前言¶
前两天讲了RCNN和Fast-RCNN,相信对目标检测已经有了一些认识了。我们知道RCNN和Fast-RCNN都是双阶段的算法,依赖于候选框搜索算法。而搜索算法是很慢的,这就导致这两个算法不能实时。基于这个重大缺点,Faster-RCNN算法问世。
贡献¶
Fast-RCNN仍依赖于搜索候选框方法,其中以Selective Search为主。在Fast-RCNN给出的时间测试结果中,一张图片需要2.3s的前向推理时间,其中2s用于生成2000个ROI。可以看到整个算法的时间消耗几乎都在区域候选框搜索这个步骤了,如果我们能去掉候选框搜索这个过程是不是实时有希望了?Faster-RCNN就干了这件事,论文提出在内部使用深层网络代替候选区域。新的候选区域网络(RPN)在生成ROI的效率大大提升,一张图片只需要10毫秒!!!
网络结构¶
Faster-RCNN的网络结构如下图表示:
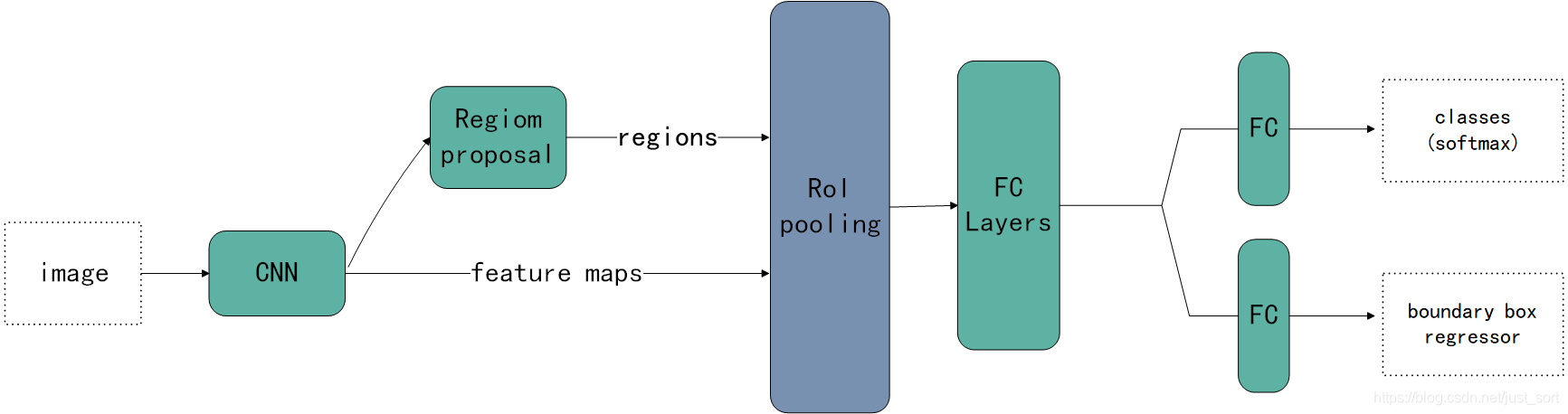
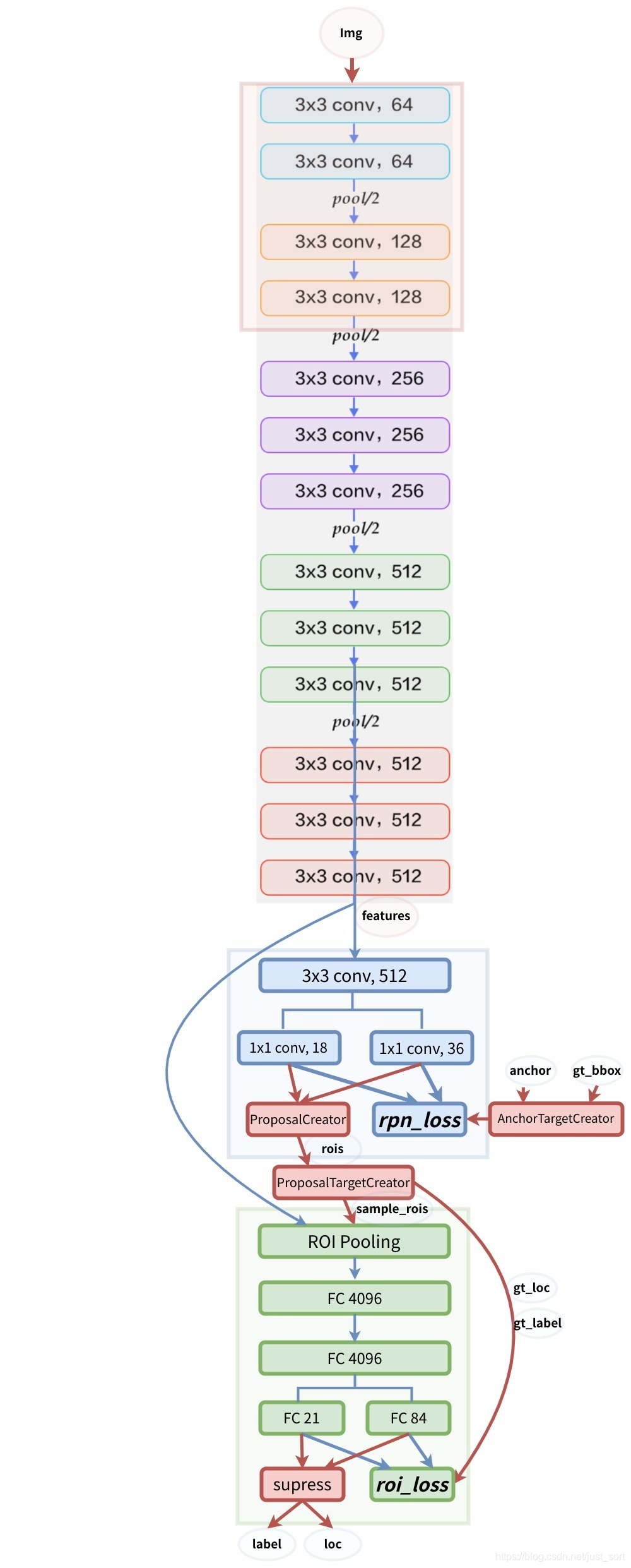
我们可以发现除了添加一个RPN网络之外,其他地方和Fast-RCNN是完全一致的。引用知乎上看到的一张更详细的网络结构如下:
RPN网络¶
RPN网络将第一个卷积网络(backbone,如VGG16,ResNet)的输出特征图作为输入。它在特征图上滑动一个3\times 3的卷积核,以使用卷积网络构建与类别无关的候选区域(候选框建议网络只用关心建议出来的框是否包含物体,而不用关系那个物体是哪一类的),我们将RPN产生的每个框叫做Anchor。
这里这样说肯定还是比较模糊,我引用一张训练时候的RPN的结构图然后固定输入分辨率和backbone为VGG16来解释一下。下面这张图是RPN架构:
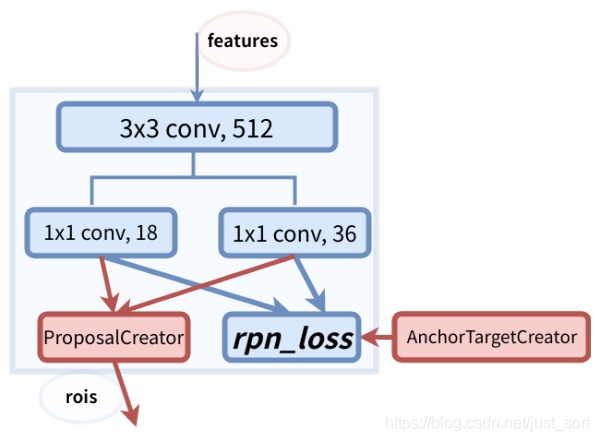
我们可以看到anchor的数量是和Feature Map的大小相关,对于特征图中的每一个位置,RPN会做k次预测。因此,在这里对每个像素,RPN将输出4\times k个坐标和2\times k个得分。然后由于使用了VGG16做Backbone,所以输入到RPN的特征图大小是原图H,W的\frac{1}{16}。