【GiantPandaCV导语】这篇文章主要介绍了一下TVM的Relay并介绍了如何基于Relay构建一个Conv+BN+ReLU的小网络,然后介绍了一下TVM中的Pass的工作机制,并较为详细的介绍了RemoveUnusedFunctions,ToBasicBlockNormalForm,EliminateCommonSubexpr三种Pass。其中Relay部分的详细介绍大部分引用自官方文档:https://tvm.apache.org/docs/tutorials/get_started/introduction.html。
0x0. 介绍¶
在前面几节的介绍中我们了解到了TVM是如何将ONNX前端模型转换为IR Module的,并且还剖析了TVM中的Relay算子和TOPI算子的扭转过程,知道了Relay算子的最终计算也是基于TOPI算子集合完成的。然后我们在基于ONNX模型结构了解TVM的前端那篇文章贴出的示例程序中还有一个很重要的细节即TVM的编译流程没有详细介绍,即下面这几行代码:
######################################################################
# Relay Build
# -----------
# Compile the graph to llvm target with given input specification.
target = "llvm"
target_host = "llvm"
dev = tvm.cpu(0)
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, target=target, target_host=target_host, params=params)
这几行代码展示了TVM的编译流程,在这个编译流程里面不仅包含了基于Relay IR进行的优化策略来去除冗余的算子(也叫Pass)还包含了将Relay程序编译成特定后端(这里是llvm)可以执行的代码(codegen)。
在这篇文章中我们将简单介绍一下Relay,然后再认识一下TVM中的Pass,也就是解释with tvm.transform.PassContext(opt_level=3)这个类具体完成了什么工作。至于code gen和详细的编译流程,由于TVM的水太深,我还没把握住,下次再探索吧。
0x2. Relay介绍¶
这一节主要结合TVM的文档(https://tvm.apache.org/docs/dev/relay_intro.html)来介绍一下NNVM的第二代Relay。Relay的设计目标有以下几点:
- 支持传统的数据流(DataFlow)风格编程。
- 支持functional-style scoping,并融合了编程语言领域的一些知识,带了一些新的特性(支持Let表达式,支持递归等等)
- 支持数据流风格和函数式风格混合编程。
0x2.1 使用Relay建立一个计算图¶
传统的深度学习框架使用计算图作为它们的中间表示。 计算图(或数据流图)是代表计算过程的有向无环图(DAG)。 尽管由于缺少控制流,数据流图在计算能力方面受到限制,但它们的简单性使其易于实现自动微分并针对异构执行环境进行编译(例如,在专用硬件上执行计算图的某些部分,即子图)。

我们可以使用Relay来构建一个计算(DataFlow)图。具体来说,上面的代码显示了如何构造一个简单的两个节点的计算图,我们可以发现这个示例的代码和现有的Garph IR如NNVMv1没有太大区别,唯一的区别是在术语方面:
- 现有框架通常使用图和子图
- Relay使用函数,例如 –
fn(%x),表示图
