1. 前言¶
人脸检测领域目前主要的难点集中在小尺寸,模糊人脸,以及遮挡人脸的检测,这篇ICCV2017的S3FD(全称:Single Shot Scale-invariant Face Detector)即是在小尺寸人脸检测上发力。
2. 出发点&贡献¶
S3FD这篇论文的出发点是当人脸尺寸比较小的时候,Anchor-Based的人脸检测算法效果下降明显,因此作者提出了这个不受人脸变化影响的S3FD算法。这一算整体上可以看做是基于SSD的改进,它的主要贡献可以概括为:
- 改进检测网络并设置更加合理的Anchor,改进检测网络主要是增加
Stride=4的预测层,Anchor尺寸的设置参考有效感受野,另外不同预测层的Anchor间隔采用等比例设置。 - 引入尺度补偿的Anchor匹配策略增加正样本Anchor的数量,从而提高人脸的召回率。
- 引入
max-out background label降低误检。
3. 小尺寸人脸检测效果不好的原因研究¶
下面的Figure1展示了论文对Anchor-Based的人脸检测算法在小人脸检测中效果下降明显的原因分析。
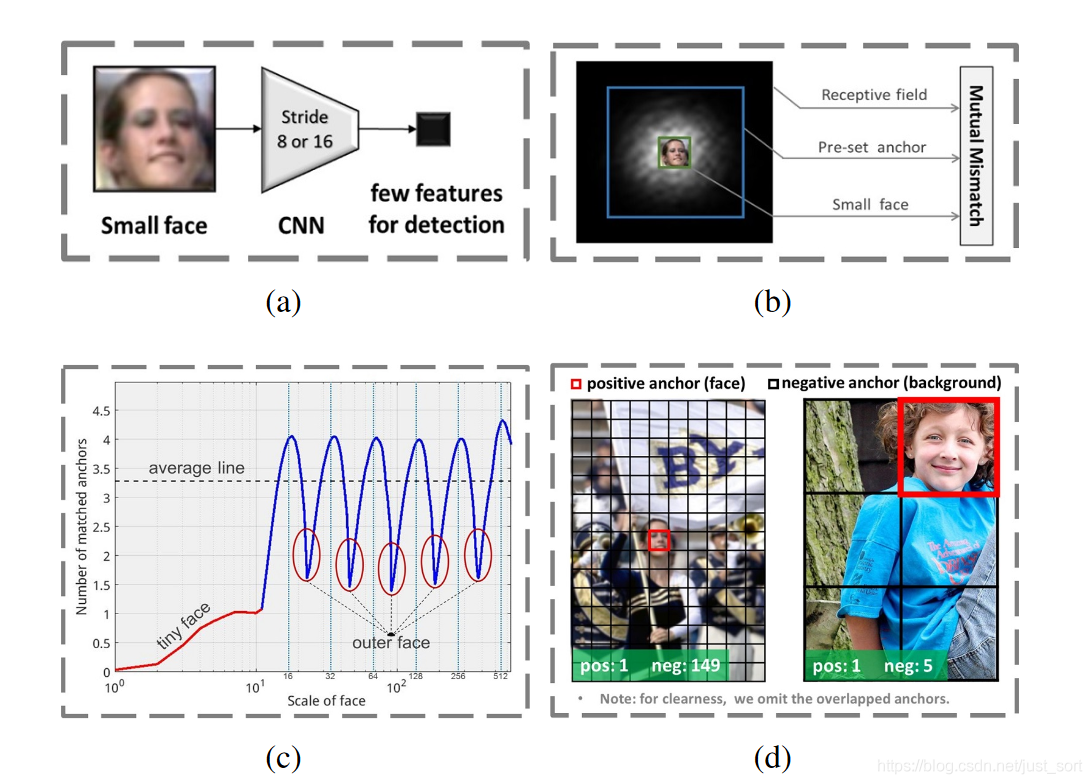
Figure1(a)中展示的是网络结构本身设计的问题。了解过SSD的同学知道在网络结构中有多个特征层被用于检测目标,这些特征层中stride最小的是8,这样原图中8\times 8大小的区域在该预测层中就仅有1个像素点,这对小人脸的检测是非常不利的,因为有效的特征太少了。同样,对于Faster-RCNN来讲,用于检测目标的特征层的stride是16,这样用于人脸检测的有效特征范围就更小,这对小脸检测是致命打击。Figure1(b)中展示了Anchor的尺寸,感受野和人脸的尺寸不匹配的问题。