最近一些群友有询问我有没有哪些YOLO的算法推荐,考虑到现在Pytorch是做实验发论文最流行的深度学习框架,所以我就针对Pytorch实现的YOLO项目做了一个盘点和汇总,真心希望可以帮助到入门目标检测的同学。写作不易,要是觉得这篇文章有用就点个关注吧QAQ。
前言¶
这篇推文的目的是为了给目标检测领域的刚入门或者希望进一步提升自己的能力的同学做的一个YOLO项目推荐。推荐的项目都是当前流行,Star较高,用Pytorch框架实现的基于YOLO的检测项目,建议收藏和学习。
推荐项目¶
Pytorch-YOLOv3¶
- 项目地址:https://github.com/eriklindernoren/PyTorch-YOLOv3
- 项目特点:代码简洁,适合学习,最原始的YOLOV3实现,没有什么特殊Trick。
- 在COCO数据集上的mAP50测试结果如下:
| Model | mAP (min. 50 IoU) |
|---|---|
| YOLOv3 608 (paper) | 57.9 |
| YOLOv3 608 (this impl.) | 57.3 |
| YOLOv3 416 (paper) | 55.3 |
| YOLOv3 416 (this impl.) | 55.5 |
- 推理时间:
| Backbone | GPU | FPS |
|---|---|---|
| ResNet-101 | Titan X | 53 |
| ResNet-152 | Titan X | 37 |
| Darknet-53 (paper) | Titan X | 76 |
| Darknet-53 (this impl.) | 1080ti | 74 |
- 可视化效果:


- 总结:本项目适合刚学习目标检测的新手,可以快速上手,了解YOLOV3的原理,为进一步的实验和工作打下基础。
ultralytics-yolov3¶
- 项目地址:https://github.com/ultralytics/yolov3
- 项目特点:实现效果更好,适合工业应用。此项目,不仅仅实现了先进的数据增强方式如嵌入增强,还支持多种SOTA metric learning方式的回归损失如IOU Loss,GIOU Loss,DIOU Loss, CIOU Loss。另外在分类损失时也支持了Focal Loss来提升检测的敏感度。最后,此项目还支持了超参数进化机制,可以在你的数据上生成更好的的超参数,相当于有自动调参的功能,吸引力很强。
-
在COCO数据集上的mAP测试结果如下:
- mAP@0.5 run at
--iou-thr 0.5, mAP@0.5...0.95 run at--iou-thr 0.7 - Darknet results: https://arxiv.org/abs/1804.02767
- mAP@0.5 run at
| Size | COCO mAP @0.5...0.95 |
