1. 前言¶
RetinaFace是2019年5月来自InsightFace的又一力作,它是一个鲁棒性较强的人脸检测器。它在目标检测这一块的变动其实并不大,主要贡献是新增了一个人脸关键点回归分支(5个人脸关键点)和一个自监督学习分支(主要是和3D有关),加入的任务可以用下图来表示:
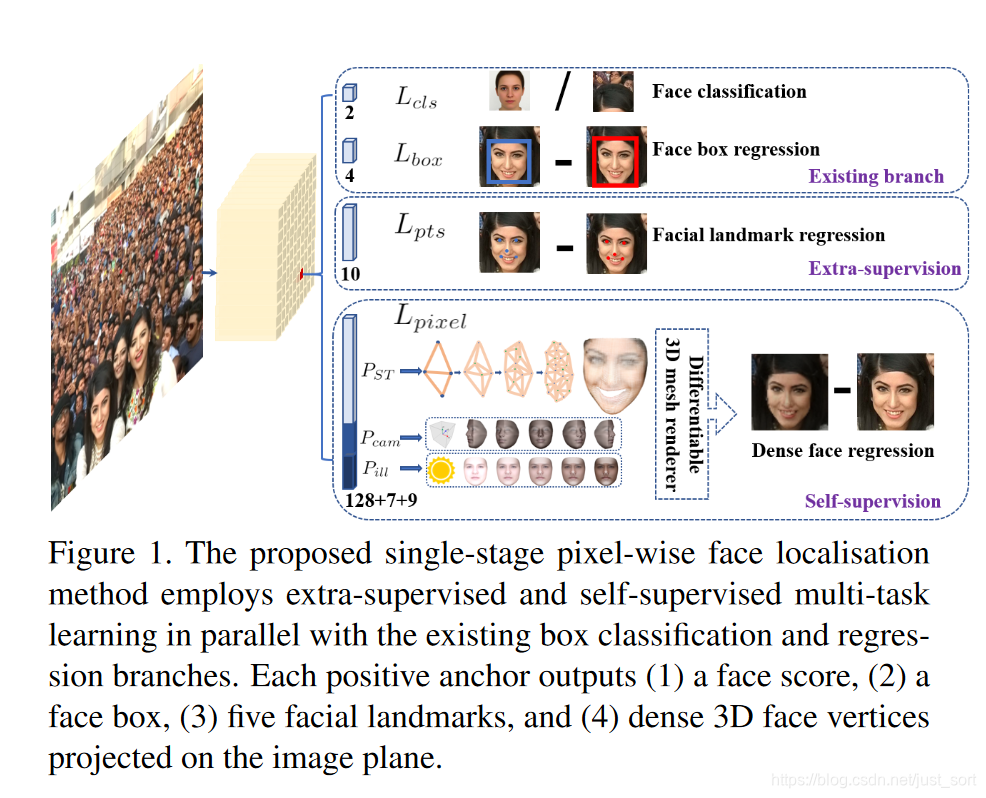
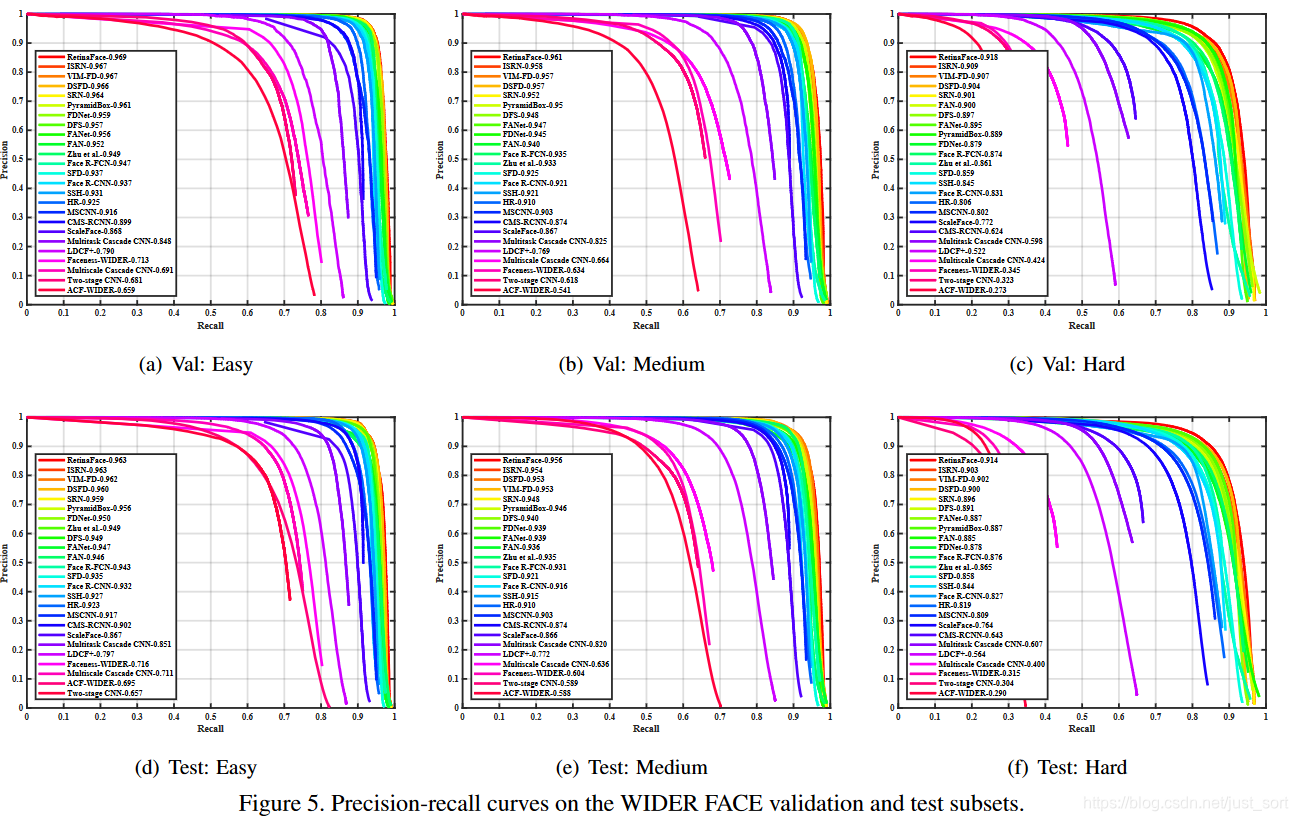
语言是空洞的,我们来看一下在WiderFace数据集上RetinaFace的表现:
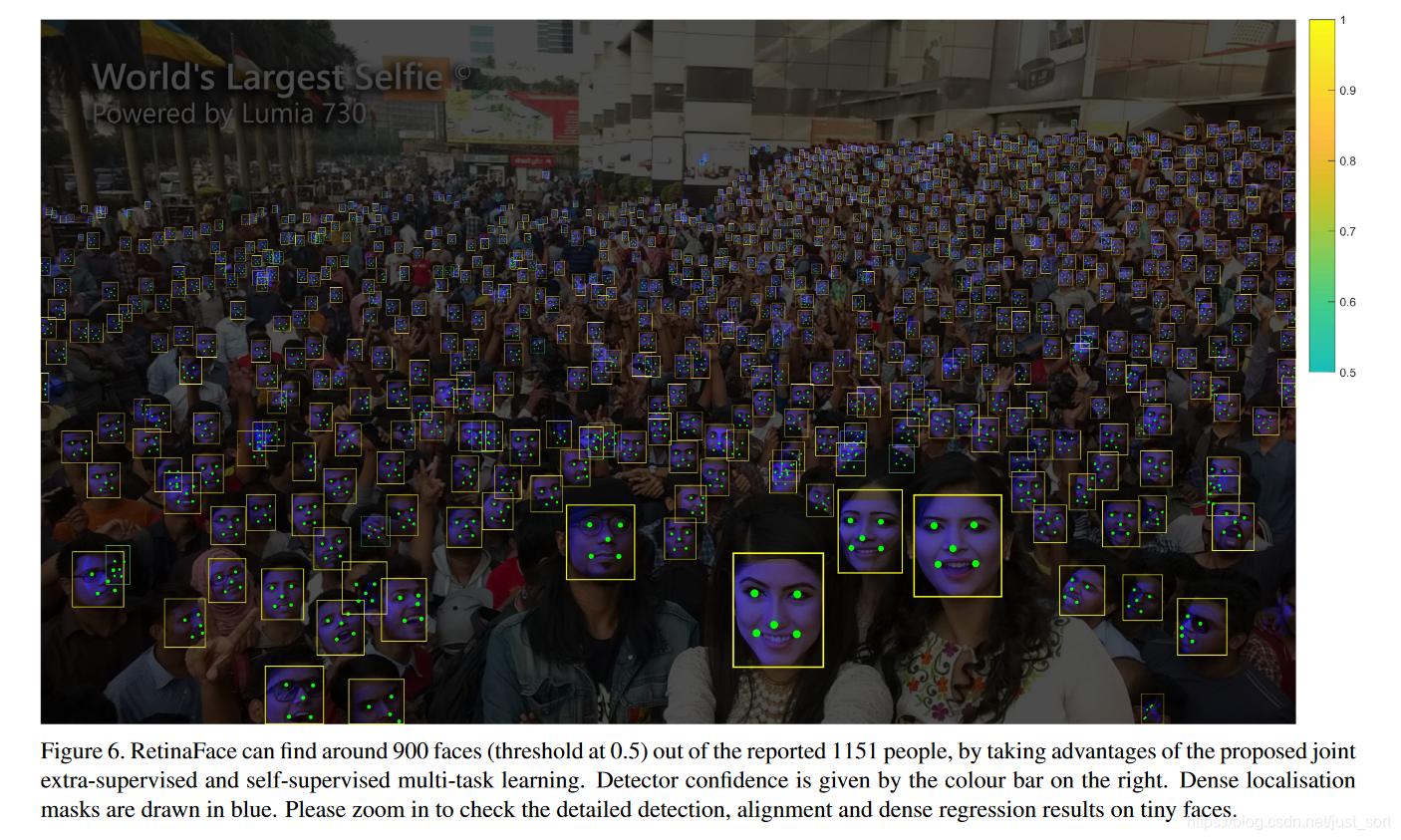
另外再来看看论文跑出来的一个效果图:
2. RetinaFace的特点¶
RetinaFace有几个主要特点:
- 采用FPN特征金字塔提取多尺度特征。
- 单阶段&&e2e,使用MobileNet Backbone可以在Arm上实时。
- 引入SSH算法的Context Modeling。
- 多任务训练,提供额外的监督信息。
2.1 RetinaFace的结构图¶
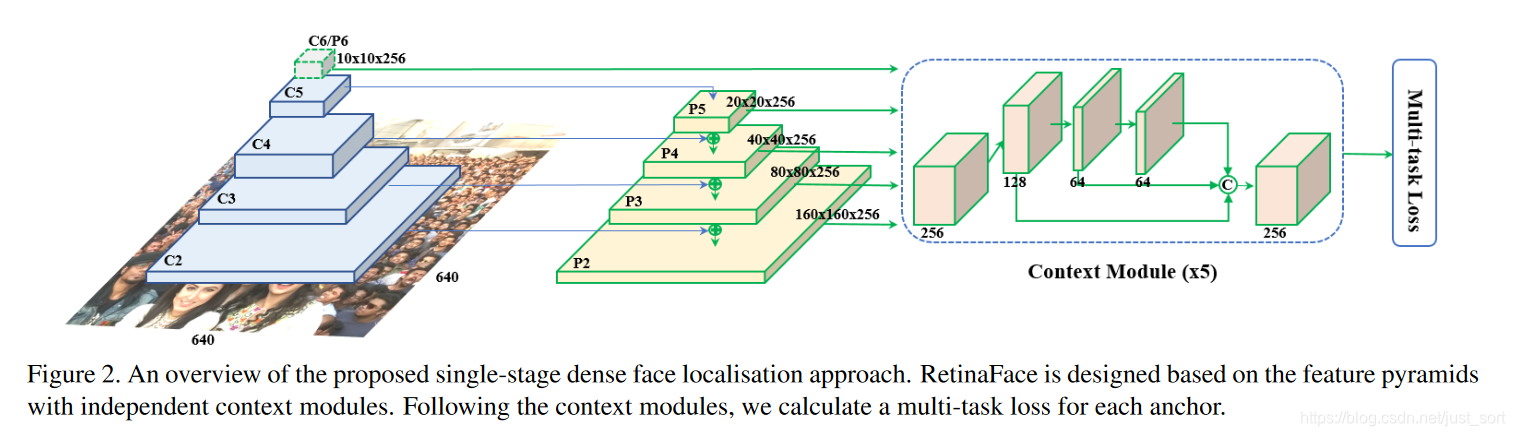
2.2 FPN¶
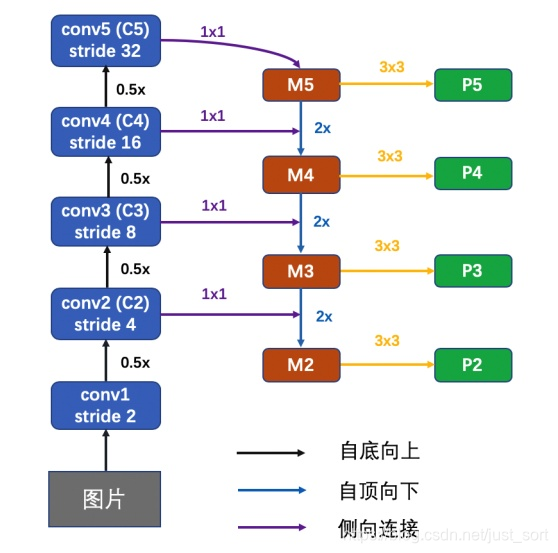
下图表示FPN的整体结构:
我们可以看到FPN的整体结构分为自底向上和自顶向下和侧向连接的过程。接下来我们分别解释一下这两个关键部分。
2.2.1 自底向上¶
这一部分就是普通的特征提取网络,特征分辨率不断缩小,容易想到这个特征提取网络可以换成任意Backbone,并且CNN网络一般都是按照特征图大小分为不同的stage,每个stage的特征图长宽差距为2倍。在这个自底向上的结构中,一个stage对应特征金字塔的一个level。以我们要用的ResNet为例,选取conv2、conv3、conv4、conv5层的最后一个残差block层特征作为FPN的特征,记为{C2、C3、C4、C5},也即是FPN网络的4个级别。这几个特征层相对于原图的步长分别为4、8、16、32。
2.2.2 自上向下和侧向连接¶
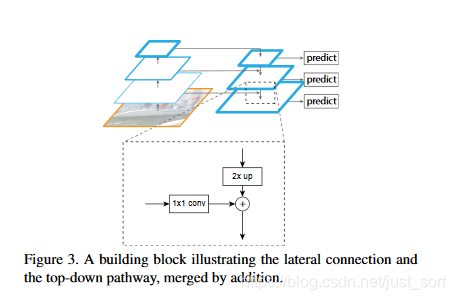
自上向下是特征图放大的过程,我们一般采用上采样来实现。FPN的巧妙之处就在于从高层特征上采样既可以利用顶层的高级语义特征(有助于分类)又可以利用底层的高分辨率信息(有助于定位)。上采样可以使用插值的方式实现。为了将高层语义特征和底层的精确定位能力结合,论文提出了类似于残差结构的侧向连接。向连接将上一层经过上采样后和当前层分辨率一致的特征,通过相加的方法进行融合。同时为了保持所有级别的特征层通道数都保持一致,这里使用1\times 1卷积来实现。在网上看到一张图,比较好的解释了这个过程:
FPN只是一个特征金字塔结构,需要配合其他目标检测算法才能使用。
2.3 SSH算法¶
2.3.1 检测模块¶
下面的Figure3是检测模块的示意图:
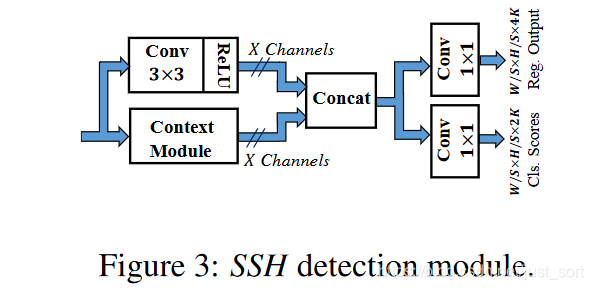
