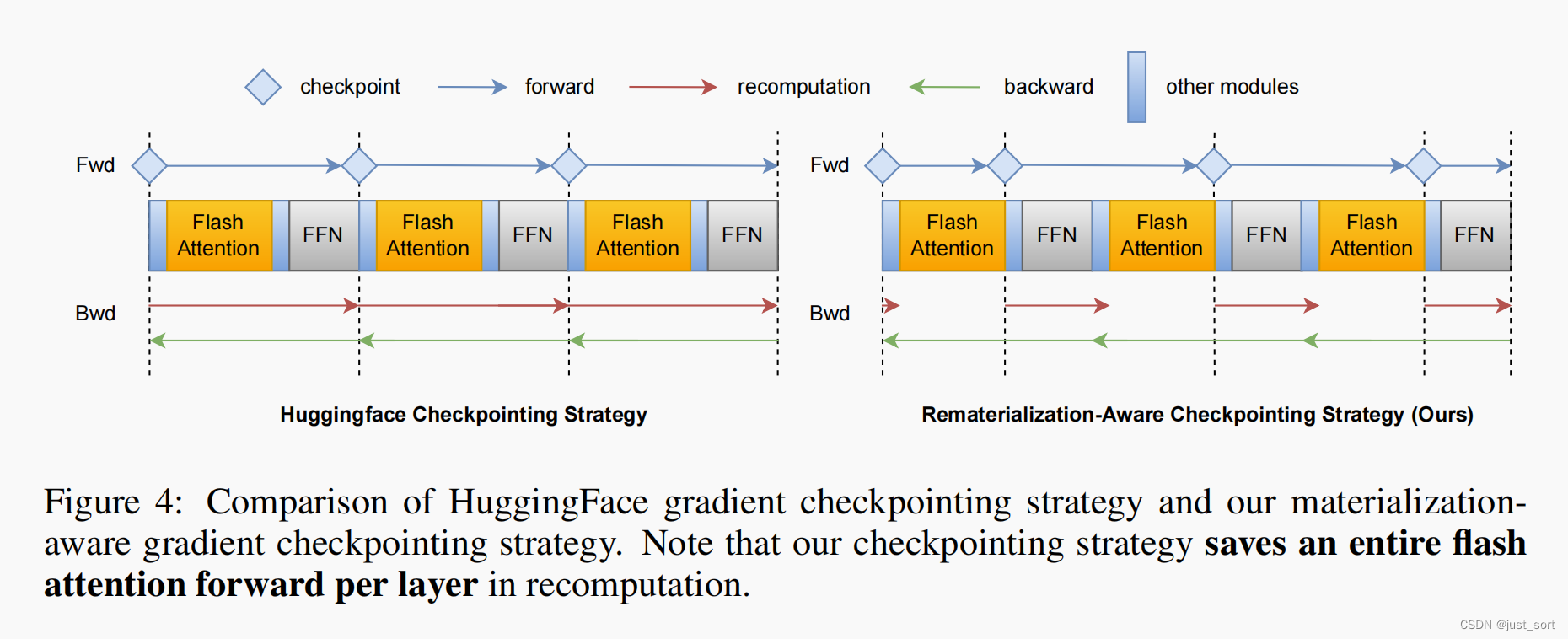
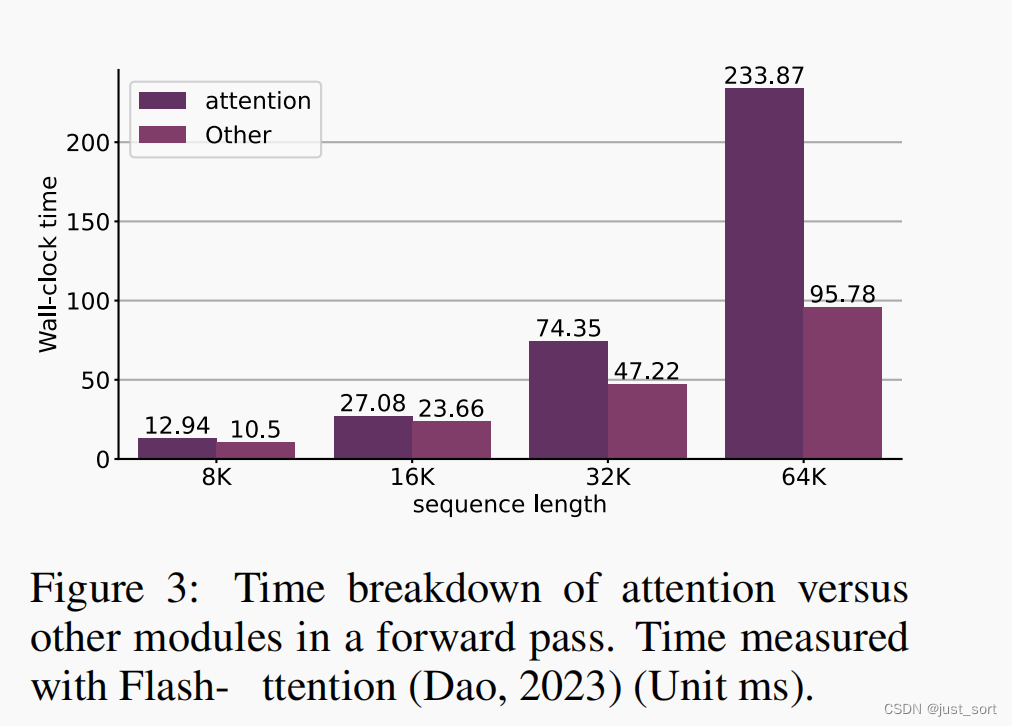
训练 Transformer 的事实标准方式需要梯度CHECKPOINTING。通常,系统使用启发式方法在每个 Transformer 层插入梯度CHECKPOINTING(Wolf 等人,2019)。然而,有了 Dao 等人(2022)的研究,我们发现之前的梯度CHECKPOINTING策略会导致额外重计算 flash attention 前向kernel。具体来说,当计算 MLP 层的梯度时,Wolf 等人(2019)将重计算整个 Transformer 层的前向,包括 flash attention 中的那一个。然而,当计算 flash attention kernel的梯度时,需要再次重计算 flash attention 的前向。本质上,这是因为 flash attention 在前向过程中不会实体化中间值,并且无论外部系统级别的重计算策略如何,都会在反向传播时重新计算它。为了解决这个问题,我们提议在 flash attention kernel的输出处插入CHECKPOINTING,而不是在 Transformer 层的边界处。在这种情况下,我们只需要重计算一次 flash attention 的前向,有效地为每个 Transformer 层节省了一次前向的注意力,如Figure 4 所示。在图 3 中,我们展示了在扩大序列长度时,注意力时间在前向传播中占主导地位,这表明我们的方法可以在使用 flash attention 的本地版本在 Llama-7b 上训练 64K 序列示例时节省大约 0.23 × 32(即大约 7)秒(这里的32是层数,0.23是Figure3中的测量数据)。此外,这还节省了我们的 DISTATTN 前向在分布式训练场景中带来的通信。我们在 §4.3 中基准测试了这种REMATERIALIZATION-AWARE CHECKPOINTING策略带来的端到端加速。