COCO mAP @0.5 |
|
|---|---|---|---|
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
320 | 14.0 28.7 30.5 36.3 |
29.1 51.8 52.3 55.5 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
416 | 16.0 31.2 33.9 39.8 |
33.0 55.4 56.9 59.6 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
512 | 16.6 32.7 35.6 41.3 |
34.9 57.7 59.5 61.3 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
608 | 16.6 33.1 37.0 41.7 |
35.4 58.2 60.7 61.5 |
- 在Google云上的速度测试:
https://cloud.google.com/deep-learning-vm/
Machine type: preemptible n1-standard-16 (16 vCPUs, 60 GB memory)
CPU platform: Intel Skylake
GPUs: K80 (0.20/hr), T4 (0.35/hr), V100 ($0.83/hr) CUDA with Nvidia Apex FP16/32
HDD: 1 TB SSD
Dataset: COCO train 2014 (117,263 images)
Model: yolov3-spp.cfg
Command: python3 train.py --img 416 --batch 32 --accum 2
| GPU | n | --batch --accum |
img/s | epoch time |
epoch cost |
|---|---|---|---|---|---|
| K80 | 1 | 32 x 2 | 11 | 175 min | $0.58 |
| T4 | 1 2 |
32 x 2 64 x 1 |
41 61 |
48 min 32 min |
0.28<br>0.36 |
| V100 | 1 2 |
32 x 2 64 x 1 |
122 178 |
16 min 11 min |
**0.23**<br>0.31 |
| 2080Ti | 1 2 |
32 x 2 64 x 1 |
81 140 |
24 min 14 min |
- - |
- 可视化:



-
总结:本项目不仅适合写论文做实验,还适合工业级应用,并且本工程还支持了Pytorch模型和DarkNet模型互转,以及导出Onnx通过移动端框架部署,作者也提供了通过CoreML在IOS端进行部署的例子。这一项目也是Pytorch YOLO实现中最流行的项目,推荐使用。