Figure1(c)中展示了由于一般设置的Anchor尺寸都是离散的,例如[16,32,64,128,256,512], 而人脸的尺寸是连续的,因此当人脸的尺寸在设定的Anchor值之间时可以用于检测的Anchor数量就会很少,如图中的红色圆圈部分所示,这样就会导致人脸检测的召回率低。Figure1(d)指出为了提高小人脸的检测召回率,很多检测算法都会通过设置较多的小尺寸Anchor实现,这样容易导致较多的小尺寸负样本Anchor,最终导致误检率的增加。这里两张图的分辨率是一样的,左图中的人脸区域较小,因此主要通过浅层特征来进行检测,因此这里Anchor尺寸设置较小,而右图中的人脸区域较大,因此主要是通过高层特征进行检测,此时Anchor尺寸设置较大。可以看出左图中标签为背景的Anchor数量远远多于标签为目标的Anchor,而在右图中数量比例还是相对较均衡的。
4. S3FD原理¶
论文针对第三节的问题进行了分析并提出了解决方案,也就有了这篇S3FD。
首先针对FIgure1(a),(b)的问题,论文对检测网络的设计以及Anchor的铺设做了改进,提出了不受人脸尺寸影响的检测网络,改进的主要内容包括:
- 预测层的最小
stride降低到4(具体而言预测层的stride范围为4到128,一共6个预测层),这样就保证了小人脸在浅层进行检测时能够有足够的特征信息。 - Anchor的尺寸根据每个预测层的有效感受野和等比例间隔原理进行设置,设置为16到512,前者保证了每个预测层的Anchor和有效感受野大小匹配,后者保证了不同预测层的Anchor再输入图像中的密度基本类似。
下面的Figure3展示了Anchor尺寸和数量设置的依据。

-
Figure3(a)展示了有效感受野effective receptive field和理论感受野theoretical receptive field的区别,其中整个(a)代表的就是理论感受野,一般都是矩形,而(a)中的白色点状区域就是有效感受野。这一点可以看我们更详细的文章:目标检测和感受野的总结和想法 -