每个数据流节点都是Relay中的一个CallNode。通过Relay的Python DSL,我们可以快速构建计算图。在上面的代码需要注意的是这里显示构造了一个Add节点,两个输入都指向%1。当一个深度学习框架对上面的计算图进行推理时,它将会按照拓扑序进行计算,并且%1只会被计算一次。虽然这个事实对于深度学习框架的开发者来说是一件很自然的事情,但这或许会使得只关心算法的研究员困惑。如果我们实现一个简单的vistor来打印结果并将结果视为嵌套的Call表达式,它将是log(%x) + log(%x)。
当DAG中存在共享节点时,这种歧义是由程序语义的解释不同而引起的。在正常的函数式编程IR中,嵌套表达式被视为表达式树,并没有考虑%1实际上在%2中被重用了2次的事实。
Relay IR注意到了这个区别。其实深度学习框架用户经常使用这种方式构建计算图,其中经常发生DAG节点重用。然后当我们以文本格式打印Relay程序时,我们每行打印一个CallNode,并为每个CallNode分配一个临时ID(%1, %2),以便可以在程序的后续部分中引用每个公共节点。
0x2.2 Module:支持多个函数(Graphs)¶
上面介绍了如何构建一个数据流图为一个函数。然后一个很自然的问题是可以做到构建多个函数并相互调用吗?Relay允许将多个函数组合在一个Module中,下面的代码展示了一个函数调用另外一个函数的例子。
def @muladd(%x, %y, %z) {
%1 = mul(%x, %y)
%2 = add(%1, %z)
%2
}
def @myfunc(%x) {
%1 = @muladd(%x, 1, 2)
%2 = @muladd(%1, 2, 3)
%2
}
Module可以被看作Map<GlobalVar, Function>,其中GlobalVar仅仅是一个表示函数名的ID,上面的程序中GlobalVar是@muladd和@myfunc。当一个CallNode被用来调用另外一个函数时,相应的GlobalVar被存在CallNode的OP中。它包含了一个间接的等级关系---我们需要使用相应的GlobalVar从Module中查找被调用函数的主体。在这种情况下,我们也可以直接将引用的函数存储为CallNode中的OP。那么为什么需要引入GlobalVar呢?主要原因是为了解耦定义和声明,并支持了函数的递归和延迟声明。
def @myfunc(%x) {
%1 = equal(%x, 1)
if (%1) {
%x
} else {
%2 = sub(%x, 1)
%3 = @myfunc(%2)
%4 = add(%3, %3)
%4
}
}
在上面的例子中,@myfunc递归调用它自己。使用GlobalVar @myfunc来表示函数避免了数据结构中的循环依赖性。至此,已经介绍完了Relay中的基本概念。值得注意的是,相比NNVM,Relay在如下方面进行了改进:
- 有文本形式中间表示,便于开发和 debug
- 支持子图函数、联合模块,便于联合优化
- 前端用户友好,便于调优
0x2.3 Let Binding and Scopes¶
至此,已经介绍了如何用深度学习框架中的旧方法来构建计算图。这一节将讨论一个Relay的一个新的构造-let bindings。
Let binding被每一种高级的编程语言应用。在Relay中,他是一个拥有三个字段Let(var, value, body)的数据结构。当我们计算一个Let表达式时,我们首先计算value部分,然后将其绑定到var,最后在body表达式中返回计算结果。
我们可以使用一系列的Let绑定来构造一个逻辑上等效于数据流程序的程序,下面的代码示例显示了这个用法:
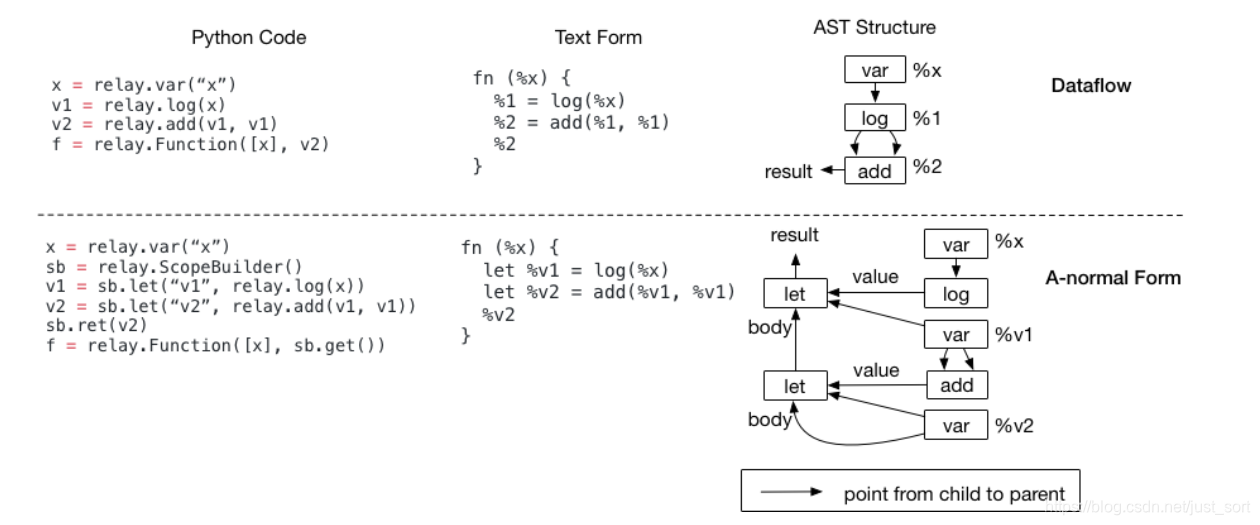
嵌套的Let Binding被称作A-normal形式,作为函数式编程语言中的常用IR。通过上面的图我们可以发现虽然这两个程序的语义完全等价,它们的文本表示也一样(除了A-norm形式有let的前缀),但AST抽象语法树却不一样。
