DiffusionDet: Diffusion Model for Object Detection¶
1. 论文信息¶
标题:DiffusionDet: Diffusion Model for Object Detection
作者:Shoufa Chen, Peize Sun, Yibing Song, Ping Luo
原文链接:https://arxiv.org/abs/2211.09788
代码链接:https://github.com/ShoufaChen/DiffusionDet
2. 引言¶
扩散模型(diffusion models)在利用深度网络的生成模型中,取得了非常不错的成绩,达到了SOTA的水准。而且扩散模型在图片生成任务中超越了原SOTA:GAN,并且在诸多应用领域都有出色的表现。而扩散模型在生成模型中的成功经验不禁让人好奇,其能否在计算机视觉的判别模型中,同样发挥出较好的效果。最近来自腾讯和HKU的一份工作给出了肯定的答案。
首先简单回顾下最近目标检测(object detection)的趋势。目标检测的目的是在一个图像中,预测一组bounding box和相关的class label。作为一项基本的视觉识别任务,它已经成为许多相关识别场景的基石。现有的目标检测方法随着候选的bounding box的选取方式的发展而不断发展,即从经验的先验知识到设立参数来进行回归目标的学习。在CNN时代,大多数检测器通过在经验设计的候选对象上定义回归和分类来解决检测任务。最近,DETR提出了可学习对象query,消除手工设计的组件,在我的观点里,这是第一次成功建立端到端目标检测的方法。
本文就提出了一个新的疑问:: is there a simpler approach that does not even need the surrogate of learnable queries? 就是能不能有一种简单的方法来完成科学系的查询,同时也不需要生成surrogate。基于diffusion的相关知识,论文通过设计一个新颖的框架来回答这个问题,该框架可以直接从一组随机框中检测object。我们希望从纯随机的box中(如纯粹的高斯噪声)开始,逐步refine这些boxes的位置和大小,直到它们完美地覆盖目标对象。这种从噪声到盒子的方法不需要启发式的对象先验,也不需要可学习的查询,进一步简化了对象候选。从完全随机的noise到盒范式的原理类似于去噪扩散模型中的噪声到图像过程[15,35,79],这是一类基于似然的模型,通过学习到的去噪模型逐步去除图像中的噪声来生成图像。
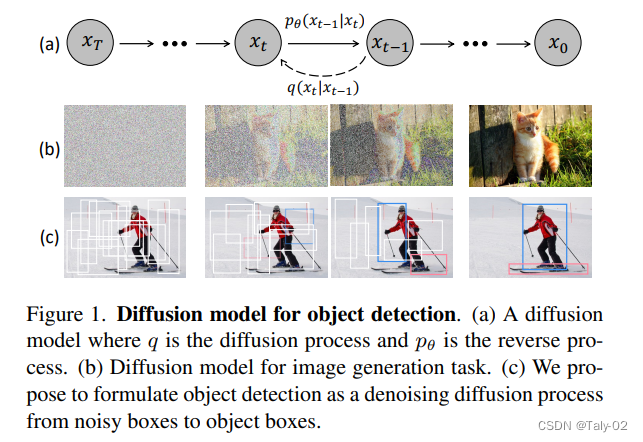
从下图可以看出来,由于采用了diffusion的结构,这个模型没有利用任何anchor选取上的先验,也不是像完全的可学习参数一样,需要进行相应的初始化,再消耗较长的时间来进行调整。
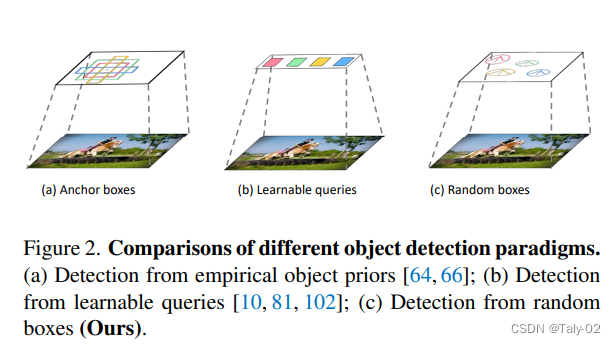
其实论文提出的模型非常简单但经典,就是目标检测中常用的backbone+neck。论文主要聚焦于训练策略与推理策略上的调整和改进,其实可以视为在给定现有检测网络的前提下所探索的新的网络优化方式。
3. 方法¶