Figure3(b)以预测层conv3_3(stride=4)为例介绍理论感受野、有效感受野和Anchor尺寸的关系。首先黑色点组成的方形框就是理论感受野,对于conv3_3预测层来说是48\times 48,而有效感受野是蓝色点组成的圆形框,而红色实线组成的方形框是该预测层设置的Anchor,尺寸是16\times 16,可以看到这里Anchor的尺寸和有效感受野是匹配的。 Figure3(c)是关于Anchor的等比例间隔设置。假设n是Anchor的尺寸,那么将Anchor的间隔设置为n/4。例如对于stride=4的conv3_3预测层而言,Anchor的尺寸为16\times 16,那么相当于在输入图像中每隔4个像素点就有一个16\times 16大小的Anchor。可以看出这部分和SSD中关于Anchor尺寸的设置是类似的,只是相同Stride层的Anchor数量比SSD少,因为这里设置的Anchor宽高比为1:1,因为人脸一般是正方形的,另外SSD是对特征图每个像素点都设置Anchor。
下面的Table1展示了预测层的stride,anchor尺寸和感受野之间的关系。
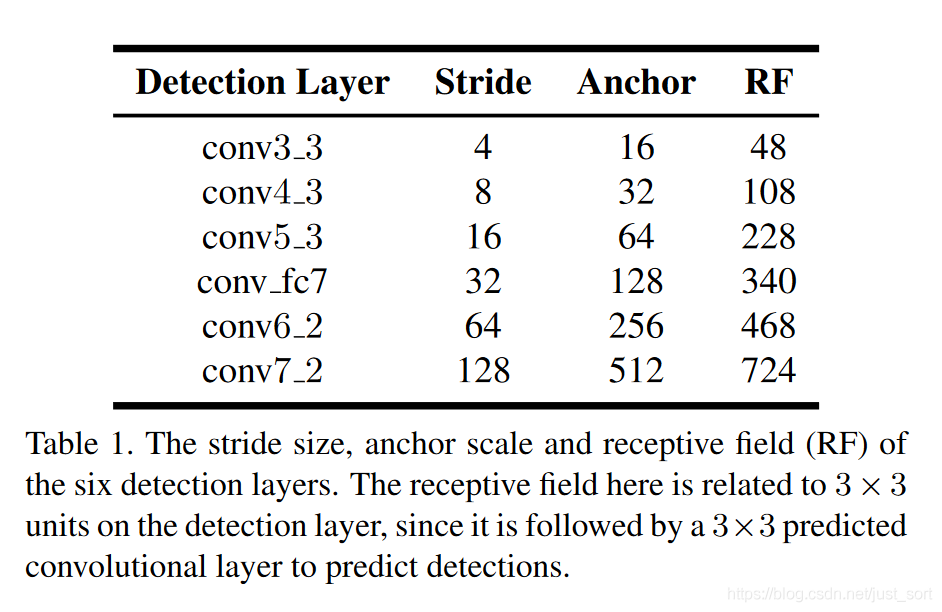
S3FD的Anchor尺寸设置和SSD最主要的区别在于S3FD中的Anchor大小是只和stride相关的,而SSD的Anchor大小不仅和stride有关,还和输入大小有关。
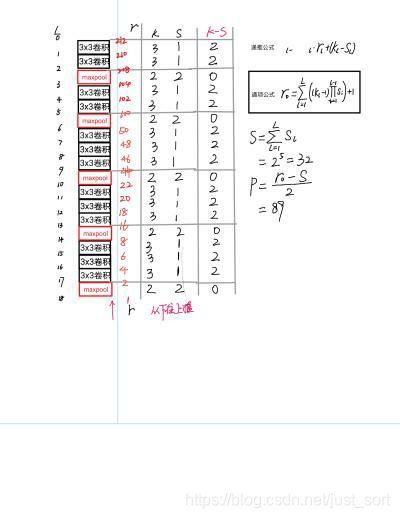
这里以conv3_3为例子,来手算一下理论感受野,注意这里说的理论感受野是基于预测层计算的,比如第一行的conv3_3,是指在conv3_3后接的预测层的感受野,不是conv3_3的感受野。
