1. 摘要¶
随着深度学习发展,大量方法提出使得人脸检测性能在近些年提高。而针对PyramidBox,我们引入了相关策略去提升整个模型性能,包括以下
- 更平衡的data-anchor-sampling,为了得到更趋于正态分布的人脸
- 设计了一个Dual-PyramidAnchors,引入了一个新的锚框损失
- 设计了一个Dense Context 模块,不仅仅关注更大的感受野,还考虑了如何更有效的传递信息流
基于上面几点改进,让PyramidBox++在hard人脸性能上得到了SOTA效果
2. Balanced-data-anchor-sampling¶
先回顾下PyramidBox里面data-anchor-sampling的做法
整个网络锚框大小设定如下
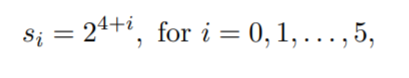
也就是16,32,64.......512
然后设
换句话说,i是比人脸框稍大的那个锚框的索引index
然后我们从

随机选取一个数字i_{target},min中的5是因为我们锚框最大的index就是5
再设置一个变量S_{target},并随机从(s_{i_{target}}/2, s_{i_{target}}*2)选取一个数
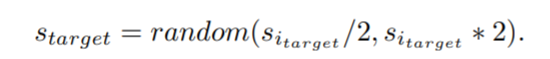
最后再与人脸区域相除,得到最后的缩放scale

举个例子很容易看懂
假设我的人脸大小是52x52
那么相邻两个锚框大小分别是32x32 和 64x64
经过比较52距离64更近一点,因此ianchor = 2(因为64x64这个锚框对应的i是2)
然后在set里面就是(0, 1, 2, 3),随机选取1个数字i_target,假设这里选到的是1
starget = random(s1/2, s1*2) = random(16, 64) 假设这里选到的是48
s* = 48/52 = 0.923
