CVPR 2023: Stare at What You See: Masked Image Modeling without Reconstruction¶
1. 论文信息¶
标题:Stare at What You See: Masked Image Modeling without Reconstruction
作者:Hongwei Xue, Peng Gao, Hongyang Li, Yu Qiao, Hao Sun, Houqiang Li, Jiebo Luo
原文链接:https://arxiv.org/abs/2211.08887
代码链接:https://github.com/OpenPerceptionX/maskalign?utm_source=catalyzex.com
2. 引言¶

近年来,Vision Transformers 在计算机视觉领域展现出巨大的潜力。继掩蔽建模在自然语言处理中取得巨大成功之后,Masked Image Modeling (MIM) 展示了自我监督学习的强大能力,同时缓解了 Transformer 架构的数据匮乏问题。通过 MIM 学习的视觉表示在各种下游视觉任务上表现出良好的性能,优于基准学习范例。
现有的 MIM 方法旨在从一小部分可见图像区域中产生完整图像的幻觉。如图 1 所示,现有的 MIM 方法可以主要分为两种类型:(a) inpainting-style 和 (b) decoder-style。这两种类型都需要模型来重建mask区域。修复风格的模型用可学习的向量替换图像区域,然后通过编码器内的交互进行填充。解码器风格的模型则舍弃图像区域,根据可见信息从mask区域位置解码特征。最近的一些研究将语义丰富的 CLIP 等教师模型纳入这两种范例中,通过使用教师模型提取的特征作为重建目标来进一步提高MIM这种方式所得到的特征,从而获得更好的性能。
重建mask区域间接地迫使编码器理解图像的语义相关性。然而,重建过程需要在编码器内部或外部的mask标记上进行广泛的计算,具体取决于重建风格,这降低了编码器的训练效率,增加了预训练成本。与pixel values of patches、HOG 等低级和孤立的特征不同,强大teacher模型提取的特征显然已经包含了在教师模型训练阶段学习到的丰富语义相关性。这种差异引发了一个问题:使用教师模型进行mask的图像进行建模是实现良好性能的唯一途径吗?为了回答这个问题,作者提出了一种更有效的 MIM 范例,称为 MaskAlign,它不需要对mask标记进行重建。MaskAlign 将学生模型提取的可见特征与教师模型提取的完整图像特征进行对齐,而不是对mask标记应用重建。因此,MaskAlign 强制学生模型通过特征对齐学习教师模型的良好表示,并且通过Masked Image Modeling这种“想象”的能力:完整图像特征和mask视图之间的一致性要求学生模型从中推断出语义信息,这比教师模型学习到的要少得多。作者使用教师模型的多级特征作为监督来借用更丰富的语义。然而,学生模型的输入包含的信息比教师模型的信息少得多,导致每个层次上的特征不对齐。为了解决这个问题,作者使用了一个动态对齐 (Dynamic Alignment, DA) 模块来增强学生的特征。DA 动态地对不同级别的学生特征进行,并将它们与教师模型的多级特征对齐。该方法也可以轻松扩展到不对称的teacher-student结构。
3. 方法¶