由于程序的优化使用了这些AST数据结构并对其进行了变换,这两种不同的结构会影响到最终编译器生成的代码。比如,我们想要检测add(log(x), y)这个模式。在数据流程序中,我们可以首先进入add节点,然后直接检查它的第一个参数是不是log。而在A-form的程序中,我们不能直接检查任何东西,因为add节点的输入是%v1-我们需要维护一个映射表将变量和它绑定的值进行映射,然后查表才知道%v1代表的是log。
0x2.4 为什么我们可能需要Let Binding¶
Let Binding的一种关键用法是它可以指定计算的scope。我们看一下下面这个没有使用Let Binding的例子:
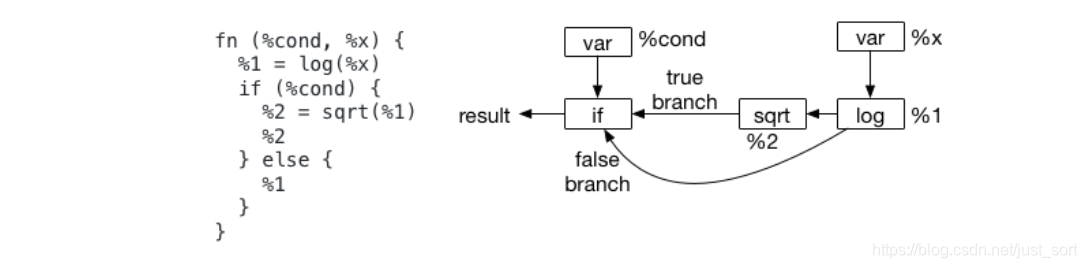
当我们尝试在该在哪里计算%1节点时,问题就来了。特别的是,虽然文本格式似乎建议我们应该在if的scope之外计算节点%1,但AST却不建议这样做。实际上数据流图永远不会定义它的计算scope,这在语义上产生了一些歧义。
当我们有闭包时,这种歧义更加有趣,考虑下面的程序,该程序返回一个闭包。我们不知道在哪里计算%1,它可以在闭包的内部和外部。
fn (%x) {
%1 = log(%x)
%2 = fn(%y) {
add(%y, %1)
}
%2
}
Let Binding解决了这些问题,因为值的计算发生在let节点上。在这两个程序中,如果将%1 = log(%x)改成let %v1 = log(%x),则我们将计算位置明确指定为if scope和闭包之外。可以看到Let Binding为计算端提供了更精确的范围,并且在生成后端代码时会很有用(因为这种范围在IR中)。
另一方面,没有指定计算scope的数据流形式也有其自身的优势,我们不需要担心在生成代码时将let放到哪里。数据流格式还为后面决定将计算节点放到哪里的Passes提供了更大的自由度。因此,在优化的初始阶段如果发现数据流形式还是挺方便的,那么使用数据流图的编码方法可能不是一个坏主意。目前在Relay中也实现了很多针对数据流图的优化方式。
但是,当我们将IR lower到实际的运行时程序时,我们需要精确的计算scope。 特别是当我们使用子函数和闭包时,我们要明确指定计算scope应在哪里发生。 在后期执行特定的优化中,可以使用Let Binding来解决此问题。
0x2.5 对IR转换的影响¶
希望到目前为止,你们已经熟悉两种表示形式。 大多数函数式编程语言都以A-normal形式进行分析,分析人员无需注意表达式是DAG。
Relay选择同时支持数据流形式和Let Binding。TVM相信让框架开发者选择熟悉的表达形式很重要。但是这确实对我们写通用的Passes产生了一些影响。由于这里还没介绍Passes,以及对Passes理解不深并且我没有使用过Let表达式来构建网络,就不继续介绍具体有哪些影响了。
详细内容可以参考:https://tvm.apache.org/docs/dev/relay_intro.html#let-binding-and-scopes
0x3. 基于Relay构建一个自定义的神经网络示例¶
我们基于Relay的接口定义一个Conv+BN+ReLU的小网络,展示一下Relay接口应该如何使用,这里TVM版本是0.8.0.dev,代码如下:
#coding=utf-8
import tvm
from tvm import relay
import numpy as np
from tvm.contrib import graph_executor
# 构造BN
def batch_norm(data,
gamma=None,
beta=None,
moving_mean=None,
moving_var=None,
**kwargs):
name = kwargs.get("name")