分类和回归的特征图是融合了普通卷积层和上下文模块输出的结果。分类和回归支路输出的K表示特征图上每个点都设置了K个Anchor,这K个Anchor的宽高比例都是1:1,论文说增加宽高比例对于人脸检测的效果没有提示还会增加Anchor的数量。
2.3.2 上下文模块¶
下面的Figure4是上下文模块的示意图:
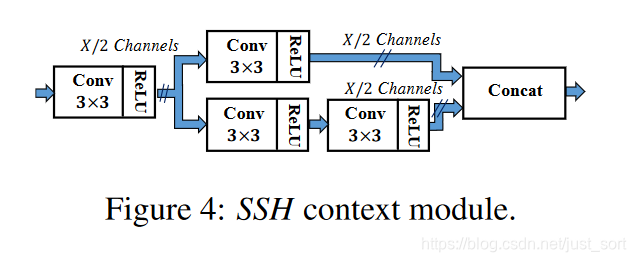
作者原本是通过引入卷积核尺寸较大的卷积层例如5\times 5和7\times 7来增大感受野,从而引入更多的上下文信息。但为了减少计算量,作者借鉴了GoogleNet中用多个3\times 3卷积代替5\times 5卷积或者7\times 7卷积的做法,于是最终上下文模块的结构就如Figure4所示了,另外注意到开头的3\times 3卷积是共享的。
2.4 损失函数¶
损失函数的改进是这篇论文的一个核心贡献,为了实现下面的损失函数的训练,作者还在WIDER FACE这个巨大的人脸数据集上进行了5点的标注,损失函数如下:
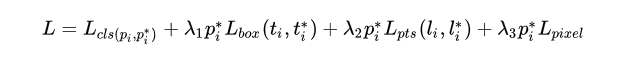
前面两项和以前的多任务人脸检测的损失是一样的,即分类和bbox回归损失,第三项是5个人脸关键点的回归损失。而最后一项是论文提出的Dense Regression分支带来的损失,下面会再简单介绍一下。其中\lambda_1,\lambda_2,\lambda_3的取值分别是0.25,0.1,0.01,也即是说来自检测分支和关键点分支的损失权重更高,而Dense Regression分支的损失权重占比小。
2.5 Dense Regression 分支¶
这个分支就是将2D的人脸映射到3D模型上,再将3D模型解码为2D图片,然后计算经过了编解码的图片和原始图片的差别。中间还用到了GCN。这里实际上用到了mesh decoder来做解码部分,mesh decoder是一种基于GCN的方法,参数量比常用的2D卷积要少。如Figure3所示:
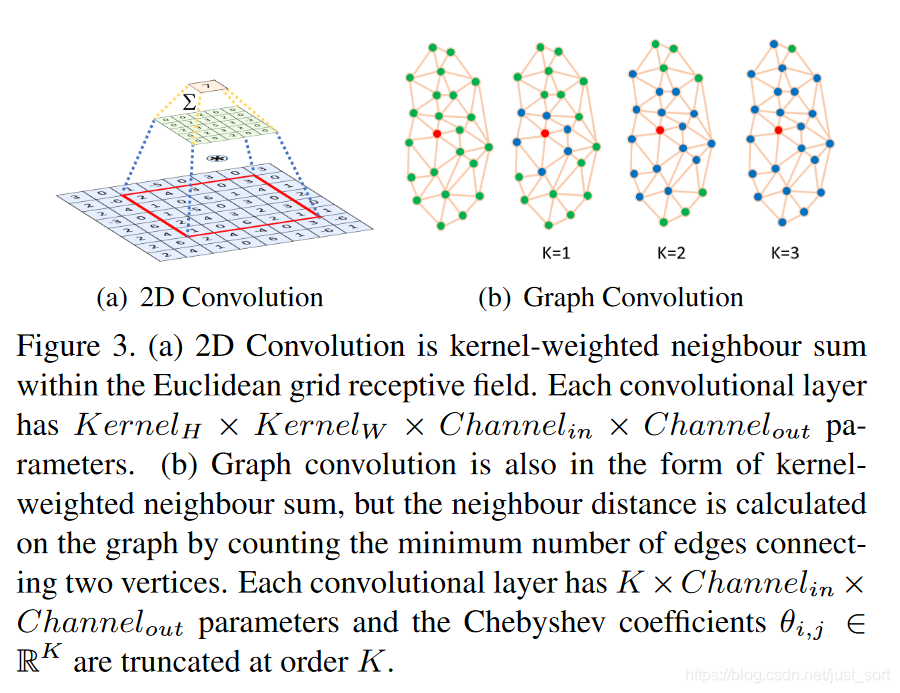
从上图可以看到,普通的卷积操作参数量一般是kernel_H\times kernel_W\times channels_{in}\times channels_{out},而GCN的参数量只有K\times channel_{in}\times channel_{out}。
在Decoder完成之后会再做一个3D到2D的映射,之后就会有一个Dense Regression Loss,实际上就是比较编解码前后的人脸图片的5个人脸特征点的位置差距了,Dense Regression Loss的公式表达如下:
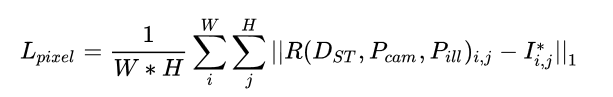
其中,W和H分别表示Anchor区域I_{i,j}^*的宽高。
3. 实现细节¶
RetinaFace使用ResNet152为Backbone的FPN结构,对于每一层金字塔都有特定的Anchor设置,这样可以捕捉到不同尺寸的目标,P2被设置为捕捉微小人脸。具体设置如下:
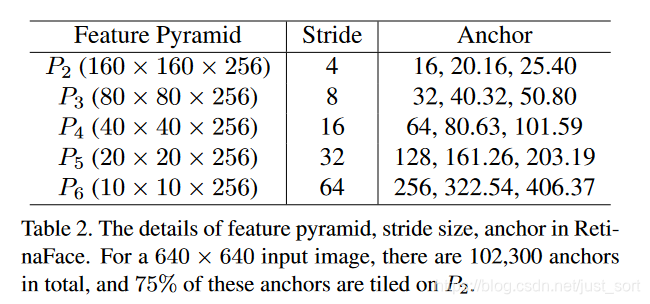
