前言¶
这篇文章是对前面《目标检测算法之SSD代码解析》,推文地址如下:点这里的补充。主要介绍SSD的数据增强策略,把这篇文章和代码解析的文章放在一起学最好不过啦。本节解析的仍然是上篇SSD代码解析推文的pytorch版本的代码。源码地址见附录。
数据下载¶
在工程的根目录下执行下面的命令下载VOC2007的trainval & test,以及VOC2012的trainval。
sh data/scripts/VOC2007.sh
sh data/scripts/VOC2012.sh
把下载下来的数据整理一下,将VOC2007和VOC2012放在同一目录下,具体目录结构为:
├── data
│ ├── VOC
│ ├── VOCdevkit
│ ├── VOC2007
│ ├── VOC2012
制作pytorch可以读取的数据集¶
这部分的代码都在data/voc0712.py文件里面。代码主要实现了2个class,第一个class是VOCAnnotationTransform(),主要功能是为了提取VOC数据集中每张原图的xml文件的bbox坐标进行归一化,并将类别转化为字典格式,最后把数据组合起来。形状最后类似于:[[x_min,y_min,x_max,y_max, c], ...]。第一部分的代码如下:
"""VOC Dataset Classes
Original author: Francisco Massa
https://github.com/fmassa/vision/blob/voc_dataset/torchvision/datasets/voc.py
Updated by: Ellis Brown, Max deGroot
"""
from .config import HOME
import os.path as osp
import sys
import torch
import torch.utils.data as data
import cv2
import numpy as np
if sys.version_info[0] == 2:
import xml.etree.cElementTree as ET
else:
import xml.etree.ElementTree as ET
# VOC的数据类别
VOC_CLASSES = ( # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
# VOC数据所在的目录
# note: if you used our download scripts, this should be right
VOC_ROOT = osp.join(HOME, "data/VOCdevkit/")
class VOCAnnotationTransform(object):
"""
将VOC的annotation中的bbox坐标转化为归一化的值;
将类别转化为用索引来表示的字典形式;
参数列表:
class_to_ind: 类别的索引字典。
keep_difficult: 是否保留difficult=1的物体。
"""
def __init__(self, class_to_ind=None, keep_difficult=False):
self.class_to_ind = class_to_ind or dict(
zip(VOC_CLASSES, range(len(VOC_CLASSES))))
self.keep_difficult = keep_difficult
def __call__(self, target, width, height):
"""
参数列表:
target: xml被读取的一个ET.Element对象
width: 图片宽度
height: 图片高度
返回值:
一个list,list中的每个元素是[bbox coords, class name]
"""
res = []
for obj in target.iter('object'):
# 判断目标是否difficult
difficult = int(obj.find('difficult').text) == 1
if not self.keep_difficult and difficult:
continue
# 读取xml中所需的信息
name = obj.find('name').text.lower().strip()
bbox = obj.find('bndbox')
# xml文件中bbox的表示
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for i, pt in enumerate(pts):
cur_pt = int(bbox.find(pt).text) - 1
# 归一化,x/w,y/h
cur_pt = cur_pt / width if i % 2 == 0 else cur_pt / height
bndbox.append(cur_pt)
# 提取类别名称对应的 index
label_idx = self.class_to_ind[name]
bndbox.append(label_idx)
res += [bndbox] # [xmin, ymin, xmax, ymax, label_ind]
# img_id = target.find('filename').text[:-4]
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
第2个class主要根据VOCAnnotationTransform()和VOC数据集的文件结构,读取图片,bbox和lable,构建VOC数据集。这部分的代码仍在data/voc0712.py文件中,具体如下:
class VOCDetection(data.Dataset):
# target_transform传入上面的VOCAnnotationTransform()类
def __init__(self, root,
image_sets=[('2007', 'trainval'), ('2012', 'trainval')],
transform=None, target_transform=VOCAnnotationTransform(),
dataset_name='VOC0712'):
self.root = root
self.image_set = image_sets
self.transform = transform
self.target_transform = target_transform
self.name = dataset_name
# bbox和label
self._annopath = osp.join('%s', 'Annotations', '%s.xml')