kwargs.pop("name")
if not gamma:
gamma = relay.var(name + "_gamma")
if not beta:
beta = relay.var(name + "_beta")
if not moving_mean:
moving_mean = relay.var(name + "_moving_mean")
if not moving_var:
moving_var = relay.var(name + "_moving_var")
return relay.nn.batch_norm(data,
gamma=gamma,
beta=beta,
moving_mean=moving_mean,
moving_var=moving_var,
**kwargs)[0]
# 构造卷积
def conv2d(data, weight=None, **kwargs):
name = kwargs.get("name")
kwargs.pop("name")
if not weight:
weight = relay.var(name + "_weight")
return relay.nn.conv2d(data, weight, **kwargs)
# 构造卷积+BN+ReLU的simpleNet
def simplenet(data, name, channels, kernel_size=(3, 3), strides=(1, 1),
padding=(1, 1), epsilon=1e-5):
conv = conv2d(
data=data,
channels=channels,
kernel_size=kernel_size,
strides=strides,
padding=padding,
data_layout='NCHW',
name=name+'_conv')
bn = batch_norm(data=conv, epsilon=epsilon, name=name + '_bn')
act = relay.nn.relu(data=bn)
return act
data_shape = (1, 3, 224, 224)
kernel_shape = (32, 3, 3, 3)
dtype = "float32"
data = relay.var("data", shape=data_shape, dtype=dtype)
act = simplenet(data, "graph", 32, strides=(2, 2))
func = relay.Function(relay.analysis.free_vars(act), act)
print(func)
np_data = np.random.uniform(-1, 1, (1, 3, 224, 224))
params = {
"graph_conv_weight": tvm.nd.array(np.random.uniform(-1, 1, (32, 3, 3, 3)).astype(dtype)),
"graph_bn_gamma": tvm.nd.array(np.random.uniform(-1, 1, (32)).astype(dtype)),
"graph_bn_beta": tvm.nd.array(np.random.uniform(-1, 1, (32)).astype(dtype)),
"graph_bn_moving_mean": tvm.nd.array(np.random.uniform(-1, 1, (32)).astype(dtype)),
"graph_bn_moving_var": tvm.nd.array(np.random.uniform(-1, 1, (32)).astype(dtype)),