除此之外,中间还使用了OHEM来平衡positive 和negative的anchors,因为negative anchors的数量明显要多。另外还使用可变形卷积MASA DCN(可变形卷积) 算法笔记描述 代替了lateral connections和context modules中的3*3卷积 。
最后,除了上面提到的针对网络结构上的Trick,还在数据上做了额外的标注信息,具体为:
- 定义了5个等级的人脸质量,根据清晰度来定义检测难度。
- 定义了5个人脸关键点。

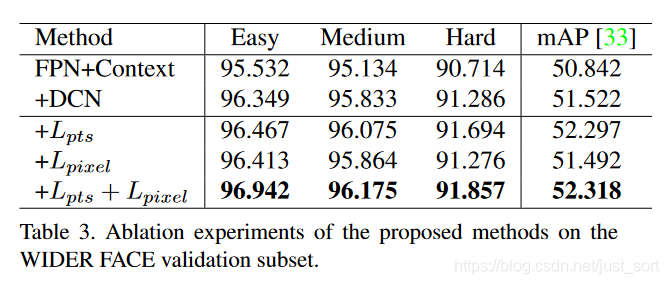
最终,基于上面的这些改进就成就了这一大名鼎鼎的RetinaFace。这些Trick的消融实验如Table3所示:
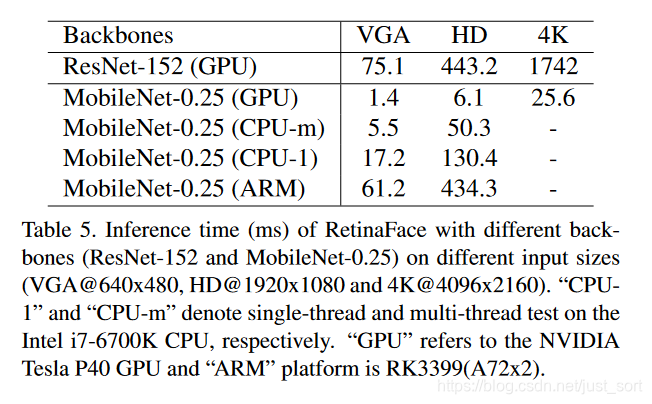
4. 速度¶
论文给出的在Wider Face上的结果是基于ResNet-152的骨干网络,如果将骨干网络换成轻量化网络,那么RetinaFace就可以轻松在Arm上达到实时检测。
5. 部署¶
前几天Hanson大佬发表了一篇文章:NINE之RetinaFace部署量化,详细介绍了MobileNet-0.25为BackBone的RetinaFace在Hisi35xx板子上的部署流程,列举了部署中的所有坑点,欢迎去学习并将RetinaFace部署在自己的工程中。实际上MobileNet-0.25的RetinaFace参数量是很少的,CaffeModel只有1.7M,从速度和精度的TradeOff来看,这可能是至今为止最好用的人脸检测器了。(训练过MTCNN的都懂,那是真不好训练,并且我个人也更倾向于这种单阶段的,不仅好训练还相对好部署啊)。
6. 核心代码¶
import torch
import torch.nn as nn
import torchvision.models.detection.backbone_utils as backbone_utils
import torchvision.models._utils as _utils
import torch.nn.functional as F
from collections import OrderedDict
from models.net import MobileNetV1 as MobileNetV1
from models.net import FPN as FPN
from models.net import SSH as SSH
class ClassHead(nn.Module):
def __init__(self,inchannels=512,num_anchors=3):
super(ClassHead,self).__init__()
self.num_anchors = num_anchors
self.conv1x1 = nn.Conv2d(inchannels,self.num_anchors*2,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.permute(0,2,3,1).contiguous()
