1. 前言¶
回顾一下上节推文的内容,我们将Faster RCNN的数据预处理以及实现细节弄清楚了,并将其总结为了下图:
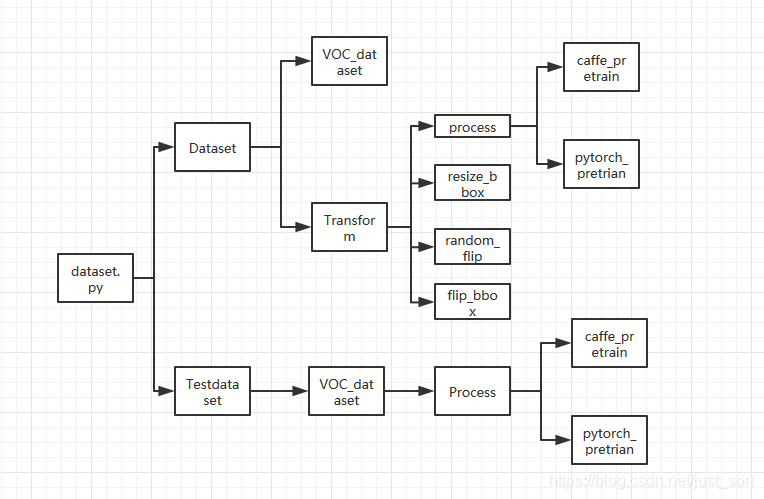
这一节,我们将重点讲讲Faster RCNN中的RPN即候选框生成网络和ROI Head的细节。
2. 原理介绍&代码详解¶
还是先回忆一下上节讲到的Faster RCNN整体结构,如下所示:
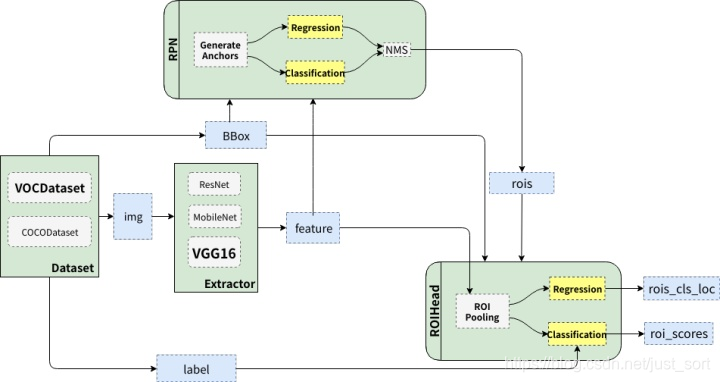
可以看到原始图片首先会经过一个特征提取器Extrator这里是VGG16,在原始论文中作者使用了Caffe的预训练模型。同时将VGG16模型的前4层卷积层的参数冻结(在Caffe中将其学习率设为0),并将最后三层全连接层的前两层保留并用来初始化ROIHead里面部分参数,等我们将代码解析到这里了,就很好理解了,暂时没理解也不要紧,只是了解一下有这个流程即可。我们可以将Extrator用下图来表示:
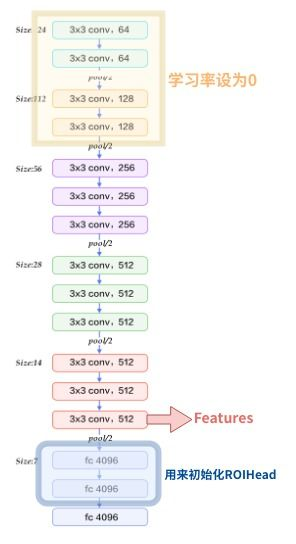
可以看到对于一个尺寸为H\times W\times C的图片,经过这个特征提取网络之后会得到一个\frac{H}{16}\times \frac{W}{16} \times 3的特征图,也即是图中的红色箭头代表的Features。
接下来我们来讲一下RPN,我们从整体结构图中可以看到RPN这个候选框生成网络接收了2个输入,一个是特征图也就是我们刚提到的,另外一个是数据集提供的GT Box,这里面究竟是怎么操作呢?