# 图片路径
self._imgpath = osp.join('%s', 'JPEGImages', '%s.jpg')
self.ids = list()
for (year, name) in image_sets:
rootpath = osp.join(self.root, 'VOC' + year)
for line in open(osp.join(rootpath, 'ImageSets', 'Main', name + '.txt')):
self.ids.append((rootpath, line.strip()))
# 可以自定义的函数
def __getitem__(self, index):
im, gt, h, w = self.pull_item(index)
return im, gt
def __len__(self):
return len(self.ids)
def pull_item(self, index):
img_id = self.ids[index]
# label 信息
target = ET.parse(self._annopath % img_id).getroot()
# 读取图片信息
img = cv2.imread(self._imgpath % img_id)
# 图片的长宽通道数
height, width, channels = img.shape
# 标签执行VOCAnnotationTransform()操作
if self.target_transform is not None:
target = self.target_transform(target, width, height)
# 数据(包括标签)是否需要执行transform(数据增强)操作
if self.transform is not None:
target = np.array(target)
# 执行了数据增强操作
img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])
# 把图片转化为RGB
img = img[:, :, (2, 1, 0)]
# 把 bbox和label合并为 shape(N, 5)
target = np.hstack((boxes, np.expand_dims(labels, axis=1)))
return torch.from_numpy(img).permute(2, 0, 1), target, height, width
# return torch.from_numpy(img), target, height, width
def pull_image(self, index):
'''
以PIL图像的方式返回下标为index的PIL格式原始图像
'''
img_id = self.ids[index]
return cv2.imread(self._imgpath % img_id, cv2.IMREAD_COLOR)
def pull_anno(self, index):
'''
返回索引为index的图像的xml标注信息对象
shape: [img_id, [(label, bbox coords),...]]
例子: ('001718', [('dog', (96, 13, 438, 332))])
'''
img_id = self.ids[index]
anno = ET.parse(self._annopath % img_id).getroot()
gt = self.target_transform(anno, 1, 1)
return img_id[1], gt
def pull_tensor(self, index):
'''
以Tensor的形式返回索引为index的原始图像,调用unsqueeze_函数
return torch.Tensor(self.pull_image(index)).unsqueeze_(0)
借用知乎文章中的测试代码,测试上面的两个类的效果。
Data = VOCDetection(VOC_ROOT)
data_loader = data.DataLoader(Data, batch_size=1,
num_workers=0,
shuffle=True,
pin_memory=True)
print('the data length is:', len(data_loader))
# 类别 to index
class_to_ind = dict(zip(VOC_CLASSES, range(len(VOC_CLASSES))))
# index to class,转化为类别名称
ind_to_class = ind_to_class ={v:k for k, v in class_to_ind.items()}
# 加载数据
for datas in data_loader:
img, target,h, w = datas
img = img.squeeze(0).permute(1,2,0).numpy().astype(np.uint8)
target = target[0].float()
# 把bbox的坐标还原为原图的数值
target[:,0] *= w.float()
target[:,2] *= w.float()
target[:,1] *= h.float()
target[:,3] *= h.float()
# 取整
target = np.int0(target.numpy())
# 画出图中类别名称
for i in range(target.shape[0]):
# 画矩形框
img =cv2.rectangle(img, (target[i,0],target[i,1]),(target[i, 2], target[i, 3]), (0,0,255), 2)
# 标明类别名称
img =cv2.putText(img, ind_to_class[target[i,4]],(target[i,0], target[i,1]-25),
cv2.FONT_HERSHEY_SIMPLEX, .5, (255, 255, 0), 1)
# 显示
cv2.imshow('imgs', img)
cv2.waitKey(0);
cv2.destroyAllWindows()
break
数据增强¶
这部分介绍的代码都在utils/augmentations.py里面了。我们首先看一下SSD数据增强的python类代码:
class PhotometricDistort(object):
"""
图片亮度,对比度和色调变化的方式合并为一个类
"""
def __init__(self):