return out.view(out.shape[0], -1, 2)
class BboxHead(nn.Module):
def __init__(self,inchannels=512,num_anchors=3):
super(BboxHead,self).__init__()
self.conv1x1 = nn.Conv2d(inchannels,num_anchors*4,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.permute(0,2,3,1).contiguous()
return out.view(out.shape[0], -1, 4)
class LandmarkHead(nn.Module):
def __init__(self,inchannels=512,num_anchors=3):
super(LandmarkHead,self).__init__()
self.conv1x1 = nn.Conv2d(inchannels,num_anchors*10,kernel_size=(1,1),stride=1,padding=0)
def forward(self,x):
out = self.conv1x1(x)
out = out.permute(0,2,3,1).contiguous()
return out.view(out.shape[0], -1, 10)
class RetinaFace(nn.Module):
def __init__(self, cfg = None, phase = 'train'):
"""
:param cfg: Network related settings.
:param phase: train or test.
"""
super(RetinaFace,self).__init__()
self.phase = phase
backbone = None
if cfg['name'] == 'mobilenet0.25':
backbone = MobileNetV1()
if cfg['pretrain']:
checkpoint = torch.load("./weights/mobilenetV1X0.25_pretrain.tar", map_location=torch.device('cpu'))
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in checkpoint['state_dict'].items():
name = k[7:] # remove module.
new_state_dict[name] = v
# load params
backbone.load_state_dict(new_state_dict)
elif cfg['name'] == 'Resnet50':
import torchvision.models as models
backbone = models.resnet50(pretrained=cfg['pretrain'])
