1. 前言¶
上一节详细解读了Faster RCNN中的RPN和ROIHead的细节,这一节我们将从搭建完整的Faster RCNN模型出发来进行梳理。
2. 搭建Faster RCNN网络模型¶
Faster RCNN的整体网络结构如下图所示:
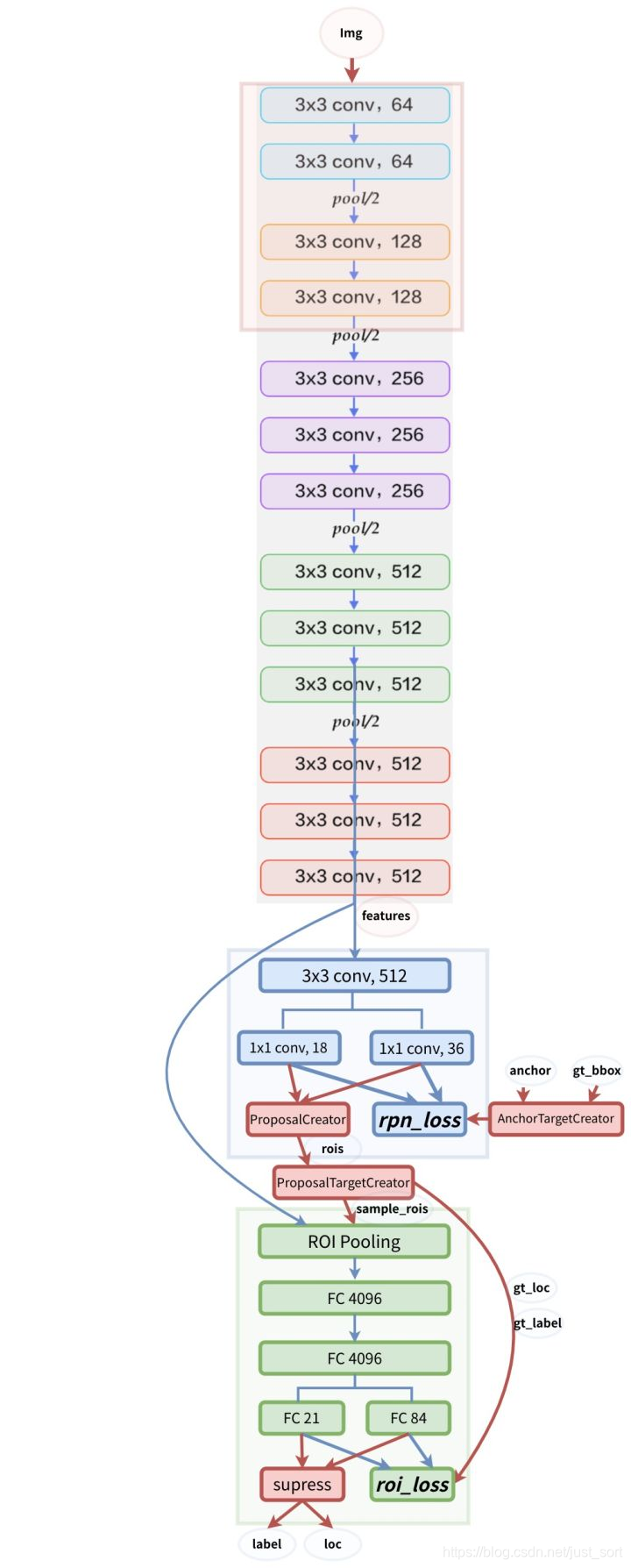
注意网络结构图中的蓝色箭头的线代表了计算图,梯度反向传播会经过。而红色的线不需要反向传播。一个有趣的事情是在Instance-aware Semantic Segmentation via Multi-task Network Cascades这篇论文(https://arxiv.org/abs/1512.04412)中提到ProposalCreator生成RoIs的过程也可以进行反向传播,感兴趣可以去看看。
在上一节主要讲了RPN里面的AnchorTargetCreator,ProposalCreator,ProposalTargetCreator,而RPN网络的核心类RegionProposalNetwork还没讲,这里先看一下,代码在model/region_proposal_network.py里面,细节如下:
class RegionProposalNetwork(nn.Module):
def __init__(
self, in_channels=512, mid_channels=512, ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32], feat_stride=16,
proposal_creator_params=dict(),
):
super(RegionProposalNetwork, self).__init__()
# 首先生成上述以(0,0)为中心的9个base anchor
self.anchor_base = generate_anchor_base(
anchor_scales=anchor_scales, ratios=ratios)
self.feat_stride = feat_stride
self.proposal_layer = ProposalCreator(self, **proposal_creator_params)
n_anchor = self.anchor_base.shape[0]
self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
self.score = nn.Conv2d(mid_channels, n_anchor * 2, 1, 1, 0)
self.loc = nn.Conv2d(mid_channels, n_anchor * 4, 1, 1, 0)
normal_init(self.conv1, 0, 0.01)
normal_init(self.score, 0, 0.01)
normal_init(self.loc, 0, 0.01)
def forward(self, x, img_size, scale=1.):
# x的尺寸为(batch_size,512,H/16,W/16),其中H,W分别为原图的高和宽
# x为feature map,n为batch_size,此版本代码为1. hh,ww即为宽高
n, _, hh, ww = x.shape
# 在9个base_anchor基础上生成hh*ww*9个anchor,对应到原图坐标
# feat_stride=16 ,因为是经4次pool后提到的特征,故feature map较
# 原图缩小了16倍
anchor = _enumerate_shifted_anchor(
np.array(self.anchor_base),/
self.feat_stride, hh, ww)
# (hh * ww * 9)/hh*ww = 9
n_anchor = anchor.shape[0] // (hh * ww)
# 512个3x3卷积(512, H/16,W/16)
h = F.relu(self.conv1(x))
# n_anchor(9)* 4个1x1卷积,回归坐标偏移量。(9*4,hh,ww)
rpn_locs = self.loc(h)
# UNNOTE: check whether need contiguous
# A: Yes
# 转换为(n,hh,ww,9*4)后变为(n,hh*ww*9,4)
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
# n_anchor(9)*2个1x1卷积,回归类别。(9*2,hh,ww)
rpn_scores = self.score(h)
