1. 前言¶
前面介绍了在小目标检测上另辟蹊径的SNIP算法,这一节来介绍一下SNIP的升级版SNIPER算法,这个算法的目的是减少SNIP的计算量。并且相比于SNIP,基于Faster RCNN(ResNet101作为Backbone)的实验结果显示SNIPER的mAP值比SNIP算法提升了4.6个百分点,所以效果也还是非常不错的。在单卡V100上,每秒可以处理5涨图像,这个速度在two-stage的算法中来看并不快,但是效果是非常好。
2. 介绍¶
SNIP算法借鉴了多尺度训练的思想进行训练,所谓多尺度训练就是用图像金字塔作为模型的输入,这种做法虽然可以提高模型效果,但是计算量的增加也非常明显,因为模型需要需要处理每个尺度的图像的每个像素。
针对这一缺点,SNIPER(Scale Normalization for Image Pyramids with Efficient Resampling)算法通过引入context-regions这个概念(论文中使用chips这个单词来表示这些区域,chips的中文翻译就是碎片,比较形象)使得模型不再需要处理每个尺度图像的每个像素点,而是选择那些对检测最有帮助的区域进行训练,这样就大大减少了计算量。
这些chips主要分为2个类别:
- positive chips 这些
chips包含Ground Truth。 - neigative chips 这是从RPN网络输出的ROI抽样获得的,这些
chips可以理解为是难分类的背景,而那些容易分类的背景就没必要进行多尺度训练了。
最后,模型只处理这2类chips,而不是处理整个图像,这样既可以提升效果也可以提升速度。因此,论文的核心就是如何选择positive chips 和 neigative chips。
3. 算法原理¶
3.1 positive chip的选择过程¶
positive chip 选择的出发点是希望一个chip中尽可能包含尺度合适的ground truth box。这里假设有n个scale,并且这n个scale用{s_1,s_2,...,s_n}来表示,C^i表示每张图像在尺度为i时获得的chip集合。另外用C_{pos}^{i}表示positive chip 集合,用C_{neg}^{i}表示neigative chip 集合。
假设一个区域的范围是R_{i}=[r_{min}^i,r_{max}^i],其中i\in [1, n],表示尺度,R_i表示对于尺度i来说,哪些尺寸范围的ground truth box 才可以被选中选进chip,在R^i表示范围内的ground truth box集合用G_i表示,每个chip都希望可以尽可能多的包含ground truth box ,而且只有当某个ground truth box 完全包含在一个chip中才说明该chip包含了这个ground truth box ,这样得到的尺度i的positive chip集合就是C_{pos}^i。