 这里是对通信和内存的分析,定义隐藏维度为d。在 DISTATTN 中,每个worker需要在执行相应的块计算之前,获取 key 和 value 的块,每个块的大小为 \frac{N}{P}d。因此,P个worker 系统中的总通信量为 2 \times \frac{N}{P}d \times P=2Nd。在因果语言目标下,一半的 key 和 value 不需要被关注,将前向通信量减半至 Nd。在反向传播中,DISTATTN 需要通信 key、value 及其梯度,其通信量为 2Nd。DISTATTN 的总通信量加起来为 3Nd。在 Megatron-LM 中,每个 worker 需要对 \frac{N}{P}d 大小的张量执行六次all-gather和四次reduce-scatter,从而产生 10Nd 的总通信量。考虑到CHECKPOINTING,Megatron-LM 将在前向中再次执行通信,总通信量为 14Nd。另一方面,由于REMATERIALIZATION-AWARE CHECKPOINTING策略,我们的通信量保持在 3Nd。总之,与 Megatron-LM 相比,LIGHTSEQ 实现了 4.7 倍的通信量减少。在实践中,我们将 LIGHTSEQ 与 FSDP 结合使用,以便也切分大模型的模型权重。我们注意到,FSDP 引入的通信仅与模型权重的大小成比例,不会随着长序列长度的增加而增加。我们在表 1 中展示了与 FSDP 的端到端加速。在模型使用 MQA 或 GQA 的情况下,LIGHTSEQ 通过共享的 key 和 value 进一步节省了通信量,我们在 § 4.1 中详细讨论了这一点。然而,我们也注意到这是一种理论分析,在实际中wall-clock时间可能因诸如实现等因素而有所不同。在实验部分,我们提供了端到端的wall-clock时间结果进行比较。
这里是对通信和内存的分析,定义隐藏维度为d。在 DISTATTN 中,每个worker需要在执行相应的块计算之前,获取 key 和 value 的块,每个块的大小为 \frac{N}{P}d。因此,P个worker 系统中的总通信量为 2 \times \frac{N}{P}d \times P=2Nd。在因果语言目标下,一半的 key 和 value 不需要被关注,将前向通信量减半至 Nd。在反向传播中,DISTATTN 需要通信 key、value 及其梯度,其通信量为 2Nd。DISTATTN 的总通信量加起来为 3Nd。