0. 序言¶
版权声明:此份电子书整理自公众号「 GiantPandaCV 」, 版权所有 GiantPandaCV , 禁止任何形式的转载, 禁止传播、商用, 违者必究!
GiantPandaCV公众号由专注于技术的一群95后创建, 专注于机器学习、深度学习、计算机视觉、图像处理等领域。每天更新一到两篇相关推文, 希望在传播知识、分享知识的同时能够启发你。
欢迎关注我们的公众号GiantPandaCV:

目前为止,我们已经推出了《从零开始学习YOLOv3》和《从零开始学习SSD》两个系列教程,方便各位传阅,但是请注意版权归GiantPandaCV公众号所有,不可用于牟利, 否则我们将保留起诉的权利。
1. 整体框架¶
Faster R-CNN是R-CNN系列中第三个模型, 经历了2013年Girshick提出的R-CNN、2015年Girshick提出的Fast R-CNN以及2015年Ren提出的Faster R-CNN。
Faster R-CNN是目标检测中较早提出来的两阶段网络, 其网络架构如下图所示:

可以看出可以大体分为四个部分:
- Conv Layers 卷积神经网络用于提取特征, 得到feature map。
- RPN网络, 用于提取Region of Interests(RoI)。
- RoI pooling, 用于综合RoI和feature map, 得到固定大小的resize后的feature。
- classifier, 用于分类RoI属于哪个类别。
1.1 Conv Layers¶
在Conv Layers中, 对输入的图片进行卷积和池化, 用于提取图片特征, 最终希望得到的是feature map。在Faster R-CNN中, 先将图片Resize到固定尺寸, 然后使用了VGG16中的13个卷积层、13个ReLU层、4个maxpooling层。(VGG16中进行了5次下采样, 这里舍弃了第四次下采样后的部分, 将剩下部分作为Conv Layer提取特征。)
与YOLOv3不同,Faster R-CNN下采样后的分辨率为原始图片分辨率的1/16(YOLOv3是变为原来的1/32)。feature map的分辨率要比YOLOv3的Backbone得到的分辨率要大, 这也可以解释为何Faster R-CNN在小目标上的检测效果要优于YOLOv3。
1.2 Region Proposal Network¶
简称RPN网络, 用于推荐候选区域(Region of Interests), 接受的输入为原图片经过Conv Layer后得到的feature map。

上图参考的实现是:https://github.com/ruotianluo/pytorch-faster-rcnn
RPN网络将feature map作为输入, 然后用了一个3x3卷积将filter减半为512,然后进入两个分支:
一个分支用于计算对应anchor的foreground和background的概率, 目标是foreground。
一个分支用于计算对应anchor的Bounding box的偏移量, 来获得其目标的定位。
通过RPN网络, 我们就得到了每个anchor是否含有目标和在含有目标情况下目标的位置信息。
对比RPN和YOLOv3:
都说YOLOv3借鉴了RPN,这里对比一下两者:
RPN: 分两个分支, 一个分支预测目标框, 一个分支预测前景或者背景。将两个工作分开来做的, 并且其中前景背景预测分支功能是判断这个anchor是否含有目标, 并不会对目标进行分类。另外就是anchor的设置是通过先验得到的。
YOLOv3:将整个问题当做回归问题, 直接就可以获取目标类别和坐标。Anchor是通过IoU聚类得到的。
区别:Anchor的设置,Ground truth和Anchor的匹配细节不一样。
联系:两个都是在最后的feature map(w/16,h/16或者w/32,h/32)上每个点都分配了多个anchor,然后进行匹配。虽然具体实现有较大的差距, 但是这个想法有共同点。
1.3 ROI Pooling¶
这里看一个来自deepsense.ai提供的例子:
RoI Pooling输入是feature map和RoIs:
假设feature map是如下内容:

RPN提供的其中一个RoI为:左上角坐标(0,3), 右下角坐标(7,8)

然后将RoI对应到feature map上的部分切割为2x2大小的块:

将每个块做类似maxpooling的操作, 得到以下结果:

以上就是ROI pooling的完整操作, 想一想为何要这样做?
在RPN阶段, 我们得知了当前图片是否有目标, 在有目标情况下目标的位置。现在唯一缺少的信息就是这个目标到底属于哪个类别(通过RPN只能得知这个目标属于前景, 但并不能得到具体类别)。
如果想要得知这个目标属于哪个类别, 最简单的想法就是将得到的框内的图片放入一个CNN进行分类, 得到最终类别。这就涉及到最后一个模块:classification
1.4 Classification¶
ROIPooling后得到的是大小一致的feature,然后分为两个分支, 靠下的一个分支去进行分类, 上一个分支是用于Bounding box回归。如下图所示(来自知乎):

分类这个分支很容易理解, 用于计算到底属于哪个类别。Bounding box回归的分支用于调整RPN预测得到的Bounding box,让回归的结果更加精确。
参考内容¶
文章链接:https://arxiv.org/abs/1504.08083
博客:http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/
代码:https://github.com/ruotianluo/pytorch-faster-rcnn
ROI pooling:https://deepsense.ai/region-of-interest-pooling-explained/
Classification图示:https://zhuanlan.zhihu.com/p/31426458
2. 代码解析第一部分¶
2.1 Faster RCNN整体结构¶
Faster RCNN的背景, 介绍这些都没必要再次讲解了, 这里我们直接再来复习一下Faster RCNN的整体结构, 如下图所示。

可以看到Faster RCNN大概可以分成绿色描述的4个部分, 即:
- DataSet:代表数据集, 典型的比如VOC和COCO。
- Extrator:特征提取器, 也即是我们常说的Backbone网络, 典型的有VGG和ResNet。
- RPN:全称Region Proposal Network,负责产生候选区域(rois), 每张图大概给出2000个候选框。
- RoIHead:负责对rois进行分类和回归微调。
所以Faster RCNN的流程可以总结为:
原始图像--->特征提取------>RPN产生候选框------>对候选框进行分类和回归微调。
2.2 数据预处理及实现细节¶
首先让我们进入到这个Pytorch的Faster RCNN工程:https://github.com/chenyuntc/simple-faster-rcnn-pytorch。数据预处理的相关细节都在data这个文件夹下面, 我画了一个流程图总结了Faster RCNN的预处理, 如下:

接下来我们结合一下我的代码注释来理解一下, 首先是data/dataset.py。
# 去正则化,img维度为[[B,G,R],H,W],因为caffe预训练模型输入为BGR 0-255图片,pytorch预训练模型采用RGB 0-1图片
def inverse_normalize(img):
if opt.caffe_pretrain:
# [122.7717, 115.9465, 102.9801]reshape为[3,1,1]与img维度相同就可以相加了,
# pytorch_normalize之前有减均值预处理, 现在还原回去。
img = img + (np.array([122.7717, 115.9465, 102.9801]).reshape(3, 1, 1))
# 将BGR转换为RGB图片(python [::-1]为逆序输出)
return img[::-1, :, :]
# pytorch_normalze中标准化为减均值除以标准差, 现在乘以标准差加上均值还原回去, 转换为0-255
return (img * 0.225 + 0.45).clip(min=0, max=1) * 255
# 采用pytorch预训练模型对图片预处理, 函数输入的img为0-1
def pytorch_normalze(img):
"""
https://github.com/pytorch/vision/issues/223
return appr -1~1 RGB
"""
# #transforms.Normalize使用如下公式进行归一化
# channel=(channel-mean)/std,转换为[-1,1]
normalize = tvtsf.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# nddarry->Tensor
img = normalize(t.from_numpy(img))
return img.numpy()
# 采用caffe预训练模型时对输入图像进行标准化, 函数输入的img为0-1
def caffe_normalize(img):
"""
return appr -125-125 BGR
"""
# RGB-BGR
img = img[[2, 1, 0], :, :] # RGB-BGR
img = img * 255
# 转换为与img维度相同
mean = np.array([122.7717, 115.9465, 102.9801]).reshape(3, 1, 1)
# 减均值操作
img = (img - mean).astype(np.float32, copy=True)
return img
# 函数输入的img为0-255
def preprocess(img, min_size=600, max_size=1000):
# 图片进行缩放, 使得长边小于等于1000,短边小于等于600(至少有一个等于)。
# 对相应的bounding boxes 也也进行同等尺度的缩放。
C, H, W = img.shape
scale1 = min_size / min(H, W)
scale2 = max_size / max(H, W)
# 选小的比例, 这样长和宽都能放缩到规定的尺寸
scale = min(scale1, scale2)
img = img / 255.
# resize到(H * scale, W * scale)大小,anti_aliasing为是否采用高斯滤波
img = sktsf.resize(img, (C, H * scale, W * scale), mode='reflect',anti_aliasing=False)
#调用pytorch_normalze或者caffe_normalze对图像进行正则化
if opt.caffe_pretrain:
normalize = caffe_normalize
else:
normalize = pytorch_normalze
return normalize(img)
class Transform(object):
def __init__(self, min_size=600, max_size=1000):
self.min_size = min_size
self.max_size = max_size
def __call__(self, in_data):
img, bbox, label = in_data
_, H, W = img.shape
# 图像等比例缩放
img = preprocess(img, self.min_size, self.max_size)
_, o_H, o_W = img.shape
# 得出缩放比因子
scale = o_H / H
# bbox按照与原图等比例缩放
bbox = util.resize_bbox(bbox, (H, W), (o_H, o_W))
# 将图片进行随机水平翻转, 没有进行垂直翻转
img, params = util.random_flip(
img, x_random=True, return_param=True)
# 同样地将bbox进行与对应图片同样的水平翻转
bbox = util.flip_bbox(
bbox, (o_H, o_W), x_flip=params['x_flip'])
return img, bbox, label, scale
# 训练集样本的生成
class Dataset:
def __init__(self, opt):
self.opt = opt
# 实例化类
self.db = VOCBboxDataset(opt.voc_data_dir)
#实例化类
self.tsf = Transform(opt.min_size, opt.max_size)
# __ xxx__运行Dataset类时自动运行
def __getitem__(self, idx):
# 调用VOCBboxDataset中的get_example()从数据集存储路径中将img, bbox, label, difficult 一个个的获取出来
ori_img, bbox, label, difficult = self.db.get_example(idx)
# 调用前面的Transform函数将图片,label进行最小值最大值放缩归一化,
# 重新调整bboxes的大小, 然后随机反转, 最后将数据集返回
img, bbox, label, scale = self.tsf((ori_img, bbox, label))
# TODO: check whose stride is negative to fix this instead copy all
# some of the strides of a given numpy array are negative.
return img.copy(), bbox.copy(), label.copy(), scale
def __len__(self):
return len(self.db)
# 测试集样本的生成
class TestDataset:
def __init__(self, opt, split='test', use_difficult=True):
self.opt = opt
# 此处设置了use_difficult,
self.db = VOCBboxDataset(opt.voc_data_dir, split=split, use_difficult=use_difficult)
def __getitem__(self, idx):
ori_img, bbox, label, difficult = self.db.get_example(idx)
img = preprocess(ori_img)
return img, ori_img.shape[1:], bbox, label, difficult
def __len__(self):
return len(self.db)
接下来是data/voc_dataset.py, 注释如下:
class VOCBboxDataset:
def __init__(self, data_dir, split='trainval',
use_difficult=False, return_difficult=False,
):
# if split not in ['train', 'trainval', 'val']:
# if not (split == 'test' and year == '2007'):
# warnings.warn(
# 'please pick split from \'train\', \'trainval\', \'val\''
# 'for 2012 dataset. For 2007 dataset, you can pick \'test\''
# ' in addition to the above mentioned splits.'
# )
# id_list_file为split.txt,split为'trainval'或者'test'
id_list_file = os.path.join(
data_dir, 'ImageSets/Main/{0}.txt'.format(split))
# id_为每个样本文件名
self.ids = [id_.strip() for id_ in open(id_list_file)]
# 写到/VOC2007/的路径
self.data_dir = data_dir
self.use_difficult = use_difficult
self.return_difficult = return_difficult
# 20类
self.label_names = VOC_BBOX_LABEL_NAMES
# trainval.txt有5011个,test.txt有210个
def __len__(self):
return len(self.ids)
def get_example(self, i):
#读入xml标签文件
id_ = self.ids[i]
anno = ET.parse(
os.path.join(self.data_dir, 'Annotations', id_ + '.xml'))
bbox = list()
label = list()
difficult = list()
#解析xml文件
for obj in anno.findall('object'):
# 标为difficult的目标在测试评估中一般会被忽略
if not self.use_difficult and int(obj.find('difficult').text) == 1:
continue
#xml文件中包含object name和difficult(0或者1,0代表容易检测)
difficult.append(int(obj.find('difficult').text))
# bndbox(xmin,ymin,xmax,ymax),表示框左上角和右下角坐标
bndbox_anno = obj.find('bndbox')
# #让坐标基于(0,0)
bbox.append([
int(bndbox_anno.find(tag).text) - 1
for tag in ('ymin', 'xmin', 'ymax', 'xmax')])
# 框中object name
name = obj.find('name').text.lower().strip()
label.append(VOC_BBOX_LABEL_NAMES.index(name))
# 所有object的bbox坐标存在列表里
bbox = np.stack(bbox).astype(np.float32)
# 所有object的label存在列表里
label = np.stack(label).astype(np.int32)
# PyTorch 不支持 np.bool,所以这里转换为uint8
difficult = np.array(difficult, dtype=np.bool).astype(np.uint8)
# 根据图片编号在/JPEGImages/取图片
img_file = os.path.join(self.data_dir, 'JPEGImages', id_ + '.jpg')
# 如果color=True,则转换为RGB图
img = read_image(img_file, color=True)
# if self.return_difficult:
# return img, bbox, label, difficult
return img, bbox, label, difficult
# 一般如果想使用索引访问元素时, 就可以在类中定义这个方法(__getitem__(self, key) )
__getitem__ = get_example
# 类别和名字对应的列表
VOC_BBOX_LABEL_NAMES = (
'aeroplane',
'bicycle',
'bird',
'boat',
'bottle',
'bus',
'car',
'cat',
'chair',
'cow',
'diningtable',
'dog',
'horse',
'motorbike',
'person',
'pottedplant',
'sheep',
'sofa',
'train',
'tvmonitor')
再接下来是utils.py里面一些用到的相关函数的注释, 只选了其中几个, 并且有一些函数没有用到, 全部放上来篇幅太多:
def resize_bbox(bbox, in_size, out_size):
# 根据图片resize的情况来缩放bbox
bbox = bbox.copy()
# #获得与原图同样的缩放比
y_scale = float(out_size[0]) / in_size[0]
x_scale = float(out_size[1]) / in_size[1]
# #按与原图同等比例缩放bbox
bbox[:, 0] = y_scale * bbox[:, 0]
bbox[:, 2] = y_scale * bbox[:, 2]
bbox[:, 1] = x_scale * bbox[:, 1]
bbox[:, 3] = x_scale * bbox[:, 3]
return bbox
def flip_bbox(bbox, size, y_flip=False, x_flip=False):
# 根据图片flip的情况来flip bbox
H, W = size #缩放后图片的size
bbox = bbox.copy()
if y_flip: #进行垂直翻转
y_max = H - bbox[:, 0]
y_min = H - bbox[:, 2]
bbox[:, 0] = y_min
bbox[:, 2] = y_max
if x_flip: #进行水平翻转
x_max = W - bbox[:, 1]
x_min = W - bbox[:, 3] #计算水平翻转后左下角和右下角的坐标
bbox[:, 1] = x_min
bbox[:, 3] = x_max
return bbox
def random_flip(img, y_random=False, x_random=False,
return_param=False, copy=False):
# 数据增强, 随机翻转
y_flip, x_flip = False, False
if y_random:
y_flip = random.choice([True, False])
# 随机选择图片是否进行水平翻转
if x_random:
x_flip = random.choice([True, False])
if y_flip:
img = img[:, ::-1, :]
if x_flip:
# python [::-1]为逆序输出, 这里指水平翻转
img = img[:, :, ::-1]
if copy:
img = img.copy()
if return_param:
#返回img和x_flip(为了让bbox有同样的水平翻转操作)
return img, {'y_flip': y_flip, 'x_flip': x_flip}
else:
return img
至此, 我们就可以很好的理解数据预处理部分了, 这部分也是最简单的, 下一节我们开始搭建模型。带注释的Faster RCNN完整代码版本等我更新完这个专题我再放出来。
2.3 思考¶
可以看到在Faster RCNN的代码中, 数据预处理是相对简单的, 没有大量的增强操作(相比于YOLOV3来说), 如果结合更多的数据增强操作是否可以获得更好的精度呢?感觉值得尝试一下。
参考文献¶
3. 代码解析第二部分¶
3.1 原理介绍&代码详解¶
还是先回忆一下上节讲到的Faster RCNN整体结构, 如下所示:

可以看到原始图片首先会经过一个特征提取器Extrator这里是VGG16,在原始论文中作者使用了Caffe的预训练模型。同时将VGG16模型的前4层卷积层的参数冻结(在Caffe中将其学习率设为0), 并将最后三层全连接层的前两层保留并用来初始化ROIHead里面部分参数, 等我们将代码解析到这里了, 就很好理解了, 暂时没理解也不要紧, 只是了解一下有这个流程即可。我们可以将Extrator用下图来表示:

可以看到对于一个尺寸为H\times W\times C的图片, 经过这个特征提取网络之后会得到一个\frac{H}{16}\times \frac{W}{16} \times 512的特征图, 也即是图中的红色箭头代表的Features。
接下来我们来讲一下RPN,我们从整体结构图中可以看到RPN这个候选框生成网络接收了2个输入, 一个是特征图也就是我们刚提到的, 另外一个是数据集提供的GT Box,这里面究竟是怎么操作呢?
我们知道RPN网络使用来提取候选框的, 它最大的贡献就在于它提出了一个Anchor的思想, 这也是后面One-Stage以及Two-Stage的各类目标检测算法的出发点, Anchor表示的是大小和尺寸固定的候选框, 论文中用到了三种比例和三种尺寸, 也就是说对于特征图的每个点都将产生3\times 3=9种不同大小的Anchor候选框, 其中三种尺寸分别是128(下图中的蓝色), 256(下图中的红色), 512(下图中的绿色), 而三种比例分别为:1:2, 2:1, 1:1。Faster RCNN的九种Anchor的示意图如下:

然后我们来算一下对于一个尺寸为512\times 62\times 37的特征图有多少个Anchor,上面提到对于特征图的每个点都要产生9个Anchor,那么这个特征图就一共会产生62\times 37 \times 9=20464个Anchor。可以看到一张图片产生这么多Anchor,肯定很多Anchor和真正的目标框是接近的(IOU大), 这相对于从0开始回归目标框就大大降低了难度, 可以理解为有一些老司机先给出了我们一些经验, 然后我们在这些经验上去做出判断和优化, 这样就更容易了。
这里我们先来看一下生成Anchor的过程, 具体是在model/util文件夹下, 我们首先来看bbox_tools.py文件, 其中涉及到了RCNN中提到的边框回归公式, \hat{G}代表候选框, 而回归学习就是学习d_x,d_y,d_h,d_w这4个偏移量, \hat{G}和P的关系可以如下表示:
真正的目标框和候选框之间的偏移可以表示为:
bbox_tools.py的具体解释如下:
# 已知源bbox和位置偏差dx,dy,dh,dw,求目标框G
def loc2bbox(src_bbox, loc):
# src_bbox:(R,4),R为bbox个数, 4为左上角和右下角四个坐标
if src_bbox.shape[0] == 0:
return xp.zeros((0, 4), dtype=loc.dtype)
src_bbox = src_bbox.astype(src_bbox.dtype, copy=False)
#src_height为Ph,src_width为Pw,src_ctr_y为Py,src_ctr_x为Px
src_height = src_bbox[:, 2] - src_bbox[:, 0] #ymax-ymin
src_width = src_bbox[:, 3] - src_bbox[:, 1] #xmax-xmin
src_ctr_y = src_bbox[:, 0] + 0.5 * src_height #y0+0.5h
src_ctr_x = src_bbox[:, 1] + 0.5 * src_width #x0+0.5w,计算出中心点坐标
#python [start:stop:step]
dy = loc[:, 0::4]
dx = loc[:, 1::4]
dh = loc[:, 2::4]
dw = loc[:, 3::4]
# RCNN中提出的边框回归:寻找原始proposal与近似目标框G之间的映射关系, 公式在上面
ctr_y = dy * src_height[:, xp.newaxis] + src_ctr_y[:, xp.newaxis] #ctr_y为Gy
ctr_x = dx * src_width[:, xp.newaxis] + src_ctr_x[:, xp.newaxis] # ctr_x为Gx
h = xp.exp(dh) * src_height[:, xp.newaxis] #h为Gh
w = xp.exp(dw) * src_width[:, xp.newaxis] #w为Gw
# 上面四行得到了回归后的目标框(Gx,Gy,Gh,Gw)
# 由中心点转换为左上角和右下角坐标
dst_bbox = xp.zeros(loc.shape, dtype=loc.dtype)
dst_bbox[:, 0::4] = ctr_y - 0.5 * h
dst_bbox[:, 1::4] = ctr_x - 0.5 * w
dst_bbox[:, 2::4] = ctr_y + 0.5 * h
dst_bbox[:, 3::4] = ctr_x + 0.5 * w
return dst_bbox
# 已知源框和目标框求出其位置偏差
def bbox2loc(src_bbox, dst_bbox):
# 计算出源框中心点坐标
height = src_bbox[:, 2] - src_bbox[:, 0]
width = src_bbox[:, 3] - src_bbox[:, 1]
ctr_y = src_bbox[:, 0] + 0.5 * height
ctr_x = src_bbox[:, 1] + 0.5 * width
# 计算出目标框中心点坐标
base_height = dst_bbox[:, 2] - dst_bbox[:, 0]
base_width = dst_bbox[:, 3] - dst_bbox[:, 1]
base_ctr_y = dst_bbox[:, 0] + 0.5 * base_height
base_ctr_x = dst_bbox[:, 1] + 0.5 * base_width
# 求出最小的正数
eps = xp.finfo(height.dtype).eps
# 将height,width与其比较保证全部是非负
height = xp.maximum(height, eps)
width = xp.maximum(width, eps)
# 根据上面的公式二计算dx,dy,dh,dw
dy = (base_ctr_y - ctr_y) / height
dx = (base_ctr_x - ctr_x) / width
dh = xp.log(base_height / height)
dw = xp.log(base_width / width)
# np.vstack按照行的顺序把数组给堆叠起来
loc = xp.vstack((dy, dx, dh, dw)).transpose()
return loc
# 求两个bbox的相交的交并比
def bbox_iou(bbox_a, bbox_b):
# 确保bbox第二维为bbox的四个坐标(ymin,xmin,ymax,xmax)
if bbox_a.shape[1] != 4 or bbox_b.shape[1] != 4:
raise IndexError
# top left
# l为交叉部分框左上角坐标最大值, 为了利用numpy的广播性质,
# bbox_a[:, None, :2]的shape是(N,1,2),bbox_b[:, :2]
# shape是(K,2),由numpy的广播性质, 两个数组shape都变成(N,K,2),
# 也就是对a里每个bbox都分别和b里的每个bbox求左上角点坐标最大值
tl = xp.maximum(bbox_a[:, None, :2], bbox_b[:, :2])
# bottom right
# br为交叉部分框右下角坐标最小值
br = xp.minimum(bbox_a[:, None, 2:], bbox_b[:, 2:])
# 所有坐标轴上tl<br时, 返回数组元素的乘积(y1max-yimin)X(x1max-x1min),
# bboxa与bboxb相交区域的面积
area_i = xp.prod(br - tl, axis=2) * (tl < br).all(axis=2)
# 计算bboxa的面积
area_a = xp.prod(bbox_a[:, 2:] - bbox_a[:, :2], axis=1)
# 计算bboxb的面积
area_b = xp.prod(bbox_b[:, 2:] - bbox_b[:, :2], axis=1)
# 计算IOU
return area_i / (area_a[:, None] + area_b - area_i)
def __test():
pass
if __name__ == '__main__':
__test()
# 对特征图features以基准长度为16、选择合适的ratios和scales取基准锚点
# anchor_base。(选择长度为16的原因是图片大小为600*800左右, 基准长度
# 16对应的原图区域是256*256,考虑放缩后的大小有128*128,512*512比较合适)
def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]):
# 根据基准点生成9个基本的anchor的功能,ratios=[0.5,1,2],anchor_scales=
# [8,16,32]是长宽比和缩放比例,anchor_scales也就是在base_size的基础上再增
# 加的量, 本代码中对应着三种面积的大小(16*8)^2 ,(16*16)^2 (16*32)^2
# 也就是128,256,512的平方大小
py = base_size / 2.
px = base_size / 2.
#(9,4), 注意:这里只是以特征图的左上角点为基准产生的9个anchor,
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4),
dtype=np.float32)
# six.moves 是用来处理那些在python2 和 3里面函数的位置有变化的,
# 直接用six.moves就可以屏蔽掉这些变化
for i in six.moves.range(len(ratios)):
for j in six.moves.range(len(anchor_scales)):
# 生成9种不同比例的h和w
h = base_size * anchor_scales[j] * np.sqrt(ratios[i])
w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i])
index = i * len(anchor_scales) + j
# 计算出anchor_base画的9个框的左上角和右下角的4个anchor坐标值
anchor_base[index, 0] = py - h / 2.
anchor_base[index, 1] = px - w / 2.
anchor_base[index, 2] = py + h / 2.
anchor_base[index, 3] = px + w / 2.
return anchor_base
在上面的generate_anchor_base函数中, 输出Anchor的形状以及这9个Anchor的左上右下坐标如下:
这9个anchor形状为:
90.50967 *181.01933 = 128^2
181.01933 * 362.03867 = 256^2
362.03867 * 724.07733 = 512^2
128.0 * 128.0 = 128^2
256.0 * 256.0 = 256^2
512.0 * 512.0 = 512^2
181.01933 * 90.50967 = 128^2
362.03867 * 181.01933 = 256^2
724.07733 * 362.03867 = 512^2
9个anchor的左上右下坐标:
-37.2548 -82.5097 53.2548 98.5097
-82.5097 -173.019 98.5097 189.019
-173.019 -354.039 189.019 370.039
-56 -56 72 72
-120 -120 136 136
-248 -248 264 264
-82.5097 -37.2548 98.5097 53.2548
-173.019 -82.5097 189.019 98.5097
-354.039 -173.019 370.039 189.019
需要注意的是:
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4), dtype=np.float32)
这行代码表示的是只是以特征图的左上角为基准产生的9个Anchor,而我们知道Faster RCNN是会在特征图的每个点产生9个Anchor的, 这个过程在什么地方呢?答案是在mode/region_proposal_network.py里面, 这里面的_enumerate_shifted_anchor这个函数就实现了这一功能, 接下来我们就仔细看看这个函数是如何产生整个特征图的所有Anchor的(一共20000+个左右Anchor,另外产生的Anchor坐标会截断到图像坐标范围里面)。下面来看看model/region_proposal_network.py里面的_enumerate_shifted_anchor函数:
# 利用anchor_base生成所有对应feature map的anchor
def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width):
# Enumerate all shifted anchors:
#
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
# return (K*A, 4)
# !TODO: add support for torch.CudaTensor
# xp = cuda.get_array_module(anchor_base)
# it seems that it can't be boosed using GPU
import numpy as xp
# 纵向偏移量(0,16,32,...)
shift_y = xp.arange(0, height * feat_stride, feat_stride)
# 横向偏移量(0,16,32,...)
shift_x = xp.arange(0, width * feat_stride, feat_stride)
# shift_x = [[0,16,32,..],[0,16,32,..],[0,16,32,..]...],
# shift_y = [[0,0,0,..],[16,16,16,..],[32,32,32,..]...],
# 就是形成了一个纵横向偏移量的矩阵, 也就是特征图的每一点都能够通过这个
# 矩阵找到映射在原图中的具体位置!
shift_x, shift_y = xp.meshgrid(shift_x, shift_y)
# #经过刚才的变化, 其实大X,Y的元素个数已经相同, 看矩阵的结构也能看出,
# 矩阵大小是相同的,X.ravel()之后变成一行, 此时shift_x,shift_y的元
# 素个数是相同的, 都等于特征图的长宽的乘积(像素点个数), 不同的是此时
# 的shift_x里面装得是横向看的x的一行一行的偏移坐标, 而此时的y里面装
# 的是对应的纵向的偏移坐标!下图显示xp.meshgrid(),shift_y.ravel()
# 操作示例
shift = xp.stack((shift_y.ravel(), shift_x.ravel(),
shift_y.ravel(), shift_x.ravel()), axis=1)
# A=9
A = anchor_base.shape[0]
# 读取特征图中元素的总个数
K = shift.shape[0]
#用基础的9个anchor的坐标分别和偏移量相加, 最后得出了所有的anchor的坐标,
# 四列可以堪称是左上角的坐标和右下角的坐标加偏移量的同步执行, 飞速的从
# 上往下捋一遍, 所有的anchor就都出来了!一共K个特征点, 每一个有A(9)个
# 基本的anchor,所以最后reshape((K*A),4)的形式, 也就得到了最后的所有
# 的anchor左上角和右下角坐标.
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
anchor = anchor_base.reshape((1, A, 4)) + \
shift.reshape((1, K, 4)).transpose((1, 0, 2))
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
return anchor
我们结合一个例子来看一下shift_x, shift_y = xp.meshgrid(shift_x, shift_y)函数操这个函数到底执行了什么操作?其中xp就是numpy。

