史上最详细的Yolov3边框预测分析
我们读yolov3论文时都知道边框预测的公式,然而难以准确理解为何作者要这么做,这里我就献丑来总结解释一下个人的见解,总结串联一下学习时容易遇到的疑惑,期待对大家有所帮助,理解错误的地方还请大家批评指正,我只是个小白哦,发出来也是为了与大家多多交流,看看理解的对不对。
论文中边框预测公式如下:
其中,Cx,Cy是feature map中grid cell的左上角坐标,在yolov3中每个grid cell在feature map中的宽和高均为1。如下图1的情形时,这个bbox边界框的中心属于第二行第二列的grid cell,它的左上角坐标为(1,1),故Cx=1,Cy=1.公式中的Pw、Ph是预设的anchor box映射到feature map中的宽和高(anchor box原本设定是相对于416*416坐标系下的坐标,在yolov3.cfg文件中写明了,代码中是把cfg中读取的坐标除以stride如32映射到feature map坐标系中)。
最终得到的边框坐标值是bx,by,bw,bh即边界框bbox相对于feature map的位置和大小,是我们需要的预测输出坐标。但我们网络实际上的学习目标是tx,ty,tw,th这4个offsets,其中tx,ty是预测的坐标偏移值,tw,th是尺度缩放,有了这4个offsets,自然可以根据之前的公式去求得真正需要的bx,by,bw,bh4个坐标。至于为何不直接学习bx,by,bw,bh呢?因为YOLO 的输出是一个卷积特征图,包含沿特征图深度的边界框属性。边界框属性由彼此堆叠的单元格预测得出。因此,如果你需要在 (5,6) 处访问该单元格的第二个边框bbox,那么你需要通过 map[5,6, (5+C): 2*(5+C)] 将其编入索引。这种格式对于输出处理过程(例如通过目标置信度进行阈值处理、添加对中心的网格偏移、应用锚点等)很不方便,因此我们求偏移量即可。那么这样就只需要求偏移量,也就可以用上面的公式求出bx,by,bw,bh,反正是等价的。另外,通过学习偏移量,就可以通过网络原始给定的anchor box坐标经过线性回归微调(平移加尺度缩放)去逐渐靠近groundtruth.为何微调可看做线性回归看后文。
这里需要注意的是,虽然输入尺寸是416\times 416,但原图是按照纵横比例缩放至416\times 416的, 取 min(w/img_w, h/img_h)这个比例来缩放,保证长的边缩放为需要的输入尺寸416,而短边按比例缩放不会扭曲,img_w,img_h是原图尺寸768,576, 缩放后的尺寸为new_w, new_h=416,312,需要的输入尺寸是w,h=416*416.如图2所示:
剩下的灰色区域用(128,128,128)填充即可构造为416*416。不管训练还是测试时都需要这样操作原图。pytorch代码中比较好理解这一点。下面这个函数实现了对原图的变换。
def letterbox_image(img, inp_dim):
"""
lteerbox_image()将图片按照纵横比进行缩放,将空白部分用(128,128,128)填充,调整图像尺寸
具体而言,此时某个边正好可以等于目标长度,另一边小于等于目标长度
将缩放后的数据拷贝到画布中心,返回完成缩放
"""
img_w, img_h = img.shape[1], img.shape[0]
w, h = inp_dim#inp_dim是需要resize的尺寸(如416*416)
