1. 前言¶
今天来介绍一个在CPU上可以实时运行的人脸检测器FaceBoxes,FaceBoxes仍然是以SSD为基础进行了改进,在速度和精度上都取得了较好的Trade-Off,所以就一起来看看这篇论文吧。
2. 算法总览¶
我们先看一下FaceBoxes的整体结构图:
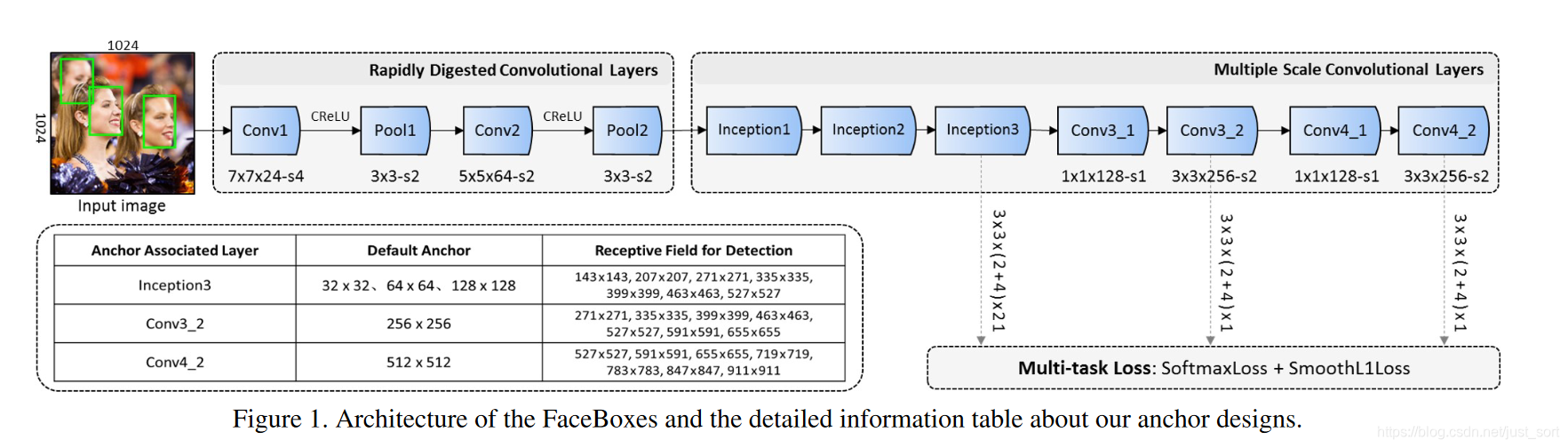
我们可以看这个网络和SSD非常类似,主要是在SSD的基础上针对人脸检测这个具体任务对其做了几点改进,例如所有Anchor的长宽比例都是1:1,并且只在三个特征层上进行预测(预知人脸的尺寸变化比例不大)。接下来我们就分别看一下这几个关键的改进点。
3. RDCL¶
RDCL即Rapidly Digested Convolutional Layers,主要包含下面几个要点:
- 快速减小输入特征图的大小:为了达到这一点,在卷积和池化层中使用了一系列大的滑动步长,在Conv1,Pool1,Conv2,Pool2上
stride分别是4,2,2,2, 所以RDCL的stride一共是32,也即是说输入图片的尺寸被快速的减小了32倍。 - 选择合适的核尺寸:一个网络开始的一些层的kernel size应该比较小以用来加速,同时也要在某些层上使用较大的卷积核来减轻特征图减小带来的信息损失。Conv1,Conv2以及所有的Pool分别选取了7\times 7,5\times 5, 3\times 3的核尺寸。
- 减少输出通道数:使用C.ReLU来减少输出通道数。
4. MSCL¶
MSCL即Multiple Scale Convolutional Layers,主要包含下面几个要点:
- 丰富感受野:使用了Inception模块来丰富感受野,感受野的知识可以看我们的这篇推文:目标检测和感受野的总结和想法