}
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(func, "llvm", params=params)
dev = tvm.cpu(0)
dtype = "float32"
m = graph_executor.GraphModule(lib["default"](dev))
# set inputs
m.set_input("data", tvm.nd.array(np_data.astype(dtype)))
# execute
m.run()
# get outputs
tvm_output = m.get_output(0)
就是一个很常规的过程,创建Relay Function,然后将所有的OP的权重信息用params这个字典存起来,注意这里的权重信息是随机初始化的。在编译Relay IR之前可以先看一下优化前的IR长什么样:
fn (%data: Tensor[(1, 3, 224, 224), float32], %graph_conv_weight, %graph_bn_gamma, %graph_bn_beta, %graph_bn_moving_mean, %graph_bn_moving_var) {
%0 = nn.conv2d(%data, %graph_conv_weight, strides=[2, 2], padding=[1, 1, 1, 1], channels=32, kernel_size=[3, 3]);
%1 = nn.batch_norm(%0, %graph_bn_gamma, %graph_bn_beta, %graph_bn_moving_mean, %graph_bn_moving_var);
%2 = %1.0;
nn.relu(%2)
}
符合我们第二节介绍的规则,Relay IR时一个函数。
0x4. 初识Pass¶
在上面构造simplenet的代码中,relay.build外部包了一层tvm.transform.PassContext,如下:
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(func, "llvm", params=params)
实际上tvm.transform.PassContext这个接口就定义了Pass,如文档所示:
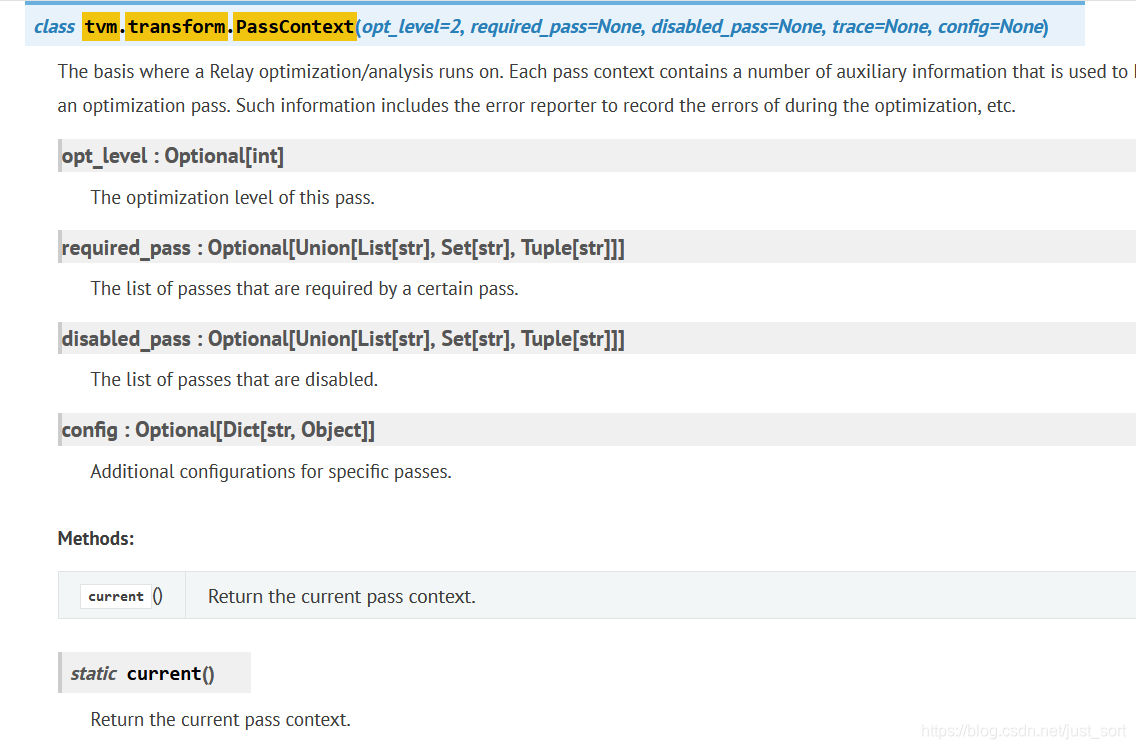
Pass是TVM中基于Relay IR进行的一系列优化,类似于onnx-simplifier里面用到的onnxoptimizer,它可以简化计算图,去除一些冗余的算子,提高模型的推理效率。TVM将所有的pass都抽象到了tvm/include/tvm/ir/transform.h这个文件中,主要包含PassContext,PassInfo,Pass,以及Sequential。
这里的PassContext即是上面Python接口对应的C++实现,它包含了Pass执行依赖的一些参数如优化level,依赖的其它特定Pass以及设置不使用某种指定Pass等。PassInfo是用来记录Pass信息的类,包含Pass的opy_level,name,以及当前Pass需要哪些前置Pass。而Pass这个类就执行pass的主体,这是一个基类,每种Pass具体的C++代码实现在tvm/src/relay/transforms中,它们都会继承Pass这个基类。最后,Sequential是一个container,装载所有Pass。
需要说明一下,不是所有的Pass都定义在tvm/src/relay/transforms这里,比如下面的第一个例子就在tvm/src/relay/backend/vm这个文件夹里。接下来我们将几个Pass的例子,看看它到底对Relay IR做了什么?