# 取min(w/img_w, h/img_h)这个比例来缩放,缩放后的尺寸为new_w, new_h,即保证较长的边缩放后正好等于目标长度(需要的尺寸),另一边的尺寸缩放后还没有填充满.
new_w = int(img_w * min(w/img_w, h/img_h))
new_h = int(img_h * min(w/img_w, h/img_h))
resized_image = cv2.resize(img, (new_w,new_h), interpolation = cv2.INTER_CUBIC) #将图片按照纵横比不变来缩放为new_w x new_h,768 x 576的图片缩放成416x312.,用了双三次插值
# 创建一个画布, 将resized_image数据拷贝到画布中心。
canvas = np.full((inp_dim[1], inp_dim[0], 3), 128)#生成一个我们最终需要的图片尺寸hxwx3的array,这里生成416x416x3的array,每个元素值为128
# 将wxhx3的array中对应new_wxnew_hx3的部分(这两个部分的中心应该对齐)赋值为刚刚由原图缩放得到的数组,得到最终缩放后图片
canvas[(h-new_h)//2:(h-new_h)//2 + new_h,(w-new_w)//2:(w-new_w)//2 + new_w, :] = resized_image
return canvas
而且我们注意yolov3需要的训练数据的label是根据原图尺寸归一化了的,这样做是因为怕大的边框的影响比小的边框影响大,因此做了归一化的操作,这样大的和小的边框都会被同等看待了,而且训练也容易收敛。既然label是根据原图的尺寸归一化了的,自己制作数据集时也需要归一化才行,如何转为yolov3需要的label网上有一大堆教程,也可参考我的文章:将实例分割数据集转为目标检测数据集(https://zhuanlan.zhihu.com/p/49979730),这里不再赘述。
这里再解释一下anchor box,YOLO3为每种FPN预测特征图(13*13,26*26,52*52)设定3种anchor box,总共聚类出9种尺寸的anchor box。在COCO数据集这9个anchor box是:(10\times 13),(16\times30),(33\times23),(30\times 61),(62\times 45),(59\times 119),(116\times 90),(156\times 198),(373\times 326)。
分配上,在最小的13\times 13特征图上由于其感受野最大故应用最大的anchor box (116\times 90),(156\times 198),(373\times 326),(这几个坐标是针对416\times 416下的,当然要除以32把尺度缩放到13\times 13下),适合检测较大的目标。中等的26\times 26特征图上由于其具有中等感受野故应用中等的anchor box (30\times 61),(62\times 45),(59\times 119),适合检测中等大小的目标。较大的52\times 52特征图上由于其具有较小的感受野故应用最小的anchor box(10\times 13),(16\times 30),(33\times 23),适合检测较小的目标。同Faster-Rcnn一样,特征图的每个像素(即每个grid)都会有对应的三个anchor box,如13\times 13特征图的每个grid都有三个anchor box(116\times 90),(156\times 198),(373\times 326)(这几个坐标需除以32缩放尺寸)
那么4个坐标t_x,t_y,t_w,t_h是怎么求出来的呢?对于训练样本,在大多数文章里需要用到ground truth的真实框来求这4个坐标:
上面这个公式是Faster-rcnn系列文章用到的公式,P_x,P_y在Faster-rcnn系列文章是预设的anchor box在feature map上的中心点坐标。 P_w、P_h是预设的anchor box在feature map上的宽和高。至于G_x、G_y、G_w、G_h自然就是ground truth在这个feature map的4个坐标了(其实上面已经描述了这个过程,要根据原图坐标系先根据原图纵横比不变映射为416*416坐标下的一个子区域如416*312,取 min(w/img_w, h/img_h)这个比例来缩放成416*312,再填充为416*416,坐标变换上只需要让ground truth在416*312下的y1,y2(即左上角和右下角纵坐标)加上图2灰色部分的一半,y1=y1+(416-416/768*576)/2=y1+(416-312)/2,y2同样的操作,把x1,x2,y1,y2的坐标系的换算从针对实际红框的坐标系(416*312)变为416*416下了,这样保证bbox不会扭曲,然后除以stride得到相对于feature map的坐标)。