conv3_3的预测层采用的是3\times 3且步长为1的卷积,所以预测层中的一个点映射到预测层的输入就是3\times 3的区域,预测层的输入是conv3_3的输出,所以conv3_3输出3\times 3区域映射到conv3_3的输入就是5\times 5的区域,conv3_3的输入又是conv3_2的输出,因此conv3_2输出的5\times 5区域映射到conv3_2的输入就是7\times 7区域,conv3_2的输入是conv3_1的输出,因此conv3_1输出的7\times 7区域映射到conv3_1的输入就是9\times 9的区域,conv3_1的输入是pool2的输出,因此pool2输出的9\times 9区域映射到pool2的输入就是18\times 18的区域,然后映射到conv2_2的输入是20\times 20的区域,映射到conv2_1的输入是22\times 22的区域,映射到pool1的输入是44\times 44的区域,映射到conv1_2的输入是46\times 46的区域,映射到conv1_1的输入是48\times 48的区域,因为conv1_1的输入就是输入图像,所以conv3_3预测层的感受野就是48,这个层就计算完了,其它层同理,注意这里计算的方法是从网络顶端算到底端,下面用一张pprp的图来看一下整个VGG16各层的感受野。
接下来的是针对Figure1(c)中的问题,论文提出了尺度补偿的Anchor匹配策略。这部分主要分两步,第一步和常规确定Anchor的正负标签类似,只不过将IOU阈值从0.5降到0.35,这样可以保证每个目标有足够的Anchor来检测,这样相当于间接解决了原本处于不同Anchor尺寸之间的人脸的可用Anchor数量少的问题。经过这一步之后,仍然会有较多的小人脸没有足够的正样本Anchor来检测,因此第二部的目的就是提高小人脸的正样本Anchor数量,具体而言是对所有和Ground Truth的IOU大于0.1的Anchor做排序,选择前N个Anchor作为正样本,这个N是第一步的Anchor数量均值。