MaskAlign是一种Masked Image Modeling (MIM)范例,它将student模型提取的可见特征与frozen的teacher模型提取的完整图像特征进行对齐。MaskAlign的概览如上图所示,它把学生模型提取的可见特征和teacher模型提取的完整图像特征进行对齐,而对齐采用的就是可学习的MLP来进行学习。Dynamic Alignment (DA) 模块则负责动态地对不同级别的student特征进行聚合,并与teahcer模型的多级特征对齐。在本节中,将详细介绍mask和algin的细节。具体来说,就是我们可以看到,Teacher model采用完整的图像来进行特征的提取,而Student model仅仅从mask image中完成建模,而采用的结构也是多尺度的,这样有助于获得全局感受野。实际上作者的motivation很直接,就是想借助teacher来教会student如何从不完整的image中获取完整的语义特征,所以就借助adapter(可学习的MLP)来完成特征之间的对齐,而每一层都要完成对齐,所以就称之为Dynamic Alignment,而且每个层级都有Adapter。
3.1 Model Struture¶
在我们的模型中,我们采用了标准的ViT作为MIM中的基准模型,以便与现有的工作进行公平比较。我们采用一个具有丰富语义的冻结教师模型来生成监督信号。在实验中,我们采用了如CLIP-ViT [35]和DINO [4]之类的ViT教师模型。对于教师模型的输入,图像I \in \mathbb{R}^{C \times H \times W}被划分为大小为(P,P)的块。然后,图像块\mathcal{I}被线性投影到输入token,并添加位置嵌入。对于学生模型的输入,该过程类似,只是我们使用了图像的屏蔽视图。与MAE中类似,我们丢弃r %的块,仅将可见块\mathcal{V}=\left\{x_i^p\right\}_{i=1}^{N(1-r \%)}馈送到学生模型中。通过ViT内的自注意机制,块相互作用以聚合信息。在学生模型中,每个query只能关注N(1-r \%)个keys,这比教师模型少得多。这可以大大降低训练成本,并鼓励学生模型学习更好的视觉表征能力。
3.2 Masking Strategy¶
Masking Strategy被用于Masked Image Modeling (MIM)来消除图像中的冗余。它创建的任务不能通过从相邻可见的图像块中推断来轻易地解决。一个简单的采样策略是随机遮蔽,它均匀地采样图像块而不重复。另一个遮蔽策略是由教师模型引导的。在MIM中,也使用了注意力遮蔽,其旨在以高概率将覆盖重要图像区域的token馈送到编码器中。总之,遮蔽策略的目的是通过从小的可见图像区域重建被遮蔽的图像块来创建任务,以便模型学习图像的语义相关性。
3.3 Dynamic Alignment¶
动态对齐(Dynamic Alignment)模块旨在改善MIM这一任务中student模型和teacher模型之间的对齐度。DA 通过应用可学习的align策略来解决学生和教师模型之间输入不一致的问题。它有助于使学生模型提取的特征与教师模型提取的特征保持一致。这种对齐方式很重要,因为教师模型提取的特征已经在完整的图像中编码了跨区域的丰富语义相关性。DA 模块效率高,附加参数和计算可以忽略不计。在预训练期间,梯度可以反向传播到动态对齐矩阵,这进一步提高了模型的性能。