self.pd = [
RandomContrast(),
ConvertColor(transform='HSV'),
RandomSaturation(),
RandomHue(),
ConvertColor(current='HSV', transform='BGR'),
RandomContrast()
]
self.rand_brightness = RandomBrightness()
self.rand_light_noise = RandomLightingNoise()
def __call__(self, image, boxes, labels):
# 使用图像的副本来做数据增强操作
im = image.copy()
# 亮度扰动增强
im, boxes, labels = self.rand_brightness(im, boxes, labels)
# 如果随机到1(只可能随机到0,1)就不执行pd的最后一个操作
if random.randint(2):
distort = Compose(self.pd[:-1])
else:
# 随机到0
distort = Compose(self.pd[1:])
# 执行一系列pd中的操作
im, boxes, labels = distort(im, boxes, labels)
# 最后再执行一个图片更换通道,形成颜色变化
return self.rand_light_noise(im, boxes, labels)
# 结合所有的图片增广方法形成的类
class SSDAugmentation(object):
def __init__(self, size=300, mean=(104, 117, 123)):
self.mean = mean
self.size = size
self.augment = Compose([
ConvertFromInts(), # 转化为float32
ToAbsoluteCoords(), # 转化为原图坐标
PhotometricDistort(), # 图片增强方式
Expand(self.mean), # 扩充
RandomSampleCrop(), # 裁剪
RandomMirror(), # 镜像
ToPercentCoords(), # 转化为归一化后的坐标
Resize(self.size), # Resize
ToAbsoluteCoords(), # 转为原图坐标
#SubtractMeans(self.mean), # 减去均值
])
def __call__(self, image, boxes, labels):
return self.augment(image, boxes, labels)
接下来我们就分别看看SSDAugmentation每一个增强子类似如何实现的。
Compose类¶
从SSDAugmentation类来看,代码中有很多图片增强方式,如对比度,亮度,色度,那么如何将这些增强方法组合起来呢?就用这个类来实现。代码如下:
class Compose(object):
"""将不同的增强方法组合在一起
参数:
transforms (List[Transform]): list of transforms to compose.
例子:
>>> augmentations.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img, boxes=None, labels=None):
for t in self.transforms:
img, boxes, labels = t(img, boxes, labels)
return img, boxes, labels
数据类型转换¶
在数据进行增强之前需要把图片的uchar类型转换为float类型。代码实现如下:
class ConvertFromInts(object):
def __call__(self, image, boxes=None, labels=None):
return image.astype(np.float32), boxes, labels
转回原图坐标¶
class ToAbsoluteCoords(object):
# 把归一化后的box变回原图
def __call__(self, image, boxes=None, labels=None):
height, width, channels = image.shape
boxes[:, 0] *= width
boxes[:, 2] *= width
boxes[:, 1] *= height
boxes[:, 3] *= height
return image, boxes, labels
图片色彩空间转换¶
在进行亮度,对比度,色度调整之前需要把色彩空间转换为HSV空间。最后还需要把HSV颜色空间转回RGB颜色空间。这部分的代码为:
class ConvertColor(object):
# RGB和HSV颜色空间互转
def __init__(self, current='BGR', transform='HSV'):
self.transform = transform
self.current = current
def __call__(self, image, boxes=None, labels=None):
if self.current == 'BGR' and self.transform == 'HSV':
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
elif self.current == 'HSV' and self.transform == 'BGR':
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
else:
raise NotImplementedError
return image, boxes, labels
饱和度变化¶
饱和度变化需要在HSV颜色空间下改变S的数字,同时S的范围是[0,1],需要限定在里面。这部分的代码实现如下:
class RandomSaturation(object):
# 随机饱和度变化,需要输入图片格式为HSV
def __init__(self, lower=0.5, upper=1.5):
self.lower = lower
self.upper = upper
assert self.upper >= self.lower, "contrast upper must be >= lower."
assert self.lower >= 0, "contrast lower must be non-negative."
