1. 前言¶
昨天行云大佬找到我提出了他关于GiantPandaCV公众号出版的《从零开始学YOLOV3》电子书中关于原版本的YOLOV3损失的一个质疑,并给出了他的理解。昨天晚上我仔细又看了下原始论文和DarkNet源码,发现在YOLOV3的原版损失函数的解释上我误导了不少人。所以就有了今天这篇文章,与其说是文章不如说是一个错误修正吧。
2. 在公众号里面的YOLOV3损失函数¶
在我们公众号出版的YOLOV3的PDF教程里对原始的DarkNet的损失函数是这样解释的,这个公式也是我参照源码(https://github.com/BBuf/Darknet/blob/master/src/yolo_layer.c)进行总结的,。 我的总结截图如下:

其中S表示grid\ size,S^2表示13\times 13,26\times 26, 52\times 52。B代表box,1_{ij}^{obj}表示如果在i,j处的box有目标,其值为1,否则为0。1_{ij}^{noobj}表示如果i,j处的box没有目标,其值为1,否则为0。
BCE(binary cross entropy)的具体公式计算如下: BCE(\hat(c_i),c_i)=-\hat{c_i}\times log(c_i)-(1-\hat{c_i})\times log(1-c_i)
另外,针对YOLOV3,回归损失会乘以一个2-w*h的比例系数,w和h代表Ground Truth box的宽高,如果没有这个系数AP会下降明显,大概是因为COCO数据集小目标很多的原因。
我根据DarkNet的源码对每一步进行了梯度推导发现损失函数的梯度是和上面的公式完全吻合的,所以当时以为这是对的,感谢行云大佬提醒让我发现了一个致命理解错误,接下来我们就说一下。
3. 行云大佬的损失函数公式¶
接下来我们看一下行云大佬的损失函数公式,形式如下:
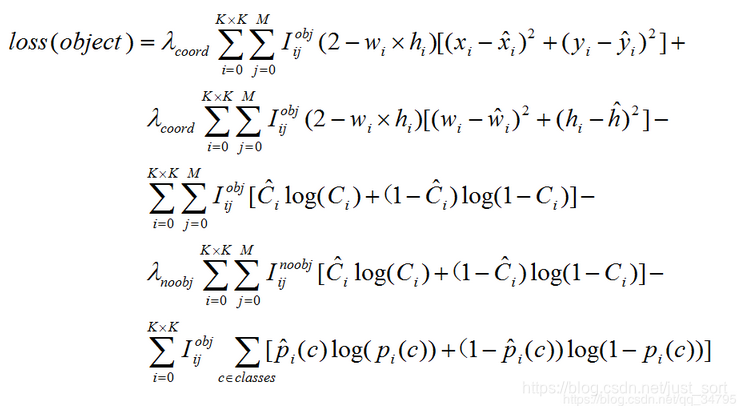
可以看到我的损失函数理解和行云大佬的损失函数理解在回归损失以及分类损失上是完全一致的,只有obj loss表示形式完全不同。对于obj loss,我的公式里面是方差损失,而行云大佬是交叉熵损失。那么这两种形式哪一种是正确的呢?
其实只要对交叉熵损失和方差损失求个导问题就迎刃而解了。
4. 交叉熵损失求导数¶
推导过程如下:
(1)softmax函数
首先再来明确一下softmax函数,一般softmax函数是用来做分类任务的输出层。softmax的形式为: S_i = \frac{e^{z_i}}{\sum_ke^{z_k}} 其中S_i表示的是第i个神经元的输出,接下来我们定义一个有多个输入,一个输出的神经元。神经元的输出为 z_i = \sum_{ij}x_{ij}+b 其中w_{ij}是第i个神经元的第j个权重,b是偏移值.z_i表示网络的第i个输出。给这个输出加上一个softmax函数,可以写成: a_i = \frac{e^{z_i}}{\sum_ke^{z_k}}, 其中a_i表示softmax函数的第i个输出值。这个过程可以用下图表示:
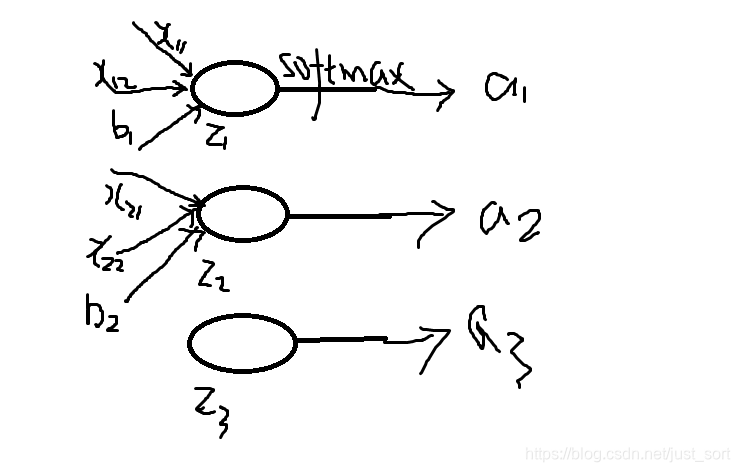
(2)损失函数
softmax的损失函数一般是选择交叉熵损失函数,交叉熵函数形式为: C=-\sum_i{y_i lna_i} 其中y_i表示真实的标签值
(3)需要用到的高数的求导公式
c'=0(c为常数)
(x^a)'=ax^(a-1),a为常数且a≠0
(a^x)'=a^xlna
(e^x)'=e^x
(logax)'=1/(xlna),a>0且 a≠1
(lnx)'=1/x
(sinx)'=cosx
(cosx)'=-sinx
(tanx)'=(secx)^2
(secx)'=secxtanx
(cotx)'=-(cscx)^2
(cscx)'=-csxcotx
(arcsinx)'=1/√(1-x^2)
(arccosx)'=-1/√(1-x^2)
(arctanx)'=1/(1+x^2)
(arccotx)'=-1/(1+x^2)
(shx)'=chx
(chx)'=shx
(uv)'=uv'+u'v
(u+v)'=u'+v'
(u/)'=(u'v-uv')/^2