self.body = _utils.IntermediateLayerGetter(backbone, cfg['return_layers'])
in_channels_stage2 = cfg['in_channel']
in_channels_list = [
in_channels_stage2 * 2,
in_channels_stage2 * 4,
in_channels_stage2 * 8,
]
out_channels = cfg['out_channel']
self.fpn = FPN(in_channels_list,out_channels)
self.ssh1 = SSH(out_channels, out_channels)
self.ssh2 = SSH(out_channels, out_channels)
self.ssh3 = SSH(out_channels, out_channels)
self.ClassHead = self._make_class_head(fpn_num=3, inchannels=cfg['out_channel'])
self.BboxHead = self._make_bbox_head(fpn_num=3, inchannels=cfg['out_channel'])
self.LandmarkHead = self._make_landmark_head(fpn_num=3, inchannels=cfg['out_channel'])
def _make_class_head(self,fpn_num=3,inchannels=64,anchor_num=2):
classhead = nn.ModuleList()
for i in range(fpn_num):
classhead.append(ClassHead(inchannels,anchor_num))
return classhead
def _make_bbox_head(self,fpn_num=3,inchannels=64,anchor_num=2):
bboxhead = nn.ModuleList()
for i in range(fpn_num):
bboxhead.append(BboxHead(inchannels,anchor_num))
return bboxhead
def _make_landmark_head(self,fpn_num=3,inchannels=64,anchor_num=2):
landmarkhead = nn.ModuleList()
for i in range(fpn_num):
landmarkhead.append(LandmarkHead(inchannels,anchor_num))
return landmarkhead
def forward(self,inputs):
out = self.body(inputs)
# FPN
fpn = self.fpn(out)
# SSH
feature1 = self.ssh1(fpn[0])
feature2 = self.ssh2(fpn[1])
