Deep SORT多目标跟踪算法代码解析(下)¶
Deep SORT是多目标跟踪(Multi-Object Tracking)中常用到的一种算法,是一个Detection Based Tracking的方法。这个算法工业界关注度非常高,在知乎上有很多文章都是使用了Deep SORT进行工程部署。笔者将参考前辈的博客,结合自己的实践(理论&代码)对Deep SORT算法进行代码层面的解析。
在之前笔者写的一篇Deep SORT论文阅读总结中,总结了DeepSORT论文中提到的核心观点,如果对Deep SORT不是很熟悉,可以先理解一下,然后再来看解读代码的部分。
由于知乎对文章篇幅有限制,所以分上下篇发。
上篇将梳理SORT、Deep SORT,讲解DeepSORT代码部分的各个模块,以类图为主。
下篇主要是梳理运行的流程,对照流程图进行代码层面理解。以及最后的总结+代码推荐。
5. 流程解析¶
流程部分主要按照以下流程图来走一遍:
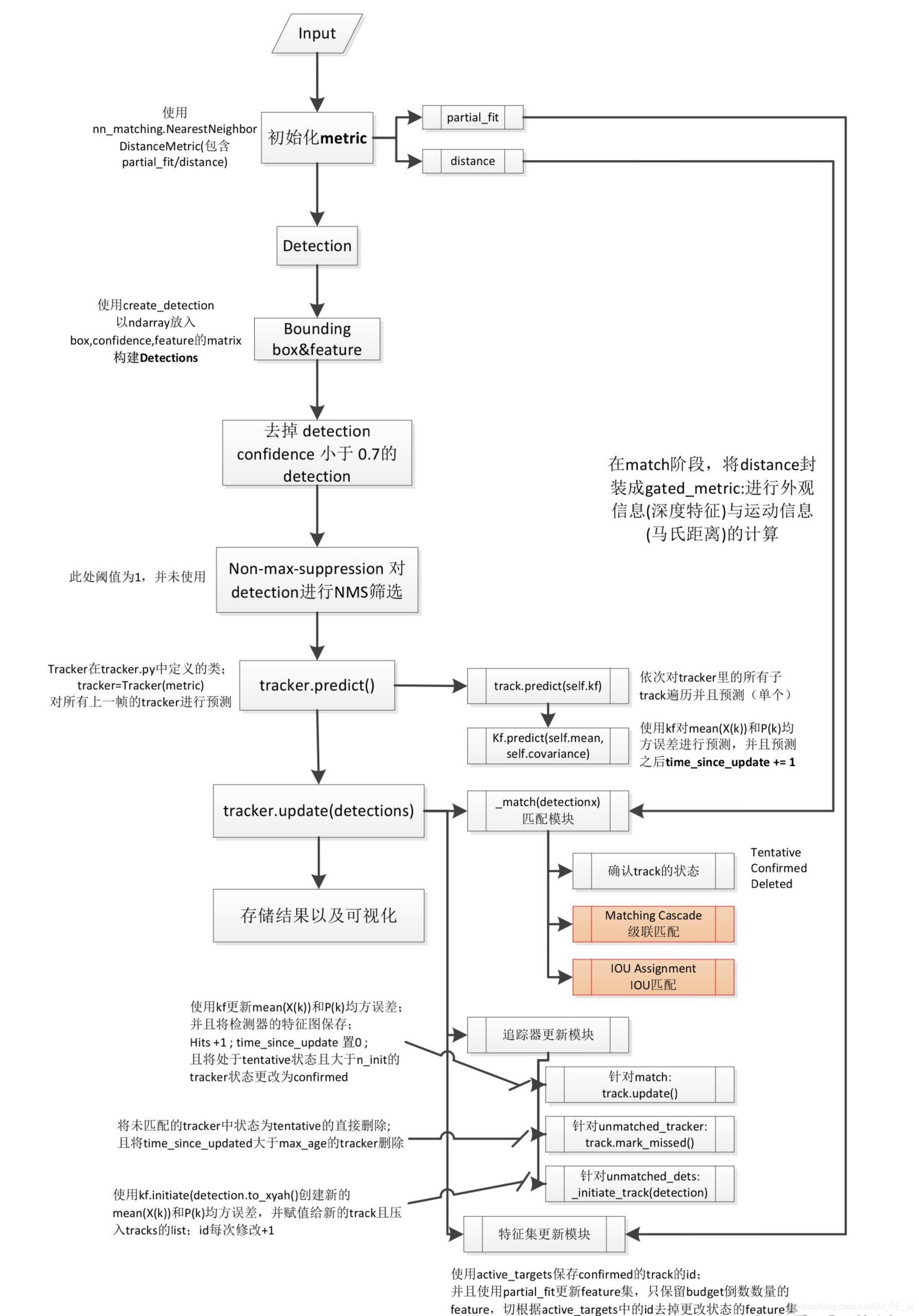
感谢知乎@猫弟总结的流程图,讲解非常地清晰,如果单纯看代码,非常容易混淆。比如说代价矩阵的计算这部分,连续套了三个函数,才被真正调用。上图将整体流程总结地非常棒。笔者将参考以上流程结合代码进行梳理:
1. 分析detector类中的Deep SORT调用:
class Detector(object):
def __init__(self, args):
self.args = args
if args.display:
cv2.namedWindow("test", cv2.WINDOW_NORMAL)
cv2.resizeWindow("test", args.display_width, args.display_height)
device = torch.device(
'cuda') if torch.cuda.is_available() else torch.device('cpu')
self.vdo = cv2.VideoCapture()
self.yolo3 = InferYOLOv3(args.yolo_cfg,
args.img_size,
args.yolo_weights,
args.data_cfg,
device,
conf_thres=args.conf_thresh,
nms_thres=args.nms_thresh)
self.deepsort = DeepSort(args.deepsort_checkpoint)
初始化DeepSORT对象,更新部分接收目标检测得到的框的位置,置信度和图片:
outputs = self.deepsort.update(bbox_xcycwh, cls_conf, im)
2. 顺着DeepSORT类的update函数看
class DeepSort(object):
def __init__(self, model_path, max_dist=0.2):
self.min_confidence = 0.3
# yolov3中检测结果置信度阈值,筛选置信度小于0.3的detection。
self.nms_max_overlap = 1.0
# 非极大抑制阈值,设置为1代表不进行抑制
# 用于提取图片的embedding,返回的是一个batch图片对应的特征
self.extractor = Extractor("resnet18",
model_path,
use_cuda=True)
max_cosine_distance = max_dist
# 用在级联匹配的地方,如果大于改阈值,就直接忽略
nn_budget = 100
# 预算,每个类别最多的样本个数,如果超过,删除旧的
# 第一个参数可选'cosine' or 'euclidean'
metric = NearestNeighborDistanceMetric("cosine",
max_cosine_distance,