首先论文回顾了目标检测和diffusion model的基础知识。目标检测的内容应该大家都比较熟悉,就不再回顾了。而diffusion model的形式如下:

扩散模型是一类受非平衡热力学启发的基于likelihood的模型。这些模型通过逐渐向样本数据添加噪声,定义了马尔可夫扩散前向过程链。
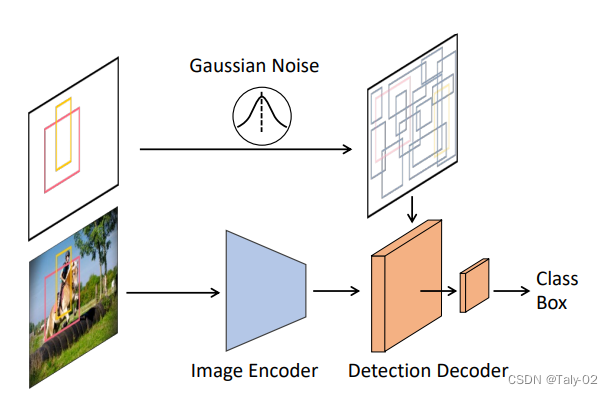
如上图,论文的结构其实非常的简单。首先利用image的encoder从输入image中提取相应的特征。检测的decoder则是以noise的boxes为输入,来预测类别的label和目标检测框的坐标。在训练过程中,将高斯噪声添加到ground-truth的noise box中,来构造相应的结构。在inference中,噪声的框则从高斯噪声采样中得到。
其实结构很简单,关键是训练和测试的算法步骤,这篇论文的写作同样值得学习,组织的非常好,来看伪代码:


在训练阶段:
-
Ground truth boxes padding. ROI的数量在不同图像中也不完全一致。因此,本文首先将一些额外的框填充到原始真值框中,使所有框相加为固定数量。
-
Box corruption. 我们将高斯噪声添加到填充的真值框中。噪声尺度由α控制,α在不同的时间步长t中采用单调递减的cosine值。
-
Training losses. 目标检测器将N个框作为输入,并预测类别分类和框坐标。论文将set prediction loss应用于预测集合。我们通过最优运输分配方法选择成本最小的前k个预测,为每个真值框分配多个预测。
在推理阶段:
-
Sampling step. 在每个采样步骤中,来自最后采样步骤的随机框或估计框被送到检测解码器,以预测类别和边界框坐标。
-
Box renewal. 在每个采样步骤之后,可以将预测的框粗略地分类为两种类型,期望的和不期望的预测。期望的预测包含正确定位在相应对象上的框,而不期望的预测任意分布。
-
Once-for-all. 由于随机框的设计,方法可以使用任意数量的随机框和采样步骤来评估DiffusionDet。
4. Experiments¶
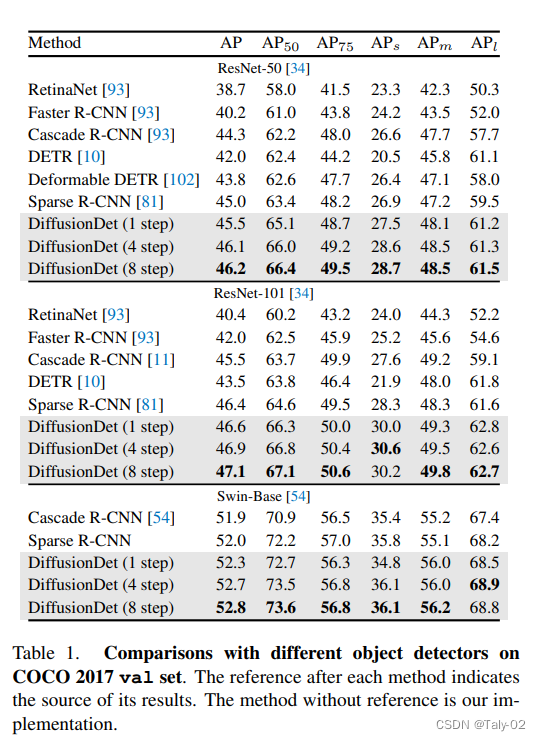
论文的结果似乎也很让人满意,成功地展示了diffusion model在感知任务上的优化也是可行的。而ResNet-50的最好结果为46.2,似乎也说明了对于感知任务,似乎特征才是最为最为关键的,优化方式的改进似乎没有想象中的那么有效果。
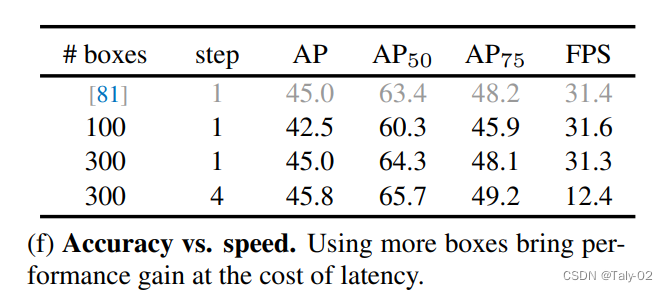
消融实验中值得关注的是,不同于其他的目标检测方法,本文提出的方法如果增加step,速度显著变慢的情况瞎,AP上涨的幅度也不大,所以这个trade-off做的可能不是特别到位。
5. Conclusion¶
在这项工作中,论文提出了一种新的检测范式DiffusionDet,通过将目标检测视为从噪声框到目标框的去噪扩散过程。我们的noise-to-box框架具有几个吸引人的特性。在标准检测baseline上进行充足的实验后,可以发现DiffusionDet实现了良好的性能。为了进一步探索扩散模型解决对象级识别任务的潜力,未来的几项工作是有益的。
本文总阅读量次