在 Megatron-LM 中,每个 worker 需要对 \frac{N}{P}d 大小的张量执行六次all-gather和四次reduce-scatter,从而产生 10Nd 的总通信量。考虑到CHECKPOINTING,Megatron-LM 将在前向中再次执行通信,总通信量为 14Nd。另一方面,由于REMATERIALIZATION-AWARE CHECKPOINTING策略,我们的通信量保持在 3Nd。总之,与 Megatron-LM 相比,LIGHTSEQ 实现了 4.7 倍的通信量减少。在实践中,我们将 LIGHTSEQ 与 FSDP 结合使用,以便也切分大模型的模型权重。我们注意到,FSDP 引入的通信仅与模型权重的大小成比例,不会随着长序列长度的增加而增加。我们在表 1 中展示了与 FSDP 的端到端加速。在模型使用 MQA 或 GQA 的情况下,LIGHTSEQ 通过共享的 key 和 value 进一步节省了通信量,我们在 § 4.1 中详细讨论了这一点。然而,我们也注意到这是一种理论分析,在实际中wall-clock时间可能因诸如实现等因素而有所不同。在实验部分,我们提供了端到端的wall-clock时间结果进行比较。
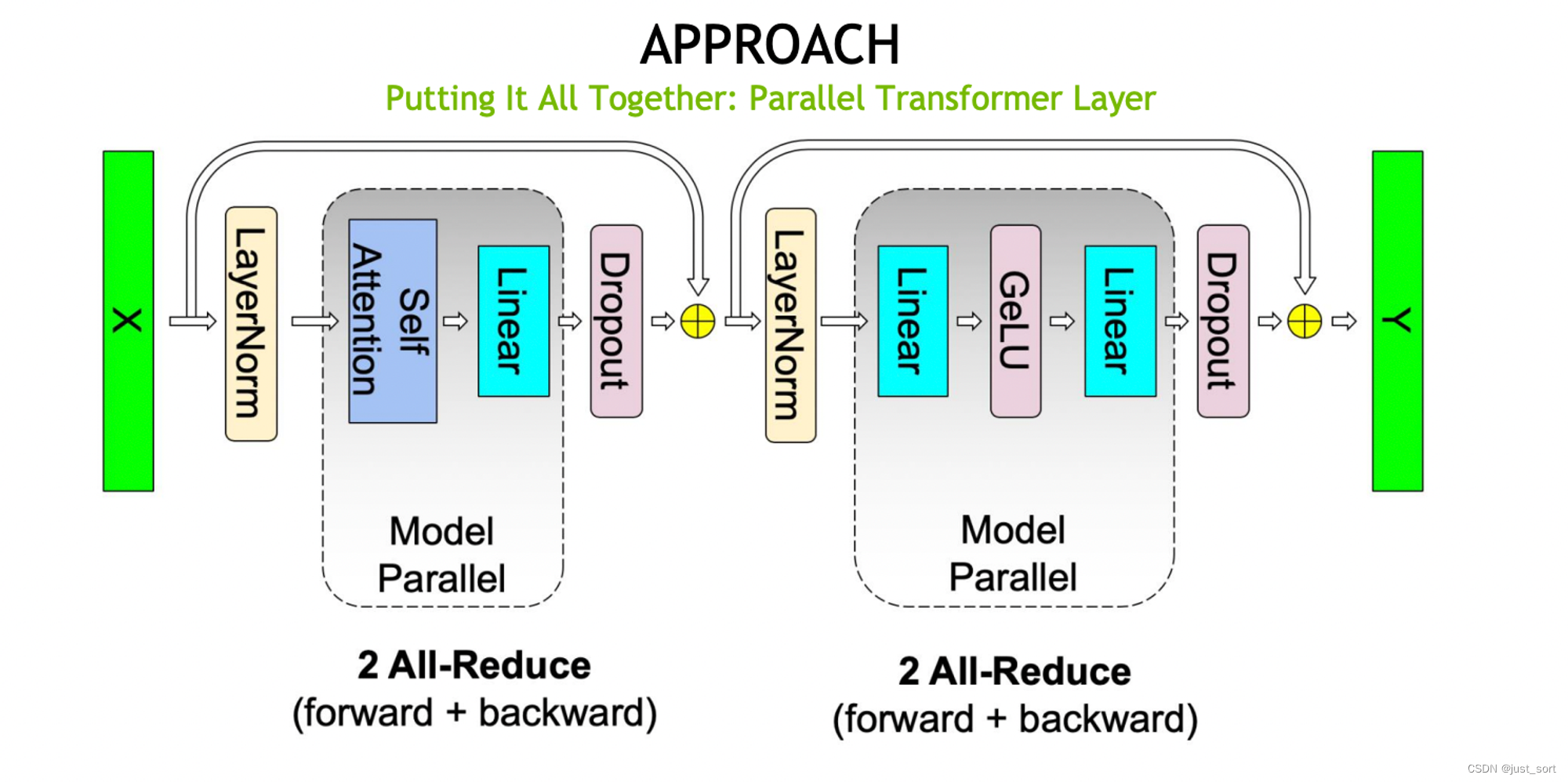
这里提到的Megatron-LM 中,每个 worker 需要对 \frac{N}{P}d 大小的张量执行六次all-gather和四次reduce-scatter,从而产生 10Nd 的总通信量。我的理解是,Meagtron TransformerLayer的通信如下图所示,前后向一共是4次all-reduce,可以折算成8Nd的通信量,多的2次all-gather应该是FlashAttention kernel backward pass自带的重计算导致需要gather key和value带来的。
 如果CHECKPOINT和FlashAttention同时打开,则会多一次Flash Attention的forward pass,在这个forward pass的前后针对key, value分别会多出一个all-gather和reduce-scatter。