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
image[:, :, 1] *= random.uniform(self.lower, self.upper)
return image, boxes, labels
色调变化¶
Hue变化需要在 HSV 空间下,改变H的数值,H的取值范围是0-360。代码如下:
class RandomHue(object):
def __init__(self, delta=18.0):
assert delta >= 0.0 and delta <= 360.0
self.delta = delta
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
image[:, :, 0] += random.uniform(-self.delta, self.delta)
image[:, :, 0][image[:, :, 0] > 360.0] -= 360.0
image[:, :, 0][image[:, :, 0] < 0.0] += 360.0
return image, boxes, labels
对比度变化¶
图片的对比度变化,只需要在RGB空间下,乘上一个alpha值。代码如下:
class RandomContrast(object):
def __init__(self, lower=0.5, upper=1.5):
self.lower = lower
self.upper = upper
assert self.upper >= self.lower, "contrast upper must be >= lower."
assert self.lower >= 0, "contrast lower must be non-negative."
# expects float image
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
alpha = random.uniform(self.lower, self.upper)
image *= alpha
return image, boxes, labels
亮度变化¶
接下来的增强操作是亮度变化,亮度变化只需要在RGB空间下,加上一个delta值,代码如下:
class RandomBrightness(object):
def __init__(self, delta=32):
assert delta >= 0.0
assert delta <= 255.0
self.delta = delta
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
delta = random.uniform(-self.delta, self.delta)
image += delta
return image, boxes, labels
颜色通道变化¶
针对图片的RGB空间,随机调换各通道的位置,实现不同灯光效果,代码如下:
class SwapChannels(object):
"""图像通道变换
specified in the swap tuple.
Args:
swaps (int triple): final order of channels
eg: (2, 1, 0)
"""
def __init__(self, swaps):
self.swaps = swaps
def __call__(self, image):
image = image[:, :, self.swaps]
return image
class RandomLightingNoise(object):
# 图片更换通道,形成的颜色变化
def __init__(self):
self.perms = ((0, 1, 2), (0, 2, 1),
(1, 0, 2), (1, 2, 0),
(2, 0, 1), (2, 1, 0))
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
swap = self.perms[random.randint(len(self.perms))]
shuffle = SwapChannels(swap) # shuffle channels
image = shuffle(image)
return image, boxes, labels
图像扩充¶