然后shift = xp.stack((shift_y.ravel(), shift_x.ravel(),shift_y.ravel(), shift_x.ravel()), axis=1)这行代码则是产生坐标偏移对, 一个是x方向, 一个是y方向。
另外一个问题是这里为什么需要将特征图对应回原图呢?这是因为我们要框住的目标是在原图上, 而我们选Anchor是在特征图上,Pooling之后特征之间的相对位置不变, 但是尺寸已经减少为了原始图的\frac{1}{16}, 而我们的Anchor是为了框住原图上的目标而非特征图上的, 所以注意一下Anchor一定指的是针对原图的, 而非特征图。
接下来我们看看训练RPN的一些细节,RPN的总体架构如下图所示:

首先我们要明确Anchor的数量是和特征图相关的, 不同的特征图对应的Anchor数量也不一样。RPN在Extractor输出的特征图基础上先增加了一个3\times 3卷积, 然后利用两个1\times 1卷积分别进行二分类和位置回归。进行分类的卷积核通道数为9\times 2(9个Anchor,每个Anchor二分类, 使用交叉熵损失), 进行回归的卷积核通道数为9\times 4(9个Anchor,每个Anchor有4个位置参数)。RPN是一个全卷积网络, 这样对输入图片的尺寸是没有要求的。
接下来我们就要讲到今天的重点部分了, 即AnchorTargetCreator, ProposalCreator, ProposalTargetCreator, 也就是ROI Head最核心的部分:
3.2 AnchorTargetCreator¶
AnchorTargetCreator就是将20000多个候选的Anchor选出256个Anchor进行分类和回归, 选择过程如下:
- 对于每一个GT bbox,选择和它交并比最大的一个Anchor作为正样本。
- 对于剩下的Anchor,从中选择和任意一个GT bbox交并比超过0.7的Anchor作为正样本, 正样本数目不超过128个。
- 随机选择和GT bbox交并比小于0.3的Anchor作为负样本, 负样本和正样本的总数为256。
对于每一个Anchor来说,GT_Label要么为1(前景), 要么为0(背景), 而GT_Loc则是由4个位置参数组成, 也就是上面讲的目标框和候选框之间的偏移。
计算分类损失使用的是交叉熵损失, 而计算回归损失则使用了SmoothL1Loss,在计算回归损失的时候只计算正样本(前景)的损失, 不计算负样本的损失。
代码实现在model/utils/creator_tool.py里面, 具体如下:
# AnchorTargetCreator作用是生成训练要用的anchor(正负样本
# 各128个框的坐标和256个label(0或者1))
# 利用每张图中bbox的真实标签来为所有任务分配ground truth
class AnchorTargetCreator(object):
def __init__(self,
n_sample=256,
pos_iou_thresh=0.7, neg_iou_thresh=0.3,
pos_ratio=0.5):
self.n_sample = n_sample
self.pos_iou_thresh = pos_iou_thresh
self.neg_iou_thresh = neg_iou_thresh
self.pos_ratio = pos_ratio
def __call__(self, bbox, anchor, img_size):
# 特征图大小
img_H, img_W = img_size
# 一般对应20000个左右anchor
n_anchor = len(anchor)
# 将那些超出图片范围的anchor全部去掉,只保留位于图片内部的序号
inside_index = _get_inside_index(anchor, img_H, img_W)
# 保留位于图片内部的anchor
anchor = anchor[inside_index]
# 筛选出符合条件的正例128个负例128并给它们附上相应的label
argmax_ious, label = self._create_label(
inside_index, anchor, bbox)
# 计算每一个anchor与对应bbox求得iou最大的bbox计算偏移
# 量(注意这里是位于图片内部的每一个)
loc = bbox2loc(anchor, bbox[argmax_ious])
# 将位于图片内部的框的label对应到所有生成的20000个框中
# (label原本为所有在图片中的框的)
label = _unmap(label, n_anchor, inside_index, fill=-1)
# 将回归的框对应到所有生成的20000个框中(label原本为
# 所有在图片中的框的)
loc = _unmap(loc, n_anchor, inside_index, fill=0)
return loc, label
# 下面为调用的_creat_label() 函数
def _create_label(self, inside_index, anchor, bbox):
# inside_index为所有在图片范围内的anchor序号
label = np.empty((len(inside_index),), dtype=np.int32)
# #全部填充-1
label.fill(-1)
# 调用_calc_ious()函数得到每个anchor与哪个bbox的iou最大
# 以及这个iou值、每个bbox与哪个anchor的iou最大(需要体会从
# 行和列取最大值的区别)
argmax_ious, max_ious, gt_argmax_ious = \
self._calc_ious(anchor, bbox, inside_index)
# #把每个anchor与对应的框求得的iou值与负样本阈值比较, 若小
# 于负样本阈值, 则label设为0,pos_iou_thresh=0.7,
# neg_iou_thresh=0.3
label[max_ious < self.neg_iou_thresh] = 0
# 把与每个bbox求得iou值最大的anchor的label设为1
label[gt_argmax_ious] = 1
# 把每个anchor与对应的框求得的iou值与正样本阈值比较,
# 若大于正样本阈值, 则label设为1
label[max_ious >= self.pos_iou_thresh] = 1
# 按照比例计算出正样本数量,pos_ratio=0.5,n_sample=256
n_pos = int(self.pos_ratio * self.n_sample)
# 得到所有正样本的索引
pos_index = np.where(label == 1)[0]
# 如果选取出来的正样本数多于预设定的正样本数, 则随机抛弃, 将那些抛弃的样本的label设为-1
if len(pos_index) > n_pos:
disable_index = np.random.choice(
pos_index, size=(len(pos_index) - n_pos), replace=False)
label[disable_index] = -1
# 设定的负样本的数量
n_neg = self.n_sample - np.sum(label == 1)
# 负样本的索引
neg_index = np.where(label == 0)[0]
if len(neg_index) > n_neg:
# 随机选择不要的负样本, 个数为len(neg_index)-neg_index,label值设为-1
disable_index = np.random.choice(
neg_index, size=(len(neg_index) - n_neg), replace=False)
label[disable_index] = -1
return argmax_ious, label
# _calc_ious函数
def _calc_ious(self, anchor, bbox, inside_index):
# ious between the anchors and the gt boxes
# 调用bbox_iou函数计算anchor与bbox的IOU, ious:(N,K),
# N为anchor中第N个,K为bbox中第K个,N大概有15000个
ious = bbox_iou(anchor, bbox)
# 1代表行, 0代表列
argmax_ious = ious.argmax(axis=1)
# 求出每个anchor与哪个bbox的iou最大, 以及最大值,max_ious:[1,N]
max_ious = ious[np.arange(len(inside_index)), argmax_ious]
gt_argmax_ious = ious.argmax(axis=0)
# 求出每个bbox与哪个anchor的iou最大, 以及最大值,gt_max_ious:[1,K]
gt_max_ious = ious[gt_argmax_ious, np.arange(ious.shape[1])]
# 然后返回最大iou的索引(每个bbox与哪个anchor的iou最大),有K个
gt_argmax_ious = np.where(ious == gt_max_ious)[0]
return argmax_ious, max_ious, gt_argmax_ious
3.3 ProposalCreator¶
RPN在自身训练的时候还会提供ROIs给Faster RCNN的ROI Head作为训练样本。RPN生成ROIs的过程就是ProposalCreator,具体流程如下:
- 对于每张图片, 利用它的特征图, 计算\frac{H}{16} \times \frac{W}{16}\times 9(大约20000个)Anchor属于前景的概率以及对应的位置参数。
- 选取概率较大的12000个Anchor。
- 利用回归的位置参数修正这12000个Anchor的位置, 获得ROIs。
- 利用非极大值抑制, 选出概率最大的2000个ROIs。
注意! 在推理阶段, 为了提高处理速度, 12000和2000分别变成了6000和300。并且这部分操作不需要反向传播, 所以可以利用numpy或者tensor实现。因此,RPN的输出就是形如2000\times 4或者300\times 4的Tensor。
RPN给出了候选框, 然后ROI Head就是在候选框的基础上继续进行分类和位置参数的回归获得最后的结果,ROI Head的结构图如下所示:

代码实现在model/utils/creator_tool.py里面, 具体如下:
# 下面是ProposalCreator的代码: 这部分的操作不需要进行反向传播
# 因此可以利用numpy/tensor实现
class ProposalCreator:
# 对于每张图片, 利用它的feature map,计算(H/16)x(W/16)x9(大概20000)
# 个anchor属于前景的概率, 然后从中选取概率较大的12000张, 利用位置回归参
# 数, 修正这12000个anchor的位置, 利用非极大值抑制, 选出2000个ROIS以及
# 对应的位置参数。
def __init__(self,
parent_model,
nms_thresh=0.7,
n_train_pre_nms=12000,
n_train_post_nms=2000,
n_test_pre_nms=6000,
n_test_post_nms=300,
min_size=16
):
self.parent_model = parent_model
self.nms_thresh = nms_thresh
self.n_train_pre_nms = n_train_pre_nms
self.n_train_post_nms = n_train_post_nms
self.n_test_pre_nms = n_test_pre_nms
self.n_test_post_nms = n_test_post_nms
self.min_size = min_size
# 这里的loc和score是经过region_proposal_network中
# 经过1x1卷积分类和回归得到的。
def __call__(self, loc, score,
anchor, img_size, scale=1.):
if self.parent_model.training:
n_pre_nms = self.n_train_pre_nms #12000
n_post_nms = self.n_train_post_nms #经过NMS后有2000个
else:
n_pre_nms = self.n_test_pre_nms #6000
n_post_nms = self.n_test_post_nms #经过NMS后有300个
# 将bbox转换为近似groudtruth的anchor(即rois)
roi = loc2bbox(anchor, loc)
# slice表示切片操作
# 裁剪将rois的ymin,ymax限定在[0,H]
roi[:, slice(0, 4, 2)] = np.clip(
roi[:, slice(0, 4, 2)], 0, img_size[0])
# 裁剪将rois的xmin,xmax限定在[0,W]
roi[:, slice(1, 4, 2)] = np.clip(
roi[:, slice(1, 4, 2)], 0, img_size[1])
# Remove predicted boxes with either height or width < threshold.
min_size = self.min_size * scale #16
# rois的宽
hs = roi[:, 2] - roi[:, 0]
# rois的高
ws = roi[:, 3] - roi[:, 1]
# 确保rois的长宽大于最小阈值
keep = np.where((hs >= min_size) & (ws >= min_size))[0]
roi = roi[keep, :]
# 对剩下的ROIs进行打分(根据region_proposal_network中rois的预测前景概率)
score = score[keep]
# Sort all (proposal, score) pairs by score from highest to lowest.
# Take top pre_nms_topN (e.g. 6000).
# 将score拉伸并逆序(从高到低)排序
order = score.ravel().argsort()[::-1]
# train时从20000中取前12000个rois,test取前6000个
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
# Apply nms (e.g. threshold = 0.7).
# Take after_nms_topN (e.g. 300).
# unNOTE: somthing is wrong here!
# TODO: remove cuda.to_gpu
# #(具体需要看NMS的原理以及输入参数的作用)调用非极大值抑制函数,
# 将重复的抑制掉, 就可以将筛选后ROIS进行返回。经过NMS处理后Train
# 数据集得到2000个框,Test数据集得到300个框
keep = non_maximum_suppression(
cp.ascontiguousarray(cp.asarray(roi)),
thresh=self.nms_thresh)
if n_post_nms > 0:
keep = keep[:n_post_nms]
# 取出最终的2000或300个rois
roi = roi[keep]
return roi
3.4 ProposalTargetCreator¶
ROIs给出了2000个候选框, 分别对应了不同大小的Anchor。我们首先需要利用ProposalTargetCreator挑选出128个sample_rois, 然后使用了ROI Pooling将这些不同尺寸的区域全部Pooling到同一个尺度(7\times 7)上, 关于ROI Pooling这里就不多讲了, 具体见:实例分割算法之Mask R-CNN论文解读 。那么这里为什么要Pooling成7\times 7大小呢?
这是为了共享权重, 前面在Extrator部分说到Faster RCNN除了前面基层卷积被用到之外, 最后全连接层的权重也可以继续利用。当所有的RoIs都被Resize到512\times 512\times 7的特征图之后, 将它Reshape成一个一维的向量, 就可以利用VGG16预训练的权重初始化前两层全连接层了。最后, 再接上两个全连接层FC21用来分类(20个类+背景,VOC)和回归(21个类, 每个类有4个位置参数)。
我们再来看一下ProposalTargetCreator具体是如何选择128个ROIs进行训练的?过程如下:
- RoIs和GT box的IOU大于0.5的, 选择一些如32个。
- RoIs和gt_bboxes的IoU小于等于0(或者0.1)的选择一些(比如 128-32=96个)作为负样本。
同时为了方便训练, 对选择出的128个RoIs的gt_roi_loc进行标准化处理(减均值除以标准差)。
下面来看看代码实现, 同样是在model/utils/creator_tool.py里面:
# 下面是ProposalTargetCreator代码:ProposalCreator产生2000个ROIS,
# 但是这些ROIS并不都用于训练, 经过本ProposalTargetCreator的筛选产生
# 128个用于自身的训练
class ProposalTargetCreator(object):
def __init__(self,
n_sample=128,
pos_ratio=0.25, pos_iou_thresh=0.5,
neg_iou_thresh_hi=0.5, neg_iou_thresh_lo=0.0
):
self.n_sample = n_sample
self.pos_ratio = pos_ratio
self.pos_iou_thresh = pos_iou_thresh
self.neg_iou_thresh_hi = neg_iou_thresh_hi
self.neg_iou_thresh_lo = neg_iou_thresh_lo # NOTE:default 0.1 in py-faster-rcnn
# 输入:2000个rois、一个batch(一张图)中所有的bbox ground truth(R,4)、
# 对应bbox所包含的label(R,1)(VOC2007来说20类0-19)
# 输出:128个sample roi(128,4)、128个gt_roi_loc(128,4)、
# 128个gt_roi_label(128,1)
def __call__(self, roi, bbox, label,
loc_normalize_mean=(0., 0., 0., 0.),
loc_normalize_std=(0.1, 0.1, 0.2, 0.2)):
n_bbox, _ = bbox.shape
# 首先将2000个roi和m个bbox给concatenate了一下成为
# 新的roi(2000+m,4)。
roi = np.concatenate((roi, bbox), axis=0)
# n_sample = 128,pos_ratio=0.5,round 对传入的数据进行四舍五入
pos_roi_per_image = np.round(self.n_sample * self.pos_ratio)
# 计算每一个roi与每一个bbox的iou
iou = bbox_iou(roi, bbox)
# 按行找到最大值, 返回最大值对应的序号以及其真正的IOU。
# 返回的是每个roi与哪个bbox的最大, 以及最大的iou值
gt_assignment = iou.argmax(axis=1)
# 每个roi与对应bbox最大的iou
max_iou = iou.max(axis=1)
# 从1开始的类别序号, 给每个类得到真正的label(将0-19变为1-20)
gt_roi_label = label[gt_assignment] + 1
# 同样的根据iou的最大值将正负样本找出来,pos_iou_thresh=0.5
pos_index = np.where(max_iou >= self.pos_iou_thresh)[0]
# 需要保留的roi个数(满足大于pos_iou_thresh条件的roi与64之间较小的一个)
pos_roi_per_this_image = int(min(pos_roi_per_image, pos_index.size))
# 找出的样本数目过多就随机丢掉一些
if pos_index.size > 0:
pos_index = np.random.choice(
pos_index, size=pos_roi_per_this_image, replace=False)
# neg_iou_thresh_hi=0.5,neg_iou_thresh_lo=0.0
neg_index = np.where((max_iou < self.neg_iou_thresh_hi) &
(max_iou >= self.neg_iou_thresh_lo))[0]
neg_roi_per_this_image = self.n_sample - pos_roi_per_this_image
neg_roi_per_this_image = int(min(neg_roi_per_this_image,
neg_index.size))
if neg_index.size > 0:
neg_index = np.random.choice(
neg_index, size=neg_roi_per_this_image, replace=False)
# The indices that we're selecting (both positive and negative).
keep_index = np.append(pos_index, neg_index)
gt_roi_label = gt_roi_label[keep_index]
gt_roi_label[pos_roi_per_this_image:] = 0 # 负样本label 设为0
sample_roi = roi[keep_index]
# 此时输出的128*4的sample_roi就可以去扔到 RoIHead网络里去进行分类
# 与回归了。同样, RoIHead网络利用这sample_roi+featue为输入, 输出
# 是分类(21类)和回归(进一步微调bbox)的预测值, 那么分类回归的groud
# truth就是ProposalTargetCreator输出的gt_roi_label和gt_roi_loc。
# Compute offsets and scales to match sampled RoIs to the GTs.
# 求这128个样本的groundtruth
gt_roi_loc = bbox2loc(sample_roi, bbox[gt_assignment[keep_index]])
# ProposalTargetCreator首次用到了真实的21个类的label,
# 且该类最后对loc进行了归一化处理, 所以预测时要进行均值方差处理
gt_roi_loc = ((gt_roi_loc - np.array(loc_normalize_mean, np.float32)
) / np.array(loc_normalize_std, np.float32))
return sample_roi, gt_roi_loc, gt_roi_label
参考文献¶
4. 代码解析第三部分¶
4.1 搭建Faster RCNN网络模型¶
Faster RCNN的整体网络结构如下图所示:

注意网络结构图中的蓝色箭头的线代表了计算图, 梯度反向传播会经过。而红色的线不需要反向传播。一个有趣的事情是在Instance-aware Semantic Segmentation via Multi-task Network Cascades这篇论文(https://arxiv.org/abs/1512.04412)中提到ProposalCreator生成RoIs的过程也可以进行反向传播, 感兴趣可以去看看。
在上一节主要讲了RPN里面的AnchorTargetCreator, ProposalCreator, ProposalTargetCreator, 而RPN网络的核心类RegionProposalNetwork还没讲, 这里先看一下, 代码在model/region_proposal_network.py里面, 细节如下:
class RegionProposalNetwork(nn.Module):
def __init__(
self, in_channels=512, mid_channels=512, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32], feat_stride=16,
proposal_creator_params=dict(),
):
super(RegionProposalNetwork, self).__init__()
# 首先生成上述以(0,0)为中心的9个base anchor
self.anchor_base = generate_anchor_base(
anchor_scales=anchor_scales, ratios=ratios)
self.feat_stride = feat_stride
self.proposal_layer = ProposalCreator(self, **proposal_creator_params)
n_anchor = self.anchor_base.shape[0]
self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
self.score = nn.Conv2d(mid_channels, n_anchor * 2, 1, 1, 0)
self.loc = nn.Conv2d(mid_channels, n_anchor * 4, 1, 1, 0)
normal_init(self.conv1, 0, 0.01)
normal_init(self.score, 0, 0.01)
normal_init(self.loc, 0, 0.01)
def forward(self, x, img_size, scale=1.):
# x的尺寸为(batch_size,512,H/16,W/16), 其中H,W分别为原图的高和宽
# x为feature map,n为batch_size,此版本代码为1. hh,ww即为宽高
n, _, hh, ww = x.shape
# 在9个base_anchor基础上生成hh*ww*9个anchor,对应到原图坐标
# feat_stride=16 , 因为是经4次pool后提到的特征, 故feature map较
# 原图缩小了16倍
anchor = _enumerate_shifted_anchor(
np.array(self.anchor_base),/
self.feat_stride, hh, ww)
# (hh * ww * 9)/hh*ww = 9
n_anchor = anchor.shape[0] // (hh * ww)
# 512个3x3卷积(512, H/16,W/16)
h = F.relu(self.conv1(x))
# n_anchor(9)* 4个1x1卷积, 回归坐标偏移量。(9*4,hh,ww)
rpn_locs = self.loc(h)
# UNNOTE: check whether need contiguous
# A: Yes
# 转换为(n,hh,ww,9*4)后变为(n,hh*ww*9,4)
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
# n_anchor(9)*2个1x1卷积, 回归类别。(9*2,hh,ww)
rpn_scores = self.score(h)
# 转换为(n,hh,ww,9*2)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous()
# 计算{Softmax}(x_{i}) = \{exp(x_i)}{\sum_j exp(x_j)}
rpn_softmax_scores = F.softmax(rpn_scores.view(n, hh, ww, n_anchor, 2), dim=4)
# 得到前景的分类概率
rpn_fg_scores = rpn_softmax_scores[:, :, :, :, 1].contiguous()
# 得到所有anchor的前景分类概率
rpn_fg_scores = rpn_fg_scores.view(n, -1)
# 得到每一张feature map上所有anchor的网络输出值
rpn_scores = rpn_scores.view(n, -1, 2)
rois = list()
roi_indices = list()
# n为batch_size数
for i in range(n):
# 调用ProposalCreator函数, rpn_locs维度(hh*ww*9,4)
# ,rpn_fg_scores维度为(hh*ww*9),anchor的维度为
# (hh*ww*9,4), img_size的维度为(3,H,W),H和W是
# 经过数据预处理后的。计算(H/16)x(W/16)x9(大概20000)
# 个anchor属于前景的概率, 取前12000个并经过NMS得到2000个
# 近似目标框G^的坐标。roi的维度为(2000,4)
roi = self.proposal_layer(
rpn_locs[i].cpu().data.numpy(),
rpn_fg_scores[i].cpu().data.numpy(),
anchor, img_size,
scale=scale)
batch_index = i * np.ones((len(roi),), dtype=np.int32)
# rois为所有batch_size的roi
rois.append(roi)
roi_indices.append(batch_index)
# 按行拼接(即没有batch_size的区分, 每一个[]里都是一个anchor的四个坐标)
rois = np.concatenate(rois, axis=0)
# 这个 roi_indices在此代码中是多余的, 因为我们实现的是batch_siae=1的
# 网络, 一个batch只会输入一张图象。如果多张图像的话就需要存储索引以找到
# 对应图像的roi
roi_indices = np.concatenate(roi_indices, axis=0)
# rpn_locs的维度(hh*ww*9,4),rpn_scores维度为(hh*ww*9,2),
# rois的维度为(2000,4),roi_indices用不到,
# anchor的维度为(hh*ww*9,4)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
可以看到RegionProposalNetwork继承于nn.Module,这个网络我们在上一个推文讲的很细节了, 在继续阅读之前, 请确保你已经理解了RPN和ROI Head。
接下来, 我们需要知道在model/roi_module.py里面主要利用了cupy(专用于GPU的numpy)实现ROI Pooling的前向传播和反向传播。NMS和ROI pooling利用了:cupy和chainer 。
其主要任务是对于一张图像得到的特征图(512\times \frac{w}{16}\times \frac{h}{16}), 然后利用sample_roi的bbox坐标去在特征图上裁剪下来所有roi对应的特征图(训练:128\times 512\times \frac{w}{16}\times \frac{h}{16})、(测试:300\times 512\times \frac{w}{16}\times \frac{h}{16})。
接下来就是搭建网络模型的文件model/faster_rcnn.py, 这个脚本定义了Faster RCNN的基本类FasterRCNN。我们知道Faster RCNN的三个核心步骤就是:
- 特征提取:输入一张图片得到其特征图feature map
- RPN:给定特征图后产生一系列RoIs
- ROI Head:利用这些RoIs对应的特征图对这些RoIs中的类别进行分类, 并提升定位精度
在FasterRCNN这个类中就初始化了这三个重要的步骤, 即self.extrator, self.rpn, self.head。
FasterRCNN类中, forward函数实现前向传播, 代码如下:
def forward(self, x, scale=1.):
# 实现前向传播
img_size = x.shape[2:]
h = self.extractor(x)
rpn_locs, rpn_scores, rois, roi_indices, anchor = \
self.rpn(h, img_size, scale)
roi_cls_locs, roi_scores = self.head(
h, rois, roi_indices)
return roi_cls_locs, roi_scores, rois, roi_indices
也可以用下图来更清晰的表示:

而这个forward过程中边界框的数量变化可以表示为下图:

接下来我们看一下预测函数predict, 这个函数实现了对测试集图片的预测, 同样batch=1, 即每次输入一张图片。详解如下:
def predict(self, imgs,sizes=None,visualize=False):
# 设置为eval模式
self.eval()
# 是否开启可视化
if visualize:
self.use_preset('visualize')
prepared_imgs = list()
sizes = list()
for img in imgs:
size = img.shape[1:]
img = preprocess(at.tonumpy(img))
prepared_imgs.append(img)
sizes.append(size)
else:
prepared_imgs = imgs
bboxes = list()
labels = list()
scores = list()
for img, size in zip(prepared_imgs, sizes):
img = at.totensor(img[None]).float()
# 对读入的图片求尺度scale,因为输入的图像经预处理就会有缩放,
# 所以需记录缩放因子scale,这个缩放因子在ProposalCreator
# 筛选roi时有用到, 即将所有候选框按这个缩放因子映射回原图,
# 超出原图边框的趋于将被截断。
scale = img.shape[3] / size[1]
# 执行forward
roi_cls_loc, roi_scores, rois, _ = self(img, scale=scale)
# We are assuming that batch size is 1.
roi_score = roi_scores.data
roi_cls_loc = roi_cls_loc.data
roi = at.totensor(rois) / scale
# Convert predictions to bounding boxes in image coordinates.
# Bounding boxes are scaled to the scale of the input images.
# 为ProposalCreator对loc做了归一化(-mean /std)处理, 所以这里
# 需要再*std+mean,此时的位置参数loc为roi_cls_loc。然后将这128
# 个roi利用roi_cls_loc进行微调, 得到新的cls_bbox。
mean = t.Tensor(self.loc_normalize_mean).cuda(). \
repeat(self.n_class)[None]
std = t.Tensor(self.loc_normalize_std).cuda(). \
repeat(self.n_class)[None]
roi_cls_loc = (roi_cls_loc * std + mean)
roi_cls_loc = roi_cls_loc.view(-1, self.n_class, 4)
roi = roi.view(-1, 1, 4).expand_as(roi_cls_loc)
cls_bbox = loc2bbox(at.tonumpy(roi).reshape((-1, 4)),
at.tonumpy(roi_cls_loc).reshape((-1, 4)))
cls_bbox = at.totensor(cls_bbox)
cls_bbox = cls_bbox.view(-1, self.n_class * 4)
# clip bounding box
cls_bbox[:, 0::2] = (cls_bbox[:, 0::2]).clamp(min=0, max=size[0])
cls_bbox[:, 1::2] = (cls_bbox[:, 1::2]).clamp(min=0, max=size[1])
# 对于分类得分roi_scores,我们需要将其经过softmax后转为概率prob。
# 值得注意的是我们此时得到的是对所有输入128个roi以及位置参数、得分
# 的预处理, 下面将筛选出最后最终的预测结果。
prob = at.tonumpy(F.softmax(at.totensor(roi_score), dim=1))
raw_cls_bbox = at.tonumpy(cls_bbox)
raw_prob = at.tonumpy(prob)
bbox, label, score = self._suppress(raw_cls_bbox, raw_prob)
bboxes.append(bbox)
labels.append(label)
scores.append(score)
self.use_preset('evaluate')
self.train()
return bboxes, labels, scores
注意! 训练完train_datasets之后, model要来测试样本了。在model(test_datasets)之前, 需要加上model.eval()。否则的话, 有输入数据, 即使不训练, 它也会改变权值。这是model中含有batch normalization层所带来的的性质。
所以我们看到在第一行使用了self.eval(), 那么为什么在最后一行函数返回bboxes, labels, scores之后还要加一行self.train呢?这是因为这次预测之后下次要接着训练, 训练的时候需要设置模型类型为train。

