前言¶
之前已经讲了一些目标检测原理性的东西了,今天讲一个偏工程一点的东西,就是如何在使用YOLO算法的时候针对自己的数据集获得合适的Anchor?
原理¶
Anchor如何获得?¶
如何获得Anchor的算法在前面讲解YOLOv2原理的时候已经说清楚了,推文地址如下:https://mp.weixin.qq.com/s/4PPhCpdna4AWgbEWhunNTQ 。我们再复习一下Anchor的获得策略。
在Faster-RCNN中,Anchor都是手动设定的,YOLOv2使用k-means聚类算法对训练集中的边界框做了聚类分析,尝试找到合适尺寸的Anchor。另外作者发现如果采用标准的k-means聚类,在box的尺寸比较大的时候其误差也更大,而我们希望的是误差和box的尺寸没有太大关系。所以通过IOU定义了如下的距离函数,使得误差和box的大小无关: d(box,centroid)=1-IOU(box,centroid)
Fig2展示了聚类的簇的个数和IOU之间的关系,两条曲线分别代表了VOC和COCO数据集的测试结果。最后结合不同的K值对召回率的影响,论文选择了K=5,Figure2中右边的示意图是选出来的5个box的大小,这里紫色和黑色也是分别表示两个不同的数据集,可以看出其基本形状是类似的。而且发现聚类的结果和手动设置的anchor box大小差别显著。聚类的结果中多是高瘦的box,而矮胖的box数量较少,这也比较符合数据集中目标的视觉效果。
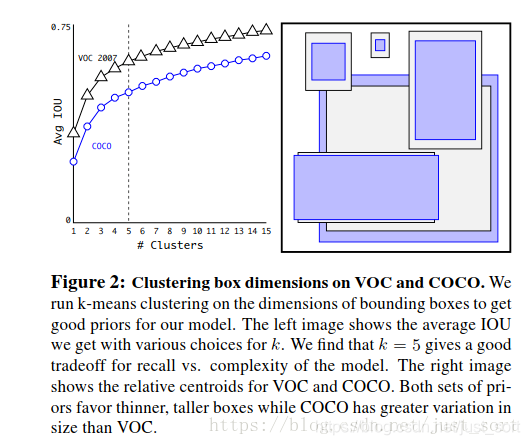
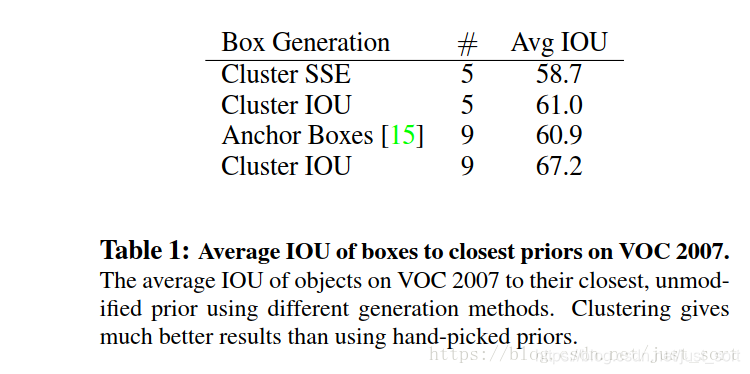
在结果测试时,YOLOv2采用的5种Anchor可以达到的Avg IOU是61,而Faster-RCNN采用9种Anchor达到的平均IOU是60.9,也即是说本文仅仅选取5种Anchor就可以达到Faster-RCNN中9种Anchor的效果。如Table1所示:
K-means聚类¶
聚类指的是把集合,分组成多个类,每个类中的对象都是彼此相似的。K-means是聚类中最常用的方法之一,它是基于点与点距离的相似度来计算最佳类别归属。在使用该方法前,要注意: - 对数据异常值的处理 - 对数据标准化处理(x-min(x))/(max(x)-min(x)) - 每一个类别的数量要大体均等 - 不同类别间的特质值应该差异较大
在这里倒是没有严格的去执行上面的步骤,直接按照k-means的算法步骤执行即可。k-means聚类的算法运行过程可以总结如下:
(1)选择k个初始聚类中心
(2)计算每个对象与这k个中心各自的距离,按照最小距离原则分配到最邻近聚类
(3)使用每个聚类中的样本均值作为新的聚类中心
(4)重复步骤(2)和(3)直到聚类中心不再变化
(5)结束,得到k个聚类
代码实现¶
有了上面的理论支持我们就可以比较容易的写出聚类Anchor的代码了,直接上代码,里面几乎每行我都标注了注释,所以就不再赘述代码了。在使用代码的时候注意替换xml文件所在的路径,需要聚类的Anchor数目还有输入到YOLO网络中的图片大小,就可以执行代码获得我们想要的Anchor了。
#coding=utf-8
import xml.etree.ElementTree as ET
import numpy as np
def iou(box, clusters):
"""
计算一个ground truth边界盒和k个先验框(Anchor)的交并比(IOU)值。
参数box: 元组或者数据,代表ground truth的长宽。
参数clusters: 形如(k,2)的numpy数组,其中k是聚类Anchor框的个数
返回:ground truth和每个Anchor框的交并比。
"""
x = np.minimum(clusters[:, 0], box[0])
y = np.minimum(clusters[:, 1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area")
intersection = x * y
box_area = box[0] * box[1]
cluster_area = clusters[:, 0] * clusters[:, 1]
iou_ = intersection / (box_area + cluster_area - intersection)
return iou_
def avg_iou(boxes, clusters):
"""
计算一个ground truth和k个Anchor的交并比的均值。
"""
return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])])
def kmeans(boxes, k, dist=np.median):
"""
利用IOU值进行K-means聚类
参数boxes: 形状为(r, 2)的ground truth框,其中r是ground truth的个数
参数k: Anchor的个数
参数dist: 距离函数
返回值:形状为(k, 2)的k个Anchor框
"""
# 即是上面提到的r
rows = boxes.shape[0]
# 距离数组,计算每个ground truth和k个Anchor的距离
distances = np.empty((rows, k))
# 上一次每个ground truth"距离"最近的Anchor索引
last_clusters = np.zeros((rows,))