-
题外话:本公众号针对这一框架也做了多期使用和原理解读的高质量文章,推荐大家阅读:
- 【从零开始学习YOLOv3】2. YOLOv3中的代码配置和数据集构建
- 【从零开始学习YOLOv3】3. YOLOv3的数据加载机制和增强方法
- 【从零开始学习YOLOv3】4. YOLOv3中的参数进化
- 【从零开始学习YOLOv3】5. 网络模型的构建
- 【从零开始学习YOLOv3】6. 模型构建中的YOLOLayer
- 【从零开始学习YOLOv3】7. 教你在YOLOv3模型中添加Attention机制
YOLOv3-model-pruning¶
- 项目地址:https://github.com/Lam1360/YOLOv3-model-pruning
- 项目特点:用 YOLOv3 模型在一个开源的人手检测数据集 oxford hand 上做人手检测,并在此基础上做模型剪枝。对于该数据集,对 YOLOv3 进行 channel pruning 之后,模型的参数量、模型大小减少 80% ,FLOPs 降低 70%,前向推断的速度可以达到原来的 200%,同时可以保持 mAP 基本不变。
- 原理简介:这个代码基于论文 ICLR 2017《Pruning Filters for Efficient ConvNets》 进行改进实现的 channel pruning算法,类似的代码实现还有这个 yolov3-network-slimming(地址:https://github.com/talebolano/yolov3-network-slimming)。原始论文中的算法是针对分类模型的,基于 BN 层的 gamma 系数进行剪枝的。剪枝步骤就是稀疏训练->剪枝->微调。
- 剪枝结果:
下面是对部分卷积层进行剪枝前后通道数的变化:
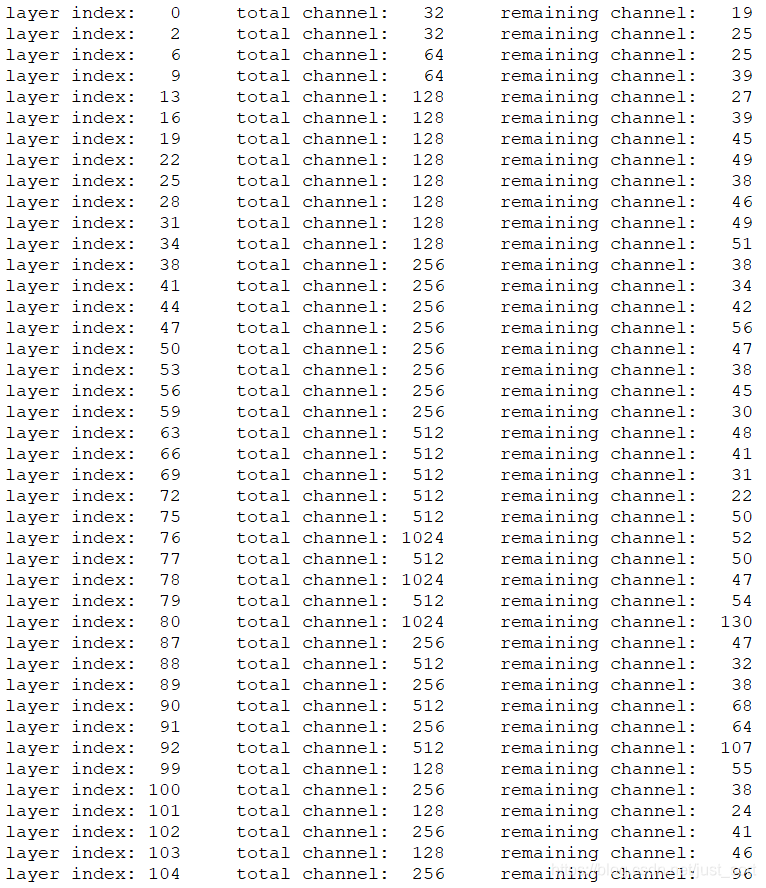
剪枝前后指标对比:
| 参数数量 | 模型体积 | Flops | 前向推断耗时(2070 TI) | mAP | |
|---|---|---|---|---|---|
| Baseline (416) | 61.5M | 246.4MB | 32.8B | 15.0 ms | 0.7692 |
| Prune (416) | 10.9M | 43.6MB | 9.6B | 7.7 ms | 0.7722 |
| Finetune (416) | 同上 | 同上 | 同上 | 同上 | 0.7750 |
加入稀疏正则项之后,mAP 反而更高了(在实验过程中发现,其实 mAP上下波动 0.02 是正常现象),因此可以认为稀疏训练得到的 mAP 与正常训练几乎一致。将 prune 后得到的模型进行 finetune 并没有明显的提升,因此剪枝三步可以直接简化成两步。剪枝前后模型的参数量、模型大小降为原来的 ⅙ ,FLOPs 降为原来的 ⅓,前向推断的速度可以达到原来的 2 倍,同时可以保持 mAP 基本不变。需要明确的是,上面表格中剪枝的效果是只是针对该数据集的,不一定能保证在其他数据集上也有同样的效果。