我们知道RPN网络使用来提取候选框的,它最大的贡献就在于它提出了一个Anchor的思想,这也是后面One-Stage以及Two-Stage的各类目标检测算法的出发点,Anchor表示的是大小和尺寸固定的候选框,论文中用到了三种比例和三种尺寸,也就是说对于特征图的每个点都将产生3\times 3=9种不同大小的Anchor候选框,其中三种尺寸分别是128(下图中的蓝色),256(下图中的红色),512(下图中的绿色),而三种比例分别为:1:2,2:1,1:1。Faster RCNN的九种Anchor的示意图如下:
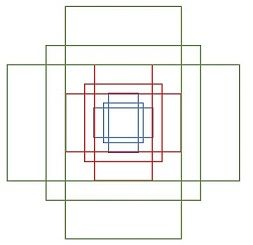
然后我们来算一下对于一个尺寸为512\times 62\times 37的特征图有多少个Anchor,上面提到对于特征图的每个点都要产生9个Anchor,那么这个特征图就一共会产生62\times 37 \times 9=20464个Anchor。可以看到一张图片产生这么多Anchor,肯定很多Anchor和真正的目标框是接近的(IOU大),这相对于从0开始回归目标框就大大降低了难度,可以理解为有一些老司机先给出了我们一些经验,然后我们在这些经验上去做出判断和优化,这样就更容易了。
这里我们先来看一下生成Anchor的过程,具体是在model/util文件夹下,我们首先来看bbox_tools.py文件,其中涉及到了RCNN中提到的边框回归公式,\hat{G}代表候选框,而回归学习就是学习d_x,d_y,d_h,d_w这4个偏移量,\hat{G}和P的关系可以如下表示:
\hat{G_x}=P_wd_x(P)+P_x \hat{G_y}=P_hd_y(P)+P_y \hat{G_w}=P_wexp(d_w(P)) \hat{G_h}=P_hexp(d_h(P))
真正的目标框和候选框之间的偏移可以表示为:
t_x=(G_x-P_x)/P_w
t_y=(G_y-P_y)/P_h
t_w=log(G_w/P_w)
t_h=log(G_h/P_h)
bbox_tools.py的具体解释如下:
# 已知源bbox和位置偏差dx,dy,dh,dw,求目标框G
def loc2bbox(src_bbox, loc):
# src_bbox:(R,4),R为bbox个数,4为左上角和右下角四个坐标
if src_bbox.shape[0] == 0:
return xp.zeros((0, 4), dtype=loc.dtype)
src_bbox = src_bbox.astype(src_bbox.dtype, copy=False)
#src_height为Ph,src_width为Pw,src_ctr_y为Py,src_ctr_x为Px
src_height = src_bbox[:, 2] - src_bbox[:, 0] #ymax-ymin
src_width = src_bbox[:, 3] - src_bbox[:, 1] #xmax-xmin
src_ctr_y = src_bbox[:, 0] + 0.5 * src_height #y0+0.5h
src_ctr_x = src_bbox[:, 1] + 0.5 * src_width #x0+0.5w,计算出中心点坐标
#python [start:stop:step]
dy = loc[:, 0::4]
dx = loc[:, 1::4]
dh = loc[:, 2::4]
dw = loc[:, 3::4]
# RCNN中提出的边框回归:寻找原始proposal与近似目标框G之间的映射关系,公式在上面
ctr_y = dy * src_height[:, xp.newaxis] + src_ctr_y[:, xp.newaxis] #ctr_y为Gy
ctr_x = dx * src_width[:, xp.newaxis] + src_ctr_x[:, xp.newaxis] # ctr_x为Gx
h = xp.exp(dh) * src_height[:, xp.newaxis] #h为Gh
w = xp.exp(dw) * src_width[:, xp.newaxis] #w为Gw
# 上面四行得到了回归后的目标框(Gx,Gy,Gh,Gw)
# 由中心点转换为左上角和右下角坐标
dst_bbox = xp.zeros(loc.shape, dtype=loc.dtype)
dst_bbox[:, 0::4] = ctr_y - 0.5 * h
dst_bbox[:, 1::4] = ctr_x - 0.5 * w
dst_bbox[:, 2::4] = ctr_y + 0.5 * h
dst_bbox[:, 3::4] = ctr_x + 0.5 * w
return dst_bbox
# 已知源框和目标框求出其位置偏差
def bbox2loc(src_bbox, dst_bbox):
# 计算出源框中心点坐标
height = src_bbox[:, 2] - src_bbox[:, 0]
width = src_bbox[:, 3] - src_bbox[:, 1]
ctr_y = src_bbox[:, 0] + 0.5 * height
ctr_x = src_bbox[:, 1] + 0.5 * width
# 计算出目标框中心点坐标
base_height = dst_bbox[:, 2] - dst_bbox[:, 0]
base_width = dst_bbox[:, 3] - dst_bbox[:, 1]
base_ctr_y = dst_bbox[:, 0] + 0.5 * base_height
base_ctr_x = dst_bbox[:, 1] + 0.5 * base_width
# 求出最小的正数
eps = xp.finfo(height.dtype).eps
# 将height,width与其比较保证全部是非负
height = xp.maximum(height, eps)
width = xp.maximum(width, eps)
# 根据上面的公式二计算dx,dy,dh,dw
dy = (base_ctr_y - ctr_y) / height
dx = (base_ctr_x - ctr_x) / width
dh = xp.log(base_height / height)
dw = xp.log(base_width / width)
# np.vstack按照行的顺序把数组给堆叠起来
loc = xp.vstack((dy, dx, dh, dw)).transpose()
return loc
# 求两个bbox的相交的交并比
def bbox_iou(bbox_a, bbox_b):