用x,y坐标减去anchor box的x,y坐标得到偏移量好理解,为何要除以feature map上anchor box的宽和高呢?我认为可能是为了把绝对尺度变为相对尺度,毕竟作为偏移量,不能太大了对吧。而且不同尺度的anchor box如果都用_x-P_x来衡量显然不对,有的anchor box大有的却很小,都用Gx-Px会导致不同尺度的anchor box权重相同,而大的anchor box肯定更能容忍大点的偏移量,小的anchor box对小偏移都很敏感,故除以宽和高可以权衡不同尺度下的预测坐标偏移量。
但是在yolov3中与Faster-rcnn系列文章用到的公式在前两行是不同的,yolov3里P_x和P_y就换为了feature map上的grid cell左上角坐标C_x,C_y了,即在yolov3里是G_x,G_y减去grid cell左上角坐标C_x,C_y。x,y坐标并没有针对anchon box求偏移量,所以并不需要除以Pw,Ph。
也就是说:t_x = Gx - Cx,ty = Gy - Cy
这样就可以直接求bbox中心距离grid cell左上角的坐标的偏移量。
t_w和t_h的公式yolov3和faster-rcnn系列是一样的,是物体所在边框的长宽和anchor box长宽之间的比率,不管Faster-RCNN还是YOLO,都不是直接回归bounding box的长宽而是 尺度缩放到对数空间,是怕训练会带来不稳定的梯度。 因为如果不做变换,直接预测相对形变t_w和t_h,那么要求t_w,t_h>0,因为你的框的宽高不可能是负数。这样,是在做一个有不等式条件约束的优化问题,没法直接用SGD来做。所以先取一个对数变换,将其不等式约束去掉,就可以了。
这里就有个重要的疑问了,一个尺度的feature map有三个anchors,那么对于某个ground truth框,究竟是哪个anchor负责匹配它呢?
和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的3个anchor box负责预测它,具体是哪个anchor box预测它,需要在训练中确定,即由那个与ground truth的IOU最大的anchor box预测它,而剩余的2个anchor box不与该ground truth匹配。 YOLOv3需要假定每个cell至多含有一个ground truth,而在实际上基本不会出现多于1个的情况。与ground truth匹配的anchor box计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的anchor box只计算置信度误差(此时target为0)。
有了平移(t_x,t_y)和尺度缩放(t_w,t_h)才能让anchor box经过微调与grand truth重合。如图3,红色框为anchor box,绿色框为Ground Truth,平移+尺度缩放可实线红色框先平移到虚线红色框,然后再缩放到绿色框。边框回归最简单的想法就是通过平移加尺度缩放进行微调嘛。
边框回归为何只能微调?当输入的 Proposal 与 Ground Truth 相差较小时,,即IOU很大时(RCNN 设置的是 IoU>0.6), 可以认为这种变换是一种线性变换, 那么我们就可以用线性回归(线性回归就是给定输入的特征向量 X, 学习一组参数 W, 使得经过线性回归后的值跟真实值 Y(Ground Truth)非常接近. 即Y≈WX )来建模对窗口进行微调, 否则会导致训练的回归模型不work(当 Proposal跟 GT 离得较远,就是复杂的非线性问题了,此时用线性回归建模显然就不合理了)
那么训练时用的ground truth的4个坐标去做差值和比值得到t_x,t_y,t_w,t_h,测试时就用预测的bbox就好了,公式修改就简单了,把Gx和Gy改为预测的x,y,并且G_w,G_h改为预测的w,h即可。
网络可以不断学习tx,ty,tw,th偏移量和尺度缩放,预测时使用这4个offsets求得bx,by,bw,bh即可,那么问题是:
这个公式tx,ty为何要sigmoid一下啊?