对于一个512×62×37的feature map,有 62×37×9约等于20000个anchor。 也就是对一张图片,有20000个左右的anchor。这里可以看到RPN的高明之处,一张图片20000个候选框就是猜也能猜得七七八八。但是并不是20000个框我们都需要,我们只需要选取其中的256个。具体的选取规则如下:
- 对于每一个Ground Truth Bounding Box,选择和它IOU最高的一个anchor作为正样本。
- 对于剩下的anchor,选择和任意一个Ground Truth Bounding Box 的IOU大于0.7的anchor作为正样本,正样本的数目不超过128个。
- 负样本直接选择和Ground Truth Bounding Box 的IOU<0.3的anchor。正负样本的总数保证为256个。
RPN在产生正负样本训练的时候,还会产生ROIs作为Faster-RCNN(ROI-Head)的训练样本。RPN生成ROIs的过程(网络结构图中的ProposalCreator)如下:
- 对于每张图片,利用它的feature map, 计算 (H/16)× (W/16)×9(大概20000)个anchor属于前景的概率,以及对应的位置参数。
- 选取概率较大的12000个anchor
- 利用回归的位置参数,修正这12000个anchor的位置,得到RoIs
- 利用非极大值((Non-maximum suppression, NMS)抑制,选出概率最大的2000个RoIs
在前向推理阶段,12000和2000分别变为6000和3000以提高速度,这个过程不需要反向传播,所以更容易实现。
最后RPN的输出维度是2000\times 4或者300\times 4的tensor。
损失函数¶
在RPN网络中,对于每个Anchor,它们对应的gt_label(就是筛选到这个Anchor的那个ground truth框的label)要么是1要么是0,1代表前景,0代表背景。而,gt_loc则是由4个位置参数(tx,ty,tw,th)组成,这样比直接回归坐标更好。
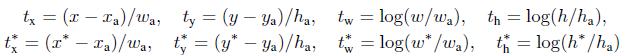
计算分类用的是交叉熵损失,而计算回归损失用的是SmoothL1Loss。在计算回归损失的时候只统计前景的损失,忽略背景的损失。