- 多尺度检测:和SSD一样在多个尺度上进行检测。
5. CReLU减少卷积核数量¶
CReLU的论文如下:
https://arxiv.org/abs/1603.05201
整个文章的出发点来自于下图中的统计现象:
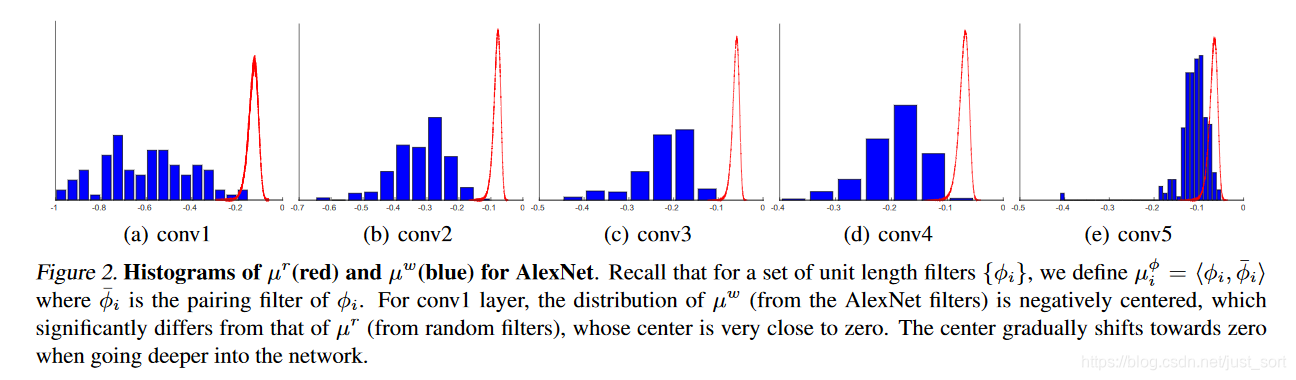
为了理解这个图需要搞清楚下面2个概念: - 余弦相似度:
similarity=cos(\theta)=\frac{A*B}{||A||||B||}
其中cos距离的取值范围是[-1,1],值越接近-1,表示两个向量的方向越相反,即呈负相关的关系。
- pair filter的定义: 我们知道一个卷积层有j=1,...,n个卷积核,一个卷积核\phi_i对应的pair filter定义为:
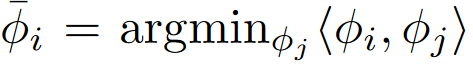
即从所有卷积核中选择一个cos相似度最小的卷积核,然后我们再看看Figure2,意思就是对于所有的卷积核都寻找它的pair filter,并计算cos相似度得到蓝色的统计直方图,而红色的曲线则代表假设随机高斯分布生成的卷积核得到的相似度统计。
- 现象
网络越前面的卷积核,参数的分布具有更强的负相关性。随着网络加深,这种负相关性逐步减弱。
- 结论:
网络的前部,网络更倾向于捕获正负相位信息而ReLU会抹掉负响应,这就造成了卷积核的冗余。
- CReLU定义:
CReLU(x)=[ReLU(x),ReLU(-x)]
输出维度自动加倍,例如-3->[0,3]。
好了,回到FaceBoxes中来,论文RDCL中将最后一层的通道数置为64,而不是128,然后接上一个CReLU,即加快了速度也不会对精度有太大影响。
