前言¶
接着昨天介绍的RCNN,我们知道RCNN需要把每一个可能有目标的候选框搜索出来,然后把每个候选框传入CNN提取特征,每一张图片要产生大约2K个候选框,而每个框对应的图像都要传入CNN,这个时间开销肯定是很难承受的。基于RCNN这个致命问题,Fast-RCNN出现了。
算法介绍¶
Fast-RCNN是在SPPNet和RCNN的基础上进行改进的。SPPNet的主要贡献是在整张图像上计算全局特征图,然后对于特定的proposal,只需要在全局特征图上取出对应坐标的特征图就可以了。但SPPNet仍然需要将特征保存在磁盘中,速度还是很慢。结合RCNN的思想,论文提出直接将候选框区域应用于特征图,并使用ROI Pooling将其转化为固定大小的特征图,最后再连接两个并行的分类头和回归头完成检测任务。整个算法可以用下面的图来表示:
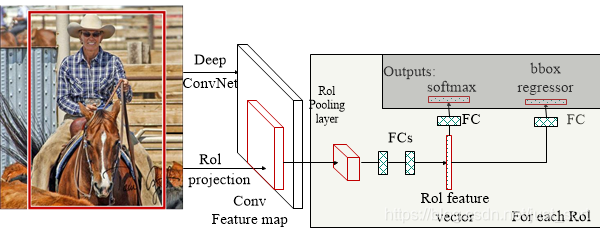
贡献&创新点¶
- Fast-RCNN 只对整个图像进行一次特征提取,避免R-CNN的上千次特征提取。