nn_budget)
self.tracker = Tracker(metric)
def update(self, bbox_xywh, confidences, ori_img):
self.height, self.width = ori_img.shape[:2]
# generate detections
features = self._get_features(bbox_xywh, ori_img)
# 从原图中crop bbox对应图片并计算得到embedding
bbox_tlwh = self._xywh_to_tlwh(bbox_xywh)
detections = [
Detection(bbox_tlwh[i], conf, features[i])
for i, conf in enumerate(confidences) if conf > self.min_confidence
] # 筛选小于min_confidence的目标,并构造一个Detection对象构成的列表
# Detection是一个存储图中一个bbox结果
# 需要:1. bbox(tlwh形式) 2. 对应置信度 3. 对应embedding
# run on non-maximum supression
boxes = np.array([d.tlwh for d in detections])
scores = np.array([d.confidence for d in detections])
# 使用非极大抑制
# 默认nms_thres=1的时候开启也没有用,实际上并没有进行非极大抑制
indices = non_max_suppression(boxes, self.nms_max_overlap, scores)
detections = [detections[i] for i in indices]
# update tracker
# tracker给出一个预测结果,然后将detection传入,进行卡尔曼滤波操作
self.tracker.predict()
self.tracker.update(detections)
# output bbox identities
# 存储结果以及可视化
outputs = []
for track in self.tracker.tracks:
if not track.is_confirmed() or track.time_since_update > 1:
continue
box = track.to_tlwh()
x1, y1, x2, y2 = self._tlwh_to_xyxy(box)
track_id = track.track_id
outputs.append(np.array([x1, y1, x2, y2, track_id], dtype=np.int))
if len(outputs) > 0:
outputs = np.stack(outputs, axis=0)
return np.array(outputs)
从这里开始对照以上流程图会更加清晰。在Deep SORT初始化的过程中有一个核心metric,NearestNeighborDistanceMetric类会在匹配和特征集更新的时候用到。
梳理DeepSORT的update流程:
-
根据传入的参数(bbox_xywh, conf, img)使用ReID模型提取对应bbox的表观特征。
-
构建detections的列表,列表中的内容就是Detection类,在此处限制了bbox的最小置信度。
- 使用非极大抑制算法,由于默认nms_thres=1,实际上并没有用。
- Tracker类进行一次预测,然后将detections传入,进行更新。
- 最后将Tracker中保存的轨迹中状态属于确认态的轨迹返回。
以上核心在Tracker的predict和update函数,接着梳理。
3. Tracker的predict函数
