【GiantPandaCV导语】这篇文章主要是讲解了如何给Jetson Nano装机,以及在Jetson Nano上如何配置TVM并将MxNet的ResNet18跑起来获取分类结果,最后我们还体验了一下使用AutoTVM来提升ResNet50在Jetson Nano上的推理效率,AutoTune了一个Task(一共需要AutoTune 20个Task)之后可以将ResNet50的推理速度做到150ms跑完一张图片(224x224x3),从上面的BenchMark可以看到TensorRT在FP32的时候大概能做到50-60ms推理一张图片(224x224x3)。本文所有实验代码均可以在这里找到:https://github.com/BBuf/tvm_learn/blob/main/relay ,如果你对学习TVM感兴趣可以考虑点个star。
0x00. Jetson Nano 安装¶
这里就不详细介绍Jetson Nano了,我们只需要知道NVIDIA Jetson是NVIDIA的一系列嵌入式计算板,可以让我们在嵌入式端跑一些机器学习应用就够了。手上刚好有一块朋友之前寄过来的Jetson Nano,过了一年今天准备拿出来玩玩。
拿到的Jetson Nano大概长这个样子:

我们需要为Jetson Nano烧录一个系统,Jetson Nano的系统会被烧录在一个SD Card中,然后插入到板子上。我这里选取了一块内存为128GB的SD Card。
首先,我们下载Jetson Nano镜像(https://developer.nvidia.com/embedded/jetpack),这个镜像里面包含提供引导加载程序、Ubuntu18.04、必要的固件、NVIDIA驱动程序、示例文件系统等。
然后下载Etcher(https://www.balena.io/etcher)这个镜像烧录工具把我们下载好的Jetson Nano镜像烧录到SD卡中,操作很简单,选择镜像和我们的读卡器就可以了。下面展示了完成烧录后的界面。
然后将SDCard插回Jetson Nano并插入电源完成系统的安装即可,安装完成后界面如下。
只有一个显示器,为了不影响基于windows的开发工作,所以直接ssh登录:
为了开发方便,可以将jetson Nano在VsCode里面进行配置,配置信息这样写:
Host JetsonNano
HostName 192.168.1.6
User bbuf
然后就可以通过VsCode远程连接到Jetson Nano上进行开发了。
0x01. 基础环境安装¶
首先使用uname -a查看一下系统的基本信息:
Linux bbuf-desktop 4.9.201-tegra #1 SMP PREEMPT Fri Feb 19 08:40:32 PST 2021 aarch64 aarch64 aarch64 GNU/Linux
可以看到这个系统是64位的arm系统,接下来我们为ubuntu更换一下国内源,换源前最好备份一下原始的源:
sudo cp /etc/apt/sources.list /etc/apt/sources_init.list
然后换源:
sudo gedit /etc/apt/sources.list
我这里选择的是清华的镜像源,将下面的代码粘贴进去:
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
保存之后,执行sudo apt-get update就完成了。
然后我们就可以来配置TVM需要的一些依赖了,我们一边编译一边配置,根据报错提示来。
首先建一个新的文件夹,克隆一下TVM源码然后执行下面这些操作:
git clone --recursive https://github.com/apache/tvm tvm
cd tvm
mkdir build
cp cmake/config.cmake build
cd build
cmake ..
