ICLR 2023 oral论文:一种除了卷积和ViT以外的新视觉框架-Image as Set of Points
ICLR 2023 oral论文:一种除了卷积和ViT以外的新视觉框架-Image as Set of Points¶
1. 论文信息¶
标题:Image as Set of Points
作者:Xu Ma, Yuqian Zhou, Huan Wang, Can Qin, Bin Sun, Chang Liu, Yun Fu
原文链接:https://openreview.net/forum?id=awnvqZja69
代码链接:https://anonymous.4open.science/r/ContextCluster
2. 引言¶
我们提取特征的方式在很大程度上取决于我们如何解读图像。 近年来,卷积神经网络 (ConvNets) 作为一种基本范式在计算机视觉领域占据主导地位,并显着提高了各种视觉任务的性能。 从方法论上讲,ConvNets 将图片概念化为矩形排列像素的集合,并以滑动窗口方式使用卷积提取局部特征。 受益于一些重要的归纳偏差,如局部性和翻译等方差,ConvNets 变得高效和有效。 最近,Vision Transformers (ViTs) 极大地挑战了 ConvNets 在视觉领域的统治地位。 Transformers 将图像视为一系列token,并采用全局范围的自注意力操作来自适应地融合来自补丁的信息。 通过生成的模型(即 ViTs),放弃了 ConvNets 中固有的inductive bias,并获得了令人满意的结果。 最近的工作显示了视觉社区的巨大改进,这些改进主要建立在卷积或注意力之上。 同时,一些尝试将卷积和注意力结合在一起,如 CMT。 这些方法在卷积神经网络中对图像进行编译,同时利用注意力探索图像中context的关系。 基于 MLP 的架构已经说明,纯基于 MLP 的设计也可以实现类似的性能。 此外,将图网络作为特征提取器被证明是可行的。 因此,我们期待一种新的特征提取范例,它可以提供一些新颖的见解,而不是渐进式的创新。
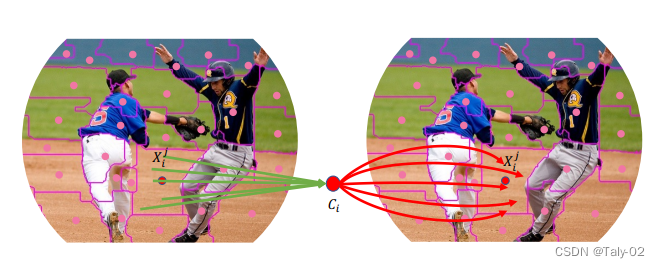
在这项工作中,从整体上讲,论文将图像视为一组point并将所有点分组到set中。如上图所示, 在每个set中,我们将point聚合到一个中心,然后自适应地将中心点分配给所有点。 我们称这种设计为上下文的簇(context cluster)。 具体来说,我们将每个像素视为具有颜色和位置信息的 5 维数据点。 从某种意义上说,我们将图像转换为一组点云,并利用点云分析的方法进行图像视觉表征的learning。 这弥合了图像和点云的表示,显示出强大的泛化能力,并为轻松融合多模态提供了可能性。 本文应该是是第一份为一般视觉representation引入聚类方法并使其发挥作用的人。 总的来说,本文提出了一种新的visual representation learning的pipeline,称为上下文集群(CoC)。 主要思想是将图像视为一组点(类似于点云)并使用聚类算法形成局部上下文集群,而不是将图像视为规则的补丁网格。 集群中的点特征使用自适应平均池聚合,然后通过全连接层“分发”回组成点。 该架构进一步考虑了多头调度,就像在自注意力网络中一样。 在各种识别任务上给出了实验结果,包括 ImageNet-1K 对象识别、ScnObjectNN 上的 3D 点云分类、MS-COCO 上的对象检测和实例分割以及 ADE20K 上的语义分割。
3. 方法¶
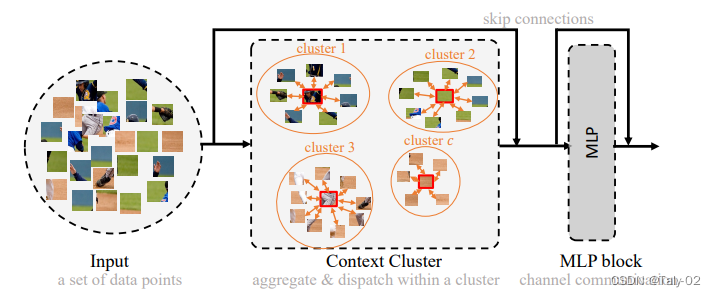