# 转换为(n,hh,ww,9*2)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous()
# 计算{Softmax}(x_{i}) = \{exp(x_i)}{\sum_j exp(x_j)}
rpn_softmax_scores = F.softmax(rpn_scores.view(n, hh, ww, n_anchor, 2), dim=4)
# 得到前景的分类概率
rpn_fg_scores = rpn_softmax_scores[:, :, :, :, 1].contiguous()
# 得到所有anchor的前景分类概率
rpn_fg_scores = rpn_fg_scores.view(n, -1)
# 得到每一张feature map上所有anchor的网络输出值
rpn_scores = rpn_scores.view(n, -1, 2)
rois = list()
roi_indices = list()
# n为batch_size数
for i in range(n):
# 调用ProposalCreator函数, rpn_locs维度(hh*ww*9,4)
# ,rpn_fg_scores维度为(hh*ww*9),anchor的维度为
# (hh*ww*9,4), img_size的维度为(3,H,W),H和W是
# 经过数据预处理后的。计算(H/16)x(W/16)x9(大概20000)
# 个anchor属于前景的概率,取前12000个并经过NMS得到2000个
# 近似目标框G^的坐标。roi的维度为(2000,4)
roi = self.proposal_layer(
rpn_locs[i].cpu().data.numpy(),
rpn_fg_scores[i].cpu().data.numpy(),
anchor, img_size,
scale=scale)
batch_index = i * np.ones((len(roi),), dtype=np.int32)
# rois为所有batch_size的roi
rois.append(roi)
roi_indices.append(batch_index)
# 按行拼接(即没有batch_size的区分,每一个[]里都是一个anchor的四个坐标)
rois = np.concatenate(rois, axis=0)
# 这个 roi_indices在此代码中是多余的,因为我们实现的是batch_siae=1的
# 网络,一个batch只会输入一张图象。如果多张图像的话就需要存储索引以找到
# 对应图像的roi
roi_indices = np.concatenate(roi_indices, axis=0)
# rpn_locs的维度(hh*ww*9,4),rpn_scores维度为(hh*ww*9,2),
# rois的维度为(2000,4),roi_indices用不到,
# anchor的维度为(hh*ww*9,4)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
可以看到RegionProposalNetwork继承于nn.Module,这个网络我们在上一个推文讲的很细节了,在继续阅读之前,请确保你已经理解了RPN和ROI Head。
接下来,我们需要知道在model/roi_module.py里面主要利用了cupy(专用于GPU的numpy)实现ROI Pooling的前向传播和反向传播。NMS和ROI pooling利用了:cupy和chainer 。
其主要任务是对于一张图像得到的特征图(512\times \frac{w}{16}\times \frac{h}{16}),然后利用sample_roi的bbox坐标去在特征图上裁剪下来所有roi对应的特征图(训练:128\times 512\times \frac{w}{16}\times \frac{h}{16})、(测试:300\times 512\times \frac{w}{16}\times \frac{h}{16})。
接下来就是搭建网络模型的文件model/faster_rcnn.py,这个脚本定义了Faster RCNN的基本类FasterRCNN。我们知道Faster RCNN的三个核心步骤就是:
- 特征提取:输入一张图片得到其特征图feature map
- RPN:给定特征图后产生一系列RoIs
- ROI Head:利用这些RoIs对应的特征图对这些RoIs中的类别进行分类,并提升定位精度
在FasterRCNN这个类中就初始化了这三个重要的步骤,即self.extrator,self.rpn,self.head。
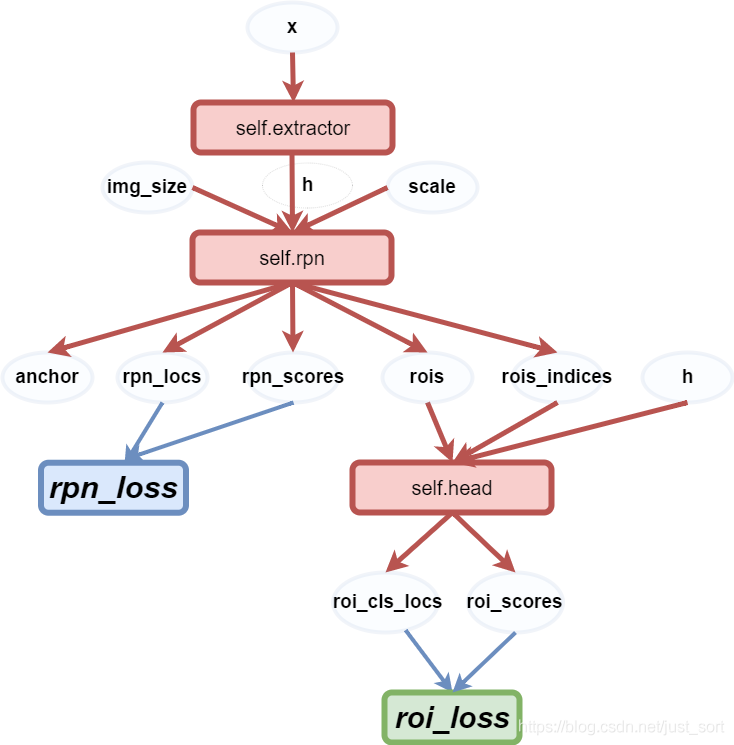
FasterRCNN类中,forward函数实现前向传播,代码如下:
def forward(self, x, scale=1.):
# 实现前向传播
img_size = x.shape[2:]
