1. 前言¶
有了前面两篇文章的铺垫,基本上YOLOV3的损失函数就比较明确了。然后在上一节还存在一个表述错误,那就是在坐标损失中针对bbox的宽度w和高度h仍然是MSE Loss,而针对bbox的左上角坐标x,y的损失则是我们YOLOV3损失函数再思考 Plus 推出来的BCE Loss。接下来我就完整的写一下根据DarkNet官方源码推出来的YOLOV3的Loss。
2. DarkNet YOLOV3 Loss¶
直接写出公式,注意带*号的变量代表预测值,不带*号的表示标签:
loss(object)=\sum_{i=0}^{K\times K}\sum_{j=0}^MI_{ij}^{obj}(2-w_i*h_i)(-x_i*log(\hat{x_i})-(1-x_i)*log(1-x_i^*)) +
\sum_{i=0}^{K\times K}\sum_{j=0}^MI_{ij}^{obj}(2-w_i*h_i)(-y_i*log(\hat{y_i})-(1-y_i)*log(1-y_i^*)) +
\sum_{i=0}^{K\times K}\sum_{j=0}^MI_{ij}^{obj}(2-w_i*h_i)[(w_i-w_i^*)^2+(h_i-h_i^*)^2] -
\sum_{i=0}^{K\times K}\sum_{j=0}^MI_{ij}^{obj}[C_ilog(C_i^*)+(1-C_i)log(1-C_i^*)]-
\sum_{i=0}^{K\times K}\sum_{j=0}^MI_{ij}^{noobj}[C_ilog(C_i^*)+(1-C_i)log(1-C_i^*)]-
\sum_{i=0}^{K\times K}\sum_{j=0}^MI_{ij}^{obj}\sum_{c\in classes}[p_i(c)log(p_i^*(c))+(1-p_i(c))log(1-p_i^*(c))]
我们再来解释一下这个公式。
在YOLOV3中,Loss分成三个部分:
- 一个是目标框位置x,y,w,h(左上角和长宽)带来的误差,也即是box带来的loss。而在box带来的loss中又分为x,y带来的BCE Loss以及w,h带来的MSE Loss。
- 一个是目标置信度带来的误差,也就是obj带来的loss(BCE Loss)。
- 最后一个是类别带来的误差,也就是class带来的loss(类别数个BCE Loss)。
另外值得注意的一个点是网上大多数博客写这个损失的时候都加了\lambda_{coord},\lambda_{obj},\lambda_{noobj}参数,但我们打开YOLOV3.cfg发现,原版的YOLOV3中并没有这几个参数,并且代码中也没有体现,所以正确的公式应当去掉这几个参数。

3. 答读者问¶
下面选几个留言区里面读者的问题来回答一下。
3.1 来自kun¶
Q: 如果坐标中心点用BCE Loss的话,那么是怎么设置标签呢,BCE 的标签不是0或者1吗? A: 首先YOLOV3没有中心点一说,只有左上角的点。那么它是怎么设置标签呢?首先在YOLOV2/V3里面引入了一个直接坐标预测的概念,可以看看下面的几个图片:

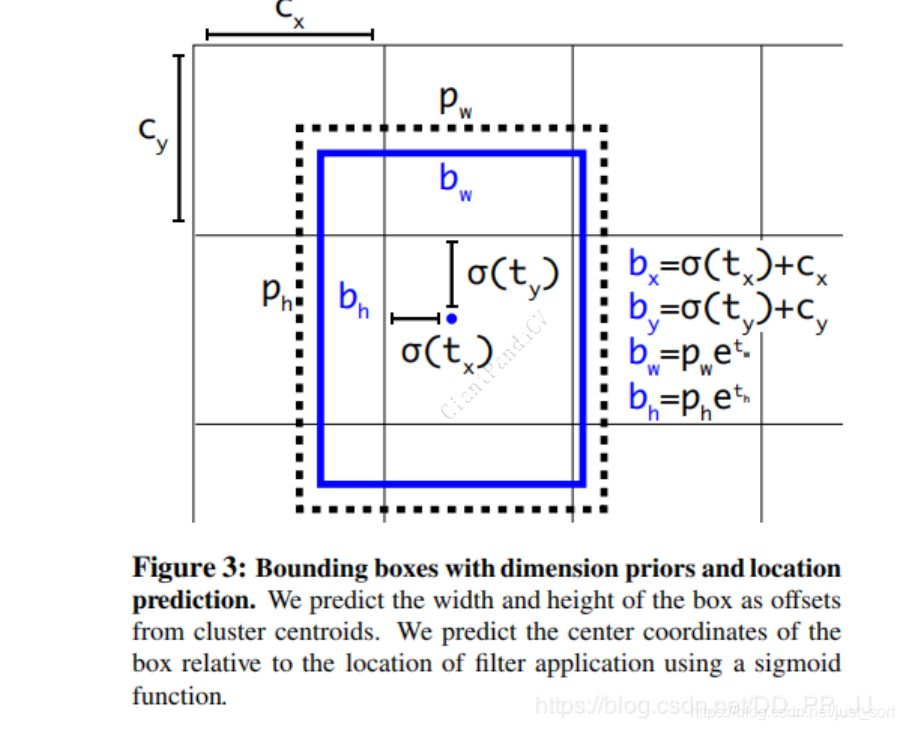

从图2可以看出,最终得到的边框坐标值是bx,by,bw,bh,即边界框相对于特征图的位置和大小,是我们需要预测的输出坐标值。但是,网络实际上学习的东西是tx,ty,tw,th(这和损失函数公式里面的xywh一致,前面已经说明),其中tx,ty是预测的坐标偏移值,tw,th是尺度缩放,有了这4个偏移量自然可以根据前面的公式计算出真正的bx,by,bw,bh这4个坐标。
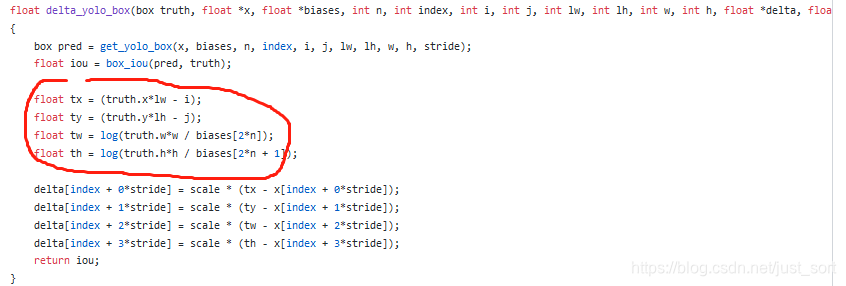
我们现在可以正面解答这位同学的问题了,标签该怎么设置呢?BCE 的标签不是0或者1? 在二分类问题并且使用One-Hot编码的情况下确实是这样的,但是我们这里并不是分类,我们要做的是预测出来的偏移值靠近原始的GT相对于于c_x,c_y的偏移值,所以这个标签就是提前算好,代码如下:
3.2 磕盐小白喵¶
Q: YOLOV3置信度误差label中的置信度数值,也就是公式中的C,还是之前YOLOV1里面Ground Truth和预测得到的bbox之间的IOU吗?看到有些博客上说是当第k个anchor box有目标时设为1否则为0。对此有些疑惑,是否能解答一下?
A: 这个问题主要是没有对YOLOv3的匹配策略搞清楚,其实我们公众号出版的PDF说得很清楚了,如下:

而YOLOV1的正负样本制定规则是啥呢?
输入图片为448\times 448,yolo将其划为为49(7\times 7)个cell, 每个cell只负责预测一个物体框, 如果这个物体的中心点落在了这个cell中,这个cell就负责预测这个物体,然后对于2个box来说,依然选择IOU最大的那个,当然YOLOV1的损失没有这么复杂,感兴趣可以去看我之前的文章。
有了匹配策略,你的问题自然就解决了,不过私以为最好的方式仍然是读源码。
4. 对读者想说的话¶
这个公众号是我在2019年的11月创建的,过去了半年时间了,也快有上万小伙伴关注了我们。我的初心就是建立一个超大的CV知识库(后面我们也会拓展到机器学习和GAN),真正的传播知识,提高自己的同时帮助一些入门的人。
然后,非常感谢公众号的三个运营者,以及一些投稿的作者们对我的信任。我相信,就算CV岗位某一天真的面临大规模缩减,大家被迫转行(开个玩笑而已),但是通过这个公众号学到的思维和解决问题的方式可以对大家有一些帮助。
最后,谢谢大家,过几天粉丝突破一万给大家抽个奖。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次