上面的步骤是对网络RoIhead网络输出的预处理, 函数_suppress将得到真正的预测结果。_suppress函数解释如下:
# predict函数是对网络RoIhead网络输出的预处理
# 函数_suppress将得到真正的预测结果。
# 此函数是一个按类别的循环,l从1至20(0类为背景类)。
# 即预测思想是按20个类别顺序依次验证, 如果有满足该类的预测结果,
# 则记录, 否则转入下一类(一张图中也就几个类别而已)。例如筛选
# 预测出第1类的结果, 首先在cls_bbox中将所有128个预测第1类的
# bbox坐标找出, 然后从prob中找出128个第1类的概率。因为阈值为0.7,
# 也即概率>0.7的所有边框初步被判定预测正确, 记录下来。然而可能有
# 多个边框预测第1类中同一个物体, 同类中一个物体只需一个边框,
# 所以需再经基于类的NMS后使得每类每个物体只有一个边框, 至此
# 第1类预测完成, 记录第1类的所有边框坐标、标签、置信度。
# 接着下一类..., 直至20类都记录下来, 那么一张图片(也即一个batch)
# 的预测也就结束了。
def _suppress(self, raw_cls_bbox, raw_prob):
bbox = list()
label = list()
score = list()
# skip cls_id = 0 because it is the background class
for l in range(1, self.n_class):
cls_bbox_l = raw_cls_bbox.reshape((-1, self.n_class, 4))[:, l, :]
prob_l = raw_prob[:, l]
mask = prob_l > self.score_thresh
cls_bbox_l = cls_bbox_l[mask]
prob_l = prob_l[mask]
keep = non_maximum_suppression(
cp.array(cls_bbox_l), self.nms_thresh, prob_l)
keep = cp.asnumpy(keep)
bbox.append(cls_bbox_l[keep])
# The labels are in [0, self.n_class - 2].
label.append((l - 1) * np.ones((len(keep),)))
score.append(prob_l[keep])
bbox = np.concatenate(bbox, axis=0).astype(np.float32)
label = np.concatenate(label, axis=0).astype(np.int32)
score = np.concatenate(score, axis=0).astype(np.float32)
return bbox, label, score
这里还定义了优化器optimizer,对于需要求导的参数 按照是否含bias赋予不同的学习率。默认是使用SGD,可选Adam,不过需更小的学习率。代码如下:
# 定义了优化器optimizer,对于需要求导的参数 按照是否含bias赋予不同的学习率。
# 默认是使用SGD,可选Adam,不过需更小的学习率。
def get_optimizer(self):
"""
return optimizer, It could be overwriten if you want to specify
special optimizer
"""
lr = opt.lr
params = []
for key, value in dict(self.named_parameters()).items():
if value.requires_grad:
if 'bias' in key:
params += [{'params': [value], 'lr': lr * 2, 'weight_decay': 0}]
else:
params += [{'params': [value], 'lr': lr, 'weight_decay': opt.weight_decay}]
if opt.use_adam:
self.optimizer = t.optim.Adam(params)
else:
self.optimizer = t.optim.SGD(params, momentum=0.9)
return self.optimizer
def scale_lr(self, decay=0.1):
for param_group in self.optimizer.param_groups:
param_group['lr'] *= decay
return self.optimizer
解释完了这个基类, 我们来看看这份代码里面实现的基于VGG16的Faster RCNN的这个类FasterRCNNVGG16, 它继承了FasterRCNN。
首先引入VGG16,然后拆分为特征提取网络和分类网络。冻结分类网络的前几层, 不进行反向传播。
然后实现VGG16RoIHead网络。实现输入特征图、rois、roi_indices,输出roi_cls_locs和roi_scores。
类FasterRCNNVGG16分别对VGG16的特征提取部分、分类部分、RPN网络、VGG16RoIHead网络进行了实例化。
此外在对VGG16RoIHead网络的全连接层权重初始化过程中, 按照图像是否为truncated(截断)分了两种初始化分方法, 至于这个截断具体有什么用呢, 也不是很明白这里似乎也没用。
详细解释如下:
def decom_vgg16():
# the 30th layer of features is relu of conv5_3
# 是否使用Caffe下载下来的预训练模型
if opt.caffe_pretrain:
model = vgg16(pretrained=False)
if not opt.load_path:
# 加载参数信息
model.load_state_dict(t.load(opt.caffe_pretrain_path))
else:
model = vgg16(not opt.load_path)
# 加载预训练模型vgg16的conv5_3之前的部分
features = list(model.features)[:30]
classifier = model.classifier
# 分类部分放到一个list里面
classifier = list(classifier)
# 删除输出分类结果层
del classifier[6]
# 删除两个dropout
if not opt.use_drop:
del classifier[5]
del classifier[2]
classifier = nn.Sequential(*classifier)
# 冻结vgg16前2个stage,不进行反向传播
for layer in features[:10]:
for p in layer.parameters():
p.requires_grad = False
# 拆分为特征提取网络和分类网络
return nn.Sequential(*features), classifier
# 分别对特征VGG16的特征提取部分、分类部分、RPN网络、
# VGG16RoIHead网络进行了实例化
class FasterRCNNVGG16(FasterRCNN):
# vgg16通过5个stage下采样16倍
feat_stride = 16 # downsample 16x for output of conv5 in vgg16
# 总类别数为20类, 三种尺度三种比例的anchor
def __init__(self,
n_fg_class=20,
ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]
):
# conv5_3及之前的部分, 分类器
extractor, classifier = decom_vgg16()
# 返回rpn_locs, rpn_scores, rois, roi_indices, anchor
rpn = RegionProposalNetwork(
512, 512,
ratios=ratios,
anchor_scales=anchor_scales,
feat_stride=self.feat_stride,
)
# 下面讲
head = VGG16RoIHead(
n_class=n_fg_class + 1,
roi_size=7,
spatial_scale=(1. / self.feat_stride),
classifier=classifier
)
super(FasterRCNNVGG16, self).__init__(
extractor,
rpn,
head,
)
class VGG16RoIHead(nn.Module):
def __init__(self, n_class, roi_size, spatial_scale,
classifier):
# n_class includes the background
super(VGG16RoIHead, self).__init__()
# vgg16中的最后两个全连接层
self.classifier = classifier
self.cls_loc = nn.Linear(4096, n_class * 4)
self.score = nn.Linear(4096, n_class)
# 全连接层权重初始化
normal_init(self.cls_loc, 0, 0.001)
normal_init(self.score, 0, 0.01)
# 加上背景21类
self.n_class = n_class
# 7x7
self.roi_size = roi_size
# 1/16
self.spatial_scale = spatial_scale
# 将大小不同的roi变成大小一致, 得到pooling后的特征,
# 大小为[300, 512, 7, 7]。利用Cupy实现在线编译的
self.roi = RoIPooling2D(self.roi_size, self.roi_size, self.spatial_scale)
def forward(self, x, rois, roi_indices):
# 前面解释过这里的roi_indices其实是多余的, 因为batch_size一直为1
# in case roi_indices is ndarray
roi_indices = at.totensor(roi_indices).float() #ndarray->tensor
rois = at.totensor(rois).float()
indices_and_rois = t.cat([roi_indices[:, None], rois], dim=1)
# NOTE: important: yx->xy
xy_indices_and_rois = indices_and_rois[:, [0, 2, 1, 4, 3]]
# 把tensor变成在内存中连续分布的形式
indices_and_rois = xy_indices_and_rois.contiguous()
# 接下来分析roi_module.py中的RoI()
pool = self.roi(x, indices_and_rois)
# flat操作
pool = pool.view(pool.size(0), -1)
# decom_vgg16()得到的calssifier,得到4096
fc7 = self.classifier(pool)
# (4096->84)
roi_cls_locs = self.cls_loc(fc7)
# (4096->21)
roi_scores = self.score(fc7)
return roi_cls_locs, roi_scores
def normal_init(m, mean, stddev, truncated=False):
"""
weight initalizer: truncated normal and random normal.
"""
# x is a parameter
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
4.2 总结¶
到这里呢我们就讲完了怎么搭建一个完整的Faster RCNN,下一节我准备讲一下训练相关的一些细节什么的, 就结束本专栏, 希望这份解释可以对你有帮助。有问题请在评论区留言讨论。
参考文献¶
- https://www.cnblogs.com/king-lps/p/8992311.html
- https://zhuanlan.zhihu.com/p/32404424
- https://blog.csdn.net/qq_32678471/article/details/84882277
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享, 坚持原创, 每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
5. 代码解析第五部分¶
5.1 回顾¶
首先从三年一梦这个博主的博客里面看到了一张对Faster RCNN全过程总结的图, 地址为:https://www.cnblogs.com/king-lps/p/8995412.html 。它是针对Chainner实现的一个Faster RCNN工程所做的流程图, 但我研究了一下过程和本文介绍的陈云大佬的代码流程完全一致, 所以在这里贴一下这张图, 再熟悉一下Faster RCNN的整体流程。
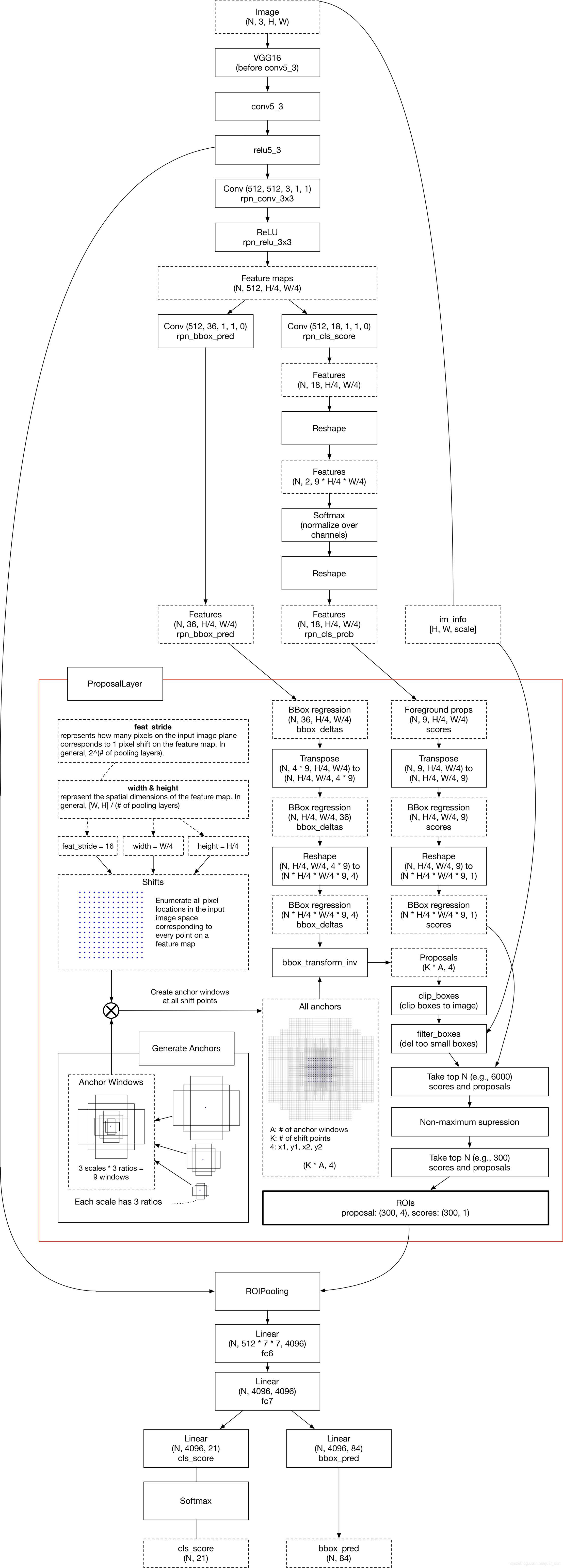
这张图把整个Faster RCNN的流程都解释的比较清楚, 注意一下图中出现的Conv(512,512,3,1,1)类似的语句里面的最后一个参数表示padding。
5.2 代码解析¶
这一节我们主要是对train.py和trainer.py的代码进行解析, 我们首先来看trainer.py, 这个脚本定义了类FasterRCNNTrainer , 在初始化的时候用到了之前定义的类FasterRCNNVGG16 为faster_rcnn。 此外在初始化中有引入了其他creator、vis、optimizer等。
另外, 还定义了四个损失函数以及一个总的联合损失函数:rpn_loc_loss、rpn_cls_loss、roi_loc_loss、roi_cls_loss,total_loss。
首先来看一下FasterRCNNTrainer类的初始化函数:
class FasterRCNNTrainer(nn.Module):
def __init__(self, faster_rcnn):
# 继承父模块的初始化
super(FasterRCNNTrainer, self).__init__()
self.faster_rcnn = faster_rcnn
# 下面2个参数是在_faster_rcnn_loc_loss调用用来计算位置损失函数用到的超参数
self.rpn_sigma = opt.rpn_sigma
self.roi_sigma = opt.roi_sigma
# target creator create gt_bbox gt_label etc as training targets.
# 用于从20000个候选anchor中产生256个anchor进行二分类和位置回归, 也就是
# 为rpn网络产生的预测位置和预测类别提供真正的ground_truth标准
self.anchor_target_creator = AnchorTargetCreator()
# AnchorTargetCreator和ProposalTargetCreator是为了生成训练的目标
# (或称ground truth), 只在训练阶段用到,ProposalCreator是RPN为Fast
# R-CNN生成RoIs,在训练和测试阶段都会用到。所以测试阶段直接输进来300
# 个RoIs,而训练阶段会有AnchorTargetCreator的再次干预
self.proposal_target_creator = ProposalTargetCreator()
# (0., 0., 0., 0.)
self.loc_normalize_mean = faster_rcnn.loc_normalize_mean
# (0.1, 0.1, 0.2, 0.2)
self.loc_normalize_std = faster_rcnn.loc_normalize_std
# SGD
self.optimizer = self.faster_rcnn.get_optimizer()
# 可视化,vis_tool.py
self.vis = Visualizer(env=opt.env)
# 混淆矩阵, 就是验证预测值与真实值精确度的矩阵ConfusionMeter
# (2)括号里的参数指的是类别数
self.rpn_cm = ConfusionMeter(2)
# roi的类别有21种(20个object类+1个background)
self.roi_cm = ConfusionMeter(21)
# 平均损失
self.meters = {k: AverageValueMeter() for k in LossTuple._fields} # average loss
接下来是Forward函数, 因为只支持batch_size等于1的训练, 因此n=1。每个batch输入一张图片, 一张图片上所有的bbox及label,以及图片经过预处理后的scale。
然后对于两个分类损失(RPN和ROI Head)都使用了交叉熵损失, 而回归损失则使用了smooth_l1_loss。
还需要注意的一点是例如ROI回归输出的是128\times 84, 然而真实位置参数是128\times 4和真实标签128\times 1, 我们需要利用真实标签将回归输出索引为128\times 4, 然后在计算过程中只计算前景类的回归损失。具体实现与Fast-RCNN略有不同(\sigma设置不同)。
代码解析如下:
def forward(self, imgs, bboxes, labels, scale):
# 获取batch个数
n = bboxes.shape[0]
if n != 1:
raise ValueError('Currently only batch size 1 is supported.')
_, _, H, W = imgs.shape
# (n,c,hh,ww)
img_size = (H, W)
# vgg16 conv5_3之前的部分提取图片的特征
features = self.faster_rcnn.extractor(imgs)
# rpn_locs的维度(hh*ww*9,4),rpn_scores维度为(hh*ww*9,2),
# rois的维度为(2000,4),roi_indices用不到,anchor的维度为
# (hh*ww*9,4),H和W是经过数据预处理后的。计算(H/16)x(W/16)x9
# (大概20000)个anchor属于前景的概率, 取前12000个并经过NMS得到2000个
# 近似目标框G^的坐标。roi的维度为(2000,4)
rpn_locs, rpn_scores, rois, roi_indices, anchor = \
self.faster_rcnn.rpn(features, img_size, scale)
# Since batch size is one, convert variables to singular form
# bbox维度(N, R, 4)
bbox = bboxes[0]
# labels维度为(N,R)
label = labels[0]
#hh*ww*9
rpn_score = rpn_scores[0]
# hh*ww*9
rpn_loc = rpn_locs[0]
# (2000,4)
roi = rois
# Sample RoIs and forward
# 调用proposal_target_creator函数生成sample roi(128,4)、
# gt_roi_loc(128,4)、gt_roi_label(128,1),RoIHead网络
# 利用这sample_roi+featue为输入, 输出是分类(21类)和回归
# (进一步微调bbox)的预测值, 那么分类回归的groud truth就
# 是ProposalTargetCreator输出的gt_roi_label和gt_roi_loc。
sample_roi, gt_roi_loc, gt_roi_label = self.proposal_target_creator(
roi,
at.tonumpy(bbox),
at.tonumpy(label),
self.loc_normalize_mean,
self.loc_normalize_std)
# NOTE it's all zero because now it only support for batch=1 now
sample_roi_index = t.zeros(len(sample_roi))
# roi回归输出的是128*84和128*21,然而真实位置参数是128*4和真实标签128*1
roi_cls_loc, roi_score = self.faster_rcnn.head(
features,
sample_roi,
sample_roi_index)
# ------------------ RPN losses -------------------#
# 输入20000个anchor和bbox,调用anchor_target_creator函数得到
# 2000个anchor与bbox的偏移量与label
gt_rpn_loc, gt_rpn_label = self.anchor_target_creator(
at.tonumpy(bbox),
anchor,
img_size)
gt_rpn_label = at.totensor(gt_rpn_label).long()
gt_rpn_loc = at.totensor(gt_rpn_loc)
# 下面分析_fast_rcnn_loc_loss函数。rpn_loc为rpn网络回归出来的偏移量
# (20000个),gt_rpn_loc为anchor_target_creator函数得到2000个anchor
# 与bbox的偏移量,rpn_sigma=1.
rpn_loc_loss = _fast_rcnn_loc_loss(
rpn_loc,
gt_rpn_loc,
gt_rpn_label.data,
self.rpn_sigma)