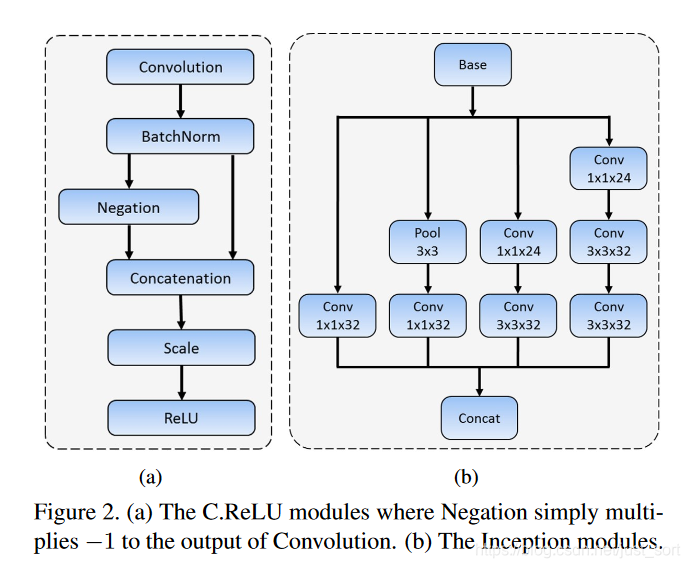
CReLU和Inception模块的示意图如下所示:
6. Anchor稠密化¶
和SSD思路一样,论文在不同的特征图上设置Anchor用于检测目标,但是对于目标拥挤的情况,论文发现在网络底层设置的小Anchor显然非常稀疏,所以需要对底层的小Anchor做一个稠密化的工作,具体就是在每个感受野的中心,也就是SSD中Anchor的中心对其进行偏移。根据Anchor的密度大小进行2,3,4倍的稠密化。
Anchor的密度计算公式为:
A_{density}=A_{scale}/A_{interval}
其中,A_{scale}表示Anchor尺度,而A_{interval}表示Anchor的间隔,默认为32,32,32,64,128,所以FaceBoxes网络中5种Anchor的密度分别为1,2,4,4,4,显然出现了密度不均衡的情况,所以我们要对32\times 32的Anchor进行四倍的稠密化,对64\times 64的Anchor进行二倍的稠密化。如Figure3所示:
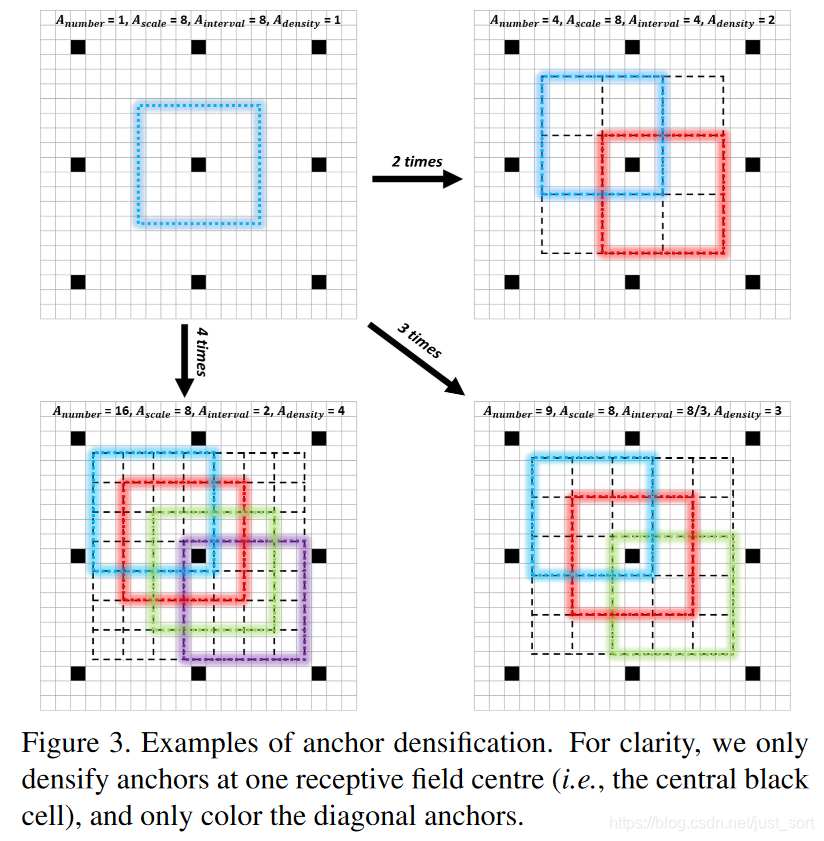
7. 网络训练¶
除了SSD中经典的Hard negative mining解决正负样本严重不平衡的Trick外,在数据增强方面也有一些特殊设置,具体如下:
- Color distorition:颜色抖动
- Random cropping:从原图中随机裁剪5个方块patch,包含一个大方块,其它的分别在范围[0.3,1]倍原图的尺寸。
- Scale transformation:将随机裁剪后的方块Resize到1024x1024。