- RemoveUnusedFunctions
首先来看一下定义在tvm/src/relay/backend/vm/removed_unused_funcs.cc这里的RemoveUnusedFunctions 这个pass,核心的代码实现如下:
void VisitExpr_(const FunctionNode* func_node) final {
auto func = GetRef<Function>(func_node);
if (visiting_.find(func) == visiting_.end()) {
visiting_.insert(func);
for (auto param : func_node->params) {
ExprVisitor::VisitExpr(param);
}
ExprVisitor::VisitExpr(func_node->body);
}
}
IRModule RemoveUnusedFunctions(const IRModule& module, Array<runtime::String> entry_funcs) {
std::unordered_set<std::string> called_funcs{};
for (auto entry : entry_funcs) {
auto funcs = CallTracer(module).Trace(entry);
called_funcs.insert(funcs.cbegin(), funcs.cend());
}
auto existing_functions = module->functions;
for (auto f : existing_functions) {
auto it = called_funcs.find(f.first->name_hint);
if (it == called_funcs.end()) {
module->Remove(f.first);
}
}
return module;
}
比较容易看出这个pass就是去除Relay IR中的冗余节点,VisitExpr_这个函数就是完成了一个图的遍历,然后把没有遍历到的节点删掉。删除发生在RemoveUnusedFunctions这个函数中。
- ToBasicBlockNormalForm
这个Pass实现在tvm/src/relay/transforms/to_basic_block_normal_form.cc,代码实现如下:
Expr ToBasicBlockNormalFormAux(const Expr& e) {
// calculate all the dependency between nodes.
support::Arena arena;
DependencyGraph dg = DependencyGraph::Create(&arena, e);
/* The scope of the whole expr is global.
* The scope of any subexpr, is the lowest common ancestor of all incoming edge.
* We also record the set of expressions whose scope is lifted.
*/
std::pair<NodeScopeMap, ExprSet> scopes = CalcScope(dg);
return Fill::ToBasicBlockNormalForm(e, dg, &scopes.first, &scopes.second);
}
IRModule ToBasicBlockNormalForm(const IRModule& mod) {
DLOG(INFO) << "ToBBlock:" << std::endl << mod;
tvm::Map<GlobalVar, Function> updates;
auto funcs = mod->functions;
for (const auto& it : funcs) {
ICHECK_EQ(FreeVars(it.second).size(), 0) << "Expected no free variables";
if (const auto* n = it.second.as<FunctionNode>()) {
if (n->GetAttr<String>(attr::kCompiler).defined()) continue;
}
Expr ret = TransformF([&](const Expr& e) { return ToBasicBlockNormalFormAux(e); }, it.second);
updates.Set(it.first, Downcast<Function>(ret));
}
for (auto pair : updates) {
mod->Add(pair.first, pair.second, true);
}
DLOG(INFO) << "ToBBlock: transformed" << std::endl << mod;
return mod;
}
bool BasicBlockNormalFormCheck(const Expr& e) {
// calculate all the dependency between nodes.
support::Arena arena;
DependencyGraph dg = DependencyGraph::Create(&arena, e);
std::pair<NodeScopeMap, ExprSet> scopes = CalcScope(dg);
for (auto expr : scopes.second) {
LOG(FATAL) << "The expression below violates the basic block normal form in that "
<< "its scope should be lifted:\n"
<< expr;
}
return scopes.second.size() == 0;
}
ToBasicBlockNormalForm这个函数通过遍历Relay IR中的function,将每个function转换为基本块形式(即ToBasicBlockNormalFormAux这个函数),ToBasicBlockNormalFormAux这个函数分成以下几个部分:
-
调用
DependencyGraph dg = DependencyGraph::Create(&arena, e)创建一个DependencyGraph,这个数据结构是一个表达式相互依赖的图结构。 -
通过