前面讲到了在yolov3中没有让G_x - C_x后除以P_w得到t_x,而是直接Gx - Cx得到t_x,这样会有问题是导致t_x比较大且很可能>1. (因为没有除以P_w归一化尺度)。用sigmoid将tx,ty压缩到[0,1]区间內,可以有效的确保目标中心处于执行预测的网格单元中,防止偏移过多。举个例子,我们刚刚都知道了网络不会预测边界框中心的确切坐标而是预测与预测目标的grid cell左上角相关的偏移t_x,t_y。如13*13的feature map中,某个目标的中心点预测为(0.4,0.7),它的c_x,c_y即中心落入的grid cell坐标是(6,6),则该物体的在feature map中的中心实际坐标显然是(6.4,6.7).这种情况没毛病,但若t_x,t_y大于1,比如(1.2,0.7)则该物体在feature map的的中心实际坐标是(7.2,6.7),注意这时候该物体中心在这个物体所属grid cell外面了,但(6,6)这个grid cell却检测出我们这个单元格内含有目标的中心(yolo是采取物体中心归哪个grid cell整个物体就归哪个grid cell了),这样就矛盾了,因为左上角为(6,6)的grid cell负责预测这个物体,这个物体中心必须出现在这个grid cell中而不能出现在它旁边网格中,一旦tx,ty算出来大于1就会引起矛盾,因而必须归一化。
看最后两行公式,tw为何要指数呀,这就好理解了嘛,因为t_w,t_h是log尺度缩放到对数空间了,当然要指数回来,而且这样可以保证大于0。至于左边乘以P_w或者P_h是因为t_w=log(G_w/P_w)当然应该乘回来得到真正的宽高。
记feature map大小为W,H(如13*13),可将bbox相对于整张图片的位置和大小计算出来(使4个值均处于[0,1]区间内)约束了bbox的位置预测值到[0,1]会使得模型更容易稳定训练(如果不是[0,1]区间,yolo的每个bbox的维度都是85,前5个属性是(C_x,C_y,w,h,confidence),后80个是类别概率,如果坐标不归一化,和这些概率值一起训练肯定不收敛啊)。
只需要把之前计算的b_x,b_w都除以W,把b_y,b_h都除以H。即
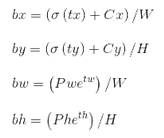
box get_yolo_box(float *x, float *biases, int n, int index, int i, int j, int lw, int lh, int w, int h, int stride)
{
box b;
b.x = (i + x[index + 0*stride]) / lw;
// 此处相当于知道了X的index,要找Y的index,向后偏移l.w*l.h个索引
b.y = (j + x[index + 1*stride]) / lh;
b.w = exp(x[index + 2*stride]) * biases[2*n] / w;
b.h = exp(x[index + 3*stride]) * biases[2*n+1] / h;
return b;
}
float delta_yolo_box(box truth, float *x, float *biases, int n, int index, int i, int j, int lw, int lh, int w, int h, float *delta, float scale, int stride)
{
box pred = get_yolo_box(x, biases, n, index, i, j, lw, lh, w, h, stride);
float iou = box_iou(pred, truth);
float tx = (truth.x*lw - i);
float ty = (truth.y*lh - j);
float tw = log(truth.w*w / biases[2*n]);
float th = log(truth.h*h / biases[2*n + 1]);
//scale = 2 - groundtruth.w * groundtruth.h
delta[index + 0*stride] = scale * (tx - x[index + 0*stride]);
delta[index + 1*stride] = scale * (ty - x[index + 1*stride]);
delta[index + 2*stride] = scale * (tw - x[index + 2*stride]);
delta[index + 3*stride] = scale * (th - x[index + 3*stride]);
return iou;
}
上述两个函数来自yolov3的darknet框架的src/yolo_layer.c代码,其中函数参数float x来自前一个卷积层的输出。先来看函数get_region_box()的参数,biases中存储的是预设的anchor box的宽和高,(lw,lh)是yolo层输入的feature map宽高(13*13),(w,h)是整个网络输入图尺度416*416,get_yolo_box()函数利用了论文中的公式,而且把结果分别利用feature map宽高和输入图宽高做了归一化,这就对应了我刚刚谈到的公式了(虽然b.w和b.h是除以416,但这是因为下面的函数中的tw和th用的是w,h=416,x,y都是针对feature map大小的)。注意这里的truth.x并非训练label的txt文件的原始归一化后的坐标,而是经过修正后的(不仅考虑了按照原始图片纵横比坐标系(416*312)变为网络输入416*416坐标系下label的变化,也考虑了数据增强后label的变化)而且这个机制是用来限制回归,避免预测很远的目标,那么这个预测范围是多大呢?(b.x,b.y)最小是(i,j),最大是(i+1,x+1),即中心点在feature map上最多移动一个像素(假设输入图下采样n得到feature map,feature map中一个像素对应输入图的n个像素)(b.w,b.h)最大是(2.7 * anchor.w,2.7anchor.h),最小就是(anchor.w,anchor.h),这是在输入图尺寸下的值。第二个函数delta_yolo_box中详细显示了t_x,t_y,t_w,t_h如何的得到的,验证了之前的说法是基本正确的。
我们还可以注意到代码中有个注释scale = 2 - groundtruth.w * groundtruth.h,这是什么含义?
