1. 前言¶
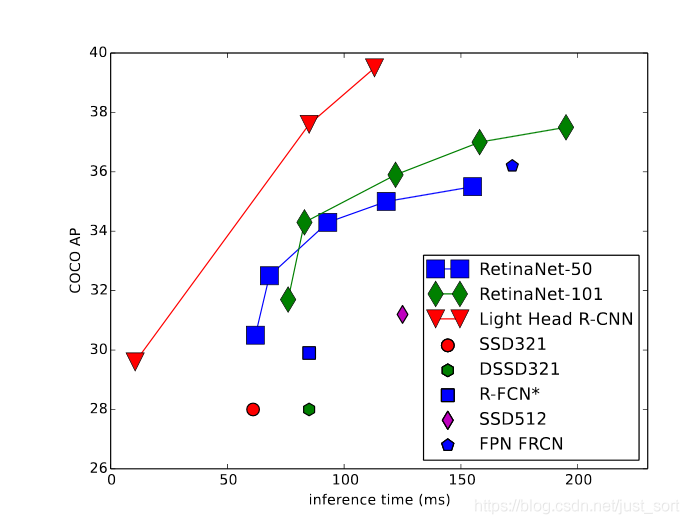
今天要为大家介绍一个RCNN系列的一篇文章,这也是COCO 2017挑战赛上获得冠军的方案。之前我们讲过了很多RCNN系列的检测论文了,例如Faster RCNN(请看公众号的Faster RCNN电子书)以及R-FCN 目标检测算法之NIPS 2016 R-FCN(来自微软何凯明团队) 。然后R-FCN是对Faster RCNN网络进行了改进,去掉了全连接层使得网络成为了全卷积网络,从而提升了检测速度,那么还能不能继续对R-FCN进行改进呢?Light-Head RCNN就实现了这一改进,我们先看一下Light-Head RCNN和一些主流的检测算法在精度和速度上的比较,如Figure1所示。
2. 具体方法¶
下面的Figure2为我们展示了Faster R-CNN,R-FCN,Light-Head RCNN在结构上的对比图。
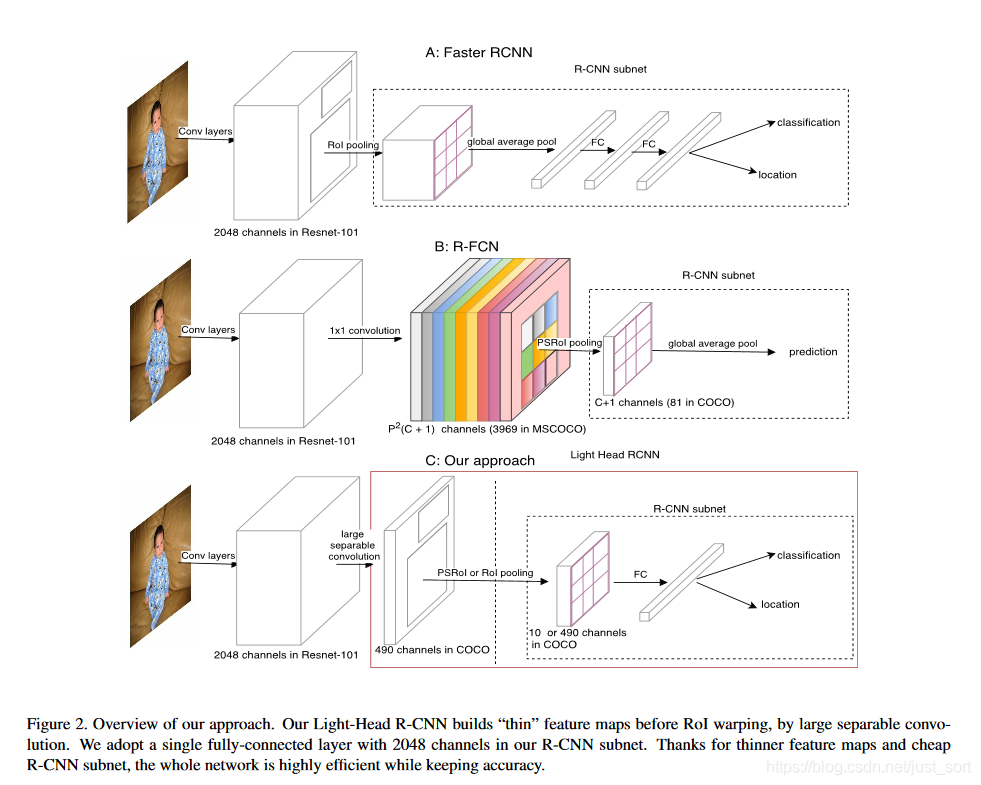
我们知道,由于Faster RCNN经过ROI Pooling之后需要对每个候选框进行检测,这是特别耗时的,特别是图片中目标很多时。