h = self.extractor(x)
rpn_locs, rpn_scores, rois, roi_indices, anchor = \
self.rpn(h, img_size, scale)
roi_cls_locs, roi_scores = self.head(
h, rois, roi_indices)
return roi_cls_locs, roi_scores, rois, roi_indices
也可以用下图来更清晰的表示:
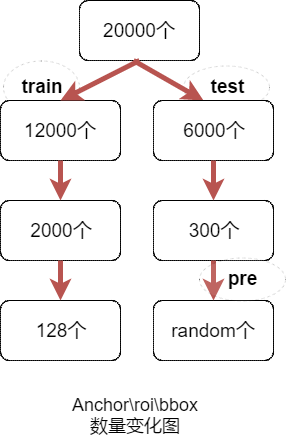
而这个forward过程中边界框的数量变化可以表示为下图:
接下来我们看一下预测函数predict,这个函数实现了对测试集图片的预测,同样batch=1,即每次输入一张图片。详解如下:
def predict(self, imgs,sizes=None,visualize=False):
# 设置为eval模式
self.eval()
# 是否开启可视化
if visualize:
self.use_preset('visualize')
prepared_imgs = list()
sizes = list()
for img in imgs:
size = img.shape[1:]
img = preprocess(at.tonumpy(img))
prepared_imgs.append(img)
sizes.append(size)
else:
prepared_imgs = imgs
bboxes = list()
labels = list()
scores = list()
for img, size in zip(prepared_imgs, sizes):
img = at.totensor(img[None]).float()
# 对读入的图片求尺度scale,因为输入的图像经预处理就会有缩放,
# 所以需记录缩放因子scale,这个缩放因子在ProposalCreator
# 筛选roi时有用到,即将所有候选框按这个缩放因子映射回原图,
# 超出原图边框的趋于将被截断。
scale = img.shape[3] / size[1]
# 执行forward
roi_cls_loc, roi_scores, rois, _ = self(img, scale=scale)
# We are assuming that batch size is 1.
roi_score = roi_scores.data
roi_cls_loc = roi_cls_loc.data
roi = at.totensor(rois) / scale
# Convert predictions to bounding boxes in image coordinates.
# Bounding boxes are scaled to the scale of the input images.
# 为ProposalCreator对loc做了归一化(-mean /std)处理,所以这里
# 需要再*std+mean,此时的位置参数loc为roi_cls_loc。然后将这128
# 个roi利用roi_cls_loc进行微调,得到新的cls_bbox。
mean = t.Tensor(self.loc_normalize_mean).cuda(). \
repeat(self.n_class)[None]
std = t.Tensor(self.loc_normalize_std).cuda(). \
repeat(self.n_class)[None]
roi_cls_loc = (roi_cls_loc * std + mean)
roi_cls_loc = roi_cls_loc.view(-1, self.n_class, 4)
roi = roi.view(-1, 1, 4).expand_as(roi_cls_loc)
cls_bbox = loc2bbox(at.tonumpy(roi).reshape((-1, 4)),
at.tonumpy(roi_cls_loc).reshape((-1, 4)))
cls_bbox = at.totensor(cls_bbox)
cls_bbox = cls_bbox.view(-1, self.n_class * 4)
# clip bounding box
cls_bbox[:, 0::2] = (cls_bbox[:, 0::2]).clamp(min=0, max=size[0])
cls_bbox[:, 1::2] = (cls_bbox[:, 1::2]).clamp(min=0, max=size[1])