make -j4
export TVM_HOME=/path/to/tvm
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}
先把config.cmake里面的USE_LLVM和USE_CUA编译选项打开,开始Cmake,然后错误发生了:
CMake Error at cmake/utils/FindLLVM.cmake:47 (find_package):
Could not find a package configuration file provided by "LLVM" with any of
the following names:
LLVMConfig.cmake
llvm-config.cmake
这是因为没有安装LLVM的原因,我们来安装一下。
git clone https://github.com/llvm/llvm-project llvm-project
cd llvm-project
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_PROJECTS=lld -DCMAKE_INSTALL_PREFIX=/usr/local ../../llvm-project/llvm
make -j4 && sudo make install
编译的时候提示cmake版本过低,先升级一下cmake版本:
wget https://github.com/Kitware/CMake/releases/download/v3.14.4/cmake-3.14.4.tar.gz
tar xvf cmake-3.14.4.tar.gz
cd cmake-3.14.4
./bootstrap --prefix=/usr
make
sudo make install
现在已经成功将cmake版本升级,继续编译llvm(编译llvm的时候建议checkout到大于等于release7.0分支,我直接编译master的代码虽然成功了,但编译tvm会报和LLVM相关的Codegen错误)。
然后编译完成之后编译tvm就可以了。成功编译之后还需要记得设置TVM的PYTHONPATH环境变量:
export TVM_HOME=/home/bbuf/tvm_project/tvm
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}
然后source ~/.bashrc使环境变量生效,这样就完成了在Jetson Nano上配置TVM了
0x02. 在Jetson Nano上跑ResNet50¶
首先参考着https://tvm.apache.org/docs/tutorials/frontend/deploy_model_on_rasp.html TVM提供的在树莓派上的这个教程来改一改,由于这里使用的预训练模型是Mxnet提供的,所以我们需要在Jetson Nano上安装一下MxNet包,安装步骤如下:
首先安装MxNet的依赖:
sudo apt-get update
sudo apt-get install -y git build-essential libopenblas-dev libopencv-dev python3-pip
sudo pip3 install -U pip
然后下载Jetson Nano的MxNet v1.6的whell包,并安装:
wget https://mxnet-public.s3.us-east-2.amazonaws.com/install/jetson/1.6.0/mxnet_cu102-1.6.0-py2.py3-none-linux_aarch64.whl
sudo pip3 install mxnet_cu102-1.6.0-py2.py3-none-linux_aarch64.whl
安装好之后导入一下MxNet看看是否可以成功:
然后我们讲解一下如何在Jetson Nano上完成MxNet的ResNet50模型的推理:
首先导入需要的头文件:
import tvm
from tvm import te
import tvm.relay as relay
from tvm import rpc
from tvm.contrib import utils, graph_executor as runtime
from tvm.contrib.download import download_testdata
然后运行的时候我们选择利用RPC在服务器上远程调用Jetson Nano的板子进行运行,也可以选择直接在板子上运行,这里我们选择的是直接在板子上运行,所以不用启动RPC Server,所以我们这里直接准备预训练模型然后编译Graph并在本地的Jetson Nano上进行推理即可:
准备预训练模型¶
这里直接从mxnet的gloun的modelzoo里面加载ResNet18的预训练模型:
from mxnet.gluon.model_zoo.vision import get_model
from PIL import Image
import numpy as np
# one line to get the model
block = get_model("resnet18_v1", pretrained=True)
然后为了测试这个模型,这里下载一张猫的图片并且转换图片的格式。
img_url = "https://github.com/dmlc/mxnet.js/blob/main/data/cat.png?raw=true"
img_name = "cat.png"
img_path = download_testdata(img_url, img_name, module="data")
image = Image.open(img_path).resize((224, 224))
def transform_image(image):
image = np.array(image) - np.array([123.0, 117.0, 104.0])
image /= np.array([58.395, 57.12, 57.375])
image = image.transpose((2, 0, 1))
image = image[np.newaxis, :]
return image
x = transform_image(image)
synset_url是网络输出类别的下标和真实名字对应的文件,这里也加载进来:
synset_url = "".join(
[
"https://gist.githubusercontent.com/zhreshold/",
"4d0b62f3d01426887599d4f7ede23ee5/raw/",
"596b27d23537e5a1b5751d2b0481ef172f58b539/",
"imagenet1000_clsid_to_human.txt",
]
)
synset_name = "imagenet1000_clsid_to_human.txt"
synset_path = download_testdata(synset_url, synset_name, module="data")
with open(synset_path) as f:
synset = eval(f.read())
然后利用我们之前介绍过的relay.frontend.xxx接口将Gluon模型转换为Relay计算图。
# We support MXNet static graph(symbol) and HybridBlock in mxnet.gluon
shape_dict = {"data": x.shape}
mod, params = relay.frontend.from_mxnet(block, shape_dict)
# we want a probability so add a softmax operator
func = mod["main"]
func = relay.Function(func.params, relay.nn.softmax(func.body), None, func.type_params, func.attrs)
下面定义了一些基本的数据相关的配置信息:
batch_size = 1
num_classes = 1000
image_shape = (3, 224, 224)
data_shape = (batch_size,) + image_shape
编译图¶
这里使用relay.build来编译计算图。我们不能在一个ARM设备上推理一个X86程序,所以这里需要指定目标设备为"llvm",这里的"llvm"代表了Jetson Nano的Arm CPU。然后编译出计算图的运行时库之后,可以将这个库直接存下来,下次运行的时候不用重新编译。下面的代码中local_demo设置为True表示在真实的Jetson Nano运行这个Relay计算图,如果设置为False表示要基于RPC调用局域网中的Jetson Nano运行Relay计算图。我们这里是直接本地编译和运行。在执行完这个步骤之后我们获得了可以直接Jetson Nano CPU上运行的库,并打包成net.tar。
local_demo = True
if local_demo:
target = tvm.target.Target("llvm")
else:
target = tvm.target.Target("llvm")
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(func, target, params=params)