针对这种情况,R-FCN将所有的权重共享,并引入了Position Sensitive Score Map来解决CNN的位置不敏感性,所以在R-FCN中将Score Map的通道设计为P^2(C+1)个,因为对于COCO数据集来说就需要3969个通道,这样就极大的增加了运算的复杂度,基于这一点Light-Head RCNN的出发点就是是否可以将这个特征图变薄?但一旦将特征图变薄,那么R-FCN里面的vote方式产生预测结果就不能用了,所以需要增加全连接层做输出映射。
相对于Faster RCNN来讲,Light-Head RCNN的检测头部分是做了轻量化的,从上图可以看到Light-Head RCNN中的Region Proposal的通道数变小了,只有7\times 7\times 10=490,并且只有一个全连接层,参数量大幅减少了。
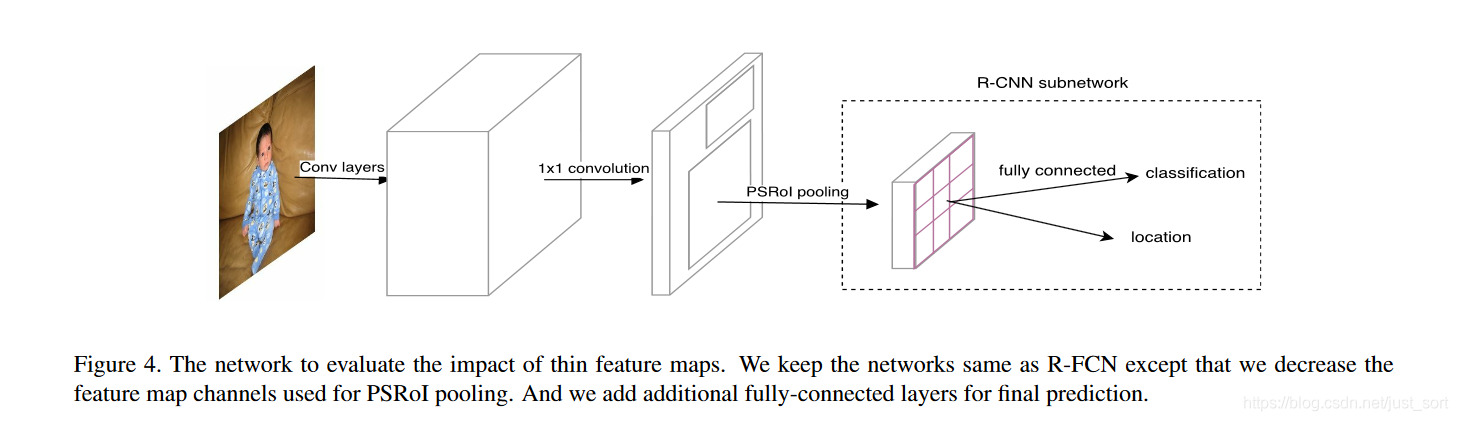
Light-Head RCNN的示意图如下:
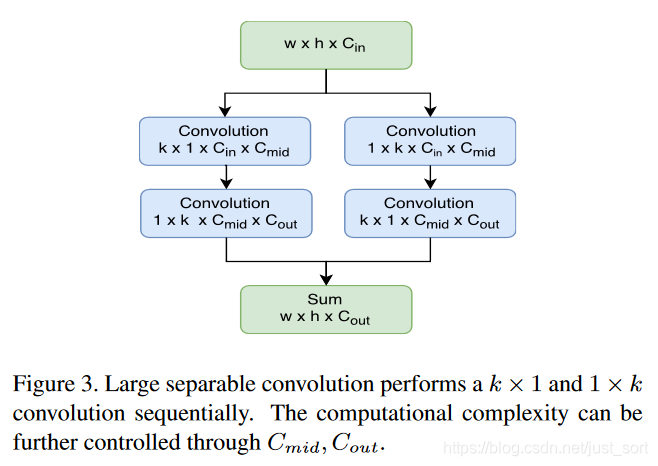
另外论文还在BackBone的最后一层卷积中加入了可分离卷积,以减少该层卷积的运算复杂度,同时实现两路卷积以增加不同的感受野。如Figure3所示:
总的来说,Light-Head RCNN的结构细节可以总结如下:
- 使用L(ResNet-1001)和S(Xception*)两种类型的网络分别做Backbone。
- RPN网络的输入是
conv4_x,定义了三个Anchor长宽比{1:1,1:2,2:1}和五个尺度{32^2,64^2,128^2,256^2,512^2},另外还使用了NMS来降低候选框重叠率获得ROI。 conv5_x输出的特征图通过large separable convolution 来获得更轻量的特征图。k设置为15,对于L网络C_{mid}=256,对于S网络,C_{mid}=64,C_{out}=10*p*p=490,整个Op的复杂可以通过C_{mid}和C_{out}来控制。- 将ROI和轻量化的特征图共同作为PSROI 或ROI pooling的输入,得到10 或者 490个通道的特征图。
- Light-Head RCNN subnet部分使用了一个通道数为2048的全连接层来改变前一层特征图的通道数,最后再通过两个全连接层实现分类和回归。
还需要注意的是这里的S(Xception*)类型BackBone网络结构是类似Xception的一个网络,结构如下:
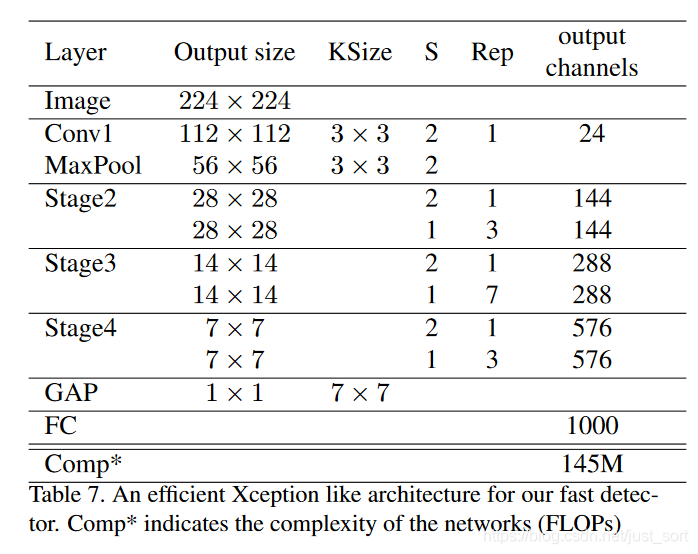