如果CHECKPOINT和FlashAttention同时打开,则会多一次Flash Attention的forward pass,在这个forward pass的前后针对key, value分别会多出一个all-gather和reduce-scatter。
0x5. 实验¶
在本节中,我们将LIGHTSEQ与Megatron-LM(Korthikanti等,2023年)进行了比较,并展示了LIGHTSEQ在各种模型上具有更快的训练速度。它在各种MHA和GQA模型上实现了最高2.01倍的加速比。LIGHTSEQ通过并行度大小解除注意力头的限制以支持更长的序列长度。LIGHTSEQ可以支持比Megatron-LM长2倍到8倍的序列。
在对照研究中,我们提供了LIGHTSEQ每个组件的收益:负载均衡、计算通信重叠和REMATERIALIZATION-AWARE CHECKPOINTING。我们在以下环境中评估我们的方法和基线:(1)单个A100 DGX主机,配备8x80GB GPUs,这些GPU通过NVLink连接;(2)两个具有相同设置的DGX主机,这两个主机通过100 Gbps Infiniband互联。这代表着跨节点训练,其中通信开销有更大的影响。(3)我们的内部集群,配备2x8 A100 40GB GPUs,没有Infiniband。我们在这个集群上报告了一些结果,这些结果可以从单节点设置或不涉及跨节点训练时间的情况下得出结论。
模型设置。我们在Llama-7B及其不同代表性家族的变体上评估我们的系统:(1)多头注意力(MHA)模型:Llama-7B,隐藏大小为4096,query(key和value)头为32(Touvron等,2023年);(2)分组查询注意力(GQA)模型:Llama-GQA,与Llama-7B相同,但有8个key和value头;(3)具有更通用注意力头数量的模型:Llama-33H,与Llama-7B相同,但有33个query(key和value)注意力头。(4)具有更少注意力头的模型:我们设计了Llama-16H、Llama-8H、Llama-4H、Llama-2H,分别具有16、8、4、2个头。根据Liu等人(2021年)的研究,我们通过适当扩展层数来保持注意力头的数量,并保持中间FFN层的大小相同,以使模型大小仍然可比。例如,Llama-16H每层有16个注意力头,隐藏大小为2048,FFN层大小为11008,共64层。