- 使用ROI Pooling层替换最后一层的Max Pooling层,巧妙避免RCNN中的将每个候选框Resize到固定大小的操作。
- Fast RCNN在网络的尾部采用并行的全连接层,可同时输出分类结果和窗口回归结果,实现了端到端的多任务训练,且不需要额外的特征存储空间(在R-CNN中特征需要保存到磁盘,以供SVM和线性回归器训练)。
- 使用SVD矩阵分解算法对网络末端并行的全连接层进行分解,加速运算。
ROI Pooling层¶
Fast-RCNN的核心是ROI池化层,它的作用是输入特征图的大小不定,但输出大小固定的输出特征图。而什么是ROI呢?ROI就是经过区域建议算法(Selective Search)生成的框经过卷积神经网络网络提取特征后的特征图上的区域,每一个ROI对应了原图的一个区域建议框,只有大小变化了,相对位置没有发生改变。这个过程可以用下图表示:
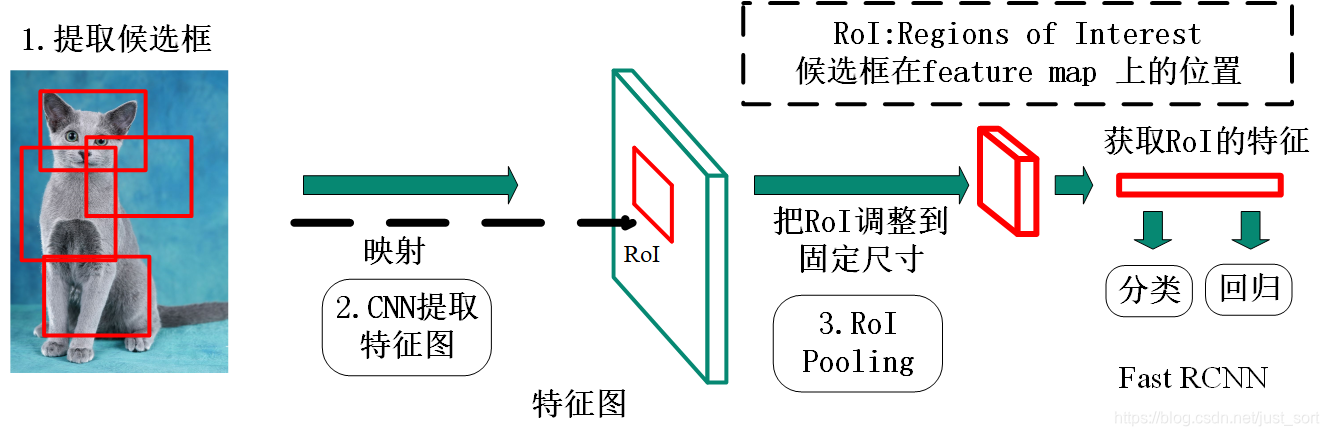
ROI Pooling层的输入有特征图和ROIs,特征图是经过CNN提取后的结果,ROIs表示Selective Search的结果,形状为N*5*1*1,其中N代表ROI的个数,5代表x,y,w,h。这里需要注意的是,坐标系的参数是针对原图的。