# 确保bbox第二维为bbox的四个坐标(ymin,xmin,ymax,xmax)
if bbox_a.shape[1] != 4 or bbox_b.shape[1] != 4:
raise IndexError
# top left
# l为交叉部分框左上角坐标最大值,为了利用numpy的广播性质,
# bbox_a[:, None, :2]的shape是(N,1,2),bbox_b[:, :2]
# shape是(K,2),由numpy的广播性质,两个数组shape都变成(N,K,2),
# 也就是对a里每个bbox都分别和b里的每个bbox求左上角点坐标最大值
tl = xp.maximum(bbox_a[:, None, :2], bbox_b[:, :2])
# bottom right
# br为交叉部分框右下角坐标最小值
br = xp.minimum(bbox_a[:, None, 2:], bbox_b[:, 2:])
# 所有坐标轴上tl<br时,返回数组元素的乘积(y1max-yimin)X(x1max-x1min),
# bboxa与bboxb相交区域的面积
area_i = xp.prod(br - tl, axis=2) * (tl < br).all(axis=2)
# 计算bboxa的面积
area_a = xp.prod(bbox_a[:, 2:] - bbox_a[:, :2], axis=1)
# 计算bboxb的面积
area_b = xp.prod(bbox_b[:, 2:] - bbox_b[:, :2], axis=1)
# 计算IOU
return area_i / (area_a[:, None] + area_b - area_i)
def __test():
pass
if __name__ == '__main__':
__test()
# 对特征图features以基准长度为16、选择合适的ratios和scales取基准锚点
# anchor_base。(选择长度为16的原因是图片大小为600*800左右,基准长度
# 16对应的原图区域是256*256,考虑放缩后的大小有128*128,512*512比较合适)
def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]):
# 根据基准点生成9个基本的anchor的功能,ratios=[0.5,1,2],anchor_scales=
# [8,16,32]是长宽比和缩放比例,anchor_scales也就是在base_size的基础上再增
# 加的量,本代码中对应着三种面积的大小(16*8)^2 ,(16*16)^2 (16*32)^2
# 也就是128,256,512的平方大小
py = base_size / 2.
px = base_size / 2.
#(9,4),注意:这里只是以特征图的左上角点为基准产生的9个anchor,
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4),
dtype=np.float32)
# six.moves 是用来处理那些在python2 和 3里面函数的位置有变化的,
# 直接用six.moves就可以屏蔽掉这些变化
for i in six.moves.range(len(ratios)):
for j in six.moves.range(len(anchor_scales)):
# 生成9种不同比例的h和w
h = base_size * anchor_scales[j] * np.sqrt(ratios[i])
w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i])
index = i * len(anchor_scales) + j
# 计算出anchor_base画的9个框的左上角和右下角的4个anchor坐标值
anchor_base[index, 0] = py - h / 2.
anchor_base[index, 1] = px - w / 2.
anchor_base[index, 2] = py + h / 2.
anchor_base[index, 3] = px + w / 2.
return anchor_base
在上面的generate_anchor_base函数中,输出Anchor的形状以及这9个Anchor的左上右下坐标如下:
这9个anchor形状为:
90.50967 *181.01933 = 128^2
181.01933 * 362.03867 = 256^2
362.03867 * 724.07733 = 512^2
128.0 * 128.0 = 128^2
256.0 * 256.0 = 256^2
512.0 * 512.0 = 512^2
181.01933 * 90.50967 = 128^2
362.03867 * 181.01933 = 256^2
724.07733 * 362.03867 = 512^2
9个anchor的左上右下坐标:
-37.2548 -82.5097 53.2548 98.5097
-82.5097 -173.019 98.5097 189.019
-173.019 -354.039 189.019 370.039
-56 -56 72 72
-120 -120 136 136
-248 -248 264 264
-82.5097 -37.2548 98.5097 53.2548
-173.019 -82.5097 189.019 98.5097
-354.039 -173.019 370.039 189.019
需要注意的是:
anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4), dtype=np.float32)
这行代码表示的是只是以特征图的左上角为基准产生的9个Anchor,而我们知道Faster RCNN是会在特征图的每个点产生9个Anchor的,这个过程在什么地方呢?答案是在mode/region_proposal_network.py里面,这里面的_enumerate_shifted_anchor这个函数就实现了这一功能,接下来我们就仔细看看这个函数是如何产生整个特征图的所有Anchor的(一共20000+个左右Anchor,另外产生的Anchor坐标会截断到图像坐标范围里面)。下面来看看model/region_proposal_network.py里面的_enumerate_shifted_anchor函数:
# 利用anchor_base生成所有对应feature map的anchor
def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width):