实现。LIGHTSEQ是一个轻量级的调度级原型。特别地,我们用1000行代码(Paszke等,2019年;Jeaugey,2017年)实现了负载均衡和重叠,并用600行Pytorch代码实现了检查点策略。它对注意力后端是不可知的。为了减少内存消耗并在注意力模块中达到更快的速度,我们使用FlashAttention2算法(Dao,2023年)。我们使用Triton(Tillet等,2019年)实现,并最小化地修改它以在FlashAttention算法中保留统计数据。我们将所有块大小调整为128,阶段数调整为1,以获得我们集群中的最佳性能。我们重用FlashAttention2的C++反向kernel,因为我们不需要修改反向逻辑。我们使用FSDP运行LIGHTSEQ,以减少数据并行的内存占用(Zhao等,2023年)。为了公平比较,我们使用相同的注意力后端运行所有比较。我们还增加了对Megatron-LM的支持,以便与它们进行比较可以产生更有洞察力的分析:(1)不实体化因果注意力掩码,大大减少了内存占用。例如,如果没有这种支持,Megatron-LM将在每个GPU上的序列长度为16K时内存不足。(2)当注意力头数量不能被设备数整除时进行padding。所有结果都是通过Adam优化器收集的,经过10次预热迭代,并在额外的10次迭代中平均。
这里的实现细节不是很清晰,后面在阅读代码的时候我们再详解细节。
0x5.1 更快的训练速度和对不同模型架构的更好支持¶
在本节中,我们在三种设置下将我们的方法与Megatron-LM进行比较:(1)多头注意力(MHA)模型,其中key和value的头数等于query头的数量;(2)分组查询注意力(GQA)模型,其中key和value的头数少于query头的数量;(3)头数任意的模型,即头数不必是并行度的倍数。