最后,每个ground truth box就能以一个合适的尺度存在于chip中,这样就可以大大减少模型对背景区域的处理。
下面我们来看看SNIPER究竟是如何选择positive chip的,如Figure 1所示。
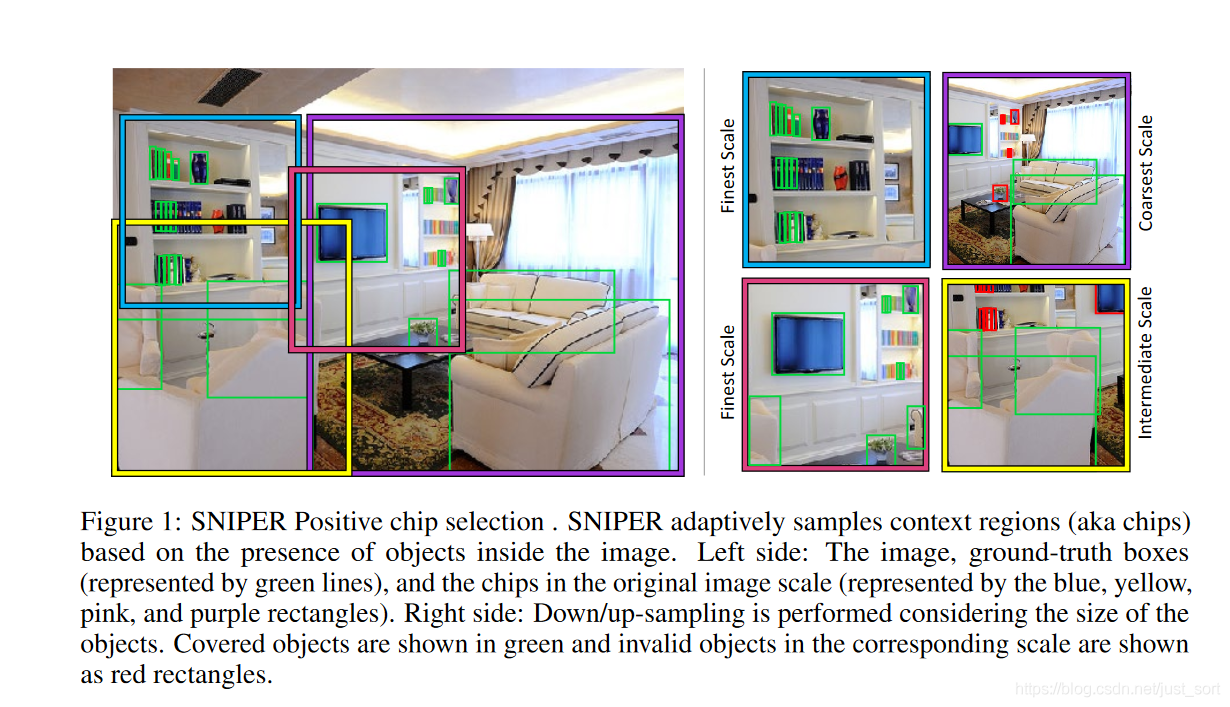
上图中左边的绿色实线表示了ground truth,各种颜色加粗的框(一共4个)表示SNIPER算法基于原图生成的chips,这些chips包含了所有的ground truth。而右边图是这4个Chips的具体内容,其中绿色实线框表示对于该chip来说有效的ground truth,而红色实线框表示对该chip而言无效的ground truth。因为不同scale图像的R_i范围有重叠,所以一个ground truth box可能会属于不同尺度的多个chip中,而且同一个ground truth box在同一个尺度中也可能属于多个chip。
3.2 negtive chip的选择过程¶
如果只基于前面的postive chip,那么会存在大量的背景区域没有参与训练,这就容易造成误检,传统的多尺度训练方法因为有大量背景区域参与训练所以误检率没那么高,但因为大多数背景区域都是非常容易分类的,所以可以想个办法来避免这部分计算,这就用到了negtive chip 的选择。接下来我们的问题就变成怎么判断哪些背景是容易的,那些背景是困难的,论文使用了一种相对简单的办法,即基于RPN网络的输出来构建negtive chip。
我们知道在Faster RCNN里面RPN网络是用来生成候选框的,这些候选框表示最有可能存在目标的区域,因为这些候选框是基于RPN粗筛选得到的,如果某个背景区域连候选框都没有,那说明这个背景区域是非常容易分类的,这些区域就没必要再参加训练了,真正参与训练的negtive候选框都是容易被误判的,这样就能减少误检率。
下面的Figure2展示了SNIPER的negative chip选择过程:

第一行表示输入图像和ground truth信息,第二行图像中的红色小圆点表示没有被positive chips(Chips) 包含的negative候选框,因为候选框较多,用框画出来的话比较繁杂,所以这里用红色小圆点表示。
橘色的框表示基于这些negtive候选框生成的negtive chips,也即是C_{neg}^i。每个negative chip的获得过程如下:
- 首先移除包含在C_{pos}^i的区域候选框
- 然后在R_i范围内,每个
chip都至少选择M个候选框。 - 在训练模型时,每一张图像的每个
