【GiantPandaCV 导语】最近因为工程需要,就去调研一下 open-set detection 算法,然后发现一篇不错的论文 《Towards Open-Set Object Detection and Discovery》。论文使用了额外的 memory 来当做网络的记忆缓存,在实现对未知类物体的坐标回归的同时,还挖掘了未知类物体潜在的类别。算法挺有意思的,里面也涉及了很多自己的知识盲点,于是和大家分享一下,一起研究研究。
论文地址:https://arxiv.org/abs/2204.05604
1.介绍¶
在之前的 open-set object detection (OSOD) 中,除了检测识别已知物体外,还会检测一些未知类别的物体,但把所有未知的物体都归到 “未知类”。该论文提出的 Open-Set Object Detection and Discovery (OSODD),不仅可以检测未知物体,还可以挖掘它们潜在的类别。OSODD 采用了两阶检测方式,先对已知物体和未知物体进行预测,然后通过无监督和半监督方式学习预测到的物体的表征并进行聚类,从而挖掘出未知物体的类别。
2.相关工作¶
略
3. 任务形式¶
在 OSODD 中,假设已知类为 Ck = {C1, C21,....,Cm};未知类为 Cu = {Cm+1, Cm+2, ..... Cm+n},Ck 和 Cu 没有交集。训练集只包含 Ck,而测试集是 Ck 和 Cu 的合集。模型的任务就是对所有物体进行定位和分类 I = [c, x, y, w, h],已知物体归于Ck,未知物体则归于 Cu。
4. 具体方法¶
论文提出的 OSODD 包含两个部分,分别是 Object Detection and Retrieval (ODR) 和 Object Category Discovery (OCD)。

- ODR 是一个带有两个记忆缓存的开集检测器,对于已知物体,检测器预测他们的位置信息和类别,对于未知物体,只预测其位置信息。其中已知物体和类别信息储存在 known memory 中,未知物体则储存在 working memory 中。
- OCD 则是主要利用 working memory 来挖掘未知物体的类别,包含了一个特征编码器和聚类辨别器。首先使用非监督对比学习方式,从 known 和 working memory 中训练一个编码器,在 latent space 中学习更好的物体表征。最后用 constrained k-means 来进行聚类。
4.1 Object Detection and Retrieval¶
open-set object detector 主要是对所有物体进行定位,同时对已知物物体进行分类,且把未知物体归到“unknown” 一类。文中使用了 faster-rcnn 作为模型的 backbone,利用了 RPN 对类别无感知的特性,把那些与 ground-truth 没有重叠且置信度比较高的候选框作为位置物体。为了让物体的特征更具有区别性,作者使用了对比损失,也就是计算从 ROI pooling 中得到的特征和模板之间的相差度:
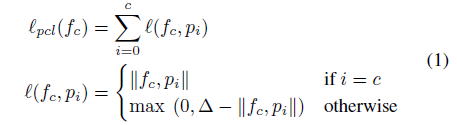
其中模板 pi 是该类别特征的滑动平均值。所以在 region of interest pooling 中的 loss 变成:
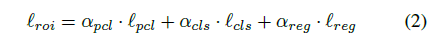
4.2 Object Category Discovery¶
因为未知物体的类别是不确定的,只能通过一些方式来挖掘出这些物体潜在的类别信息,文中采用了 DCT,主要是通过一种特殊的无参数学习的 k-mean 来估计潜在的类别数目。 为了更好地挖掘未知物体的潜在类别,作者在 OCD 中加入了一个 encoder,用来学习更有判别性的 embedding。在encoder 中使用 known memory 和 working memory 来进行对比学习,增大 positive pairs 的相似度,而减小 negative pairs的相似度,类似减小类内差而增大类间差,这样更有益于后面的聚类操作。对比学习的 InfoNCE loss 为:
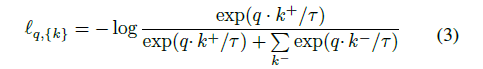
为了使得 embedding 有更加好的分布和创建更多的训练样本,作者还使用一种无监督增强方法,把 {k} 和 q 线性组合起来,代替原本的 {k},对应地,loss 中的虚拟标签也变成:

5.实验¶
在实验中,作者把数据分成三种,对应着不同的 Known / Unknown。对于已知类物体,采用 mAP 作为检测评价标准,对于未知类物体,则采用 UDR 和 UDP 作为检测评价标准:
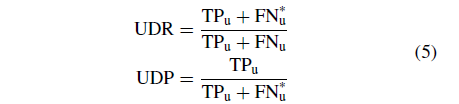
对于类别挖掘的评价指标,作者采用了聚类准确率、归一化互信息和聚类纯度:
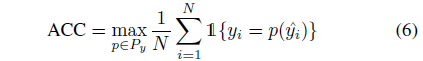
因为是 unknown class,所以不确定具体哪个物体的类别 ID具体是多少,Object Category Discovery (OCD) 也是通过 k-mean 来聚类。所以必须对unknown object 的label 进行排列组合,算出最大的那个 ACC,作为最终的结果。
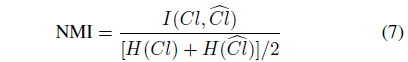

6. 结果与分析¶
作者在 Object Detection 和 Category Discovery 的baseline 上做了对比试验,还进行了多种组合的消融实验,证明文中提出的方法几乎在所有评价指标都达到了最优性能。



本文总阅读量次