多头注意力(MHA)。在Llama-7B模型上,与Megatron-LM相比,我们的方法在单节点和跨节点设置下分别实现了1.24倍和1.44倍的加速,直到我们实验的最长序列长度。这是我们的通信重叠技术和REMATERIALIZATION-AWARE CHECKPOINTING策略的共同结果。我们在剖析研究中分析了每个因素对这一结果的贡献(paper第4.3节)。我们注意到,我们的方法在较短序列上,如跨节点的每GPU 4K设置中,并没有实现更好的性能。这是因为通信占据了训练运行时间的主导地位,我们的重叠技术作用有限。我们将MHA模型和较短序列长度上的P2P通信优化留作未来工作。
分组查询注意力(GQA)。在LLama-GQA模型上,由于我们的key和value向量的通信显著减少,我们的方法实现了更好的加速。请注意,我们的通信时间与query、key、value和输出(用于负载平衡)向量的总和成正比,其中将key和value大小减少到 8 几乎减半了我们的通信时间。相反,Megatron-LM的通信时间没有减少,因为它的通信发生在注意力模块之外,即不受注意力模块内部优化的影响。因此,其总体训练运行时间没有像LIGHTSEQ那样大幅减少。
我们以每GPU 4K序列长度和2x8 GPUs为例进行分析。在MHA实验中,单个注意力模块的前向和后向传播的通信大约为143ms,计算时间大约为53ms。此外,我们的重叠技术能够将45ms隐藏在计算中,导致总运行时间为151ms,净通信开销为98ms。作为参考,Megatron-LM的通信需要33ms,这就是为什么在MHA实验中的这个特定设置下,Megatron-LM比LIGHTSEQ更快的原因。考虑到GQA情况,LIGHTSEQ的通信大约减少到71ms。与计算重叠后,通信开销现在小于Megatron-LM。结合检查点技术,我们在每GPU 4K序列长度上看到了积极的加速收益。随着序列长度的增加,我们的重叠技术,由于计算时间超过通信时间的事实,以及我们的检查点方法,由于单个注意力前向的比例上升,都贡献了更大的加速。总的来说,我们可以在跨节点设置上观察到高达1.52倍的加速,与同一设置下的MHA实验结果相比,额外增加了八个百分点的提升。
这里通过profile数据解释了Table1中MHA每GPU 4K长度时Megatron-LM比paper的LIGHTSEQ性能更好的原因。
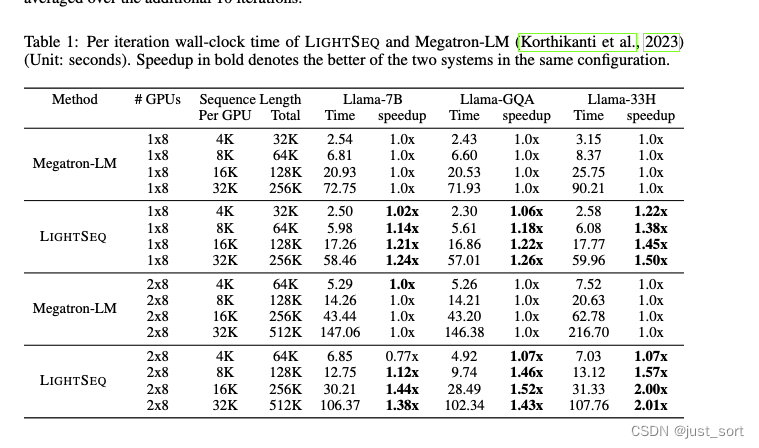