实际上,我们知道yolov1里 作者在loss里对宽高都做了开根号处理,是为了使得大小差别比较大的边框差别减小。 因为对不同大小的bbox预测中,想比于大的bbox预测偏差,小bbox预测偏差相同的尺寸对IOU影响更大,而均方误差对同样的偏差loss一样,为此取根号。例如,同样将一个 100x100 的目标与一个 10x10 的目标都预测大了 10 个像素,预测框为 110 x 110 与 20 x 20。显然第一种情况我们还可以接受,但第二种情况相当于把边界框预测大了 1 倍,但如果不使用根号函数,那么损失相同,但把宽高都增加根号时:
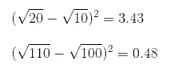
显然加根号后对小框预测偏差10个像素带来了更大的损失。而在yolov2和v3里,损失函数进行了改进,不再简单地加根号了,而是用scale = 2 - groundtruth.w * groundtruth.h加大对小框的损失。
得到除以了W,H后的b_x,b_y,b_w,b_h,如果将这4个值分别乘以输入网络的图片的宽和高(如416*416)就可以得到bbox相对于坐标系(416*416)位置和大小了。但还要将相对于输入网络图片(416*416)的边框属性变换成原图按照纵横比不变进行缩放后的区域的坐标(416*312)。应该将方框的坐标转换为相对于填充后的图片中包含原始图片区域的计算方式。 具体见下面pytorch的代码,很详细简单地解释了如何做到,代码中scaling_factor = torch.min(416/im_dim_list,1)[0].view(-1,1) 即416/最长边,得到scaling_factor这个缩放比例。
#scaling_factor*img_w和scaling_factor*img_h是图片按照纵横比不变进行缩放后的图片,即原图是768x576按照纵横比长边不变缩放到了416*372。
#经坐标换算,得到的坐标还是在输入网络的图片(416x416)坐标系下的绝对坐标,但是此时已经是相对于416*372这个区域的坐标了,而不再相对于(0,0)原点。
output[:,[1,3]] -= (inp_dim - scaling_factor*im_dim_list[:,0].view(-1,1))/2#x1=x1−(416−scaling_factor*img_w)/2,x2=x2-(416−scaling_factor*img_w)/2
output[:,[2,4]] -= (inp_dim - scaling_factor*im_dim_list[:,1].view(-1,1))/2#y1=y1-(416−scaling_factor*img_h)/2,y2=y2-(416−scaling_factor*img_h)/2
其实代码的含义就是把y1,y2减去图2灰色部分的一半,y1=y1-(416-416/768*576)/2=y1-(416-312)/2,把x1,x2,y1,y2的坐标系换算到了针对实际红框的坐标系(416*312)下了。这样保证bbox不会扭曲,
在作者的darknet的c源代码src/yolo_layer.c中也是类似处理的,
void correct_yolo_boxes(detection *dets, int n, int w, int h, int netw, int neth, int relative)
{
int i;
// 此处new_w表示输入图片经压缩后在网络输入大小的letter_box中的width,new_h表示在letter_box中的height,
// 以1280*720的输入图片为例,在进行letter_box的过程中,原图经resize后的width为416, 那么resize后的对应height为720*416/1280,
//所以height为234,而超过234的上下空余部分在作为网络输入之前填充了128,new_h=234
int new_w=0;
int new_h=0;
// 如果w>h说明resize的时候是以width/图像的width为resize比例的,先得到中间图的width,再根据比例得到height
if (((float)netw/w) < ((float)neth/h)) {