# NOTE: default value of ignore_index is -100 ...
# rpn_score为rpn网络得到的(20000个)与anchor_target_creator
# 得到的2000个label求交叉熵损失
rpn_cls_loss = F.cross_entropy(rpn_score, gt_rpn_label.cuda(), ignore_index=-1)
_gt_rpn_label = gt_rpn_label[gt_rpn_label > -1] #不计算背景类
_rpn_score = at.tonumpy(rpn_score)[at.tonumpy(gt_rpn_label) > -1]
self.rpn_cm.add(at.totensor(_rpn_score, False), _gt_rpn_label.data.long())
# ------------------ ROI losses (fast rcnn loss) -------------------#
# roi_cls_loc为VGG16RoIHead的输出(128*84), n_sample=128
n_sample = roi_cls_loc.shape[0]
# roi_cls_loc=(128,21,4)
roi_cls_loc = roi_cls_loc.view(n_sample, -1, 4)
roi_loc = roi_cls_loc[t.arange(0, n_sample).long().cuda(), \
at.totensor(gt_roi_label).long()]
# proposal_target_creator()生成的128个proposal与bbox求得的偏移量
# dx,dy,dw,dh
gt_roi_label = at.totensor(gt_roi_label).long()
# 128个标签
gt_roi_loc = at.totensor(gt_roi_loc)
# 采用smooth_l1_loss
roi_loc_loss = _fast_rcnn_loc_loss(
roi_loc.contiguous(),
gt_roi_loc,
gt_roi_label.data,
self.roi_sigma)
# 求交叉熵损失
roi_cls_loss = nn.CrossEntropyLoss()(roi_score, gt_roi_label.cuda())
self.roi_cm.add(at.totensor(roi_score, False), gt_roi_label.data.long())
# 四个loss加起来
losses = [rpn_loc_loss, rpn_cls_loss, roi_loc_loss, roi_cls_loss]
losses = losses + [sum(losses)]
return LossTuple(*losses)
下面我们来解析一下代码中的_fast_rcnn_loc_loss函数, 它用到了smooth_l1_loss。其中in_weight代表权重, 只将那些不是背景的Anchor/ROIs的位置放入到损失函数的计算中来, 方法就是只给不是背景的Anchor/ROIs的in_weight设置为1,这样就可以完成loc_loss的求和计算。
代码解析如下:
# 输入分别为rpn回归框的偏移量和anchor与bbox的偏移量以及label
def _fast_rcnn_loc_loss(pred_loc, gt_loc, gt_label, sigma):
in_weight = t.zeros(gt_loc.shape).cuda()
# Localization loss is calculated only for positive rois.
# NOTE: unlike origin implementation,
# we don't need inside_weight and outside_weight, they can calculate by gt_label
in_weight[(gt_label > 0).view(-1, 1).expand_as(in_weight).cuda()] = 1
# sigma设置为1
loc_loss = _smooth_l1_loss(pred_loc, gt_loc, in_weight.detach(), sigma)
# Normalize by total number of negtive and positive rois.
# 除去背景类
loc_loss /= ((gt_label >= 0).sum().float()) # ignore gt_label==-1 for rpn_loss
return loc_loss
接下来就是train_step函数, 整个函数实际上就是进行了一次参数的优化过程, 首先self.optimizer.zero_grad()将梯度数据全部清零, 然后利用刚刚介绍self.forward(imgs,bboxes,labels,scales)函数将所有的损失计算出来, 接着依次进行losses.total_loss.backward()反向传播计算梯度, self.optimizer.step()进行一次参数更新过程, self.update_meters(losses)就是将所有损失的数据更新到可视化界面上,最后将losses返回。代码如下:
def train_step(self, imgs, bboxes, labels, scale):
self.optimizer.zero_grad()
losses = self.forward(imgs, bboxes, labels, scale)
losses.total_loss.backward()
self.optimizer.step()
self.update_meters(losses)
return losses
接下来还有一些函数比如save(), load(), update_meters(), reset_meters(), get_meter_data()等。其中save()和load()就是根据输入参数来选择保存和解析model模型或者config设置或者other_info其他vis_info可视化参数等等, 代码如下:
# 模型保存
def save(self, save_optimizer=False, save_path=None, **kwargs):
save_dict = dict()
save_dict['model'] = self.faster_rcnn.state_dict()
save_dict['config'] = opt._state_dict()
save_dict['other_info'] = kwargs
save_dict['vis_info'] = self.vis.state_dict()
if save_optimizer:
save_dict['optimizer'] = self.optimizer.state_dict()
if save_path is None:
timestr = time.strftime('%m%d%H%M')
save_path = 'checkpoints/fasterrcnn_%s' % timestr
for k_, v_ in kwargs.items():
save_path += '_%s' % v_
save_dir = os.path.dirname(save_path)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
t.save(save_dict, save_path)
self.vis.save([self.vis.env])
return save_path
# 模型加载
def load(self, path, load_optimizer=True, parse_opt=False, ):
state_dict = t.load(path)
if 'model' in state_dict:
self.faster_rcnn.load_state_dict(state_dict['model'])
else: # legacy way, for backward compatibility
self.faster_rcnn.load_state_dict(state_dict)
return self
if parse_opt:
opt._parse(state_dict['config'])
if 'optimizer' in state_dict and load_optimizer:
self.optimizer.load_state_dict(state_dict['optimizer'])
return self
而update_meters,reset_meters以及get_meter_data()就是负责将数据向可视化界面更新传输获取以及重置的函数。
OK,trainer.py大概就解析到这里, 接下来我们来看看train.py, 详细解释如下:
def train(**kwargs):
# opt._parse(kwargs)#将调用函数时候附加的参数用,
# config.py文件里面的opt._parse()进行解释, 然后
# 获取其数据存储的路径, 之后放到Dataset里面!
opt._parse(kwargs)
dataset = Dataset(opt)
print('load data')
# #Dataset完成的任务见第二次推文数据预处理部分,
# 这里简单解释一下, 就是用VOCBboxDataset作为数据
# 集, 然后依次从样例数据库中读取图片出来, 还调用了
# Transform(object)函数, 完成图像的调整和随机翻转工作
dataloader = data_.DataLoader(dataset, \
batch_size=1, \
shuffle=True, \
# pin_memory=True,
num_workers=opt.num_workers)
testset = TestDataset(opt)
# 将数据装载到dataloader中,shuffle=True允许数据打乱排序,
# num_workers是设置数据分为几批处理, 同样的将测试数据集也
# 进行同样的处理, 然后装载到test_dataloader中
test_dataloader = data_.DataLoader(testset,
batch_size=1,
num_workers=opt.test_num_workers,
shuffle=False, \
pin_memory=True
)
# 定义faster_rcnn=FasterRCNNVGG16()训练模型
faster_rcnn = FasterRCNNVGG16()
print('model construct completed')
# 设置trainer = FasterRCNNTrainer(faster_rcnn).cuda()将
# FasterRCNNVGG16作为fasterrcnn的模型送入到FasterRCNNTrainer
# 中并设置好GPU加速
trainer = FasterRCNNTrainer(faster_rcnn).cuda()
if opt.load_path:
trainer.load(opt.load_path)
print('load pretrained model from %s' % opt.load_path)
trainer.vis.text(dataset.db.label_names, win='labels')
best_map = 0
lr_ = opt.lr
# 用一个for循环开始训练过程, 而训练迭代的次数
# opt.epoch=14也在config.py文件中预先定义好, 属于超参数
for epoch in range(opt.epoch):
# 首先在可视化界面重设所有数据
trainer.reset_meters()
for ii, (img, bbox_, label_, scale) in tqdm(enumerate(dataloader)):
scale = at.scalar(scale)
# 然后从训练数据中枚举dataloader,设置好缩放范围,
# 将img,bbox,label,scale全部设置为可gpu加速
img, bbox, label = img.cuda().float(), bbox_.cuda(), label_.cuda()
# 调用trainer.py中的函数trainer.train_step
# (img,bbox,label,scale)进行一次参数迭代优化过程
trainer.train_step(img, bbox, label, scale)
# 判断数据读取次数是否能够整除plot_every
# (是否达到了画图次数), 如果达到判断debug_file是否存在,
# 用ipdb工具设置断点, 调用trainer中的trainer.vis.
# plot_many(trainer.get_meter_data())将训练数据读取并
# 上传完成可视化
if (ii + 1) % opt.plot_every == 0:
if os.path.exists(opt.debug_file):
ipdb.set_trace()
# plot loss
trainer.vis.plot_many(trainer.get_meter_data())
# plot groud truth bboxes
ori_img_ = inverse_normalize(at.tonumpy(img[0]))
gt_img = visdom_bbox(ori_img_,
at.tonumpy(bbox_[0]),
at.tonumpy(label_[0]))
# 将每次迭代读取的图片用dataset文件里面的inverse_normalize()
# 函数进行预处理, 将处理后的图片调用Visdom_bbox可视化
trainer.vis.img('gt_img', gt_img)
# plot predicti bboxes
# 调用faster_rcnn的predict函数进行预测,
# 预测的结果保留在以_下划线开头的对象里面
_bboxes, _labels, _scores = trainer.faster_rcnn.predict([ori_img_], visualize=True)
pred_img = visdom_bbox(ori_img_,
at.tonumpy(_bboxes[0]),
at.tonumpy(_labels[0]).reshape(-1),
at.tonumpy(_scores[0]))
# 利用同样的方法将原始图片以及边框类别的
# 预测结果同样在可视化工具中显示出来
trainer.vis.img('pred_img', pred_img)
# rpn confusion matrix(meter)
# 调用trainer.vis.text将rpn_cm也就是
# RPN网络的混淆矩阵在可视化工具中显示出来
trainer.vis.text(str(trainer.rpn_cm.value().tolist()), win='rpn_cm')
# roi confusion matrix
# 可视化ROI head的混淆矩阵
trainer.vis.img('roi_cm', at.totensor(trainer.roi_cm.conf, False).float())
# 调用eval函数计算map等指标
eval_result = eval(test_dataloader, faster_rcnn, test_num=opt.test_num)
# 可视化map
trainer.vis.plot('test_map', eval_result['map'])
# 设置学习的learning rate
lr_ = trainer.faster_rcnn.optimizer.param_groups[0]['lr']
log_info = 'lr:{}, map:{},loss:{}'.format(str(lr_),
str(eval_result['map']),
str(trainer.get_meter_data()))
# 将损失学习率以及map等信息及时显示更新
trainer.vis.log(log_info)
# 用if判断语句永远保存效果最好的map
if eval_result['map'] > best_map:
best_map = eval_result['map']
best_path = trainer.save(best_map=best_map)
if epoch == 9:
# if判断语句如果学习的epoch达到了9就将学习率*0.1
# 变成原来的十分之一
trainer.load(best_path)
trainer.faster_rcnn.scale_lr(opt.lr_decay)
lr_ = lr_ * opt.lr_decay
# 判断epoch==13结束训练验证过程
if epoch == 13:
break
在train.py里面还有一个函数为eval(), 具体解释如下:
def eval(dataloader, faster_rcnn, test_num=10000):
# 预测框的位置, 预测框的类别和分数
pred_bboxes, pred_labels, pred_scores = list(), list(), list()
# 真实框的位置, 类别, 是否为明显目标
gt_bboxes, gt_labels, gt_difficults = list(), list(), list()
# 一个for循环, 从 enumerate(dataloader)里面依次读取数据,
# 读取的内容是: imgs图片,sizes尺寸,gt_boxes真实框的位置
# gt_labels真实框的类别以及gt_difficults
for ii, (imgs, sizes, gt_bboxes_, gt_labels_, gt_difficults_) in tqdm(enumerate(dataloader)):
sizes = [sizes[0][0].item(), sizes[1][0].item()]
# 用faster_rcnn.predict(imgs,[sizes]) 得出预测的pred_boxes_,
# pred_labels_,pred_scores_预测框位置, 预测框标记以及预测框
# 的分数等等
pred_bboxes_, pred_labels_, pred_scores_ = faster_rcnn.predict(imgs, [sizes])
gt_bboxes += list(gt_bboxes_.numpy())
gt_labels += list(gt_labels_.numpy())
gt_difficults += list(gt_difficults_.numpy())
pred_bboxes += pred_bboxes_
pred_labels += pred_labels_
pred_scores += pred_scores_
if ii == test_num: break
# 将pred_bbox,pred_label,pred_score ,gt_bbox,gt_label,gt_difficult
# 预测和真实的值全部依次添加到开始定义好的列表里面去, 如果迭代次数等于测
# 试test_num,那么就跳出循环!调用 eval_detection_voc函数, 接收上述的
# 六个列表参数, 完成预测水平的评估!得到预测的结果
result = eval_detection_voc(
pred_bboxes, pred_labels, pred_scores,
gt_bboxes, gt_labels, gt_difficults,
use_07_metric=True)
return result
关于如何计算map我就不再赘述了, 感兴趣可以去看我这篇推文, 自认为写的是很清楚的, 也有源码解释:目标检测算法之常见评价指标(mAP)的详细计算方法及代码解析 。
参考文献¶
- https://blog.csdn.net/qq_32678471/article/details/85678921
- https://www.cnblogs.com/king-lps/p/8995412.html
6. 目标检测算法之评价指标¶
6.1 评价指标¶
1.准确率(Accuracy)¶
检测时分对的样本数除以所有的样本数。准确率一般被用来评估检测模型的全局准确程度, 包含的信息有限, 不能完全评价一个模型性能。
2.混淆矩阵(Confusion Matrix)¶
混淆矩阵是以模型预测的类别数量统计信息为横轴, 真实标签的数量统计信息为纵轴画出的矩阵。对角线代表了模型预测和数据标签一致的数目, 所以准确率也可以用混淆矩阵对角线之和除以测试集图片数量来计算。对角线上的数字越大越好, 在混淆矩阵可视化结果中颜色越深, 代表模型在该类的预测结果更好。其他地方自然是预测错误的地方, 自然值越小, 颜色越浅说明模型预测的更好。
3.精确率(Precision)和召回率(Recall)和PR曲线¶
一个经典例子是存在一个测试集合, 测试集合只有大雁和飞机两种图片组成, 假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片, 而不是大雁的图片。然后就可以定义: - True positives: 简称为TP,即正样本被正确识别为正样本, 飞机的图片被正确的识别成了飞机。 - True negatives: 简称为TN,即负样本被正确识别为负样本, 大雁的图片没有被识别出来, 系统正确地认为它们是大雁。 - False Positives: 简称为FP,即负样本被错误识别为正样本, 大雁的图片被错误地识别成了飞机。 - False negatives: 简称为FN,即正样本被错误识别为负样本, 飞机的图片没有被识别出来, 系统错误地认为它们是大雁。
精确率就是在识别出来的图片中,True positives所占的比率。也就是本假设中, 所有被识别出来的飞机中, 真正的飞机所占的比例, 公式如下: Precision=\frac{TP}{TP+FP}=\frac{TP}{N}, 其中N代表测试集样本数。
召回率是测试集中所有正样本样例中, 被正确识别为正样本的比例。也就是本假设中, 被正确识别出来的飞机个数与测试集中所有真实飞机的个数的比值, 公式如下: Recall=\frac{TP}{TP+FN}
所谓PR曲线就是改变识别阈值, 使得系统依次能够识别前K张图片, 阈值的变化同时会导致Precision与Recall值发生变化, 从而得到曲线。曲线图大概如下, 这里有3条PR曲线, 周志华机器学习的解释如下:

4.平均精度(Average-Precision,AP)和mAP¶
AP就是Precision-recall 曲线下面的面积, 通常来说一个越好的分类器,AP值越高。 mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均, 得到的就是mAP的值,mAP的大小一定在[0,1]区间, 越大越好。该指标是目标检测算法中最重要的一个。
5.ROC曲线¶
如下图所示:

ROC的横轴是假正率(False positive rate, FPR),FPR = FP / [ FP + TN] , 代表所有负样本中错误预测为正样本的概率, 假警报率。 ROC的纵轴是真正率(True positive rate, TPR),TPR = TP / [ TP + FN] , 代表所有正样本中预测正确的概率, 命中率。 ROC曲线的对角线坐标对应于随即猜测, 而坐标点(0,1)也即是左上角坐标对应理想模型。曲线越接近左上角代表检测模型的效果越好。
那么ROC曲线是怎么绘制的呢?有如下几个步骤: - 根据每个测试样本属于正样本的概率值从大到小排序。 - 从高到低, 依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时, 我们认为它为正样本, 否则为负样本。 - 每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。 当我们将threshold设置为1和0时, 分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来, 就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
6.AUC(Area Uner Curve)¶
即为ROC曲线下的面积。AUC越接近于1,分类器性能越好。AUC值是一个概率值, 当你随机挑选一个正样本以及一个负样本, 当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大, 当前的分类算法越有可能将正样本排在负样本前面, 即能够更好的分类。AUC的计算公式如下:

目标检测中用的最多的是MAP值, 但我们最好再了解一下PR曲线和ROC曲线的应用场景, 在不同的数据集中选择合适的评价标准更好的判断我们的模型是否训好了。
7.PR曲线¶
从PR的计算公式可以看出,PR曲线聚焦于正例。类别不平衡问题中由于主要关心正例, 所以在此情况下PR曲线被广泛认为优于ROC曲线。
8.ROC曲线¶
当测试集中的正负样本的分布发生变化时,ROC曲线可以保持不变。因为TPR聚焦于正例,FPR聚焦于与负例, 使其成为一个比较均衡的评估方法。但是在关心正例的预测准确性的场景,ROC曲线就不能更好的反应模型的性能了, 因为ROC曲线的横轴采用FPR,根据FPR公式 , 当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例, 在ROC曲线上却无法直观地看出来。
因此,PR曲线和ROC曲线的选用时机可以总结如下:

从目标检测任务来讲, 一般关心MAP值即可。
6.2 代码解析¶
下面解析一下Faster-RCNN中对VOC数据集计算每个类别AP值的代码,mAP就是所有类的AP值平均值。代码来自py-faster-rcnn项目, 链接见附录。代码解析如下:
# --------------------------------------------------------
# Fast/er R-CNN
# Licensed under The MIT License [see LICENSE for details]
# Written by Bharath Hariharan
# --------------------------------------------------------
import xml.etree.ElementTree as ET #读取xml文件
import os
import cPickle #序列化存储模块
import numpy as np
def parse_rec(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
objects = []
# 解析xml文件, 将GT框信息放入一个列表
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
# 单个计算AP的函数, 输入参数为精确率和召回率, 原理见上面
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
# 如果使用2017年的计算AP的方式(插值的方式)
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# 使用2010年后的计算AP值的方式
# 这里是新增一个(0,0), 方便计算
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
# 主函数
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: 产生的txt文件, 里面是一张图片的各个检测框结果。
annopath: xml 文件与对应的图像相呼应。
imagesetfile: 一个txt文件, 里面是每个图片的地址, 每行一个地址。
classname: 种类的名字, 即类别。
cachedir: 缓存标注的目录。
[ovthresh]: IOU阈值, 默认为0.5,即mAP50。
[use_07_metric]: 是否使用2007的计算AP的方法, 默认为Fasle
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# 首先加载Ground Truth标注信息。
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
# 即将新建文件的路径
cachefile = os.path.join(cachedir, 'annots.pkl')
# 读取文本里的所有图片路径
with open(imagesetfile, 'r') as f:
lines = f.readlines()
# 获取文件名,strip用来去除头尾字符、空白符(包括\n、\r、\t、' ', 即:换行、回车、制表符、空格)
imagenames = [x.strip() for x in lines]
#如果cachefile文件不存在, 则写入
if not os.path.isfile(cachefile):
# load annots
recs = {}
for i, imagename in enumerate(imagenames):
#annopath.format(imagename): label的xml文件所在的路径
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
print 'Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames))
# save
print 'Saving cached annotations to {:s}'.format(cachefile)
with open(cachefile, 'w') as f:
#写入cPickle文件里面。写入的是一个字典, 左侧为xml文件名, 右侧为文件里面个各个参数。
cPickle.dump(recs, f)
else:
# load
with open(cachefile, 'r') as f:
recs = cPickle.load(f)
# 对每张图片的xml获取函数指定类的bbox等
class_recs = {}# 保存的是 Ground Truth的数据
npos = 0
for imagename in imagenames:
# 获取Ground Truth每个文件中某种类别的物体
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
# different基本都为0/False
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult) #自增, ~difficult取反,统计样本个数
# # 记录Ground Truth的内容
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets 读取某类别预测输出
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines] # 图片ID
confidence = np.array([float(x[1]) for x in splitlines]) # IOU值
BB = np.array([[float(z) for z in x[2:]] for x in splitlines]) # bounding box数值
# 对confidence的index根据值大小进行降序排列。
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
#重排bbox,由大概率到小概率。
BB = BB[sorted_ind, :]
# 图片重排, 由大概率到小概率。
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
这个脚本可以直接调用来计算mAP值, 可以看一下附录中的最后一个链接。
参考文献¶
- http://host.robots.ox.ac.uk/pascal/VOC/pubs/everingham15.pdf
- http://homepages.inf.ed.ac.uk/ckiw/postscript/ijcv_voc09.pdf
- 代码链接:https://github.com/rbgirshick/py-faster-rcnn/blob/master/lib/datasets/voc_eval.py
- 在Darknet中调用上面的脚本来计算mAP值:https://blog.csdn.net/amusi1994/article/details/81564504
7. 目标检测算法之NMS后处理¶
7.1 介绍¶
非极大值抑制(Non-Maximum Suppression,NMS), 顾名思义就是抑制不是极大值的元素。在目标检测任务, 例如行人检测中, 滑动窗口经过特征提取和分类器识别后, 每个窗口都会得到一个分数。但滑动窗口会导致很多窗口和其它窗口存在包含大部分交叉的情况。这个时候就需要用到NMS来选取那些邻域里分数最高, 同时抑制那些分数低的窗口。
7.2 原理¶
在目标检测任务中, 定义最后的候选框集合为B, 每个候选框对应的置信度是S,IOU阈值设为T, 然后NMS的算法过程可以表示如下: - 选择具有最大score的候选框M - 将M从集合B中移除并加入到最终的检测结果D中 - 将B中剩余检测框中和M的交并比(IOU,昨天的推文有介绍)大于阈值T的框从B中移除 - 重复上面的步骤, 直到B为空
7.3 代码实现¶
rgb大神实现Faster-RCNN中的单类别物体nms代码解释如下:
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
#x1、y1、x2、y2、以及score赋值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#每一个检测框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#按照score置信度降序排序
order = scores.argsort()[::-1]
#保留的结果框集合
keep = []
while order.size > 0:
i = order[0]
#保留该类剩余box中得分最高的一个
keep.append(i)
# 得到相交区域,左上及右下
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交的面积,不重叠时面积为0
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算IoU:重叠面积 /(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
# 保留IoU小于阈值的box
inds = np.where(ovr <= thresh)[0]
# 因为ovr数组的长度比order数组少一个,所以这里要将所有下标后移一位
order = order[inds + 1]
return keep
7.3 效果¶

7.4 Soft-NMS¶
上面说的NMS算法有一个缺点就是当两个候选框的重叠度很高时,NMS会将具有较低置信度的框去掉, 也就是将其置信度变成0,如下图所示, 红色框和绿色框是当前的检测结果, 二者的得分分别是0.95和0.80。如果按照传统的NMS进行处理, 首先选中得分最高的红色框, 然后绿色框就会因为与之重叠面积过大而被删掉。

因此为了改善这个缺点,Soft-NMS被提出, 核心思路就是不要粗鲁地删除所有IOU大于阈值的框, 而是降低其置信度。这个方法的论文地址为:https://arxiv.org/pdf/1704.04503.pdf 。算法伪代码如下:

正如作者所说, 改一行代码就OK了。这里的f函数可以是线性函数, 也可以是高斯函数。我们来对比一下: - 线性函数:
- 高斯函数:
7.5 代码实现¶
作者的代码如下:
def cpu_soft_nms(np.ndarray[float, ndim=2] boxes, float sigma=0.5, float Nt=0.3, float threshold=0.001, unsigned int method=0):
cdef unsigned int N = boxes.shape[0]
cdef float iw, ih, box_area
cdef float ua
cdef int pos = 0
cdef float maxscore = 0
cdef int maxpos = 0
cdef float x1,x2,y1,y2,tx1,tx2,ty1,ty2,ts,area,weight,ov
for i in range(N):
maxscore = boxes[i, 4]
maxpos = i
tx1 = boxes[i,0]
ty1 = boxes[i,1]
tx2 = boxes[i,2]
ty2 = boxes[i,3]
ts = boxes[i,4]
pos = i + 1
# get max box
while pos < N:
if maxscore < boxes[pos, 4]:
maxscore = boxes[pos, 4]
maxpos = pos
pos = pos + 1
# add max box as a detection
boxes[i,0] = boxes[maxpos,0]
boxes[i,1] = boxes[maxpos,1]
boxes[i,2] = boxes[maxpos,2]
boxes[i,3] = boxes[maxpos,3]
boxes[i,4] = boxes[maxpos,4]
# swap ith box with position of max box
boxes[maxpos,0] = tx1
boxes[maxpos,1] = ty1
boxes[maxpos,2] = tx2
boxes[maxpos,3] = ty2
boxes[maxpos,4] = ts
tx1 = boxes[i,0]
ty1 = boxes[i,1]
tx2 = boxes[i,2]
ty2 = boxes[i,3]
ts = boxes[i,4]
pos = i + 1
# NMS iterations, note that N changes if detection boxes fall below threshold
while pos < N:
x1 = boxes[pos, 0]
y1 = boxes[pos, 1]
x2 = boxes[pos, 2]
y2 = boxes[pos, 3]
s = boxes[pos, 4]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
iw = (min(tx2, x2) - max(tx1, x1) + 1)
if iw > 0:
ih = (min(ty2, y2) - max(ty1, y1) + 1)
if ih > 0:
ua = float((tx2 - tx1 + 1) * (ty2 - ty1 + 1) + area - iw * ih)
ov = iw * ih / ua #iou between max box and detection box
if method == 1: # linear
if ov > Nt:
weight = 1 - ov
else:
weight = 1
elif method == 2: # gaussian
weight = np.exp(-(ov * ov)/sigma)
else: # original NMS
if ov > Nt:
weight = 0
else:
weight = 1
boxes[pos, 4] = weight*boxes[pos, 4]
# if box score falls below threshold, discard the box by swapping with last box
# update N
if boxes[pos, 4] < threshold:
boxes[pos,0] = boxes[N-1, 0]
boxes[pos,1] = boxes[N-1, 1]
boxes[pos,2] = boxes[N-1, 2]
boxes[pos,3] = boxes[N-1, 3]
boxes[pos,4] = boxes[N-1, 4]
N = N - 1
pos = pos - 1
pos = pos + 1
keep = [i for i in range(N)]
return keep
7.6 效果¶
 左边是使用了NMS的效果, 右边是使用了Soft-NMS的效果。
左边是使用了NMS的效果, 右边是使用了Soft-NMS的效果。
7.7 论文的实验结果¶
 可以看到在MS-COCO数据集上
可以看到在MS-COCO数据集上map$[0.5:0.95]可以获得大约1%的提升, 如果应用到训练阶段的proposal选取过程理论上也能获得提升。顺便说一句,soft-NMS在不是基于Proposal的方法如SSD,YOLO中没什么提升。这里猜测原因可能是因为YOLO和SSD产生的框重叠率较低引起的。
本文总阅读量次