# Enumerate all shifted anchors:
#
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
# return (K*A, 4)
# !TODO: add support for torch.CudaTensor
# xp = cuda.get_array_module(anchor_base)
# it seems that it can't be boosed using GPU
import numpy as xp
# 纵向偏移量(0,16,32,...)
shift_y = xp.arange(0, height * feat_stride, feat_stride)
# 横向偏移量(0,16,32,...)
shift_x = xp.arange(0, width * feat_stride, feat_stride)
# shift_x = [[0,16,32,..],[0,16,32,..],[0,16,32,..]...],
# shift_y = [[0,0,0,..],[16,16,16,..],[32,32,32,..]...],
# 就是形成了一个纵横向偏移量的矩阵,也就是特征图的每一点都能够通过这个
# 矩阵找到映射在原图中的具体位置!
shift_x, shift_y = xp.meshgrid(shift_x, shift_y)
# #经过刚才的变化,其实大X,Y的元素个数已经相同,看矩阵的结构也能看出,
# 矩阵大小是相同的,X.ravel()之后变成一行,此时shift_x,shift_y的元
# 素个数是相同的,都等于特征图的长宽的乘积(像素点个数),不同的是此时
# 的shift_x里面装得是横向看的x的一行一行的偏移坐标,而此时的y里面装
# 的是对应的纵向的偏移坐标!下图显示xp.meshgrid(),shift_y.ravel()
# 操作示例
shift = xp.stack((shift_y.ravel(), shift_x.ravel(),
shift_y.ravel(), shift_x.ravel()), axis=1)
# A=9
A = anchor_base.shape[0]
# 读取特征图中元素的总个数
K = shift.shape[0]
#用基础的9个anchor的坐标分别和偏移量相加,最后得出了所有的anchor的坐标,
# 四列可以堪称是左上角的坐标和右下角的坐标加偏移量的同步执行,飞速的从
# 上往下捋一遍,所有的anchor就都出来了!一共K个特征点,每一个有A(9)个
# 基本的anchor,所以最后reshape((K*A),4)的形式,也就得到了最后的所有
# 的anchor左上角和右下角坐标.
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
anchor = anchor_base.reshape((1, A, 4)) + \
shift.reshape((1, K, 4)).transpose((1, 0, 2))
anchor = anchor.reshape((K * A, 4)).astype(np.float32)
return anchor
我们结合一个例子来看一下shift_x, shift_y = xp.meshgrid(shift_x, shift_y)函数操这个函数到底执行了什么操作?其中xp就是numpy。
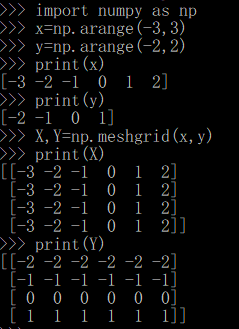
然后shift = xp.stack((shift_y.ravel(), shift_x.ravel(),shift_y.ravel(), shift_x.ravel()), axis=1)这行代码则是产生坐标偏移对,一个是x方向,一个是y方向。
另外一个问题是这里为什么需要将特征图对应回原图呢?这是因为我们要框住的目标是在原图上,而我们选Anchor是在特征图上,Pooling之后特征之间的相对位置不变,但是尺寸已经减少为了原始图的\frac{1}{16},而我们的Anchor是为了框住原图上的目标而非特征图上的,所以注意一下Anchor一定指的是针对原图的,而非特征图。
接下来我们看看训练RPN的一些细节,RPN的总体架构如下图所示:
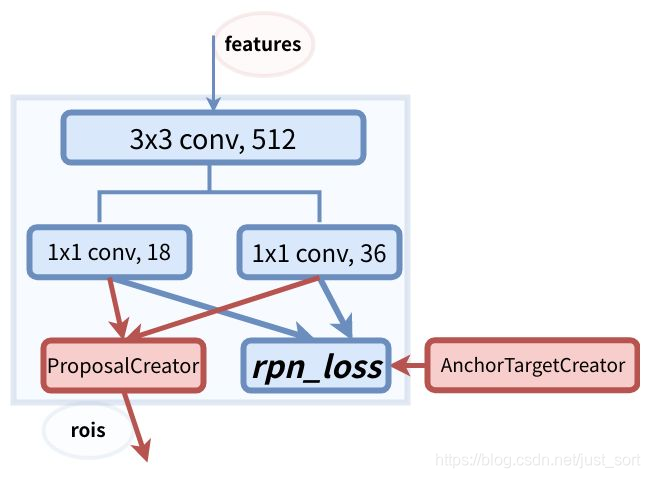
首先我们要明确Anchor的数量是和特征图相关的,不同的特征图对应的Anchor数量也不一样。RPN在Extractor输出的特征图基础上先增加了一个3\times 3卷积,然后利用两个1\times 1卷积分别进行二分类和位置回归。进行分类的卷积核通道数为9\times 2(9个Anchor,每个Anchor二分类,使用交叉熵损失),进行回归的卷积核通道数为9\times 4(9个Anchor,每个Anchor有4个位置参数)。RPN是一个全卷积网络,这样对输入图片的尺寸是没有要求的。