- 总结:这个剪枝项目是可以在工程中进行应用的,在这之前如果你想学习这个算法的原理,那么推荐看我写的这篇:深度学习算法优化系列八 | VGG,ResNet,DenseNe模型剪枝代码实战
Slim YOLOV3¶
- 项目地址:https://github.com/PengyiZhang/SlimYOLOv3
- 项目特点:《SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications》是arXiv, 25 Jul 2019的论文,作者全部来自北理,论文链接:arxiv.org/abs/1907.1109。作者对YOLOv3的卷积层通道剪枝(以通道级稀疏化),大幅削减了模型的计算量(~90.8% decrease of FLOPs)和参数量( ~92.0% decline of parameter size),剪枝后的模型运行速度约为原来的两倍,并基本保持了原模型的检测精度。
- 原理介绍:这篇论文基本上就是ICLR 2017《Pruning Filters for Efficient ConvNets》 这篇论文在YOLOV3-SPP上的一个应用。原理可以用下图解释:
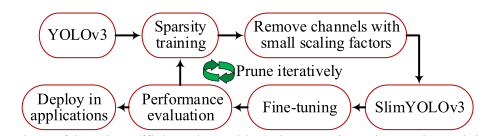 - 算法结果:
- 算法结果:
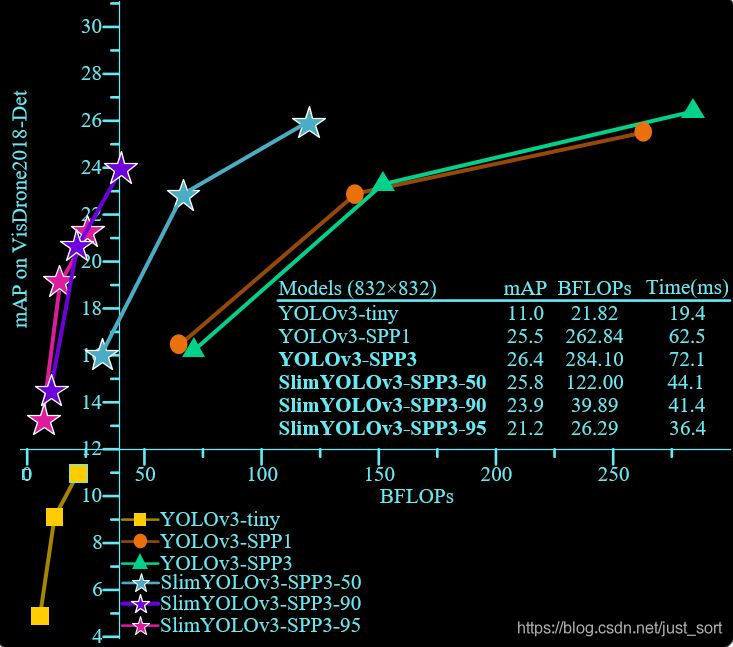
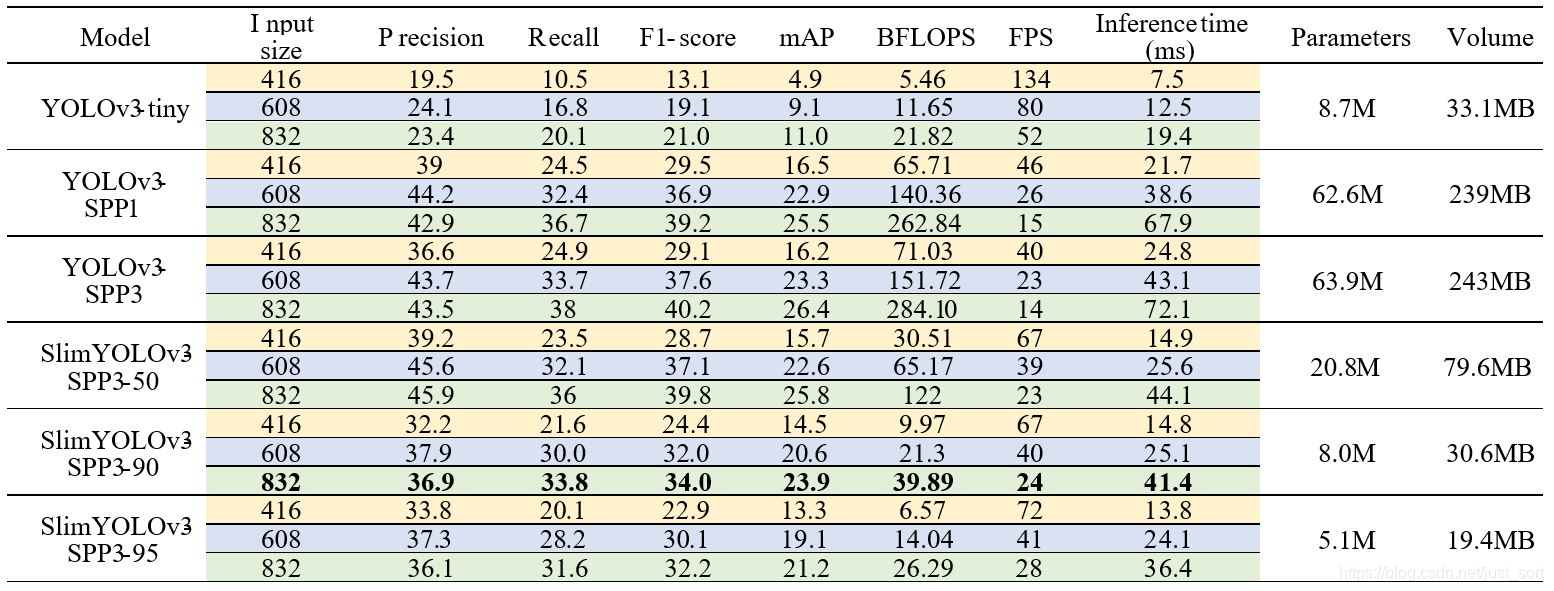
- 论文展示效果:

- 总结:说白了这篇论文就是剪枝算法在YOLOV3-SPP上的应用,技术含量其实也就那样。。。但是新手的话还是推荐大家来学习一下。
Anchor聚类 kmeans-anchor-boxes¶
- 项目地址:https://github.com/lars76/kmeans-anchor-boxes
- 项目特点:针对自己的数据集聚类出最适配的Anchor,可以加快收敛速度并有可能提升模型效果。
- 原理介绍:我之前写了一篇推文仔细的讲解这个,地址如下:目标检测算法之YOLO系列算法的Anchor聚类代码实战
- 在VOC 2007数据集上获得的算法结果:

在结果测试时,YOLOv2采用的5种Anchor可以达到的Avg IOU是61,而Faster-RCNN采用9种Anchor达到的平均IOU是60.9,也即是说本文仅仅选取5种Anchor就可以达到Faster-RCNN中9种Anchor的效果。
ASFF¶
- 论文地址:https://arxiv.org/abs/1911.09516
- 项目地址:https://github.com/ruinmessi/ASFF
- 项目特点:超强Tricks!