这就是最终的缩放大小
缩放后再去crop出640x640的图片
但我们发现这种采样方法往往会引入过多的小人脸,这一定程度上导致数据不均衡
因此我们引入了一个更均衡的采样方法
- 我们以等概率选择原始anchor锚框
- 然后以等概率在该锚框附近区间选择大小
相较于原始的DAS采样方法,数据中放大人脸的概率会更高,这就解决了数据不平衡的问题
最终的采样方法为⅘的概率BDAS和⅕的概率SSD采样(具体代码没开源,这里并不是特别的清楚)
3. Dual-Pyramid Anchors¶
之前的PyramidAnchor得到了一系列锚框,包含了头部,肩部,身体部位等大量上下文信息,通过高层级信息对人脸检测实现了自监督,这对于辅助人脸检测的提升是巨大的,我们参考了腾讯优图实验室的DSFD算法,引入了双路网络加入检测。显然这带来了一定计算量的提升,因此我们在推理阶段,仅选取了第二个网络的面部分支,所以在运行的时候并没有带来额外的开销
这里提一下DSFD算法,下面是其结构图
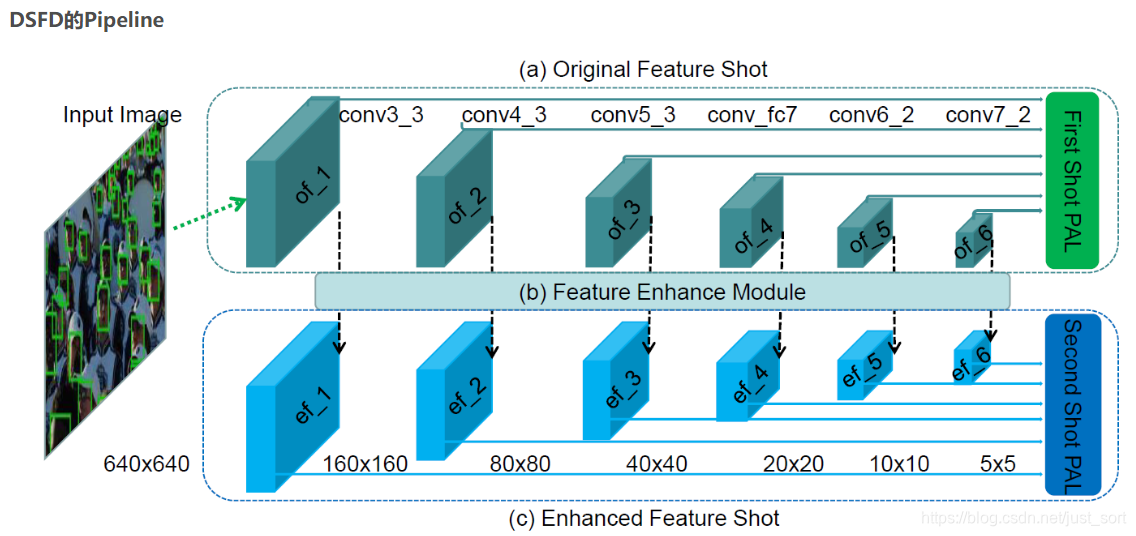
上面是原始的SSD路线,然后每个特征图经过一个FEM(Feature Enhanced Module)模块,再进行了一次特征计算
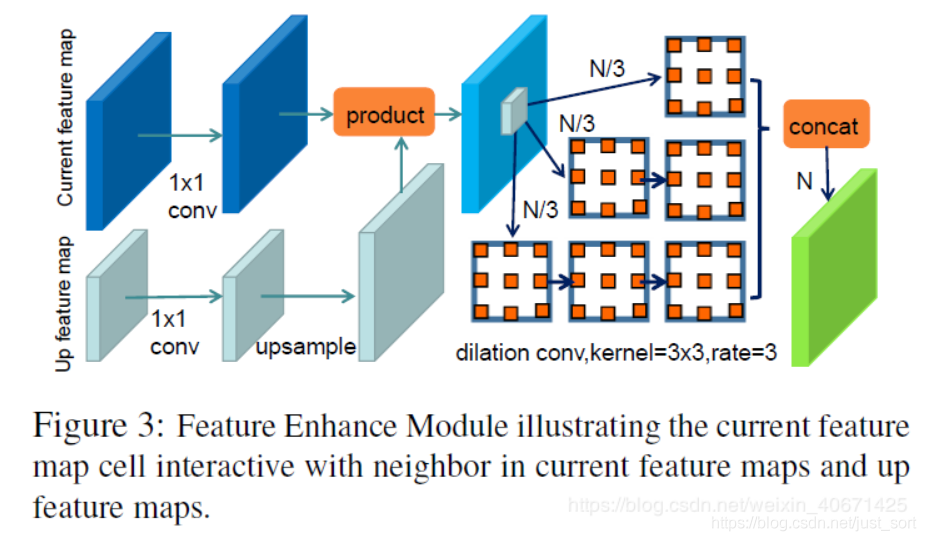
这里经过计算前后的特征图分辨率不变,因此经过FEM模块的特征图又单独作为一个通路
两个通路设置的Anchor大小并不完全一致,最后两个网络得到的损失合并在一起进行优化
(顺带吐槽一下,FEM模块是不是和pyramidBox的cpm模块太像了
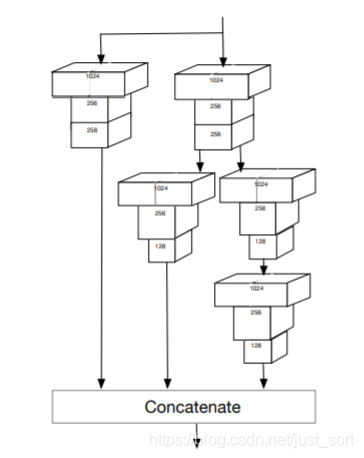
4. Dense Context Module¶
先前的工作都表明了单独设计一个预测模块对于人脸检测是有提升的,原因可能是更大的感受野包括了上下文信息。