std::pair<NodeScopeMap, ExprSet> scopes = CalcScope(dg)计算每个节点的scope,这个scope可以简单理解为由跳转指令如Ifnode,FunctionNode,LetNode等隔开的那些子图,因为一旦碰到这些节点在上面通过Relay Function创建DependencyGraph就会为这种节点分配一个new_scope标志。然后CalcScope这个函数具体做了哪些事情,我们需要跟进去看一下:
std::pair<NodeScopeMap, ExprSet> CalcScope(const DependencyGraph& dg) {
NodeScopeMap expr_scope;
ExprSet lifted_exprs;
std::unordered_map<DependencyGraph::Node*, Expr> node_to_expr;
// 首先让每个节点都属于一个单独的scope
for (auto expr_node : dg.expr_node) {
node_to_expr[expr_node.second] = expr_node.first;
}
bool global_scope_used = false;
Scope global_scope = std::make_shared<ScopeNode>();
// 使用LCA算法来更新每个节点的真正scope
for (auto it = dg.post_dfs_order.rbegin(); it != dg.post_dfs_order.rend(); ++it) {
DependencyGraph::Node* n = *it;
auto iit = n->parents.head;
Scope s;
if (iit == nullptr) {
ICHECK(!global_scope_used);
s = global_scope;
global_scope_used = true;
} else {
s = expr_scope.at(iit->value);
const auto original_s = s;
iit = iit->next;
for (; iit != nullptr; iit = iit->next) {
s = LCA(s, expr_scope.at(iit->value));
}
if (s != original_s && node_to_expr.find(n) != node_to_expr.end()) {
// filter out exprs whose scope do not matter
Expr expr = node_to_expr[n];
if (!expr.as<OpNode>()) {
lifted_exprs.insert(expr);
}
}
}
if (n->new_scope) {
auto child_scope = std::make_shared<ScopeNode>(s);
expr_scope.insert({n, child_scope});
} else {
expr_scope.insert({n, s});
}
}
ICHECK(global_scope_used);
return std::make_pair(expr_scope, lifted_exprs);
}
这个函数首先让每个节点都属于一个单独的scope,然后使用LCA算法来更新每个节点的真正scope。这里简单介绍一下LCA算法以及这里具体是如何求取每个节点的scope的。
最近公共祖先简称 LCA(Lowest Common Ancestor)。两个节点的最近公共祖先,就是这两个点的公共祖先里面,离根最远的那个。为了方便,我们记某点集 S={v_1,v_2,\ldots,v_n} 的最近公共祖先为 \text{LCA}(v_1,v_2,\ldots,v_n) 或 \text{LCA}(S)。LCA有以下性质,引自OI-wiki:
-
\text{LCA}({u})=u;
-
u 是 v 的祖先,当且仅当 \text{LCA}(u,v)=u;
-
如果 u 不为 v 的祖先并且 v 不为 u 的祖先,那么 u,v 分别处于 \text{LCA}(u,v) 的两棵不同子树中;
-
前序遍历中,\text{LCA}(S) 出现在所有 S 中元素之前,后序遍历中 \text{LCA}(S) 则出现在所有 S 中元素之后;
-
两点集并的最近公共祖先为两点集分别的最近公共祖先的最近公共祖先,即 \text{LCA}(A\cup B)=\text{LCA}(\text{LCA}(A), \text{LCA}(B));
-
两点的最近公共祖先必定处在树上两点间的最短路上;
-
d(u,v)=h(u)+h(v)-2h(\text{LCA}(u,v)),其中 d 是树上两点间的距离,h 代表某点到树根的距离。
其实不看这个性质也没关系,了解LCA可以求图中两个节点的最近公共祖先即可。然后CalcScope这个函数的具体思路就是先将每个节点初始化为一个单独的scope,然后按照后DFS序遍历这些节点,对于每一个遍历到的节点(这里记作n),看一下它的父亲节点iit是否存在,如果不存在则说明当前节点是根节点,它的scope应该为global_scope。如果iit存在,那么遍历iit的子节点,看一下这些节点的scope的LCA表达式,如果这个通过LCA求出来的表达式和iit节点的表达式完全相同,说明这个子图和当前节点是属于同一个scope的,否则就将当前节点插入到lifted_exprs,lifted_exprs是一个集合用来保存这个DependencyGraph里面的那些跳转指令节点,这也是为什么上面再插入节点到lifted_exprs之前需要判断一下这个节点的类型是否为OpNode。另外如果当前枚举的节点有new_scope标志,说明当前节点属于一个新的scope,需要为当前节点分配新的类型为ScopeNode的一个智能指针。
通过上面的算法,DependencyGraph中的节点和scope节点的关系就被映射到了一个map中,并且scope节点也被建立起了一个树结构。最后调用这个Fill::ToBasicBlockNormalForm(e, dg, &scopes.first, &scopes.second);来创建一个Fill类,这个类包含了DependencyGraph以及scope相关的信息,通过ToBasicBlockNormalForm成员函数实现基本块转换。它的实现在tvm/src/relay/transforms/to_a_normal_form.cc这个文件中,没有看得太懂,感兴趣的读者可以自己跟进来看一下,知乎的moon博主对这个Pass也做了解释,这里引用一下:
它(
ToBasicBlockNormalForm)的基本逻辑通过VisitExpr函数遍历dependency节点,将具有相同scope的节点压入到同一个let_list中。Let_list文档中是这样解释的:
/*!