feature3 = self.ssh3(fpn[2])
features = [feature1, feature2, feature3]
bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1)
classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)],dim=1)
ldm_regressions = torch.cat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], dim=1)
if self.phase == 'train':
output = (bbox_regressions, classifications, ldm_regressions)
else:
output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions)
return output
引用的fpn,ssh等结构代码
import time
import torch
import torch.nn as nn
import torchvision.models._utils as _utils
import torchvision.models as models
import torch.nn.functional as F
from torch.autograd import Variable
def conv_bn(inp, oup, stride = 1, leaky = 0):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.LeakyReLU(negative_slope=leaky, inplace=True)
)
def conv_bn_no_relu(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
)
def conv_bn1X1(inp, oup, stride, leaky=0):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, stride, padding=0, bias=False),
nn.BatchNorm2d(oup),
nn.LeakyReLU(negative_slope=leaky, inplace=True)
)
def conv_dw(inp, oup, stride, leaky=0.1):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.LeakyReLU(negative_slope= leaky,inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.LeakyReLU(negative_slope= leaky,inplace=True),
)
class SSH(nn.Module):
def __init__(self, in_channel, out_channel):
super(SSH, self).__init__()
assert out_channel % 4 == 0
leaky = 0
if (out_channel <= 64):
leaky = 0.1
self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1)
self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky)
self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky)
self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
def forward(self, input):
conv3X3 = self.conv3X3(input)
conv5X5_1 = self.conv5X5_1(input)
conv5X5 = self.conv5X5_2(conv5X5_1)
conv7X7_2 = self.conv7X7_2(conv5X5_1)
conv7X7 = self.conv7x7_3(conv7X7_2)
out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
out = F.relu(out)
return out
class FPN(nn.Module):
def __init__(self,in_channels_list,out_channels):
super(FPN,self).__init__()
leaky = 0
if (out_channels <= 64):
leaky = 0.1
self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky)
self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky)
self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky)
self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky)
self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky)
def forward(self, input):
# names = list(input.keys())
input = list(input.values())
output1 = self.output1(input[0])
output2 = self.output2(input[1])
output3 = self.output3(input[2])
up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
output2 = output2 + up3