设置一个大于原图尺寸的size,填充指定的像素值mean,然后把原图随机放入这个图片中,实现原图的扩充。
class Expand(object):
# 随机扩充图片
def __init__(self, mean):
self.mean = mean
def __call__(self, image, boxes, labels):
if random.randint(2):
return image, boxes, labels
height, width, depth = image.shape
ratio = random.uniform(1, 4)
left = random.uniform(0, width*ratio - width)
top = random.uniform(0, height*ratio - height)
# 填充mean值
expand_image = np.zeros(
(int(height*ratio), int(width*ratio), depth),
dtype=image.dtype)
# 放入原图
expand_image[:, :, :] = self.mean
expand_image[int(top):int(top + height),
int(left):int(left + width)] = image
image = expand_image
# 同样相应的变化boxes的坐标
boxes = boxes.copy()
boxes[:, :2] += (int(left), int(top))
boxes[:, 2:] += (int(left), int(top))
return image, boxes, labels
图片的随机裁剪¶
图片随机裁剪在数据增强中有重要作用,这个算法的运行流程大致如下:
- 随机选取裁剪框的大小;
- 根据大小确定裁剪框的坐标;
- 分析裁剪框和图片内部bounding box的交并比;
- 筛选掉交并比不符合要求的裁剪框;
- 裁剪图片,并重新更新bounding box的位置坐标;
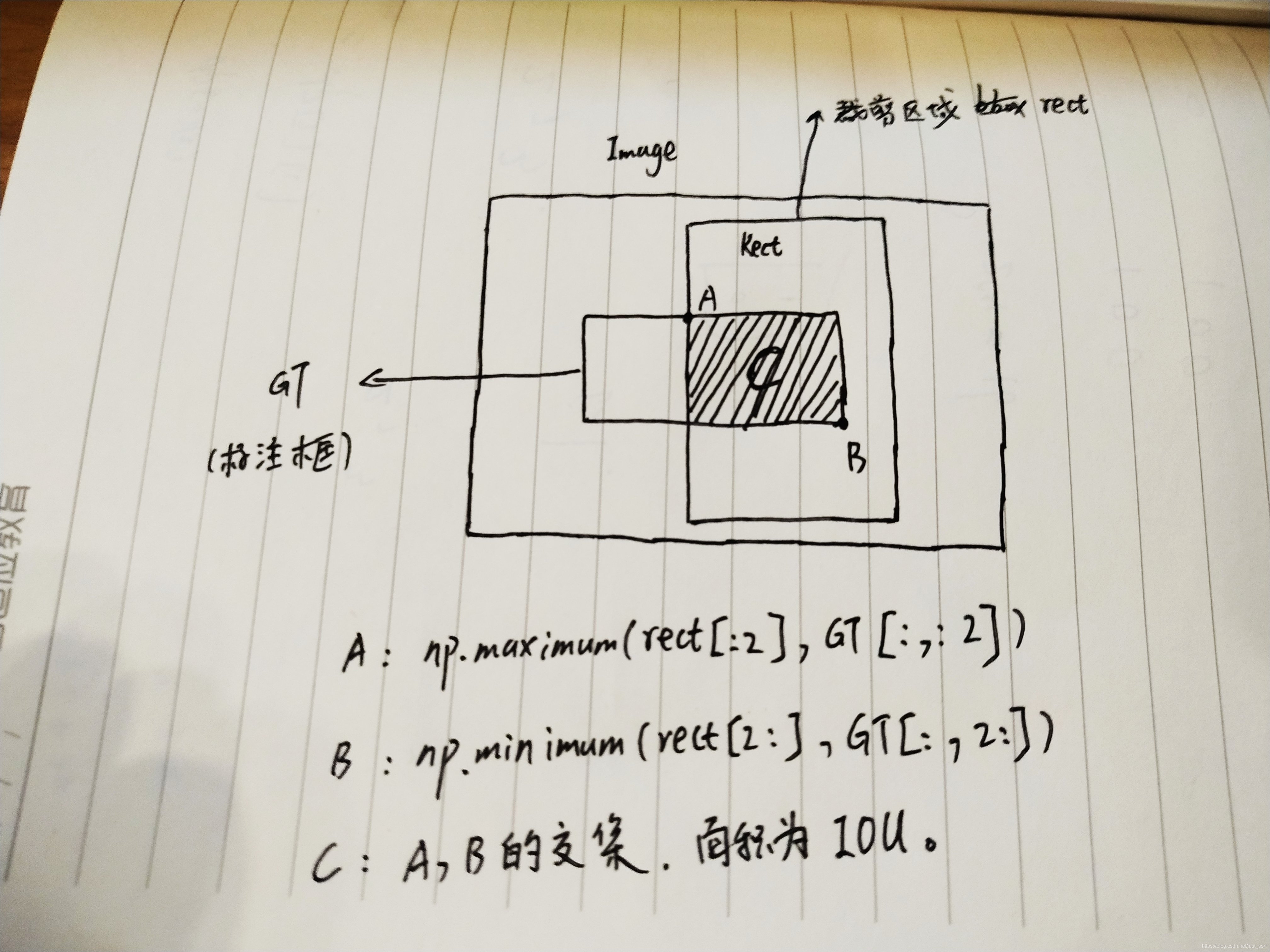
class RandomSampleCrop(object):
"""Crop
Arguments:
img (Image): the image being input during training
boxes (Tensor): the original bounding boxes in pt form
labels (Tensor): the class labels for each bbox
mode (float tuple): the min and max jaccard overlaps
Return:
(img, boxes, classes)
img (Image): the cropped image
boxes (Tensor): the adjusted bounding boxes in pt form
labels (Tensor): the class labels for each bbox
"""
def __init__(self):
self.sample_options = (
# 使用原图
None,
# 最小的IOU,和最大的IOU
(0.1, None),
(0.3, None),
(0.7, None),
(0.9, None),
# randomly sample a patch
(None, None),
)
def __call__(self, image, boxes=None, labels=None):
# 原图的长宽
height, width, _ = image.shape
while True:
# 随机选择一个切割模式
mode = random.choice(self.sample_options)
if mode is None:
return image, boxes, labels
min_iou, max_iou = mode
if min_iou is None:
min_iou = float('-inf')
if max_iou is None:
max_iou = float('inf')
# 迭代50次
for _ in range(50):
current_image = image
# 随机一个长宽
w = random.uniform(0.3 * width, width)
h = random.uniform(0.3 * height, height)