# 对于分类得分roi_scores,我们需要将其经过softmax后转为概率prob。
# 值得注意的是我们此时得到的是对所有输入128个roi以及位置参数、得分
# 的预处理,下面将筛选出最后最终的预测结果。
prob = at.tonumpy(F.softmax(at.totensor(roi_score), dim=1))
raw_cls_bbox = at.tonumpy(cls_bbox)
raw_prob = at.tonumpy(prob)
bbox, label, score = self._suppress(raw_cls_bbox, raw_prob)
bboxes.append(bbox)
labels.append(label)
scores.append(score)
self.use_preset('evaluate')
self.train()
return bboxes, labels, scores
注意! 训练完train_datasets之后,model要来测试样本了。在model(test_datasets)之前,需要加上model.eval()。否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有batch normalization层所带来的的性质。
所以我们看到在第一行使用了self.eval(),那么为什么在最后一行函数返回bboxes,labels,scores之后还要加一行self.train呢?这是因为这次预测之后下次要接着训练,训练的时候需要设置模型类型为train。
上面的步骤是对网络RoIhead网络输出的预处理,函数_suppress将得到真正的预测结果。_suppress函数解释如下:
# predict函数是对网络RoIhead网络输出的预处理
# 函数_suppress将得到真正的预测结果。
# 此函数是一个按类别的循环,l从1至20(0类为背景类)。
# 即预测思想是按20个类别顺序依次验证,如果有满足该类的预测结果,
# 则记录,否则转入下一类(一张图中也就几个类别而已)。例如筛选
# 预测出第1类的结果,首先在cls_bbox中将所有128个预测第1类的
# bbox坐标找出,然后从prob中找出128个第1类的概率。因为阈值为0.7,
# 也即概率>0.7的所有边框初步被判定预测正确,记录下来。然而可能有
# 多个边框预测第1类中同一个物体,同类中一个物体只需一个边框,
# 所以需再经基于类的NMS后使得每类每个物体只有一个边框,至此
# 第1类预测完成,记录第1类的所有边框坐标、标签、置信度。
# 接着下一类...,直至20类都记录下来,那么一张图片(也即一个batch)
# 的预测也就结束了。
def _suppress(self, raw_cls_bbox, raw_prob):
bbox = list()
label = list()
score = list()
# skip cls_id = 0 because it is the background class
for l in range(1, self.n_class):
cls_bbox_l = raw_cls_bbox.reshape((-1, self.n_class, 4))[:, l, :]
prob_l = raw_prob[:, l]
mask = prob_l > self.score_thresh
cls_bbox_l = cls_bbox_l[mask]
prob_l = prob_l[mask]
keep = non_maximum_suppression(
cp.array(cls_bbox_l), self.nms_thresh, prob_l)
keep = cp.asnumpy(keep)
bbox.append(cls_bbox_l[keep])
# The labels are in [0, self.n_class - 2].
label.append((l - 1) * np.ones((len(keep),)))
score.append(prob_l[keep])
bbox = np.concatenate(bbox, axis=0).astype(np.float32)
label = np.concatenate(label, axis=0).astype(np.int32)
score = np.concatenate(score, axis=0).astype(np.float32)
return bbox, label, score
这里还定义了优化器optimizer,对于需要求导的参数 按照是否含bias赋予不同的学习率。默认是使用SGD,可选Adam,不过需更小的学习率。代码如下:
# 定义了优化器optimizer,对于需要求导的参数 按照是否含bias赋予不同的学习率。
# 默认是使用SGD,可选Adam,不过需更小的学习率。
def get_optimizer(self):
"""