然而模块设计的越深,在网络训练过程中越难进行优化。
受DenseNet启发,我们设计了一个多尺度特征级联(concat)的模块
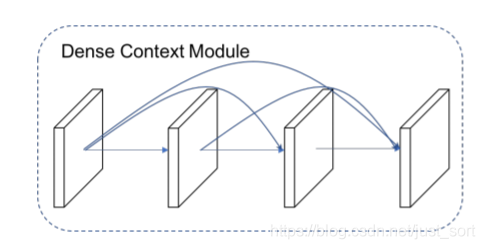
优势在于减少了计算量,优化了梯度回传
5. 多任务学习¶
多任务学习在cv领域中已经被证实能帮助网络学习到更鲁棒的特征
我们充分利用了图像分割和anchor free检测来监督网络的训练
图像分割这一分支与检测的分类分支,回归分支同时进行
分割的groundTruth是边界框级别(Bounding Box level)的(即框住的那部分矩形区域),用于监督分割训练效果
同理类似yolo算法,我们引入了Anchor free的检测分支
整体的框架如下图

6. 实验结果¶
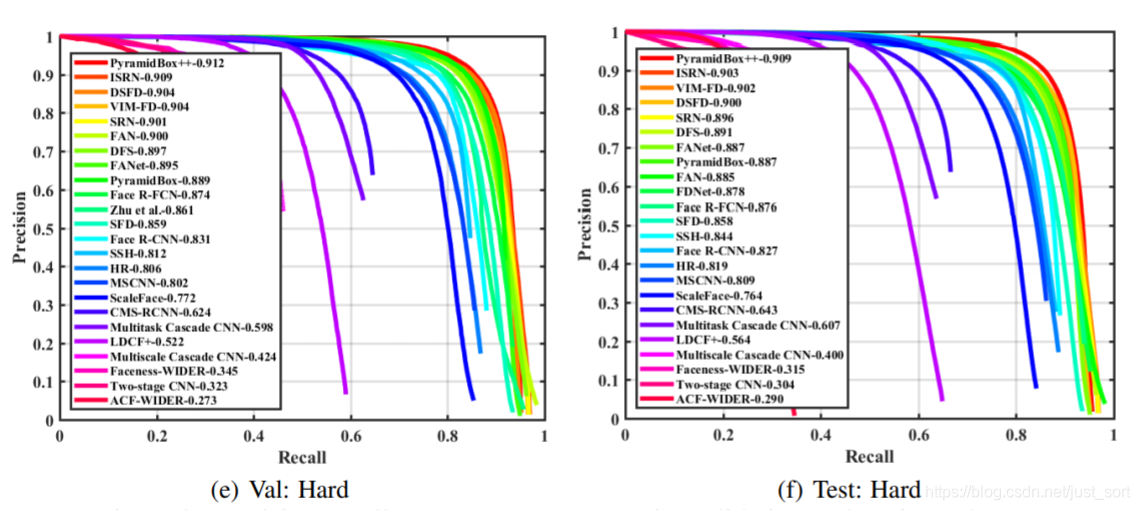
可以看到在Hard级别的数据集上,pyramidBox++表现的是非常好的
7. 训练细节¶
- 采样ImageNet上预训练的resnet50作为backbone,vgg16这个网络确实有点笨重
- 新加入的层采用Xavier初始化
- 优化器采用小批量SGD,动量为0.9,weight decay为0.0005
- 采用学习率WarmUp策略,前3000轮由1e-6到4e-3,分别在第80k,100k轮衰减10倍学习率,最终训练120k轮
最后再上一张最经典的图吧

8. 总结¶
前作的PyramidBox的想法真的十分棒,这次的PyramidBox++更是考虑了新出的算法,重新设计了双路结构,以及DenseBlock,并引入了多任务学习来辅助监督人脸检测性能。训练细节上也没有用很复杂的trick,就得到了SOTA的结果。但是如此大的计算量,模型检测的实时性可能会是个问题。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次