# 判断长宽比在一定范围
if h / w < 0.5 or h / w > 2:
continue
left = random.uniform(width - w)
top = random.uniform(height - h)
# 切割的矩形大小,形状是[x1,y1,x2,y2]
rect = np.array([int(left), int(top), int(left+w), int(top+h)])
# 计算切割的矩形和 gt 框的iou大小
overlap = jaccard_numpy(boxes, rect)
# 筛选掉不满足 overlap条件的
if overlap.min() < min_iou and max_iou < overlap.max():
continue
# 从原图中裁剪矩形
current_image = current_image[rect[1]:rect[3], rect[0]:rect[2],
:]
# 所有GT的中心点坐标
centers = (boxes[:, :2] + boxes[:, 2:]) / 2.0
# 这个地方的原理是判断每个GT的中心坐标是否在裁剪框Rect里面,
# 如果超出了那么下面的mask就全为0,那么mask.any()返回false,
# 也即是说这次裁剪失败了。
m1 = (rect[0] < centers[:, 0]) * (rect[1] < centers[:, 1])
m2 = (rect[2] > centers[:, 0]) * (rect[3] > centers[:, 1])
# mask in that both m1 and m2 are true
mask = m1 * m2
# 是否有合法的盒子
if not mask.any():
continue
# 取走中心点落在裁剪区域中的GT
current_boxes = boxes[mask, :].copy()
# 取出中心点落在裁剪区域中的GT对应的标签
current_labels = labels[mask]
# 获取GT box和切割矩形的交点(左上角) A点
current_boxes[:, :2] = np.maximum(current_boxes[:, :2],
rect[:2])
# 调节坐标系,让boxes的左上角坐标变为切割后的坐标
current_boxes[:, :2] -= rect[:2]
current_boxes[:, 2:] = np.minimum(current_boxes[:, 2:],
rect[2:])
# 调节坐标系,让boxes的左上角坐标变为切割后的坐标
current_boxes[:, 2:] -= rect[:2]
# 返回结果
return current_image, current_boxes, current_labels
图片镜像¶
这种方式比较简单,就是将图片进行左右翻转,实现数据增强。
class RandomMirror(object):
# 随机镜像图片
def __call__(self, image, boxes, labels):
w = image.shape[1]
if random.randint(2):
# 图片翻转
image = image[:, ::-1]
# boxes的坐标也需要相应改变
boxes = boxes.copy()
boxes[:, 0::2] = w - boxes[:, 2::-2]
return image, boxes, labels
执行了上面所有的数据增强操作之后就得到了代码中最终的数据增强图了,整个数据增强部分的工作也就结束了,有点快哈哈。
一个疑问¶
这里一个值得怀疑的地方是在亮度和对比度增强的时候没有将像素的值域限制在0-255范围内,似乎这一点是存在问题的?因此为了解决这一问题,我在每一个数据增强后面进行了打印,我发现在亮度增强和对比度增强之后像素值确实有超过了255的,但是最后减掉均值之后像素值的范围是在0-255的。我对这个过程充满了怀疑,按照常识亮度增强和对比度增强是需要crop的,这样难道不会影响最后的结果吗?希望和大家一起讨论这个问题,这个版本的ssd我仍存在疑问,阅读代码大家可以用,要真正训练自己的数据我还是建议使用weiliu89的caffe-ssd。
后记¶
本篇文章介绍了SSD的数据增强策略,结合上次的目标检测算法之SSD代码解析(万字长文超详细)推文,你是不是完全理解了SSD算法了呢?上次推文的地址如下:点这里
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次