我们需要求的是loss对于神经元输出z_i的梯度,求出梯度后才可以反向传播,即是求: \frac{\partial C}{\partial z_i}, 根据链式法则(也就是复合函数求导法则)\frac{\partial C}{\partial a_j}\frac{\partial a_j}{\partial z_i},初学的时候这个公式理解了很久,为什么这里是a_j而不是a_i呢?这里我们回忆一下softmax的公示,分母部分包含了所有神经元的输出,所以对于所有输出非i的输出中也包含了z_i,所以所有的a都要参与计算,之后我们会看到计算需要分为i=j和i \neq j两种情况分别求导数。
首先来求前半部分: \frac{\partial C}{ \partial a_j} = \frac{-\sum_jy_ilna_j}{\partial a_j} = -\sum_jy_j\frac{1}{a_j}
接下来求第二部分的导数:
- 如果i=j,\frac{\partial a_i}{\partial z_i} = \frac{\partial(\frac{e^{z_i}}{\sum_ke^{z_k}})}{\partial z_i}=\frac{\sum_ke^{z_k}e^{z_i}-(e^{z_i})^2}{(\sum_ke^{z_k})^2}=(\frac{e^z_i}{\sum_ke^{z_k}})(1 - \frac{e^{z_i}}{\sum_ke^{z_k}})=a_i(1-a_i)
- 如果i \neq j,\frac{\partial a_i}{\partial z_i}=\frac{\partial\frac{e^{z_j}}{\sum_ke^{z_k}}}{\partial z_i} = -e^{z_j}(\frac{1}{\sum_ke^z_k})^2e^{z_i}=-a_ia_j。
接下来把上面的组合之后得到: \frac{\partial C}{\partial z_i} =(-\sum_{j}y_j\frac{1}{a_j})\frac{\partial a_j}{\partial z_i} =-\frac{y_i}{a_i}a_i(1-a_i)+\sum_{j \neq i}\frac{y_j}{a_j}a_ia_j =-y_i+y_ia_i+\sum_{j \neq i}\frac{y_j}a_i =-y_i+a_i\sum_{j}y_j。
推导完成!
(5)对于分类问题来说,我们给定的结果y_i最终只有一个类别是1,其他是0,因此对于分类问题,梯度等于: \frac{\partial C}{\partial z_i}=a_i - y_i
5. L2损失求导数¶
推导如下:
我们写出L2损失函数的公式:
L2_{loss}=(y_i-a_i)^2,其中y_i仍然代表标签值,a_i表示预测值,同样我们对输入神经元(这里就是a_i了,因为它没有经过任何其它的函数),那么\frac{\partial C}{\partial z_i}=2(a_i - y_i),其中z_i=a_i。
注意到,梯度的变化由于有学习率的存在所以系数是无关紧要的(只用关心数值梯度),所以我们可以将系数省略,也即是:
\frac{\partial C}{\partial z_i}=a_i - y_i
6. 在原论文求证¶
可以看到无论是L2损失还是交叉熵损失,我们获得的求导形式都完全一致,都是output-label的形式,换句话说两者的数值梯度趋势是一致的。接下来,我们去原论文求证一下:


上面标红的部分向我们展示了损失函数的细节,我们可以发现原本YOLOV3的损失函数在obj loss部分应该用二元交叉熵损失的,但是作者在代码里直接用方差损失代替了。
至此,可以发现我之前的损失函数解释是有歧义的,作者的本意应该是行云大佬的损失函数理解那个公式(即obj loss应该用交叉熵,而不是方法差损失),不过恰好训练的时候损失函数是我写出的公式(obj loss用方差损失)。。。神奇吧。
7. 总结¶
本文根据行云大佬的建议,通过手推梯度并在原始论文找证据的方式为大家展示了YOLOV3的损失函数的深入理解,如果有任何疑问可以在留言区留言交流。
8. 参考¶
- YOLOV3论文:https://pjreddie.com/media/files/papers/YOLOv3.pdf
- DarkNet原始代码:https://github.com/BBuf/Darknet/blob/master/src/yolo_layer.c
- 行云大佬博客:https://blog.csdn.net/qq_34795071/article/details/92803741
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次