支持任意数量的头。对于Llama-33H模型,与LIGHTSEQ相比,Megatron-LM显示出额外的性能下降。这是因为它需要填充注意力头的数量,使得注意力头的数量可以被设备数量整除。另一方面,LIGHTSEQ不需要分割注意力头,并且可以高效地支持任意数量的头。例如,使用8个GPU时,Megatron-LM必须将注意力头填充到40,导致21.2%的计算被浪费。在使用16个GPU的情况下,Megatron-LM被迫将注意力头填充到48,导致更大的计算浪费,达到45.5%。这大致相当于与LIGHTSEQ相比,在训练Llama-7B模型时运行时间增加了1.21倍或1.45倍。Megatron-LM的这种性能下降主要是因为当扩展到更长的序列长度时,训练时间主要由注意力模块的计算时间占据。从经验上看,我们观察到1.50倍和2.01倍的加速(与Llama-7B案例相比,额外增加了20%和45%的加速,与理论分析一致)。
0x5.2 超越头数限制的scale up¶
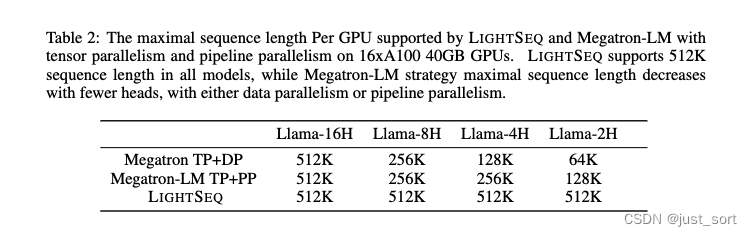 意思就是LIGHTSEQ的训练序列长度可以更长。
意思就是LIGHTSEQ的训练序列长度可以更长。
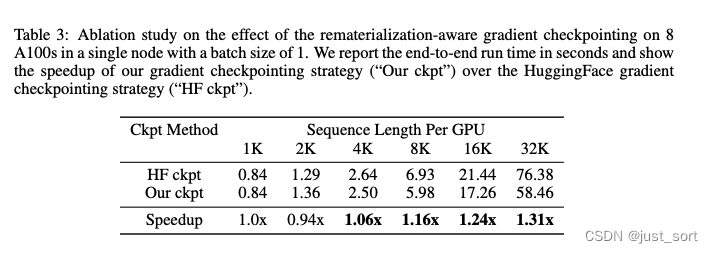
后面没什么干货了,可以看一下Table3,展示了paper提出的节省一次Flash Attetionv2前向的Checkpointing策略带来的加速:
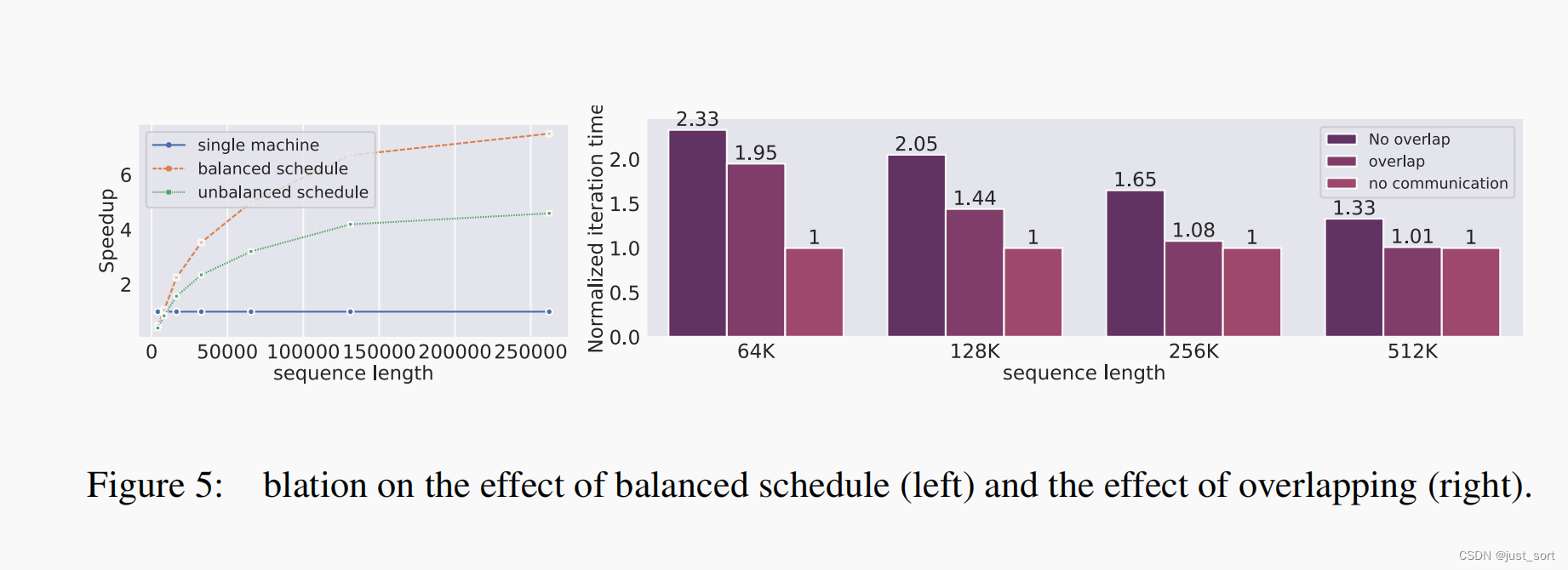
另外,下面的Figure5展示了paper提出的负载均衡Schedule以及计算和通信重叠优化的效果。
0x5. 结论¶
感觉这篇paper有几个亮点,首先把Megatron-LM的Self-Attention模块的模型并行方式变成序列并行,优化了通信量,同时通过计算和通信重叠近一步压缩了训练迭代时间。另外,在使用重计算的时候发现当前Huggingface/Megatron-LM的重计算策略和FlashAttentionV2同时工作的话会导致Transformer Layer多计算一次Flash Attention的forward,然后修正了这个问题,获得了很直接的性能提升。paper的代码实现基于Triton并且不算长,后面尝试讲解这里的代码,应该会先从这里的DISTATTN开始。
本文总阅读量次