-
贡献:这篇论文最大的创新点是提出了一种新的特征融合的方式ASFF,通过学习权重参数的方式将不同层的特征融合到一起,作者证明了这样的方法要优于通过concatenation或者element-wise的方式。不仅如此,作者还在YOLOv3的基础上吸取了很多优秀的经验,构建了一个非常强劲的目标检测baseline,这个baseline的mAP就达到了38(之前的YOLOV3mAP值是33%左右,ORZ),其中包括:
- Guided Anchoring
- Bags of Tricks
- Additional IoU loss
-
算法原理:这里不多介绍,之后会专门写一篇文章介绍一下,这里看一下论文的核心原理图:
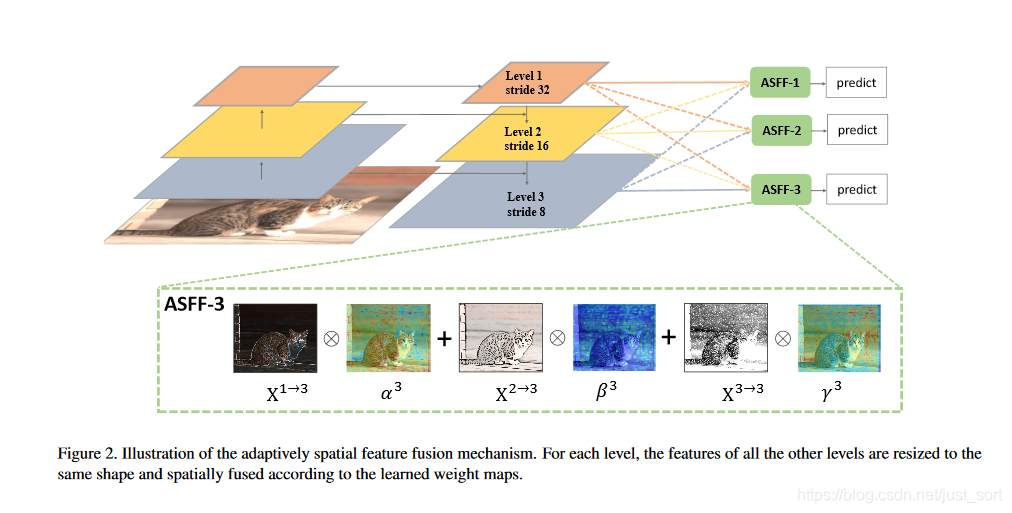
- 算法结果:
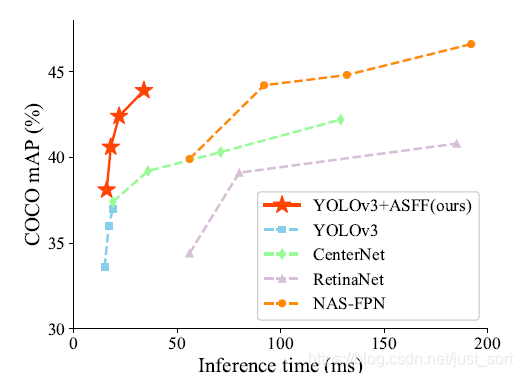
在COCO数据集的精度测试。
| System | test-dev mAP | Time (V100) | Time (2080ti) |
|---|---|---|---|
| YOLOv3 608 | 33.0 | 20ms | 26ms |
| YOLOv3 608+ BoFs | 37.0 | 20ms | 26ms |
| YOLOv3 608 (our baseline) | 38.8 | 20ms | 26ms |
| YOLOv3 608+ ASFF | 40.6 | 22ms | 30ms |
| YOLOv3 608+ ASFF* | 42.4 | 22ms | 30ms |
| YOLOv3 800+ ASFF* | 43.9 | 34ms | 38ms |
| YOLOv3 MobileNetV1 416 + BoFs | 28.6 | - | 22 ms |
| YOLOv3 MobileNetV2 416 (our baseline) | 29.0 | - | 22 ms |
| YOLOv3 MobileNetV2 416 +ASFF | 30.6 | - | 24 ms |
- 总结:ASPP这篇论文可以算是集百家之长,并且ASPP创新点也是拉满,让我第一次知道空间信息的叠加也是可学习的,结果也非常惊艳,推荐大家学习。
yolov3-channel-and-layer-pruning¶
- 项目地址:https://github.com/tanluren/yolov3-channel-and-layer-pruning
- 项目特点: 本项目以ultralytics/yolov3为基础实现,根据论文Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017)原理基于bn层Gmma系数进行通道剪枝,下面引用了几种不同的通道剪枝策略,并对原策略进行了改进,提高了剪枝率和精度;在这些工作基础上,又衍生出了层剪枝,本身通道剪枝已经大大减小了模型参数和计算量,降低了模型对资源的占用,而层剪枝可以进一步减小了计算量,并大大提高了模型推理速度;通过层剪枝和通道剪枝结合,可以压缩模型的深度和宽度,某种意义上实现了针对不同数据集的小模型搜索。此外,除了剪枝作者进一步在YOLOV3中使用了知识蒸馏策略,进一步压缩模型,具体请看原项目。这是国内的检测大佬维护的开源项目,也可以加入到他们的讨论群去讨论。