接下来我们就要讲到今天的重点部分了,即AnchorTargetCreator,ProposalCreator,ProposalTargetCreator,也就是ROI Head最核心的部分:
AnchorTargetCreator¶
AnchorTargetCreator就是将20000多个候选的Anchor选出256个Anchor进行分类和回归,选择过程如下: - 对于每一个GT bbox,选择和它交并比最大的一个Anchor作为正样本。 - 对于剩下的Anchor,从中选择和任意一个GT bbox交并比超过0.7的Anchor作为正样本,正样本数目不超过128个。 - 随机选择和GT bbox交并比小于0.3的Anchor作为负样本,负样本和正样本的总数为256。
对于每一个Anchor来说,GT_Label要么为1(前景),要么为0(背景),而GT_Loc则是由4个位置参数组成,也就是上面讲的目标框和候选框之间的偏移。
计算分类损失使用的是交叉熵损失,而计算回归损失则使用了SmoothL1Loss,在计算回归损失的时候只计算正样本(前景)的损失,不计算负样本的损失。
代码实现在model/utils/creator_tool.py里面,具体如下:
# AnchorTargetCreator作用是生成训练要用的anchor(正负样本
# 各128个框的坐标和256个label(0或者1))
# 利用每张图中bbox的真实标签来为所有任务分配ground truth
class AnchorTargetCreator(object):
def __init__(self,
n_sample=256,
pos_iou_thresh=0.7, neg_iou_thresh=0.3,
pos_ratio=0.5):
self.n_sample = n_sample
self.pos_iou_thresh = pos_iou_thresh
self.neg_iou_thresh = neg_iou_thresh
self.pos_ratio = pos_ratio
def __call__(self, bbox, anchor, img_size):
# 特征图大小
img_H, img_W = img_size
# 一般对应20000个左右anchor
n_anchor = len(anchor)
# 将那些超出图片范围的anchor全部去掉,只保留位于图片内部的序号
inside_index = _get_inside_index(anchor, img_H, img_W)
# 保留位于图片内部的anchor
anchor = anchor[inside_index]
# 筛选出符合条件的正例128个负例128并给它们附上相应的label
argmax_ious, label = self._create_label(
inside_index, anchor, bbox)
# 计算每一个anchor与对应bbox求得iou最大的bbox计算偏移
# 量(注意这里是位于图片内部的每一个)
loc = bbox2loc(anchor, bbox[argmax_ious])
# 将位于图片内部的框的label对应到所有生成的20000个框中
# (label原本为所有在图片中的框的)
label = _unmap(label, n_anchor, inside_index, fill=-1)
# 将回归的框对应到所有生成的20000个框中(label原本为
# 所有在图片中的框的)
loc = _unmap(loc, n_anchor, inside_index, fill=0)
return loc, label
# 下面为调用的_creat_label() 函数
def _create_label(self, inside_index, anchor, bbox):
# inside_index为所有在图片范围内的anchor序号
label = np.empty((len(inside_index),), dtype=np.int32)
# #全部填充-1
label.fill(-1)
# 调用_calc_ious()函数得到每个anchor与哪个bbox的iou最大
# 以及这个iou值、每个bbox与哪个anchor的iou最大(需要体会从
# 行和列取最大值的区别)
argmax_ious, max_ious, gt_argmax_ious = \
self._calc_ious(anchor, bbox, inside_index)
# #把每个anchor与对应的框求得的iou值与负样本阈值比较,若小
# 于负样本阈值,则label设为0,pos_iou_thresh=0.7,
# neg_iou_thresh=0.3
label[max_ious < self.neg_iou_thresh] = 0
# 把与每个bbox求得iou值最大的anchor的label设为1
label[gt_argmax_ious] = 1
# 把每个anchor与对应的框求得的iou值与正样本阈值比较,
# 若大于正样本阈值,则label设为1
label[max_ious >= self.pos_iou_thresh] = 1