Tracker是一个多目标跟踪器,保存了很多个track轨迹,负责调用卡尔曼滤波来预测track的新状态+进行匹配工作+初始化第一帧。Tracker调用update或predict的时候,其中的每个track也会各自调用自己的update或predict
class Tracker:
def __init__(self, metric, max_iou_distance=0.7, max_age=70, n_init=3):
# 调用的时候,后边的参数全部是默认的
self.metric = metric
self.max_iou_distance = max_iou_distance
# 最大iou,iou匹配的时候使用
self.max_age = max_age
# 直接指定级联匹配的cascade_depth参数
self.n_init = n_init
# n_init代表需要n_init次数的update才会将track状态设置为confirmed
self.kf = kalman_filter.KalmanFilter() # 卡尔曼滤波器
self.tracks = [] # 保存一系列轨迹
self._next_id = 1 # 下一个分配的轨迹id
def predict(self):
# 遍历每个track都进行一次预测
"""Propagate track state distributions one time step forward.
This function should be called once every time step, before `update`.
"""
for track in self.tracks:
track.predict(self.kf)
predict主要是对轨迹列表中所有的轨迹使用卡尔曼滤波算法进行状态的预测。
4. Tracker的更新
Tracker的更新属于最核心的部分。
def update(self, detections):
# 进行测量的更新和轨迹管理
"""Perform measurement update and track management.
Parameters
----------
detections : List[deep_sort.detection.Detection]
A list of detections at the current time step.
"""
# Run matching cascade.
matches, unmatched_tracks, unmatched_detections = \
self._match(detections)
# Update track set.
# 1. 针对匹配上的结果
for track_idx, detection_idx in matches:
# track更新对应的detection
self.tracks[track_idx].update(self.kf, detections[detection_idx])
# 2. 针对未匹配的tracker,调用mark_missed标记
# track失配,若待定则删除,若update时间很久也删除
# max age是一个存活期限,默认为70帧
for track_idx in unmatched_tracks:
self.tracks[track_idx].mark_missed()
# 3. 针对未匹配的detection, detection失配,进行初始化
for detection_idx in unmatched_detections:
self._initiate_track(detections[detection_idx])
# 得到最新的tracks列表,保存的是标记为confirmed和Tentative的track
self.tracks = [t for t in self.tracks if not t.is_deleted()]
