Towards Open World Object Detection -CVPR2021 Oral(开放世界中的目标检测)
首先基于一个现象:人类在对事物进行观察的时候,是能够检测到每个实例,并按照自己已知的知识来对每个实例进行分类,有认知的归属到对应类别,无认知的归属到未知(unknown),而过往的深度学习检测任务所完成的工作只能对已有认知的实例进行定位和分类,所以作者提出,能否使得检测算法达到更近似人类的认知体验?所以作者提出了“开放世界目标检测”任务。作者原文中对这个任务的解释如下:
1)在没有明确监督的情况下,将尚未引入该对象的对象识别为“未知”。
2)在逐步接收到相应的标签时,逐步学习这些已识别的未知类别,而不会忘记先前学习的课程。
对该任务的个人理解:
1)在训练集中无明确的某类别实例标签时,测试图像上的该类别实例能够实现检测并识别类别为未知
2)可以通过增量学习的方式,即保持已有知识库所学习到的知识正常使用,也能够逐步增加对新实例的正确类别识别。也就是该类别由“未知”学习修改为其指定的正确类别。
作者还提供了一套被成为ORE的开放世界目标检测性能评估指标和评估工具,并测试了该套工具的合理性。
作者的认知中,开放世界的分类问题和检测问题并不是完全适用的,主要原因就是检测类算法在训练时,是将类别位置的实例作为背景来进行训练的。通过在训练时添加额外的辅助方式,检测器也大多会强行将当前位置类别实例归类到某一已知类别实例中,并输出一个较高的置信度。同时作者认为本文的主要贡献为:
1) 更贴近现实世界的检测需求设置
2)提出一种基于对比聚类,位置类别RPN网络和基于能量的未知类型识别的开放世界目标检测的结构ORE
3)提供了开放世界目标检测算法模型性能测试方案
4)所提出的检测结构,在增量检测问题上,达到了当前的最优技术水平
本文中,作者认为的开放世界目标检测器工作流程应如图1的第一行,首先是网络对开放世界已知的类别进行训练,并将遇见的未知类别的实例检测提供给用户来进行分辨,用户标注出自己感兴趣的实例类别后,增添到网络中,网络不必重新训练,仅通过增量学习自我更新就可对之前的检测类别和当前新增类别实现良好检测。

作者认为,深度网络中间层学习到的隐藏层特征如果善加利用,是可以帮助学习清晰的已知类别和位置类别的特征表示的区别,从而避免上文提到的检测器大多会强行将当前位置类别实例归类到某一已知类别实例中,并输出一个较高的置信度的现象。第二点就是,因新事物与已知类别事物的不同,也就是特征空间的不重叠,所以也存在通过增量学习,在不影响原有类别识别的情况下,让网络逐步的学习新的类别。而如何对隐藏层特征善加利用,作者就采用了对比聚类;我们也知道,在出现未知类别的实例时,可能会有很多该未知类别的实例出现,手工标记并不是可取的最优选项,所以作者提出了基于RPN的自动标记机制;然后作者在提出的ORE中,在分类头上基于已知类别和位置类别在特征空间能量图上的固有间隔,通过基于能量的分类头来区分已知类别实例和未知类别实例。如图1第二行,作者采用的是Faster RCNN的两阶段基础架构,首先用类无关的RPN来确定图像中的实例区域,接着对其进行每个实例区域,在ROI中进行对比聚类,确定其为已知类别或未知类别,并进行回归定位。其中“unkonwn aware RPN”用于自动标记,基于能量的分类头用于对未知实例的类别进行识别归类。
对比聚类¶
在隐藏层特征空间上类的区分性将是实现类别分离的理想特征。采用对比性聚类就是为了强制性的达到图1上最后一行中间图的效果,类内差尽量小,而类间差尽量大。每个已知类别会维护一个向量P_i是检测器中间层生成的特征向量,假设已知类别数为C,则特征向量表征为P={p_0,p_1,...,p_c},其中p_0代表未知类的特征向量。然后再建立一个F_{store}={q_0,...q_c}用来存储训练过程中的临时特征向量,每个类的特征向量存在其对应位置。最后在常规损失函数上再叠加一个对比聚类损失来达到强制降低类内差,增大类间差的效果。原文中该部分的流程图如下,其中I_b是不叠加对比聚类损失的轮数,用以初始化已知类别的特征向量,I_p表示,在迭代轮数大于I_b后,每轮都计算对比聚类的损失,并每I_p轮进行一次特征向量更新(有点像混合高斯背景建模了):