# After `relay.build`, you will get three return values: graph,
# library and the new parameter, since we do some optimization that will
# change the parameters but keep the result of model as the same.
# Save the library at local temporary directory.
tmp = utils.tempdir()
lib_fname = tmp.relpath("net.tar")
lib.export_library(lib_fname)
接下来我们可以加载运行时库,然后推理刚才猫的图片:
local_demo = True
if local_demo:
target = tvm.target.Target("llvm")
# target = tvm.target.Target("nvidia/jetson-nano")
# target_host = "llvm"
# assert target.kind.name == "cuda"
# assert target.attrs["arch"] == "sm_53"
# assert target.attrs["shared_memory_per_block"] == 49152
# assert target.attrs["max_threads_per_block"] == 1024
# assert target.attrs["thread_warp_size"] == 32
# assert target.attrs["registers_per_block"] == 32768
else:
target = tvm.target.Target("llvm")
with tvm.transform.PassContext(opt_level=7):
lib = relay.build(func, target, target_host=target_host, params=params)
tmp = utils.tempdir()
lib_fname = tmp.relpath("net.tar")
lib.export_library(lib_fname)
# create the remote runtime module
dev = tvm.cuda(0)
module = runtime.GraphModule(lib["default"](dev))
time_start = time.time()
# set input data
module.set_input("data", tvm.nd.array(x.astype("float32")))
# run
module.run()
time_end = time.time()
print('time cost', time_end-time_start,'s')
# get output
out = module.get_output(0)
# get top1 result
top1 = np.argmax(out.numpy())
print("TVM prediction top-1: {}".format(synset[top1]))
打印结果:
TVM prediction top-1: tiger cat
上面还记录了运行的时间,输出结果是:
time cost 0.16585731506347656 s
可以看到在Jetson Nano的CPU上加载输入数据然后推理这张图片(不包含后处理)耗时大概160ms。
然后尝试使用Jetson Nano的GPU来进行推理,这个时候报了一个警告大概是找不到tophub包:
WARNING:root:Failed to download tophub package for cuda: <urlopen error [Errno 111] Connection refused>
这个警告导致了一系列错误导致了无法推理,这个错误的解决方法是:
git clone https://github.com/tlc-pack/tophub