# Update distance metric.
active_targets = [t.track_id for t in self.tracks if t.is_confirmed()]
# 获取所有confirmed状态的track id
features, targets = [], []
for track in self.tracks:
if not track.is_confirmed():
continue
features += track.features # 将tracks列表拼接到features列表
# 获取每个feature对应的track id
targets += [track.track_id for _ in track.features]
track.features = []
# 距离度量中的 特征集更新
self.metric.partial_fit(np.asarray(features), np.asarray(targets),active_targets)
这部分注释已经很详细了,主要是一些后处理代码,需要关注的是对匹配上的,未匹配的Detection,未匹配的Track三者进行的处理以及最后进行特征集更新部分,可以对照流程图梳理。
Tracker的update函数的核心函数是match函数,描述如何进行匹配的流程:
def _match(self, detections):
# 主要功能是进行匹配,找到匹配的,未匹配的部分
def gated_metric(tracks, dets, track_indices, detection_indices):
# 功能: 用于计算track和detection之间的距离,代价函数
# 需要使用在KM算法之前
# 调用:
# cost_matrix = distance_metric(tracks, detections,
# track_indices, detection_indices)
features = np.array([dets[i].feature for i in detection_indices])
targets = np.array([tracks[i].track_id for i in track_indices])
# 1. 通过最近邻计算出代价矩阵 cosine distance
cost_matrix = self.metric.distance(features, targets)
# 2. 计算马氏距离,得到新的状态矩阵
cost_matrix = linear_assignment.gate_cost_matrix(
self.kf, cost_matrix, tracks, dets, track_indices,
detection_indices)
return cost_matrix
# Split track set into confirmed and unconfirmed tracks.
# 划分不同轨迹的状态
confirmed_tracks = [
i for i, t in enumerate(self.tracks) if t.is_confirmed()
]
unconfirmed_tracks = [
i for i, t in enumerate(self.tracks) if not t.is_confirmed()
]
# 进行级联匹配,得到匹配的track、不匹配的track、不匹配的detection
'''
!!!!!!!!!!!
级联匹配
!!!!!!!!!!!
'''
# gated_metric->cosine distance
# 仅仅对确定态的轨迹进行级联匹配
matches_a, unmatched_tracks_a, unmatched_detections = \
linear_assignment.matching_cascade(
gated_metric,
self.metric.matching_threshold,
self.max_age,
self.tracks,
detections,
confirmed_tracks)
# 将所有状态为未确定态的轨迹和刚刚没有匹配上的轨迹组合为iou_track_candidates,
# 进行IoU的匹配
iou_track_candidates = unconfirmed_tracks + [
k for k in unmatched_tracks_a
if self.tracks[k].time_since_update == 1 # 刚刚没有匹配上
]
# 未匹配
unmatched_tracks_a = [
k for k in unmatched_tracks_a
if self.tracks[k].time_since_update != 1 # 已经很久没有匹配上
]
'''
!!!!!!!!!!!
IOU 匹配
对级联匹配中还没有匹配成功的目标再进行IoU匹配
!!!!!!!!!!!
'''
# 虽然和级联匹配中使用的都是min_cost_matching作为核心,
# 这里使用的metric是iou cost和以上不同
matches_b, unmatched_tracks_b, unmatched_detections = \
linear_assignment.min_cost_matching(
iou_matching.iou_cost,
self.max_iou_distance,
self.tracks,
detections,
iou_track_candidates,
unmatched_detections)
matches = matches_a + matches_b # 组合两部分match得到的结果
unmatched_tracks = list(set(unmatched_tracks_a + unmatched_tracks_b))
return matches, unmatched_tracks, unmatched_detections
对照下图来看会顺畅很多:
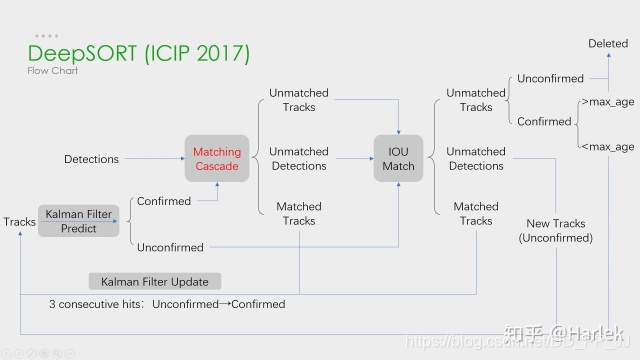
可以看到,匹配函数的核心是级联匹配+IOU匹配,先来看看级联匹配:
调用在这里:
matches_a, unmatched_tracks_a, unmatched_detections = \
linear_assignment.matching_cascade(
gated_metric,
self.metric.matching_threshold,
self.max_age,
self.tracks,
detections,
confirmed_tracks)