new_w = netw;
new_h = (h * netw)/w;
} else {
new_h = neth;
new_w = (w * neth)/h;
}
for (i = 0; i < n; ++i){
box b = dets[i].bbox;
// 此处的公式很不好理解还是接着上面的例子,现有new_w=416,new_h=234,因为resize是以w为长边压缩的
// 所以x相对于width的比例不变,而b.y表示y相对于图像高度的比例,在进行这一步的转化之前,b.y表示
// 的是预测框的y坐标相对于网络height的比值,要转化到相对于letter_box中图像的height的比值时,需要先
// 计算出y在letter_box中的相对坐标,即(b.y - (neth - new_h)/2./neth),再除以比例
b.x = (b.x - (netw - new_w)/2./netw) / ((float)new_w/netw);
b.y = (b.y - (neth - new_h)/2./neth) / ((float)new_h/neth);
b.w *= (float)netw/new_w;
b.h *= (float)neth/new_h;
if(!relative){
b.x *= w;
b.w *= w;
b.y *= h;
b.h *= h;
}
dets[i].bbox = b;
}
}
既然得到了这个坐标,就可以除以scaling_factor 缩放至真正的测试图片原图大小尺寸下的bbox实际坐标了,大功告成了!!!
!!!!!至此总结一下,我们得以知道,原来网络中通过feature map学习到的位置信息是偏移量tx,ty,tw,th,就是在Yolo检测层中,也就是最后的feture map,维度为(batch_size, num_anchors*bbox_attrs, grid_size, grid_size),对于每张图就是(num_anchors*bbox_attrs, grid_size, grid_size)对于coco的80类,bbox_attrs就是80+5,5表示网络中学习到的参数tx,ty,tw,th,以及是否有目标的score。也就是对于3层预测层,最深层是255*13*13,255是channel,物理意义表征bbox_attrs×3,3是anchor个数。为了计算loss,输出特征图需要变换为(batch_size, grid_size*grid_size*num_anchors, 5+类别数量)的tensor,这里的5就已经是通过之前详细阐述的边框预测公式转换完的结果,即bx,by,bw,bh.对于尺寸为416*416的图像,通过三个检测层检测后,有[(52*52)+(26*26)+(13*13)]*3=10647个预测框,也就是维度为(batchsize,10647,85).然后可以转为x1,y1,x2,y2来算iou,通过score滤去和执行nms去掉绝大多数多余的框,计算loss等操作了。
最后的小插曲:解释一下confidence是什么,Pr(Object) ∗ IOU(pred ,groundtruth)
如果某个grid cell无object则Pr(Object) =0,否则Pr(Object) =1,则此时的confidence=IOU,即预测的bbox和ground truth的IOU值作为置信度。因此这个confidence不仅反映了该grid cell是否含有物体,还预测这个bbox坐标预测的有多准。在预测阶段,类别的概率为类别条件概率和confidence相乘:
Pr(Classi|Object) ∗ Pr(Object) ∗ IOU(pred,ground truth) = Pr(Classi) ∗ IOU(pred,ground truth)
这样每个bbox具体类别的score就有了,乘积既包含了bbox中预测的class的概率又反映了bbox是否包含目标和bbox坐标的准确度。
这篇博客参考了几篇优质博客,但记不清从哪些地方看到过,这里感谢他们的付出,期待我的这篇博客能够帮助大家。
有问题欢迎留言交流。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次