基于RPN的自动标记机制¶
核心就是利用RPN的建议框类别无关特性,将RPN提取的置信度最高的前K个背景建议框作为位置对象的建议框位置向后传递。
基于能量的分类头¶
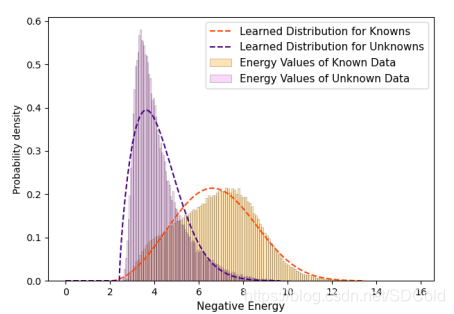
首先是基于前面提到的对比聚类将不同类别的特征表征尽量的拉开了,这里作者选择对不同类别的概率密度函数进行建模,作为不同类别的区分,作者用图进行了说明。
增量学习¶
文章最开始,作者提到了,开放世界目标检测要实现“可以通过增量学习的方式,即保持已有知识库所学习到的知识正常使用,也能够逐步增加对新实例的正确类别识别。也就是该类别由“未知”学习修改为其指定的正确类别”。所以作者就调研了针对该类问题的不同处理方式,最后选了个最简约的--每个类至少存储Nex个平衡的样本(这里应该是指具有类别代表性的样本),然后用增量学习进行微调。
实验结论¶
作者在这个部分提供了一套评估协议,用来评估检测模型识别已知类、未知类以及逐步学习未知类的性能。作者是在VOC和COCO数据集上做的实验,具体就是训练时把训练集按照类别分成t组,然后规定每个组有一个时刻\tau,在这个时刻前,T_{\tau}里的类别被视为是未知的,在这个时刻前的,就认为是已知的类别了。而在测试时,用了VOC的测试集和COCO的Val集,然后训练集的每组保留1K张做验证。
评估标准¶
\frac{P_K}{P_{K{\bigcup}U}}-1其中P_K是已知类别上的测试精度,P_{K{\bigcup}U}是在已知+未知类别上的测试精度,在Recall 0.8下进行测试,并报告被错分为已知类别的未知类别物体的绝对数量。mAP是在阈值0.5下测得的。
实现细节¶
backbone采用的Resnet-50,对分类头上类别数可能会发生该表的问题,作者先假定了一个最大类别数,然后增量学习时引入新类时修改损失函数实现,而对视而不见的类别,即判断属于"未知"类别,但是用户不关心的类,修改它们分类的对数值为一个极大的负数值,从而是的他们在softmax上贡献尽量低(e^{-v}\rightarrow0)。RoI块的最后一个残差结构得到的2048维特征用于进行对比聚类。训练时,当训练集中第t组作为已知类别加入训练时,只有当前分组被标记(这句话我个人稍微有点歧义,目前是按照自己的理解写的,大家可以看作者的开源代码来确定具体执行流程)。当测试第t组时,则是之前的所有样本都会被标记,而第t组以后的会被标记为“未知“类别。Nex作者选择的50,后续章节则是有敏感性分析的实验表格来支撑这个值的选取。
可视化结果¶

在图(a)中,还没有学习过apple、orange等类别,但ORE模型能够正确地将这些目标识别为“未知”类。在图(b)中,当给定了apple、orange标签之后,ORE模型在保证之前person类准确识别的前提下,还正确识别了新标记的目标。
论文链接¶
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次