级联匹配函数展开:
def matching_cascade(
distance_metric, max_distance, cascade_depth, tracks, detections,
track_indices=None, detection_indices=None):
# 级联匹配
# 1. 分配track_indices和detection_indices
if track_indices is None:
track_indices = list(range(len(tracks)))
if detection_indices is None:
detection_indices = list(range(len(detections)))
unmatched_detections = detection_indices
matches = []
# cascade depth = max age 默认为70
for level in range(cascade_depth):
if len(unmatched_detections) == 0: # No detections left
break
track_indices_l = [
k for k in track_indices
if tracks[k].time_since_update == 1 + level
]
if len(track_indices_l) == 0: # Nothing to match at this level
continue
# 2. 级联匹配核心内容就是这个函数
matches_l, _, unmatched_detections = \
min_cost_matching( # max_distance=0.2
distance_metric, max_distance, tracks, detections,
track_indices_l, unmatched_detections)
matches += matches_l
unmatched_tracks = list(set(track_indices) - set(k for k, _ in matches))
return matches, unmatched_tracks, unmatched_detections
可以看到和伪代码是一致的,文章上半部分也有提到这部分代码。这部分代码中还有一个核心的函数min_cost_matching,这个函数可以接收不同的distance_metric,在级联匹配和IoU匹配中都有用到。
min_cost_matching函数:
def min_cost_matching(
distance_metric, max_distance, tracks, detections, track_indices=None,
detection_indices=None):
if track_indices is None:
track_indices = np.arange(len(tracks))
if detection_indices is None:
detection_indices = np.arange(len(detections))
if len(detection_indices) == 0 or len(track_indices) == 0:
return [], track_indices, detection_indices # Nothing to match.
# -----------------------------------------
# Gated_distance——>
# 1. cosine distance
# 2. 马氏距离
# 得到代价矩阵
# -----------------------------------------
# iou_cost——>
# 仅仅计算track和detection之间的iou距离
# -----------------------------------------
cost_matrix = distance_metric(
tracks, detections, track_indices, detection_indices)
# -----------------------------------------
# gated_distance中设置距离中最高上限,
# 这里最远距离实际是在deep sort类中的max_dist参数设置的
# 默认max_dist=0.2, 距离越小越好
# -----------------------------------------
# iou_cost情况下,max_distance的设置对应tracker中的max_iou_distance,
# 默认值为max_iou_distance=0.7
# 注意结果是1-iou,所以越小越好
# -----------------------------------------
cost_matrix[cost_matrix > max_distance] = max_distance + 1e-5
# 匈牙利算法或者KM算法
row_indices, col_indices = linear_assignment(cost_matrix)
matches, unmatched_tracks, unmatched_detections = [], [], []
# 这几个for循环用于对匹配结果进行筛选,得到匹配和未匹配的结果
for col, detection_idx in enumerate(detection_indices):
if col not in col_indices:
unmatched_detections.append(detection_idx)
for row, track_idx in enumerate(track_indices):
if row not in row_indices:
unmatched_tracks.append(track_idx)
for row, col in zip(row_indices, col_indices):
track_idx = track_indices[row]
detection_idx = detection_indices[col]
if cost_matrix[row, col] > max_distance:
unmatched_tracks.append(track_idx)
unmatched_detections.append(detection_idx)
else:
matches.append((track_idx, detection_idx))