return optimizer, It could be overwriten if you want to specify
special optimizer
"""
lr = opt.lr
params = []
for key, value in dict(self.named_parameters()).items():
if value.requires_grad:
if 'bias' in key:
params += [{'params': [value], 'lr': lr * 2, 'weight_decay': 0}]
else:
params += [{'params': [value], 'lr': lr, 'weight_decay': opt.weight_decay}]
if opt.use_adam:
self.optimizer = t.optim.Adam(params)
else:
self.optimizer = t.optim.SGD(params, momentum=0.9)
return self.optimizer
def scale_lr(self, decay=0.1):
for param_group in self.optimizer.param_groups:
param_group['lr'] *= decay
return self.optimizer
解释完了这个基类,我们来看看这份代码里面实现的基于VGG16的Faster RCNN的这个类FasterRCNNVGG16,它继承了FasterRCNN。
首先引入VGG16,然后拆分为特征提取网络和分类网络。冻结分类网络的前几层,不进行反向传播。
然后实现VGG16RoIHead网络。实现输入特征图、rois、roi_indices,输出roi_cls_locs和roi_scores。
类FasterRCNNVGG16分别对VGG16的特征提取部分、分类部分、RPN网络、VGG16RoIHead网络进行了实例化。
此外在对VGG16RoIHead网络的全连接层权重初始化过程中,按照图像是否为truncated(截断)分了两种初始化分方法,至于这个截断具体有什么用呢,也不是很明白这里似乎也没用。
详细解释如下:
def decom_vgg16():
# the 30th layer of features is relu of conv5_3
# 是否使用Caffe下载下来的预训练模型
if opt.caffe_pretrain:
model = vgg16(pretrained=False)
if not opt.load_path:
# 加载参数信息
model.load_state_dict(t.load(opt.caffe_pretrain_path))
else:
model = vgg16(not opt.load_path)
# 加载预训练模型vgg16的conv5_3之前的部分
features = list(model.features)[:30]
classifier = model.classifier
# 分类部分放到一个list里面
classifier = list(classifier)
# 删除输出分类结果层
del classifier[6]
# 删除两个dropout
if not opt.use_drop:
del classifier[5]
del classifier[2]
classifier = nn.Sequential(*classifier)
# 冻结vgg16前2个stage,不进行反向传播
for layer in features[:10]:
for p in layer.parameters():
p.requires_grad = False
# 拆分为特征提取网络和分类网络
return nn.Sequential(*features), classifier
# 分别对特征VGG16的特征提取部分、分类部分、RPN网络、
# VGG16RoIHead网络进行了实例化
class FasterRCNNVGG16(FasterRCNN):
# vgg16通过5个stage下采样16倍
feat_stride = 16 # downsample 16x for output of conv5 in vgg16
# 总类别数为20类,三种尺度三种比例的anchor
def __init__(self,
n_fg_class=20,
ratios=[0.5, 1, 2],
anchor_scales=[8, 16, 32]
):
# conv5_3及之前的部分,分类器
extractor, classifier = decom_vgg16()
# 返回rpn_locs, rpn_scores, rois, roi_indices, anchor
rpn = RegionProposalNetwork(
512, 512,