最后获得的Anchor尺寸和人脸尺寸的匹配数量曲线如Figure4(a)所示,相比Figure1(c)相比有较大提升。虽然降低IOU阈值能够提高人脸的召回率,但同时也会带来一些误检,之所以采用这种方式,可能时因为召回率的增加远远大于误检率并且后面还有减少误检的操作。
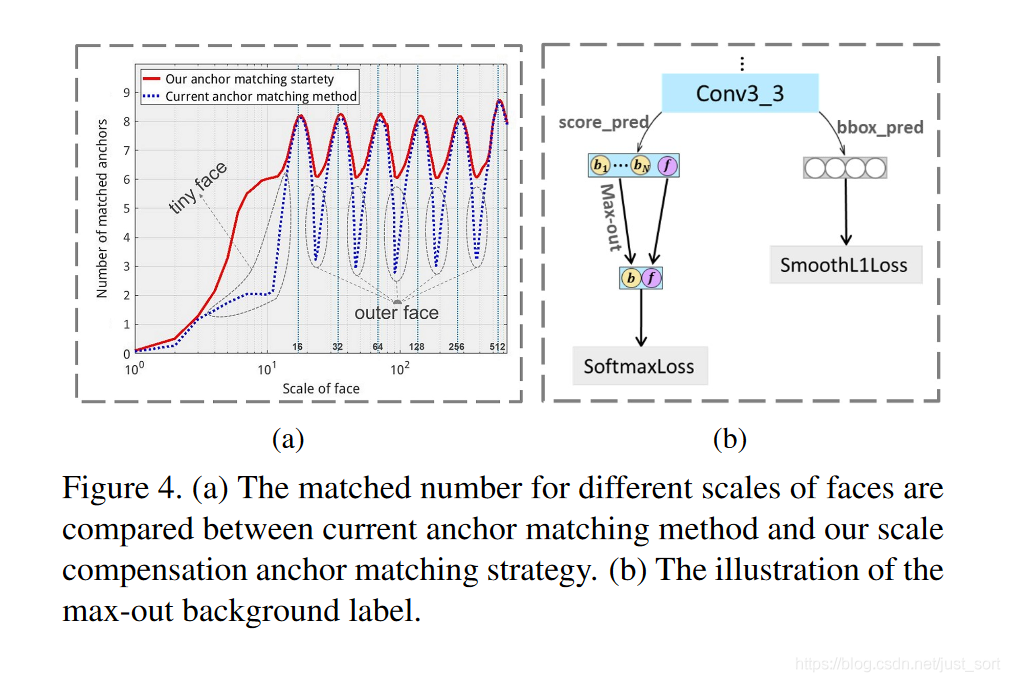
最后针对Figure1(d)的问题,作者提出了针对stride=4的预测层(conv3_3)的max-out background label操作,从而减少误检。具体如Figure4(b)所示,左边支路是分类支路,右边支路是回归支路。左边支路中一共预测N_m个背景概率和一个目标概率,选择N_m个背景概率中最高的概率作为最终的背景概率。这部分其实就相当于集成了N_m个分类器,有效削弱了负样本的预测概率,从而降低误检率,这种做法在目前不平衡的图像分类任务中也比较常用。
对max-out background label一个直观的解释就是对于每一个小尺寸anchor,进行N次人脸和背景分类,选择其中某个背景Acore最高的一个作为该Anchor的score。 其实就是对Anchor进行多次预测,然后取其最大背景概率结果,以此降低误检为人脸的anchor数量,从而降低假阳性率。
5. S3FD网络结构¶
最后,S3FD的网络结构如Figure2所示:
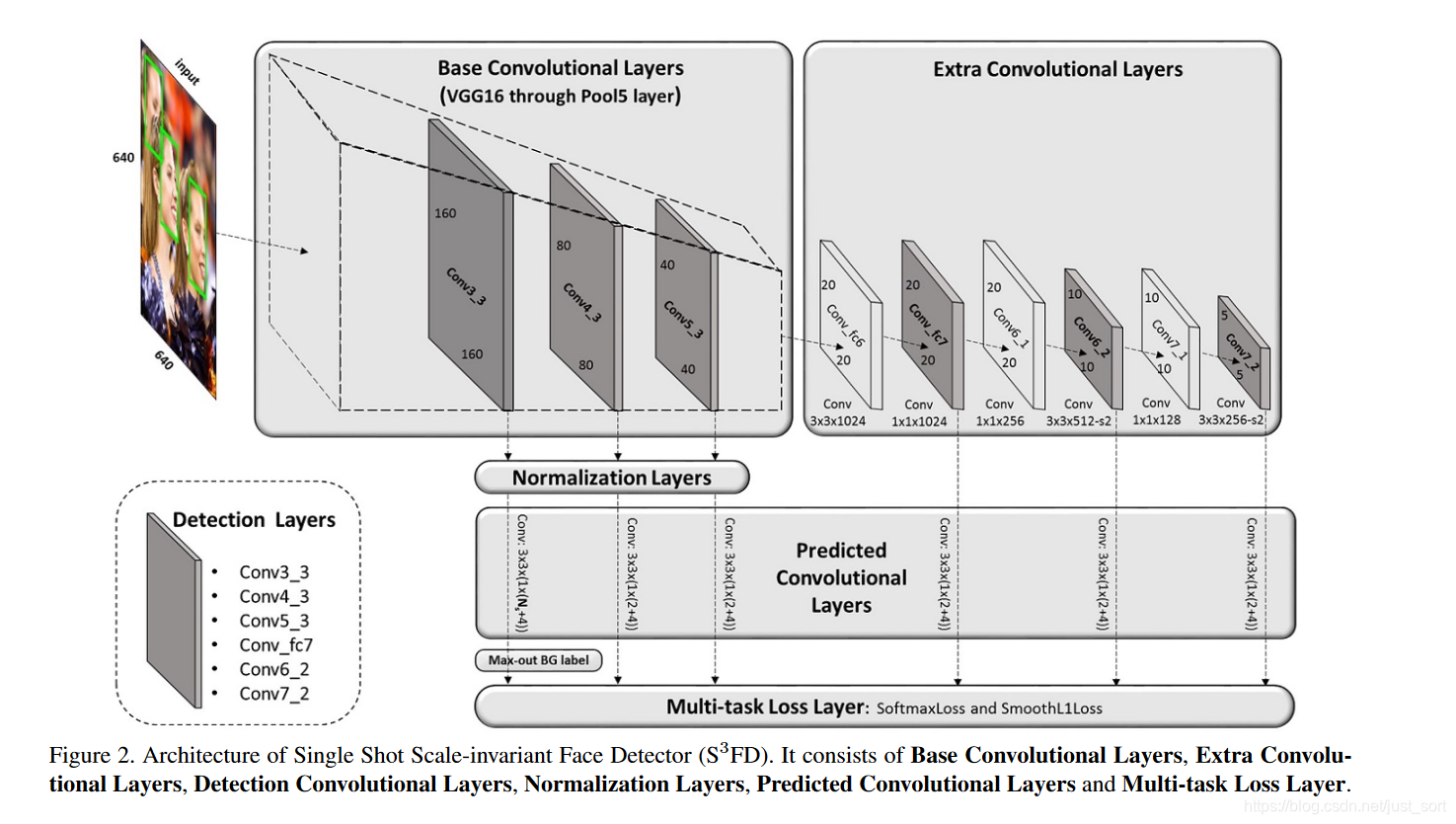
可以看到它和SSD网络结构差不多,不过预测层(predicted convolutional layers)部分和SSD的区别在于:
- 预测层整体前移了,也就是