# 得到匹配,未匹配轨迹,未匹配检测
return matches, unmatched_tracks, unmatched_detections
注释中提到distance_metric是有两个的:
- 第一个是级联匹配中传入的distance_metric是gated_metric, 其内部核心是计算的表观特征的级联匹配。
def gated_metric(tracks, dets, track_indices, detection_indices):
# 功能: 用于计算track和detection之间的距离,代价函数
# 需要使用在KM算法之前
# 调用:
# cost_matrix = distance_metric(tracks, detections,
# track_indices, detection_indices)
features = np.array([dets[i].feature for i in detection_indices])
targets = np.array([tracks[i].track_id for i in track_indices])
# 1. 通过最近邻计算出代价矩阵 cosine distance
cost_matrix = self.metric.distance(features, targets)
# 2. 计算马氏距离,得到新的状态矩阵
cost_matrix = linear_assignment.gate_cost_matrix(
self.kf, cost_matrix, tracks, dets, track_indices,
detection_indices)
return cost_matrix
对应下图进行理解(下图上半部分就是对应的gated_metric函数):
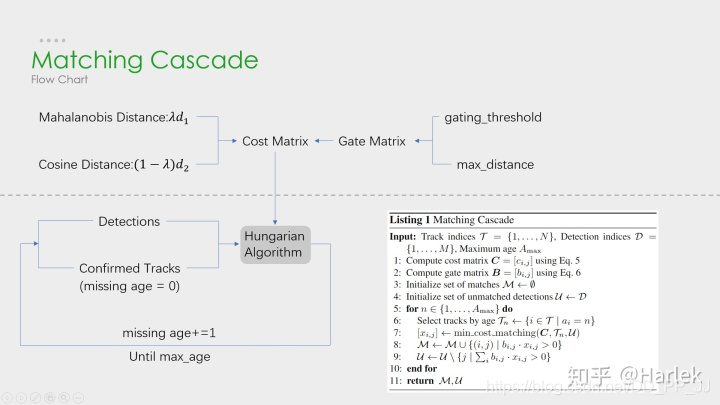
- 第二个是IOU匹配中的iou_matching.iou_cost:
# 虽然和级联匹配中使用的都是min_cost_matching作为核心,
# 这里使用的metric是iou cost和以上不同
matches_b, unmatched_tracks_b, unmatched_detections = \
linear_assignment.min_cost_matching(
iou_matching.iou_cost,
self.max_iou_distance,
self.tracks,
detections,
iou_track_candidates,
unmatched_detections)
iou_cost代价很容易理解,用于计算Track和Detection之间的IOU距离矩阵。
def iou_cost(tracks, detections, track_indices=None,
detection_indices=None):
# 计算track和detection之间的iou距离矩阵
if track_indices is None:
track_indices = np.arange(len(tracks))
if detection_indices is None:
detection_indices = np.arange(len(detections))
cost_matrix = np.zeros((len(track_indices), len(detection_indices)))
for row, track_idx in enumerate(track_indices):
if tracks[track_idx].time_since_update > 1:
cost_matrix[row, :] = linear_assignment.INFTY_COST
continue
bbox = tracks[track_idx].to_tlwh()
candidates = np.asarray(
[detections[i].tlwh for i in detection_indices])
cost_matrix[row, :] = 1. - iou(bbox, candidates)
return cost_matrix
6. 总结¶
以上就是Deep SORT算法代码部分的解析,核心在于类图和流程图,理解Deep SORT实现的过程。
如果第一次接触到多目标跟踪算法领域的,可以到知乎上看这篇文章以及其系列,对新手非常友好: https://zhuanlan.zhihu.com/p/62827974
笔者也收集了一些多目标跟踪领域中认可度比较高、常见的库,在这里分享给大家:
-
SORT官方代码: https://github.com/abewley/sort
-
DeepSORT官方代码: https://github.com/nwojke/deep_sort
-
奇点大佬keras实现DeepSORT: https://github.com/Qidian213/deep_sort_yolov3
-
CenterNet作检测器的DeepSORT: https://github.com/xingyizhou/CenterTrack 和 https://github.com/kimyoon-young/centerNet-deep-sort
-
JDE Github地址: https://github.com/Zhongdao/Towards-Realtime-MOT
-
FairMOT Github地址: https://github.com/ifzhang/FairMOT
- 笔者修改的代码: https://github.com/pprp/deep_sort_yolov3_pytorch
笔者也是最近一段时间接触目标跟踪领域,数学水平非常有限(卡尔曼滤波只能肤浅了解大概过程,但是还不会推导)。本文目标就是帮助新入门多目标跟踪的新人快速了解Deep SORT流程,由于自身水平有限,也欢迎大佬对文中不足之处进行指点一二。
7. 参考¶
https://arxiv.org/abs/1703.07402
https://github.com/pprp/deep_sort_yolov3_pytorch
https://www.cnblogs.com/yanwei-li/p/8643446.html
https://zhuanlan.zhihu.com/p/97449724
https://zhuanlan.zhihu.com/p/80764724
https://zhuanlan.zhihu.com/p/90835266
https://zhuanlan.zhihu.com/p/113685503
本文总阅读量次