# 按照比例计算出正样本数量,pos_ratio=0.5,n_sample=256
n_pos = int(self.pos_ratio * self.n_sample)
# 得到所有正样本的索引
pos_index = np.where(label == 1)[0]
# 如果选取出来的正样本数多于预设定的正样本数,则随机抛弃,将那些抛弃的样本的label设为-1
if len(pos_index) > n_pos:
disable_index = np.random.choice(
pos_index, size=(len(pos_index) - n_pos), replace=False)
label[disable_index] = -1
# 设定的负样本的数量
n_neg = self.n_sample - np.sum(label == 1)
# 负样本的索引
neg_index = np.where(label == 0)[0]
if len(neg_index) > n_neg:
# 随机选择不要的负样本,个数为len(neg_index)-neg_index,label值设为-1
disable_index = np.random.choice(
neg_index, size=(len(neg_index) - n_neg), replace=False)
label[disable_index] = -1
return argmax_ious, label
# _calc_ious函数
def _calc_ious(self, anchor, bbox, inside_index):
# ious between the anchors and the gt boxes
# 调用bbox_iou函数计算anchor与bbox的IOU, ious:(N,K),
# N为anchor中第N个,K为bbox中第K个,N大概有15000个
ious = bbox_iou(anchor, bbox)
# 1代表行,0代表列
argmax_ious = ious.argmax(axis=1)
# 求出每个anchor与哪个bbox的iou最大,以及最大值,max_ious:[1,N]
max_ious = ious[np.arange(len(inside_index)), argmax_ious]
gt_argmax_ious = ious.argmax(axis=0)
# 求出每个bbox与哪个anchor的iou最大,以及最大值,gt_max_ious:[1,K]
gt_max_ious = ious[gt_argmax_ious, np.arange(ious.shape[1])]
# 然后返回最大iou的索引(每个bbox与哪个anchor的iou最大),有K个
gt_argmax_ious = np.where(ious == gt_max_ious)[0]
return argmax_ious, max_ious, gt_argmax_ious
ProposalCreator¶
RPN在自身训练的时候还会提供ROIs给Faster RCNN的ROI Head作为训练样本。RPN生成ROIs的过程就是ProposalCreator,具体流程如下:
- 对于每张图片,利用它的特征图,计算\frac{H}{16} \times \frac{W}{16}\times 9(大约20000个)Anchor属于前景的概率以及对应的位置参数。
- 选取概率较大的12000个Anchor。
- 利用回归的位置参数修正这12000个Anchor的位置,获得ROIs。
- 利用非极大值抑制,选出概率最大的2000个ROIs。
注意! 在推理阶段,为了提高处理速度,12000和2000分别变成了6000和300。并且这部分操作不需要反向传播,所以可以利用numpy或者tensor实现。因此,RPN的输出就是形如2000\times 4或者300\times 4的Tensor。
RPN给出了候选框,然后ROI Head就是在候选框的基础上继续进行分类和位置参数的回归获得最后的结果,ROI Head的结构图如下所示:
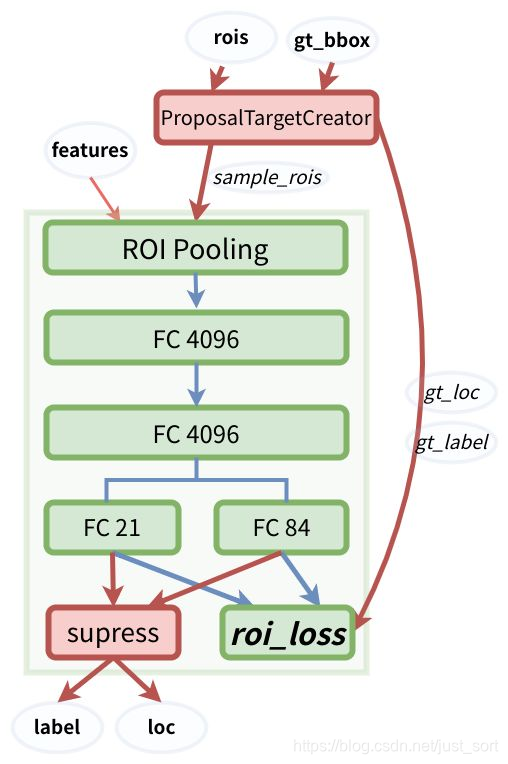
代码实现在model/utils/creator_tool.py里面,具体如下:
# 下面是ProposalCreator的代码: 这部分的操作不需要进行反向传播
# 因此可以利用numpy/tensor实现
class ProposalCreator:
# 对于每张图片,利用它的feature map,计算(H/16)x(W/16)x9(大概20000)
# 个anchor属于前景的概率,然后从中选取概率较大的12000张,利用位置回归参
# 数,修正这12000个anchor的位置, 利用非极大值抑制,选出2000个ROIS以及
# 对应的位置参数。
def __init__(self,
parent_model,
nms_thresh=0.7,
n_train_pre_nms=12000,