epoch都处理固定数量的negative chip,这些固定数量的negative chip 就是从所有尺度的negative chip中抽象获得的。
总的来说,SNIPER要考虑的东西主要有label assignments, valid range tuning, positive/negative chip selection, 作者是在MxNet实现的,如果要自己剥离出来(比如在Pytorch上)还是比较麻烦的,希望后续mmdection会提供一下实现,或者哪位好心人去剥离一下。
另外,最近在知乎上冲浪看到中科院一个大佬提出了一个Stitcher: Feedback-driven Data Provider for Object Detection ,很是有趣啊,简单来说就是和Mosaic相反的一个思路,关于Mosaic可以看我们公众号的这篇文章:【从零开始学习YOLOv3】3. YOLOv3的数据加载机制和增强方法 ,然后这篇文章可以看 如何显著提升小目标检测精度?深度解读Stitcher:简洁实用、高效涨点。我想说的就是在小目标问题上,有很多前辈做了非常多开脑洞和有意义的东西,这里向他们表示致敬和感谢。
4. 实验结果¶
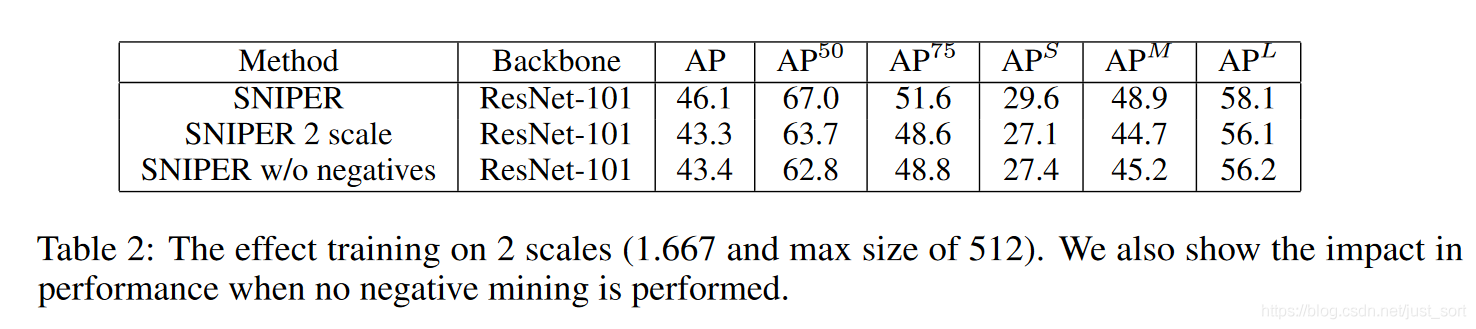
下面的Table2展示了是否有negative chip以及scale的个数对实验结果的影响。因为AP值的计算和误检是有关的,而没有negative chip 参与训练时误检会变多,所以AP会变低。然后论文采用的默认尺度个数是3,这里为了测试尺度个数对效果的影响,去掉了最大尺寸的scale,保留了其它两个scale来训练,结果显示AP下降明显。
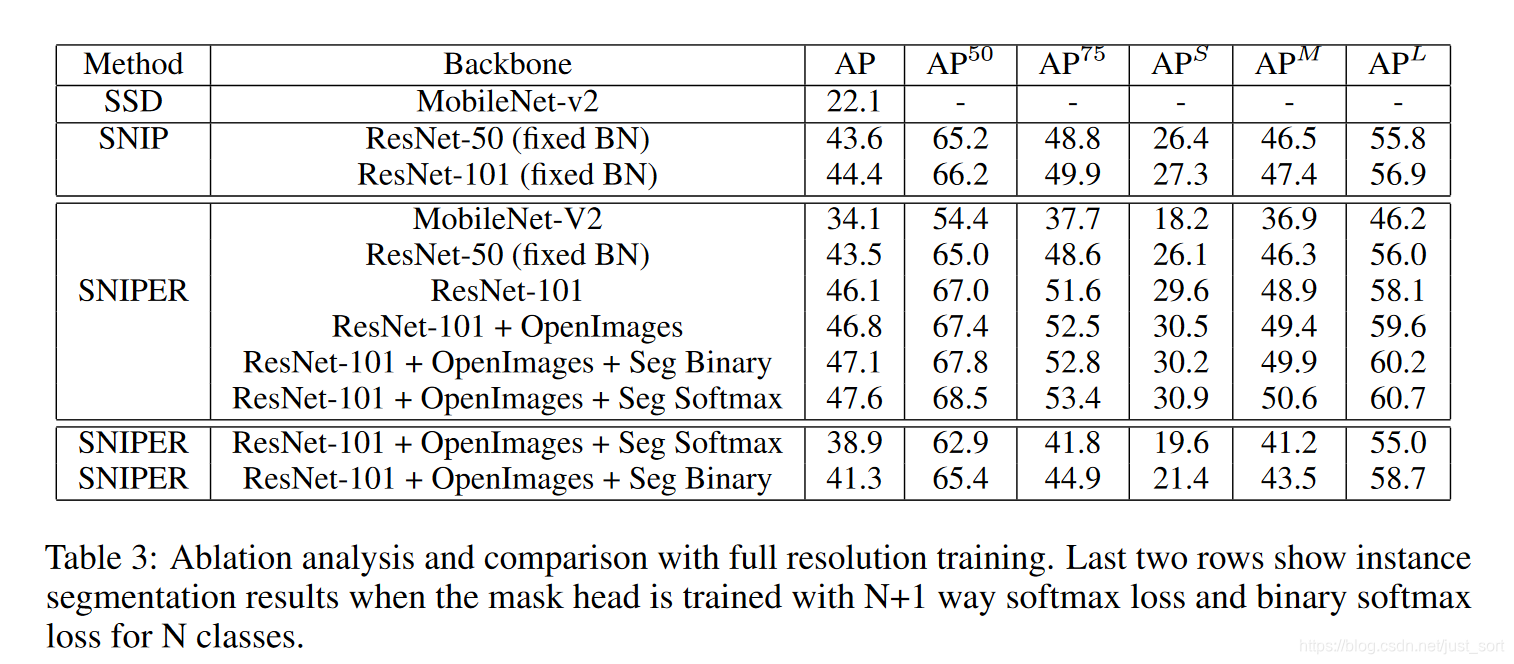
而Table3则展示了SNIPER算法和其它算法的对比,除了最后两行是实例分割的结果之外,剩下的都是检测的结果对比。
5. 总结¶
简单来说本文就是在SNIP的基础上加了一个positive/negative chip selection,从实验结果来看是非常SOTA的,可以说碾压了Mosaic反应出来的结果。另外基于ResNet101的Faster RCNN架构结合SNIPER,精度超过了YOLOV4接近4个点,效果是非常好的。
6. 参考¶
- https://blog.csdn.net/u014380165/article/details/82284128?utm_source=blogxgwz5
- 论文原文:https://arxiv.org/pdf/1805.09300.pdf
- 官方MxNet代码:https://github.com/mahyarnajibi/SNIPER
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次