- Horizontal flipping:随机翻转。
- Face-box filter:如果人脸BBox的中心在处理后的图片上,则保持其位置,并且将高或宽小于20像素的face box过滤出来(删除)。
这几个策略的具体细节就留给大家看源码了,另外我写的《从零开始学SSD》的PDF其实也介绍了一大半了,所以就不再赘述了。
8. 结果展示¶
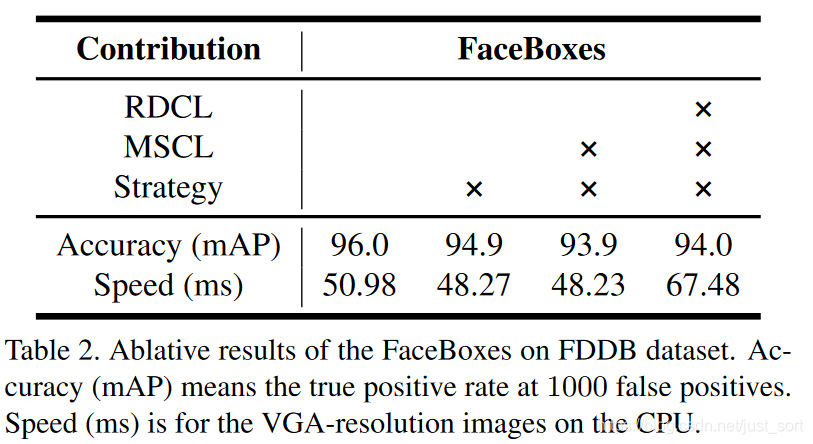
其中实验一表示去掉Anchor稠密化策略,实验二表示使用三个卷积层来代替MSCL,也即是使用单一的感受野,实验三表示使用ReLU来代替CReLU。可以看到本文的几个创新点是非常给力的。下面的Figure6展示了其在FDDB上的ROC曲线:
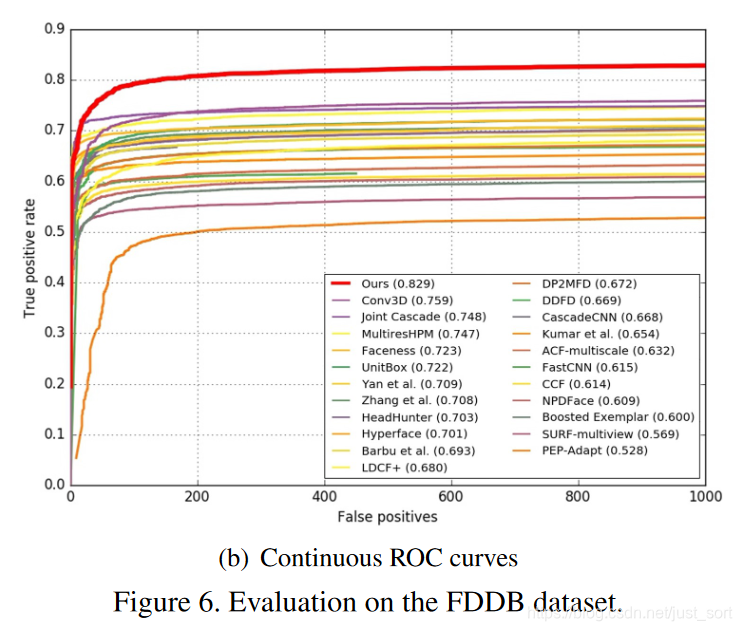
9. 结论¶
总的来说FaceBoxes在对人脸并不hard的情况下识别率是很好了,并且速度也相对较快,虽然在今天看来应用的价值不大了,但是里面提出的Trick和做的实验还是有参考意义的。
10. 参考¶
- https://zhuanlan.zhihu.com/p/56931573
- https://blog.csdn.net/shuzfan/article/details/77807550
- CReLU:https://arxiv.org/pdf/1708.05234.pdf
- 论文原文:https://arxiv.org/pdf/1603.05201.pdf
- Pytorch代码:https://github.com/zisianw/FaceBoxes.PyTorch
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次