n_train_post_nms=2000,
n_test_pre_nms=6000,
n_test_post_nms=300,
min_size=16
):
self.parent_model = parent_model
self.nms_thresh = nms_thresh
self.n_train_pre_nms = n_train_pre_nms
self.n_train_post_nms = n_train_post_nms
self.n_test_pre_nms = n_test_pre_nms
self.n_test_post_nms = n_test_post_nms
self.min_size = min_size
# 这里的loc和score是经过region_proposal_network中
# 经过1x1卷积分类和回归得到的。
def __call__(self, loc, score,
anchor, img_size, scale=1.):
if self.parent_model.training:
n_pre_nms = self.n_train_pre_nms #12000
n_post_nms = self.n_train_post_nms #经过NMS后有2000个
else:
n_pre_nms = self.n_test_pre_nms #6000
n_post_nms = self.n_test_post_nms #经过NMS后有300个
# 将bbox转换为近似groudtruth的anchor(即rois)
roi = loc2bbox(anchor, loc)
# slice表示切片操作
# 裁剪将rois的ymin,ymax限定在[0,H]
roi[:, slice(0, 4, 2)] = np.clip(
roi[:, slice(0, 4, 2)], 0, img_size[0])
# 裁剪将rois的xmin,xmax限定在[0,W]
roi[:, slice(1, 4, 2)] = np.clip(
roi[:, slice(1, 4, 2)], 0, img_size[1])
# Remove predicted boxes with either height or width < threshold.
min_size = self.min_size * scale #16
# rois的宽
hs = roi[:, 2] - roi[:, 0]
# rois的高
ws = roi[:, 3] - roi[:, 1]
# 确保rois的长宽大于最小阈值
keep = np.where((hs >= min_size) & (ws >= min_size))[0]
roi = roi[keep, :]
# 对剩下的ROIs进行打分(根据region_proposal_network中rois的预测前景概率)
score = score[keep]
# Sort all (proposal, score) pairs by score from highest to lowest.
# Take top pre_nms_topN (e.g. 6000).
# 将score拉伸并逆序(从高到低)排序
order = score.ravel().argsort()[::-1]
# train时从20000中取前12000个rois,test取前6000个
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
# Apply nms (e.g. threshold = 0.7).
# Take after_nms_topN (e.g. 300).
# unNOTE: somthing is wrong here!
# TODO: remove cuda.to_gpu
# #(具体需要看NMS的原理以及输入参数的作用)调用非极大值抑制函数,
# 将重复的抑制掉,就可以将筛选后ROIS进行返回。经过NMS处理后Train
# 数据集得到2000个框,Test数据集得到300个框
keep = non_maximum_suppression(
cp.ascontiguousarray(cp.asarray(roi)),
thresh=self.nms_thresh)
if n_post_nms > 0:
keep = keep[:n_post_nms]
# 取出最终的2000或300个rois
roi = roi[keep]
return roi
ProposalTargetCreator¶
ROIs给出了2000个候选框,分别对应了不同大小的Anchor。我们首先需要利用ProposalTargetCreator挑选出128个sample_rois,然后使用了ROI Pooling将这些不同尺寸的区域全部Pooling到同一个尺度(7\times 7)上,关于ROI Pooling这里就不多讲了,具体见:实例分割算法之Mask R-CNN论文解读 。那么这里为什么要Pooling成7\times 7大小呢?