output2 = self.merge2(output2)
up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
output1 = output1 + up2
output1 = self.merge1(output1)
out = [output1, output2, output3]
return out
class MobileNetV1(nn.Module):
def __init__(self):
super(MobileNetV1, self).__init__()
self.stage1 = nn.Sequential(
conv_bn(3, 8, 2, leaky = 0.1), # 3
conv_dw(8, 16, 1), # 7
conv_dw(16, 32, 2), # 11
conv_dw(32, 32, 1), # 19
conv_dw(32, 64, 2), # 27
conv_dw(64, 64, 1), # 43
)
self.stage2 = nn.Sequential(
conv_dw(64, 128, 2), # 43 + 16 = 59
conv_dw(128, 128, 1), # 59 + 32 = 91
conv_dw(128, 128, 1), # 91 + 32 = 123
conv_dw(128, 128, 1), # 123 + 32 = 155
conv_dw(128, 128, 1), # 155 + 32 = 187
conv_dw(128, 128, 1), # 187 + 32 = 219
)
self.stage3 = nn.Sequential(
conv_dw(128, 256, 2), # 219 +3 2 = 241
conv_dw(256, 256, 1), # 241 + 64 = 301
)
self.avg = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(256, 1000)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.avg(x)
# x = self.model(x)
x = x.view(-1, 256)
x = self.fc(x)
return x
7. 留坑¶
注意到论文里面还比较了一下在RetinaFace上加入ArcFace的实验结果,仍然还是有提升的,ArcFace我后面我会仔细讲讲,今天暂时讲到这里了,如果对你有帮助右下角点赞哦,谢谢。有问题请留言区交流哦。
8. 参考¶
- https://arxiv.org/pdf/1905.00641.pdf
- https://zhuanlan.zhihu.com/p/70834919
- https://www.cnblogs.com/ywheunji/p/12285421.html
- https://github.com/biubug6/Pytorch_Retinaface
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次