3. 实验¶
实验部分内容很多,感兴趣的可以去看看原始论文,我这里只贴一下最终的结果。
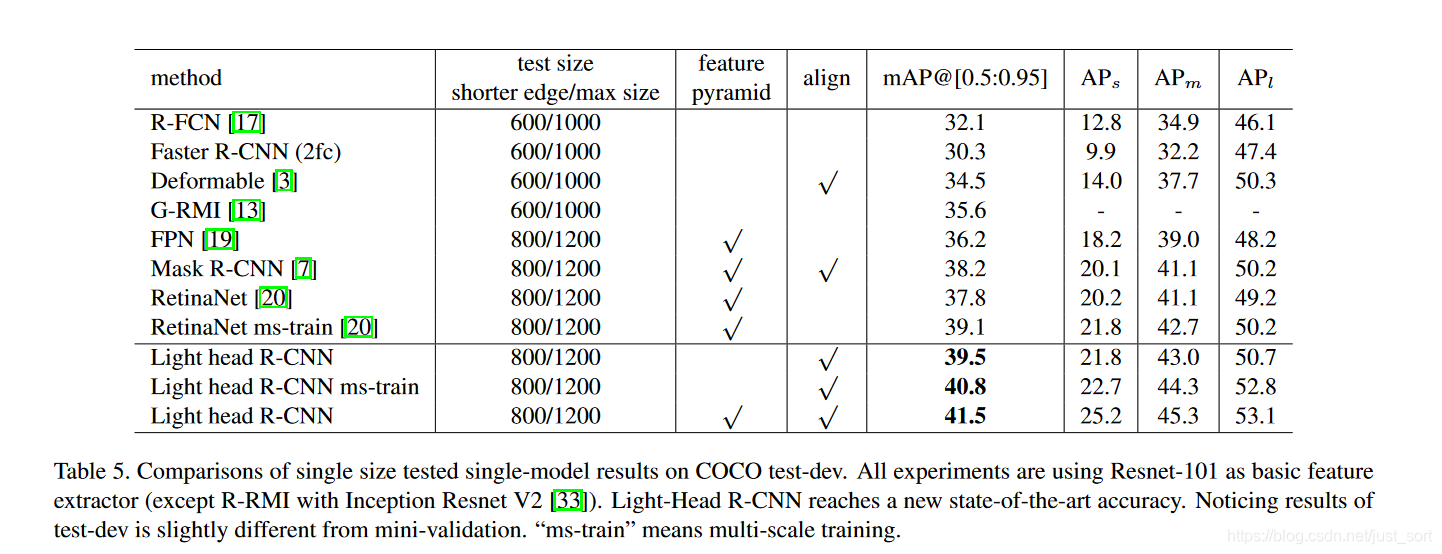
基于ResNet101的Light-Head RCNN的测试结果如下,可以看到Light-Head RCNN精度很高:
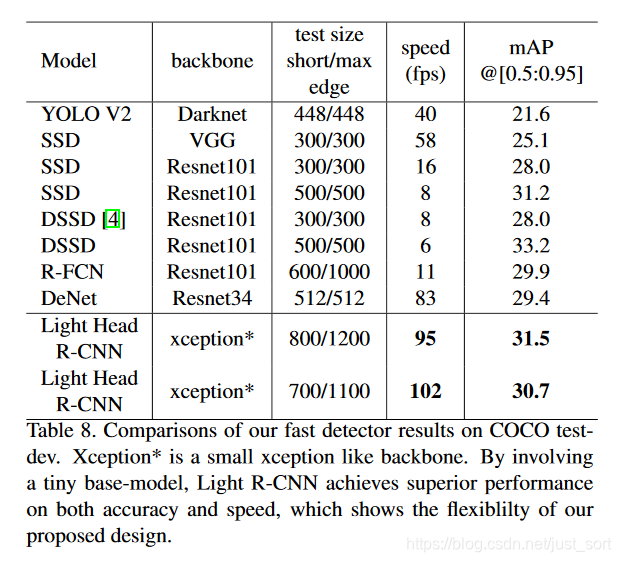
下面是基于Xception*的Light-Head RCNN的结果,可以看到速度有较大提升,并且精度也能保持得比较好。在mAP达到30的情况下可以在Titan Xp上跑到102FPS。
4. 总结¶
总的来说这篇论文没有太多花哨的操作,而是仔细分析了R-FCN效率慢的原因,并加以改进。在使用轻量级BackBone的条件下达到了极高的速度并且精度也保持SOTA级别。
5. 参考¶
- https://zhuanlan.zhihu.com/p/31389174
- https://arxiv.org/abs/1711.07264
- 代码:https://github.com/zengarden/light_head_rcnn
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次