loss function如下所示: $$ \mathcal{L}_{\text {Align }}(\hat{y}, \bar{y})= \begin{cases}\frac{1}{2}(\hat{y}-\bar{y})^2, & |\hat{y}-\bar{y}| \leq 1 \ \left(|\hat{y}-\bar{y}|-\frac{1}{2}\right), & \text { otherwise }\end{cases} $$ 在预训练期间,multi-level features用于监督 MaskAlign 中的student模型。学生模型从可见斑块中提取多级特征,教师模型从完整图像中提取多级特征。学生和教师模型之间的一致性是通过学习这些多层次特征的一致性来实现的。动态对齐 (DA) 模块用于对齐学生和教师模型提取的多级特征。DA 模块由动态对齐矩阵组成,动态对齐矩阵是一个可学习的矩阵,它对齐了学生和教师模型的多级特征。对齐目标是通过对每个级别的教师特征进行标准化以限制教师特征的特征大小来生成的。然后,使用对齐目标来计算对齐损失,用于在训练期间更新动态对齐矩阵。
4. 实验¶
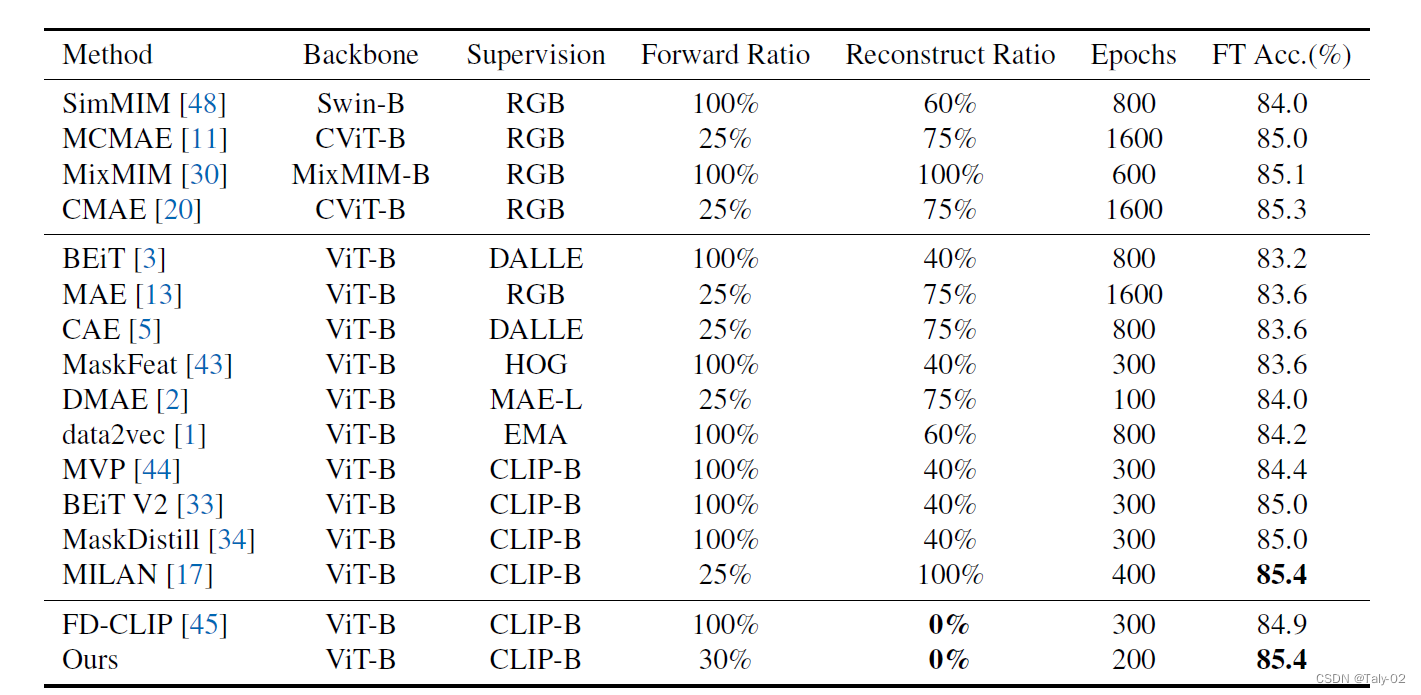
本文提出了一种名为maskAlign的MIM范式,方法可以学习学生模型提取的可见斑块特征与教师模型提取的完整图像特征的一致性。本文使用COCO数据集对拟议的MaskAlign范例进行评估。COCO 数据集是一个大型对象检测、分割和字幕数据集,包含超过 33 万张图像,超过 250 万个使用边界框、分割掩码和字幕标记的对象实例。提出的动态对齐(DA)模块用于对齐学生和教师模型提取的特征。实验结果表明,MaskAlign 在 COCO 数据集上实现了最先进的性能,用于实例分割、对象检测和语义分割任务。拟议的 maskAlign 范式也比以前的 MIM 范例更高效,因为它不需要重建mask区域。本文表明,拟议的MaskAlign范例可用于分割以外的下游任务,例如对象检测和实例分割。

该论文表明,MaskAlign 可以应用于分割以外的下游任务,例如对象检测和实例分割。这是因为 MaskAlign 可以从强大的教师模型中借用更丰富的语义,从而提高模型的泛化能力。该论文还提到,提出的动态对齐(DA)模块可以应用于其他预训练任务,例如对比学习和自我监督学习,以提高学生和教师模型之间的一致性。但是,该论文没有为这些下游任务提供任何实验结果。
5. 讨论¶
相较于具有重建模块的方法,本文提出的方法MaskAlign中,去除了重建步骤,这使得模型更专注于前景,相对于MILAN范式,提高了其鲁棒性。
拟议的 maskAlign 范例与传统的 MIM 方法的不同之处在于,它不需要重建掩码区域。取而代之的是,它学习学生模型提取的可见斑块特征和教师模型提取的完整图像特征的一致性。拟议的动态对齐(DA)模块用于对齐学生和教师模型提取的特征。这种方法在效率和性能方面具有多项优势。具体而言:
- MaskAlign 比以前的 MIM 范式更高效,因为它不需要重建掩码区域。
- MaskAlign 在 COCO 数据集上实现了最先进的性能,用于实例分割、对象检测和语义分割任务。
- MaskAlign 可以从强大的教师模型中借鉴更丰富的语义,因此可用于分段以外的下游任务,例如对象检测和实例分割。
6. 结论¶
该论文提出了一种名为MaskAlign的新掩码图像建模(MIM)范例,该范式在COCO数据集上实现了用于实例分割、对象检测和语义分割任务的最先进性能。提议的 maskAlign 范式比以前的 MIM 范例更高效,因为它不需要重建掩码区域。本文表明,拟议的MaskAlign范例可用于分割以外的下游任务,例如对象检测和实例分割。
本文总阅读量次