# 设置随机数种子
np.random.seed()
# 初始化聚类中心,k个簇,从r个ground truth随机选k个
clusters = boxes[np.random.choice(rows, k, replace=False)]
# 开始聚类
while True:
# 计算每个ground truth和k个Anchor的距离,用1-IOU(box,anchor)来计算
for row in range(rows):
distances[row] = 1 - iou(boxes[row], clusters)
# 对每个ground truth,选取距离最小的那个Anchor,并存下索引
nearest_clusters = np.argmin(distances, axis=1)
# 如果当前每个ground truth"距离"最近的Anchor索引和上一次一样,聚类结束
if (last_clusters == nearest_clusters).all():
break
# 更新簇中心为簇里面所有的ground truth框的均值
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0)
# 更新每个ground truth"距离"最近的Anchor索引
last_clusters = nearest_clusters
return clusters
# 加载自己的数据集,只需要所有labelimg标注出来的xml文件即可
def load_dataset(path):
dataset = []
for xml_file in glob.glob("{}/*xml".format(path)):
tree = ET.parse(xml_file)
# 图片高度
height = int(tree.findtext("./size/height"))
# 图片宽度
width = int(tree.findtext("./size/width"))
for obj in tree.iter("object"):
# 偏移量
xmin = int(obj.findtext("bndbox/xmin")) / width
ymin = int(obj.findtext("bndbox/ymin")) / height
xmax = int(obj.findtext("bndbox/xmax")) / width
ymax = int(obj.findtext("bndbox/ymax")) / height
xmin = np.float64(xmin)
ymin = np.float64(ymin)
xmax = np.float64(xmax)
ymax = np.float64(ymax)
if xmax == xmin or ymax == ymin:
print(xml_file)
# 将Anchor的长宽放入dateset,运行kmeans获得Anchor
dataset.append([xmax - xmin, ymax - ymin])
return np.array(dataset)
if __name__ == '__main__':
ANNOTATIONS_PATH = "F:\Annotations" #xml文件所在文件夹
CLUSTERS = 9 #聚类数量,anchor数量
INPUTDIM = 416 #输入网络大小
data = load_dataset(ANNOTATIONS_PATH)
out = kmeans(data, k=CLUSTERS)
print('Boxes:')
print(np.array(out)*INPUTDIM)
print("Accuracy: {:.2f}%".format(avg_iou(data, out) * 100))
final_anchors = np.around(out[:, 0] / out[:, 1], decimals=2).tolist()
print("Before Sort Ratios:\n {}".format(final_anchors))
print("After Sort Ratios:\n {}".format(sorted(final_anchors)))
代码测试¶
对于VOC2007数据集¶
首先下载VOC2007数据集获得每张图片的xml文件,然后将图片大小设置为416,将Anchor的数目设置为9,执行我们的代码,运行结果为:
 可以看到这个平均IOU值和上面YOLOv2给出的数据是很接近的,说明代码实现应该问题不大。
可以看到这个平均IOU值和上面YOLOv2给出的数据是很接近的,说明代码实现应该问题不大。
对于自己的数据集¶
和上面一样的使用方式,这里使用我自己标注的3个类别的数据集来测试一下,Anchor设为9,输入到网络的图像大小设置为416,测试结果如下:
 根据平均IOU值来看还是比较优秀的,然后选出这些Anchor放到YOLO网络中进行训练即可。
根据平均IOU值来看还是比较优秀的,然后选出这些Anchor放到YOLO网络中进行训练即可。
后记¶
今天提供了一个如何计算自己的数据集的Anchor的工具,从原理到代码逐渐解析,希望可以帮助到你。同时新开了一个github工程整理一些平时会用到的深度学习工具,地址为:https://github.com/BBuf/cv_tools ,持续更新欢迎关注。
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次