stride=4到stride=128共6个预测层。 stride=4的预测层通道数和其他stride的预测层通道数不同,stride=4的预测层通道数是1\times (Ns+4),其它stride的预测层通道数是1 \times(2+4),这里的2其实也可以用Ns表示,不过对其它stride的预测层来说Ns为2,表示1个前景(人脸)和1个背景(非人脸)共2个类别。而对于stride=4的预测层,N_s=N_m+1,其中1表示前景(人脸),N_m表示max-out background label数量。
另外,网络的输入大小为640\times 640。
6. 模型训练¶
6.1 数据增强方法¶
模型是在WIDER FACE 的12880张人脸数据上进行训练的。其数据增强方法如下:
- 颜色扰动。
- 随机裁剪:对小尺寸人脸放大,随机裁剪5块,最大的为原图上裁剪,其他4张为原图短边缩放至原图[0.3,1]的图像上裁剪得到。
- 裁剪图像缩放为640\times 640后,并以0.5的概率随机左右翻转。
6.2 损失函数¶
损失函数包括两部分,一部分为Anchor是否为人脸的分类损失函数,还有一部分是Anchor为人脸的检测框坐标修正值的回归损失函数。最后得到总损失函数如下所示:
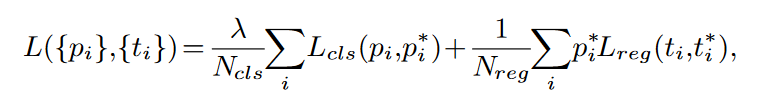
其中,i表示Anchor的索引,而p_i表示Anchor是人脸的概率,p_i^*为ground-truth,即实际情况当该anchor为人脸时,其值为1,而不为人脸时,其值为0;t_i为预测的4个检测框坐标修正值向量,t_i^*为检测框实际坐标。分类损失采用softmax 损失函数,回归损失采用smooth-L1 损失函数。p_i^*L_{reg}表示仅对正样本的anchor计算回归损失。N_{cls}和N_{reg}分别表示分类时正负anchor的数量和回归的正Anchor数量,\lambda表示平衡参数,用于平衡分类损失和回归损失。