* \file let_list.h
* \brief LetList record let binding and insert let expression implicitly.
* using it, one can treat AST as value instead of expression,
* and pass them around freely without fear of AST explosion (or effect duplication).
* for example, if one write 'b = a + a; c = b + b; d = c + c', the AST will contain 8 'a'.
* if one instead write 'b = ll.Push(a + a); c = ll.Push(b + b); d = ll.Get(c + c);',
* the AST will contain 2 'a', as b and c are now variables.
Let_list使得抽象语法树简洁化,不会因为变量的复制导致树的爆炸。具有相同的scope的expr被约束到相同的let_list中,用一个var来表达,这样就将表达式转化为var的形式。一个var也就对应了一个基本块。
- EliminateCommonSubexpr
最后再看一个消除公共子表达式的Pass,所谓公共子表达式指的就是具有相同的OP类型以及相同的参数,并且参数的顺序都是完全相同的,那么这些表达式就可以合成一个公共子表达式。举个例子:
a = b + c
d = b + c
可以看到这两个表达式时完全一致的,那么经过这个Pass之后计算图就会消除其中一个表达式。代码实现在:tvm/src/relay/transforms/eliminate_common_subexpr.cc。这里定义了一个CommonSubexprEliminator类,这个类重载了两个Rewrite_函数来对expr进行遍历和重写。代码实现如下:
Expr Rewrite_(const CallNode* call, const Expr& post) final {
static auto op_stateful = Op::GetAttrMap<TOpIsStateful>("TOpIsStateful");
Expr new_expr = post;
const CallNode* new_call = new_expr.as<CallNode>();
ICHECK(new_call);
const OpNode* op = new_call->op.as<OpNode>();
StructuralEqual attrs_equal;
if (new_call->args.size() == 0 || op == nullptr || op_stateful.get(GetRef<Op>(op), false)) {
return new_expr;
}
if (fskip_ != nullptr && fskip_(new_expr)) {
return new_expr;
}
auto it = expr_map_.find(new_call->op);
if (it != expr_map_.end()) {
for (const Expr& candidate_expr : it->second) {
if (const CallNode* candidate = candidate_expr.as<CallNode>()) {
bool is_equivalent = true;
// attrs匹配
if (!attrs_equal(new_call->attrs, candidate->attrs)) {
continue;
}
// args匹配
for (size_t i = 0; i < new_call->args.size(); i++) {
if (!new_call->args[i].same_as(candidate->args[i]) &&
!IsEqualScalar(new_call->args[i], candidate->args[i])) {
is_equivalent = false;
break;
}
}
if (!is_equivalent) continue;
return GetRef<Call>(candidate);
}
}
}
expr_map_[new_call->op].push_back(new_expr);
return new_expr;
}
可以看到大概的思路就是利用expr_map_这个std::unordered_map<Expr, std::vector<Expr>, ObjectPtrHash, ObjectPtrEqual> expr_map_;来映射遍历过的具有相同op的expr,然后每次碰到相同op的表达式都会对已经记录的expr进行匹配,匹配不仅包含OP的attrs属性还包含参数列表,如果它们完全一样说明这两个表达式就是公共表达式,就不返回新的表达式。这样就可以去掉Relay Function中的公共表达式了。
到这里可能还不是特别清楚我们最开始加载的那个simplenet的Relay Function经过一些Pass之后具体变成什么样,我其实目前也还没搞清楚这个问题,这个问题应该就需要留到后面再解答了。
0x5. 小结¶
这篇文章主要介绍了一下TVM的Relay并介绍了如何基于Relay构建一个Conv+BN+ReLU的小网络,然后介绍了一下TVM中的Pass的工作机制,并较为详细的介绍了RemoveUnusedFunctions,ToBasicBlockNormalForm,EliminateCommonSubexpr三种Pass。其中Relay部分的详细介绍大部分引用自官方文档:https://tvm.apache.org/docs/tutorials/get_started/introduction.html。
0x6. 参考资料¶
- https://zhuanlan.zhihu.com/p/358437531
- https://zhuanlan.zhihu.com/p/91283238
- https://tvm.apache.org/docs/tutorials/get_started/introduction.html
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次