网络在最后对每一个框都有两种损失,即物体属于哪一类的分类损失(21类,加了个背景),位置在哪的回归损失。所以整个Faster-RCNN的损失是这4个损失之和。网络的目标就是最小化这四个损失之和。
训练¶
上面讲了,RPN会产生大约2000个ROIs,这2000个ROIs并不都拿去训练,而是利用ProposalTargetCreator选择128个ROIs用以训练。选择的规则如下:
- RoIs和gt_bboxes 的IoU大于0.5的,选择一些(比如32个)
- 选择 RoIs和gt_bboxes的IoU小于等于0(或者0.1)的选择一些(比如 128-32=96个)作为负样本
同时为了便于训练,对选择出的128个ROIs的对应的ground truth bbox的坐标进行标准化处理,即减去均值除以标准差。 对于分类问题,直接利用交叉熵损失。 而对于位置的回归损失,一样采用Smooth_L1Loss, 只不过只对正样本计算损失。而且是只对正样本中的这个类别4个参数计算损失。举例来说:
- 一个RoI在经过FC 84后会输出一个84维的loc 向量。如果这个RoI是负样本,则这84维向量不参与计算 L1_Loss。
- 如果这个RoI是正样本,属于label K,那么它的第 K×4, K×4+1 ,K×4+2, K×4+3 这4个数参与计算损失,其余的不参与计算损失。
测试¶
测试的时候保留大约300个ROIs,对每一个计算概率,并利用位置参数调整候选框的位置。最后用NMS筛一遍,就得到结果了。
后记¶
我感觉把原理讲清楚了?但可能内容有点多,还需要仔细看下才能懂。本文的创作引用了部分知乎上的文章,地址如下,非常感谢。 https://zhuanlan.zhihu.com/p/32404424
对本文细节有质疑或者不理解的地方可以留言,也可以去查看一下上面的知乎文章。作者还实现了一个非常简化版本的Faster-RCNN,只有2000行左右并且模型的MAP值不降反升,想进一步学习Faster-RCNN,可以进行源码实战啦,之后有机会写一篇我自己的源码实战分享,今天就分享到这里啦。github地址为: https://github.com/chenyuntc/simple-faster-rcnn-pytorch
本文总阅读量次