cp tophub/tophub/ /home/bbuf/.tvm -rf
然后就可以使用Jetson Nano的GPU来推理了,然后发现推理这张图片花了1.81s。。。这一节的代码可以在https://github.com/BBuf/tvm_learn/blob/main/relay/jetsonnano/deploy_model_on_jetsonnano.py这里看到。
由此可以看到直接应用TVM到Jetson Nano上效率还是很低的,主要原因是我们还没有针对这个硬件来Auto-tuning,也就是使用到Auto-TVM来提高程序运行的性能。
0x03. 体验AutoTVM¶
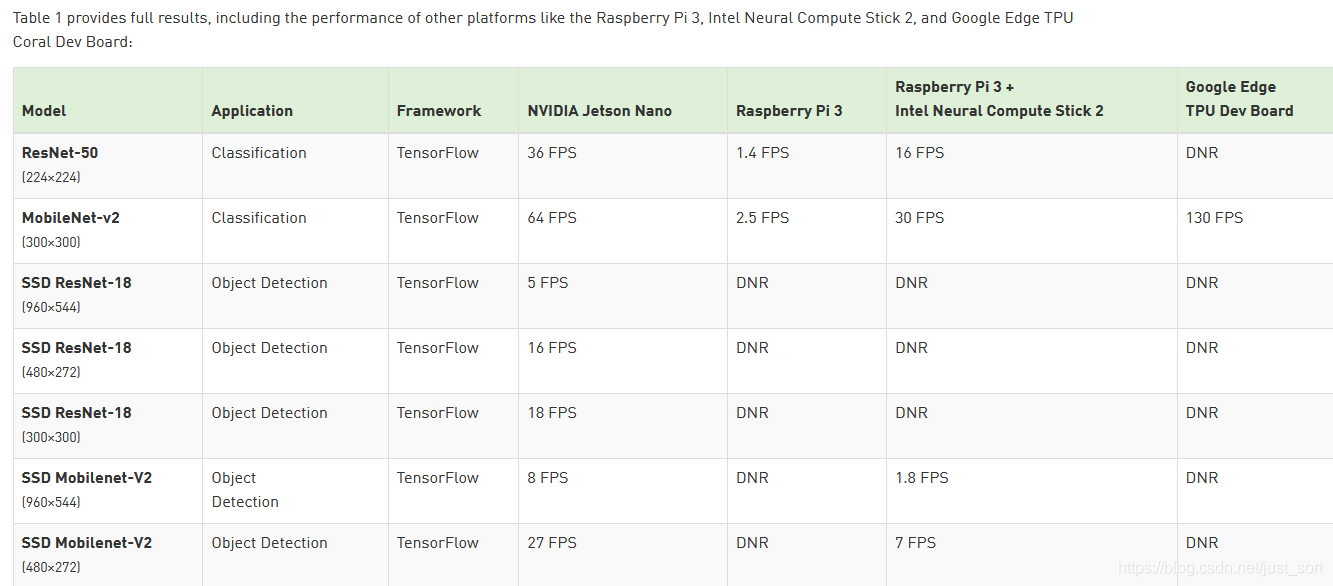
这里先不讲AutoTVM原理什么的,直接在Jetson Nano基于AutoTVM来Autotune一下ResNet50看看效果吧,我在https://developer.nvidia.com/embedded/jetson-nano-dl-inference-benchmarks NVIDIA的官网上找到了Jetson Nano一些经典网络的FPS,包含ResNet50,注意这里是FP16推理,那么可以估算FP32情况下推理224\times 224\times 3的图片应该在50+ms:
然后直接参考https://tvm.apache.org/docs/tutorials/autotvm/tune_relay_cuda.html 这个官方的AutoTune文档来修改一下,就可以在Jetson Nano上AutoTune ResNet50了,修改后的代码见:https://github.com/BBuf/tvm_learn/blob/main/relay/tune_relay_cuda.py。这里是直接在Jetson Nano上本地AutoTune。
由于这个AutoTune需要很久的时间,所以我暂时只跑了一下午也就是一个Task(这里Task的概念和ResNet50里面的卷积层个数有关,因为这里是来AutoTune卷积Op,ResNet50有20个Conv Op,所以Tasks一共有20个)之后测试一下推理的速度:
Extract tasks...
Compile...
Evaluate inference time cost...
Mean inference time (std dev): 154.54 ms (0.47 ms)
平均推理时间在150ms左右,注意到这里只跑了一轮,相信跑完整个Auto-Tune之后或许有可能可以超越TensorRT的速度的,这个板子跑完AutoTune可能要3-4天。。。下篇文章再报告最终结果,看看是否能超过TensorRT。
0x04. 总结¶
这篇文章主要是讲解了如何给Jetson Nano装机,以及在Jetson Nano上如何配置TVM并将MxNet的ResNet18跑起来获取分类结果,最后我们还体验了一下使用AutoTVM来提升ResNet50在Jetson Nano上的推理效率,AutoTune了一个Task(一共需要AutoTune 20个Task)之后可以将ResNet50的推理速度做到150ms跑完一张图片(224x224x3),从上面的BenchMark可以看到TensorRT在FP32的时候大概能做到50-60ms推理一张图片(224x224x3)。
0x05. 同期文章¶
- 【从零开始学深度学习编译器】八,TVM的算符融合以及如何使用TVM Pass Infra自定义Pass
- 【从零开始学深度学习编译器】七,万字长文入门TVM Pass
- 【从零开始学深度学习编译器】六,TVM的编译流程详解
- 【从零开始学深度学习编译器】五,TVM Relay以及Pass简介
- 【从零开始学深度学习编译器】番外一,Data Flow和Control Flow
- 【从零开始学深度学习编译器】四,解析TVM算子
- 【从零开始学TVM】三,基于ONNX模型结构了解TVM的前端
- 【从零开始学深度学习编译器】二,TVM中的scheduler
- 【从零开始学深度学习编译器】一,深度学习编译器及TVM 介绍
0x06. 参考¶
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次