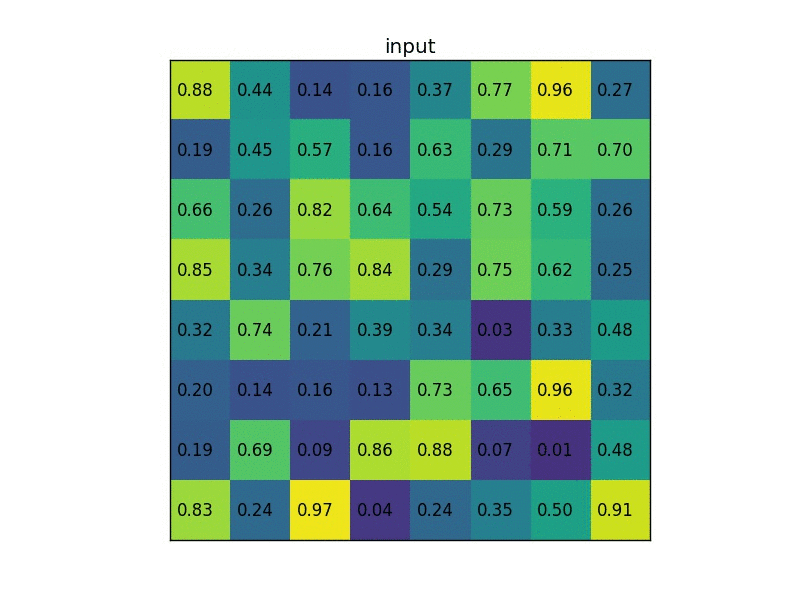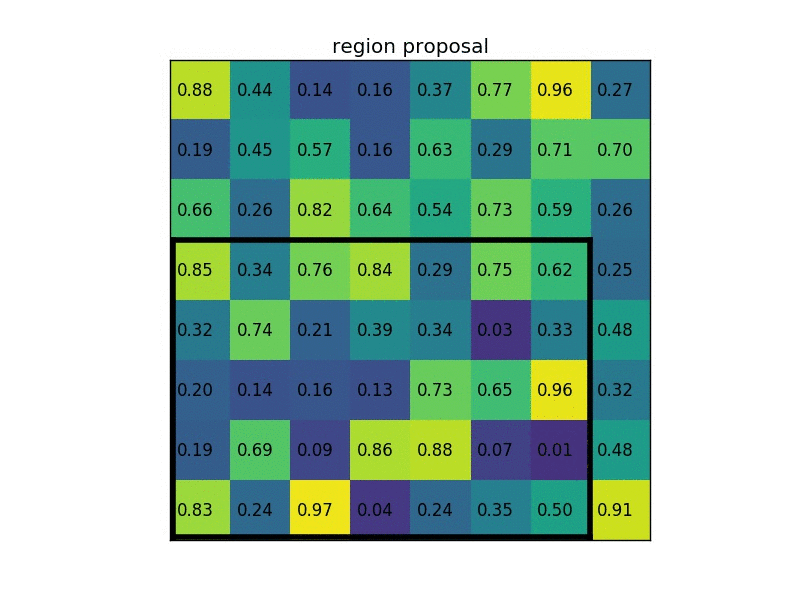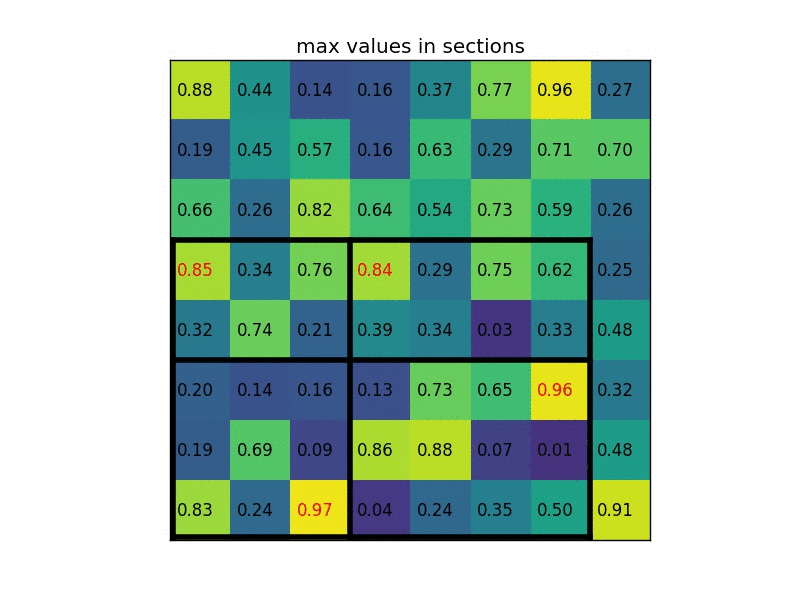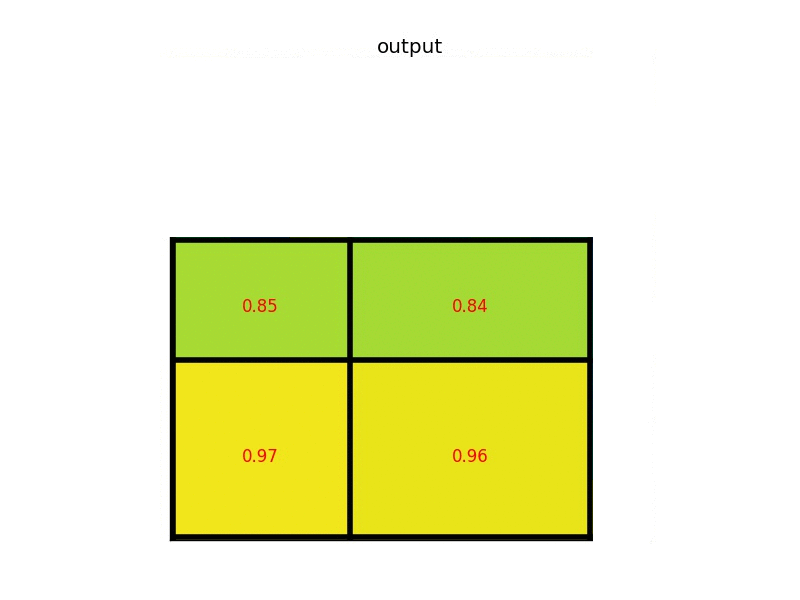
ROI Pooling的具体操作¶
- 根据输入图片,将ROI映射到特征图对应位置(映射规则就是直接把各个坐标除以“输入图片和特征图大小的比值”)
- 将映射后的区域划分为相同大小的sections,其中sections代表输出维度,例如7。
- 对每个sections进行最大池化操作。
最后上传一张经典动态图片,更好的表示这个过程:
源码¶
Fast-RCNN的作者rgbirshick依然给出了源码,有兴趣可以读一下: https://github.com/rbgirshick/fast-rcnn
本文总阅读量次