这是为了共享权重,前面在Extrator部分说到Faster RCNN除了前面基层卷积被用到之外,最后全连接层的权重也可以继续利用。当所有的RoIs都被Resize到512\times 512\times 7的特征图之后,将它Reshape成一个一维的向量,就可以利用VGG16预训练的权重初始化前两层全连接层了。最后,再接上两个全连接层FC21用来分类(20个类+背景,VOC)和回归(21个类,每个类有4个位置参数)。
我们再来看一下ProposalTargetCreator具体是如何选择128个ROIs进行训练的?过程如下: - RoIs和GT box的IOU大于0.5的,选择一些如32个。 - RoIs和gt_bboxes的IoU小于等于0(或者0.1)的选择一些(比如 128-32=96个)作为负样本。
同时为了方便训练,对选择出的128个RoIs的gt_roi_loc进行标准化处理(减均值除以标准差)。
下面来看看代码实现,同样是在model/utils/creator_tool.py里面:
# 下面是ProposalTargetCreator代码:ProposalCreator产生2000个ROIS,
# 但是这些ROIS并不都用于训练,经过本ProposalTargetCreator的筛选产生
# 128个用于自身的训练
class ProposalTargetCreator(object):
def __init__(self,
n_sample=128,
pos_ratio=0.25, pos_iou_thresh=0.5,
neg_iou_thresh_hi=0.5, neg_iou_thresh_lo=0.0
):
self.n_sample = n_sample
self.pos_ratio = pos_ratio
self.pos_iou_thresh = pos_iou_thresh
self.neg_iou_thresh_hi = neg_iou_thresh_hi
self.neg_iou_thresh_lo = neg_iou_thresh_lo # NOTE:default 0.1 in py-faster-rcnn
# 输入:2000个rois、一个batch(一张图)中所有的bbox ground truth(R,4)、
# 对应bbox所包含的label(R,1)(VOC2007来说20类0-19)
# 输出:128个sample roi(128,4)、128个gt_roi_loc(128,4)、
# 128个gt_roi_label(128,1)
def __call__(self, roi, bbox, label,
loc_normalize_mean=(0., 0., 0., 0.),
loc_normalize_std=(0.1, 0.1, 0.2, 0.2)):
n_bbox, _ = bbox.shape
# 首先将2000个roi和m个bbox给concatenate了一下成为
# 新的roi(2000+m,4)。
roi = np.concatenate((roi, bbox), axis=0)
# n_sample = 128,pos_ratio=0.5,round 对传入的数据进行四舍五入
pos_roi_per_image = np.round(self.n_sample * self.pos_ratio)
# 计算每一个roi与每一个bbox的iou
iou = bbox_iou(roi, bbox)
# 按行找到最大值,返回最大值对应的序号以及其真正的IOU。
# 返回的是每个roi与哪个bbox的最大,以及最大的iou值
gt_assignment = iou.argmax(axis=1)
# 每个roi与对应bbox最大的iou
max_iou = iou.max(axis=1)
# 从1开始的类别序号,给每个类得到真正的label(将0-19变为1-20)
gt_roi_label = label[gt_assignment] + 1
# 同样的根据iou的最大值将正负样本找出来,pos_iou_thresh=0.5
pos_index = np.where(max_iou >= self.pos_iou_thresh)[0]
# 需要保留的roi个数(满足大于pos_iou_thresh条件的roi与64之间较小的一个)
pos_roi_per_this_image = int(min(pos_roi_per_image, pos_index.size))
# 找出的样本数目过多就随机丢掉一些
if pos_index.size > 0:
pos_index = np.random.choice(
pos_index, size=pos_roi_per_this_image, replace=False)
# neg_iou_thresh_hi=0.5,neg_iou_thresh_lo=0.0
neg_index = np.where((max_iou < self.neg_iou_thresh_hi) &
(max_iou >= self.neg_iou_thresh_lo))[0]
neg_roi_per_this_image = self.n_sample - pos_roi_per_this_image
neg_roi_per_this_image = int(min(neg_roi_per_this_image,
neg_index.size))
if neg_index.size > 0:
neg_index = np.random.choice(
neg_index, size=neg_roi_per_this_image, replace=False)
# The indices that we're selecting (both positive and negative).
keep_index = np.append(pos_index, neg_index)
gt_roi_label = gt_roi_label[keep_index]
gt_roi_label[pos_roi_per_this_image:] = 0 # 负样本label 设为0
sample_roi = roi[keep_index]
# 此时输出的128*4的sample_roi就可以去扔到 RoIHead网络里去进行分类
# 与回归了。同样, RoIHead网络利用这sample_roi+featue为输入,输出
# 是分类(21类)和回归(进一步微调bbox)的预测值,那么分类回归的groud
# truth就是ProposalTargetCreator输出的gt_roi_label和gt_roi_loc。
# Compute offsets and scales to match sampled RoIs to the GTs.
# 求这128个样本的groundtruth
gt_roi_loc = bbox2loc(sample_roi, bbox[gt_assignment[keep_index]])
# ProposalTargetCreator首次用到了真实的21个类的label,
# 且该类最后对loc进行了归一化处理,所以预测时要进行均值方差处理
gt_roi_loc = ((gt_roi_loc - np.array(loc_normalize_mean, np.float32)
) / np.array(loc_normalize_std, np.float32))
return sample_roi, gt_roi_loc, gt_roi_label
3. 总结¶
这一节主要理清楚了RPN和ROIHead,希望大家能有所收获,下一节我将解读Faster RCNN的整体结构代码,谢谢观看。
4. 参考¶
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次