ratios=ratios,
anchor_scales=anchor_scales,
feat_stride=self.feat_stride,
)
# 下面讲
head = VGG16RoIHead(
n_class=n_fg_class + 1,
roi_size=7,
spatial_scale=(1. / self.feat_stride),
classifier=classifier
)
super(FasterRCNNVGG16, self).__init__(
extractor,
rpn,
head,
)
class VGG16RoIHead(nn.Module):
def __init__(self, n_class, roi_size, spatial_scale,
classifier):
# n_class includes the background
super(VGG16RoIHead, self).__init__()
# vgg16中的最后两个全连接层
self.classifier = classifier
self.cls_loc = nn.Linear(4096, n_class * 4)
self.score = nn.Linear(4096, n_class)
# 全连接层权重初始化
normal_init(self.cls_loc, 0, 0.001)
normal_init(self.score, 0, 0.01)
# 加上背景21类
self.n_class = n_class
# 7x7
self.roi_size = roi_size
# 1/16
self.spatial_scale = spatial_scale
# 将大小不同的roi变成大小一致,得到pooling后的特征,
# 大小为[300, 512, 7, 7]。利用Cupy实现在线编译的
self.roi = RoIPooling2D(self.roi_size, self.roi_size, self.spatial_scale)
def forward(self, x, rois, roi_indices):
# 前面解释过这里的roi_indices其实是多余的,因为batch_size一直为1
# in case roi_indices is ndarray
roi_indices = at.totensor(roi_indices).float() #ndarray->tensor
rois = at.totensor(rois).float()
indices_and_rois = t.cat([roi_indices[:, None], rois], dim=1)
# NOTE: important: yx->xy
xy_indices_and_rois = indices_and_rois[:, [0, 2, 1, 4, 3]]
# 把tensor变成在内存中连续分布的形式
indices_and_rois = xy_indices_and_rois.contiguous()
# 接下来分析roi_module.py中的RoI()
pool = self.roi(x, indices_and_rois)
# flat操作
pool = pool.view(pool.size(0), -1)
# decom_vgg16()得到的calssifier,得到4096
fc7 = self.classifier(pool)
# (4096->84)
roi_cls_locs = self.cls_loc(fc7)
# (4096->21)
roi_scores = self.score(fc7)
return roi_cls_locs, roi_scores
def normal_init(m, mean, stddev, truncated=False):
"""
weight initalizer: truncated normal and random normal.
"""
# x is a parameter
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
3. 总结¶
到这里呢我们就讲完了怎么搭建一个完整的Faster RCNN,下一节我准备讲一下训练相关的一些细节什么的,就结束本专栏,希望这份解释可以对你有帮助。有问题请在评论区留言讨论。
4. 参考¶
- https://www.cnblogs.com/king-lps/p/8992311.html
- https://zhuanlan.zhihu.com/p/32404424
- https://blog.csdn.net/qq_32678471/article/details/84882277
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次