6.3 难样例挖掘¶
经过Anchor匹配过程后,会存在严重的正负样本不平衡的问题,为了模型训练时稳定及更快收敛。对于负样本,选择loss 值逆序排序的top N ,使得正负样本比例为3:1,并且设定N_m=3,\lambda=4以平衡分类和回归损失。
7. 实验结果¶
下面的Table3展示了S3FD的消融实验结果,Baseline是Faster RCNN和SSD。S3FD(F)表示只改进检测网络和Anchor设置,S3FD(F+S)表示改进检测网络、Anchor设置和尺度补偿的Anchor匹配策略,S3FD(F+S+M)是最终的算法。
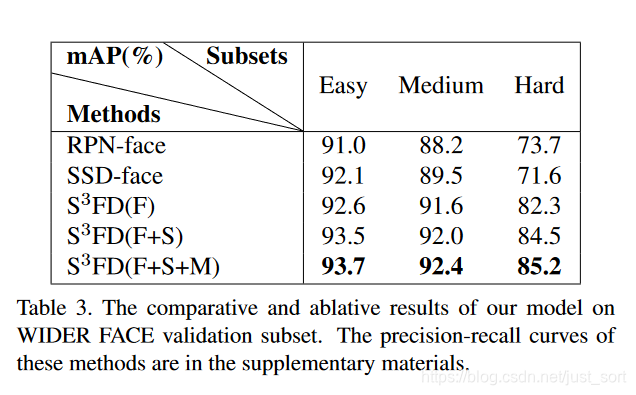
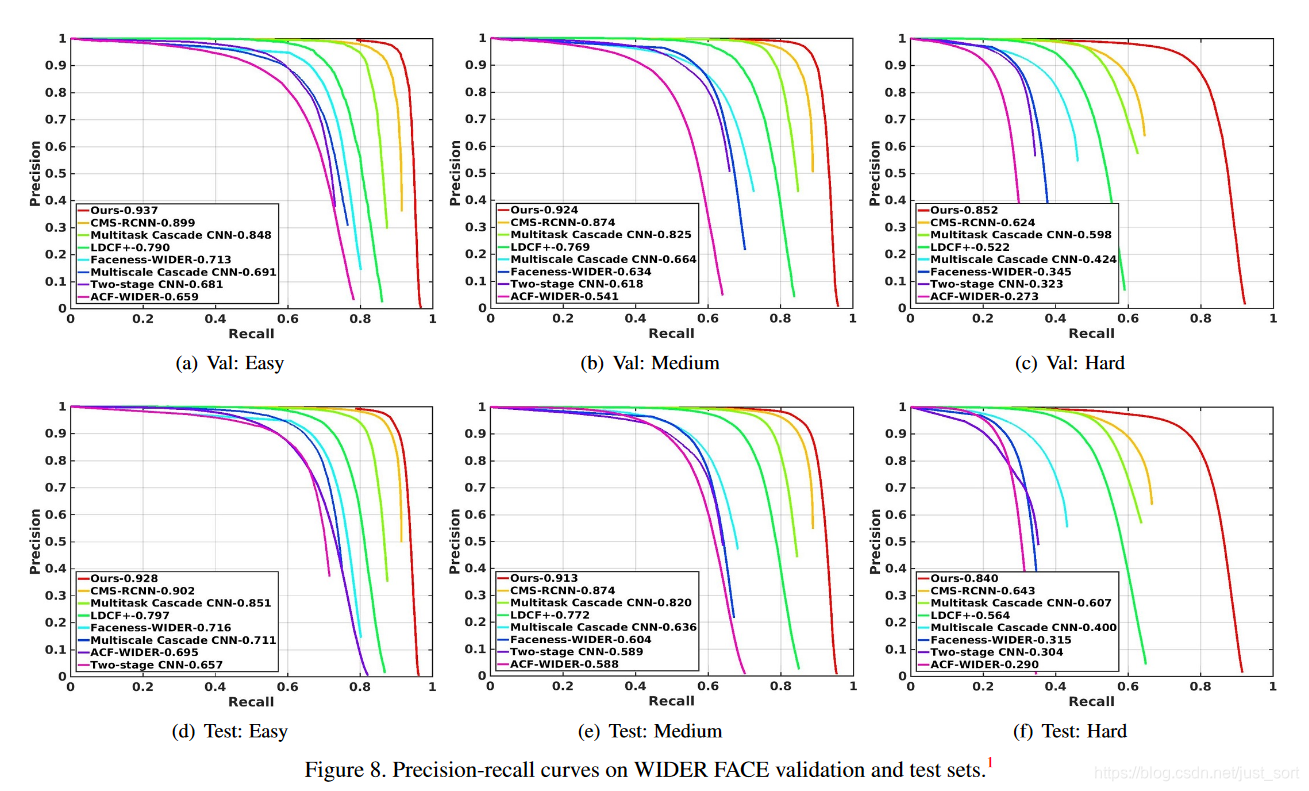
Figure8是S3FD和其它人脸检测算法在WIDER FACE数据集上的对比。
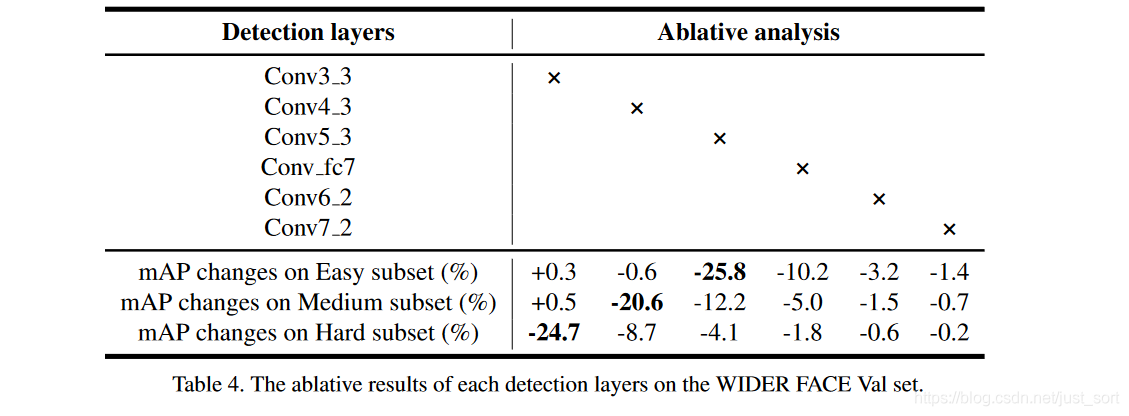
下面的Table4展示了关于选择不同预测层对最终模型效果(mAP值)的影响。
8. 结论¶
这篇论文在小尺寸人脸检测上发力,提出了一些非常有用的Trick大大提升了在小尺寸人脸上的召回率以及效果,这篇论文在小目标检测问题上提供了一个切实可行的方法,值得我们思考或者应用它。
9. 参考¶
- 论文原文:https://arxiv.org/pdf/1708.05237.pdf
- 源码:https://github.com/sfzhang15/SFD
- https://blog.csdn.net/u014380165/article/details/83477516
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次