YOLO-Lite¶
- 论文原文:https://arxiv.org/pdf/1811.05588.pdf
- 项目地址:https://github.com/reu2018DL/YOLO-LITE
- 项目特点:论文致力于设计一个网络(cpu速度大于10FPS,PASCAL VOC精度大于30%),因此基于YOLO-v2,提出了一个cpu端的或者端侧的实时检测框架YOLO-LITE。在PASCAL VOC 上取得了33.81%的map,在COCO上取得了12.26%的map,实时性达到了21FPS。
- 算法原理:作者在论文里面主要证明了两点,一是浅层网络(shallow networks)的对于非GPU快速目标检测应用的能力;二是,证明BN层对于shallow networks是不必要的。
- 精度和推理时间展示:
| DataSet | mAP | FPS |
|---|---|---|
| PASCAL VOC | 33.57 | 21 |
| COCO | 12.26 | 21 |
- 效果展示:

- 总结:精度很低,不过对于网络修改和模型加速有一定的参考价值。
YOLO Nano¶
- 论文地址:https://arxiv.org/abs/1910.01271
- 项目地址:https://github.com/liux0614/yolo_nano
-
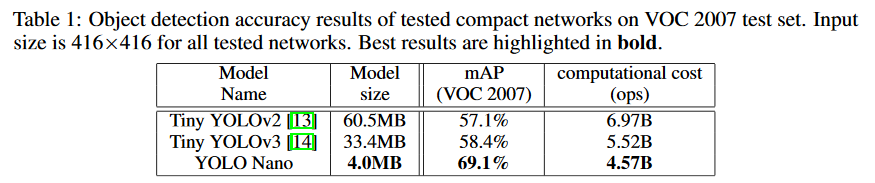
项目特点:来自滑铁卢大学与 Darwin AI 的研究者提出了名为 YOLO Nano 的网络,他们通过人与机器协同设计模型架构大大提升了性能。YOLO Nano 大小只有 4.0MB 左右,比 Tiny YOLOv2 和 Tiny YOLOv3 分别小了 15.1 倍和 8.3 倍,在计算上需要 4.57B 次推断运算,比后两个网络分别少了 34% 和 17%,在性能表现上,在 VOC2007 数据集取得了 69.1% 的 mAP,准确率比后两者分别提升了 12 个点和 10.7 个点。值得一提的是4M是int8量化后的大小。
-
精度和推理时间展示:
- 网络结构:
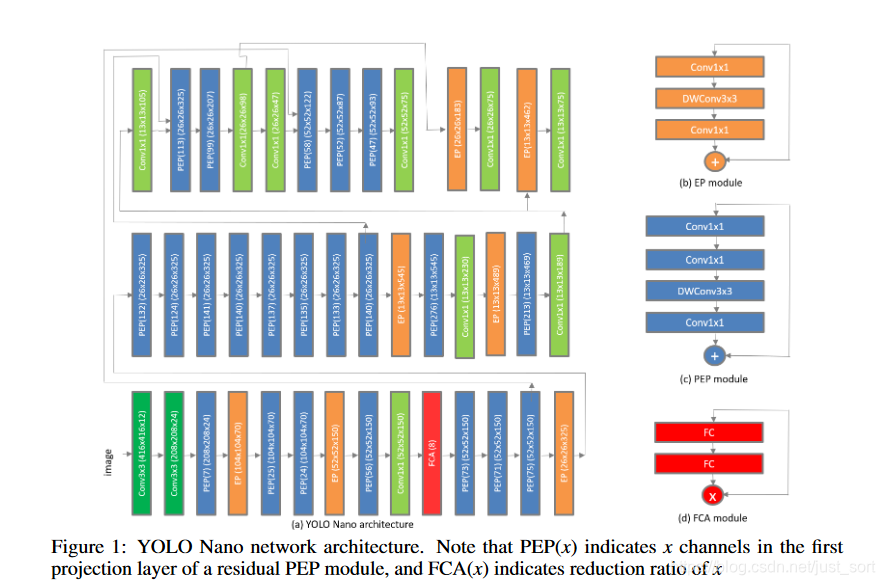 - 总结:这个开源工程并不是作者公开的,论文中的信息也不足以支撑实现代码的开发以及效果的复现,不过PEP和FCA模块可以作为我们设计网络去借鉴的思路。
- 总结:这个开源工程并不是作者公开的,论文中的信息也不足以支撑实现代码的开发以及效果的复现,不过PEP和FCA模块可以作为我们设计网络去借鉴的思路。
附录¶
- YOLOV3 608:http://pjreddie.com/darknet/yolo/
- Bag of Freebies for Training Object Detection Neural Networks : https://arxiv.org/abs/1902.04103
后记¶
好了,上面推荐的项目基本就是我入门目标检测一起调研到的Pytorch 实现的以YOLO为BaseLine的最值得收藏和学习的项目了,希望对大家有帮助。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次