Context Cluster的整体模式如上所示。本文提出的Context Clusters 放弃了流行的卷积或注意力,转而采用新颖的经典算法聚类来表示视觉学习。 在本节中,我们首先描述上下文集群管道。 然后彻底解释了所提出的用于特征提取的上下文聚类操作。 之后,作者设置了 Context Cluster 架构。
3.1 从图像转换成sets of points¶
如何把image转化成点集是首先需要考虑的问题, 给定输入图像 \mathbf{I} \in \mathbb{R}^{3 \times w \times h},我们首先使用每个像素的二维坐标 \mathbf{I}_{ image_{i, j}},其中每个像素的坐标表示为 \left[\frac{i}{w}-0.5, \frac{j}{h}-0.5\right]。 研究进一步的位置增强技术以潜在地提高性能是可行的。 这种设计考虑到它的简单性和实用性。 然后将增强图像转换为点(即像素)的集合 \mathbf{P} \in \mathbb{R}^{5 \times n},其中 n=w \times h 是数字 的点,每个点都包含特征(颜色)和位置(坐标)信息; 因此,点集可能是无序和无组织的。一组数据点可以被视为通用数据表示,因为大多数域中的数据可以作为特征和位置信息(或两者之一)的组合给出。 这启发我们将图像概念化为一组点。
3.2 使用图像设置点进行特征提取¶
按照 ConvNets 方法,我们使用上下文的block分层提取深度特征。 图 3 显示了我们的上下文集群架构。 给定一组点 \mathbf{P} \in \mathbb{R}^{5 \times n},我们首先减少点数以提高计算效率,然后应用一系列上下文簇块来提取特征。 为了减少点数,我们在空间中均匀选择一些锚点,最近的k点通过线性投影连接和融合。 请注意,如果所有点都按顺序排列并且 k 设置正确(即 4 和 9),则可以通过卷积运算实现这种减少,就像在 ViT 中一样(Dosovitskiy 等人,2020)。 为了清楚前面所述的中心和锚点,我们强烈建议读者查看附录 \S B。
3.3 在特别任务中的应用方法¶
对于分类,我们对最后一个块输出的所有点进行平均,并使用 FC 层进行分类。 对于检测和分割等下游密集预测任务,该模块则需要在每个阶段后按位置重新排列输出点,以满足大多数检测和分割头的需求。 换句话说,上下文集群在分类任务中提供了显着的灵活性,但仅限于在密集预测任务的要求和我们的模型配置之间进行折衷。
4. 实验¶
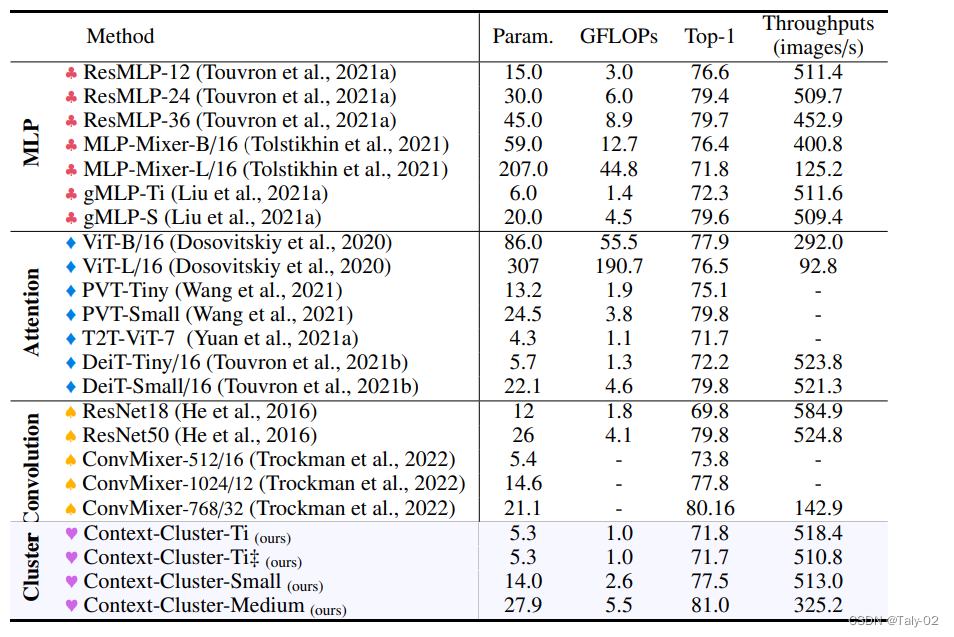
来看实验结果,判断论文提出的Context Cluster 的有效性。 该文提出的方法能够使用类似数量的参数和 FLOP 获得与广泛使用的基线相当甚至更好的性能。 Context Cluster 有大约 25M 个参数,比增强的 ResNet50(Wightman 等人,2021 年)和 PVT-small 高出 1.1%,并达到 80.9% 的 top-1 准确率。 此外,新方法明显优于基于 MLP 的方法。 这种现象表明我们的方法的性能不归功于 MLP 块,上下文集群块对视觉表示有很大贡献。 Context-Cluster-T_i 和 Context-Cluster-T_i^‡ 之间的性能差异可以忽略不计,证明了我们的 Context Cluster 对局部区域划分策略的稳健性。 虽然论文提出的基础框架无法与 SOTA 性能相匹配,但作者强调我们正在追求并证明新特征提取范例的可行性。 通过将图像概念化为一组点并自然地应用聚类算法进行特征提取,新方法成功地放弃了网络中的卷积和注意力。 与卷积和注意力相比,该方法对其他领域数据具有出色的泛化能力,并且具有良好的可解释性。
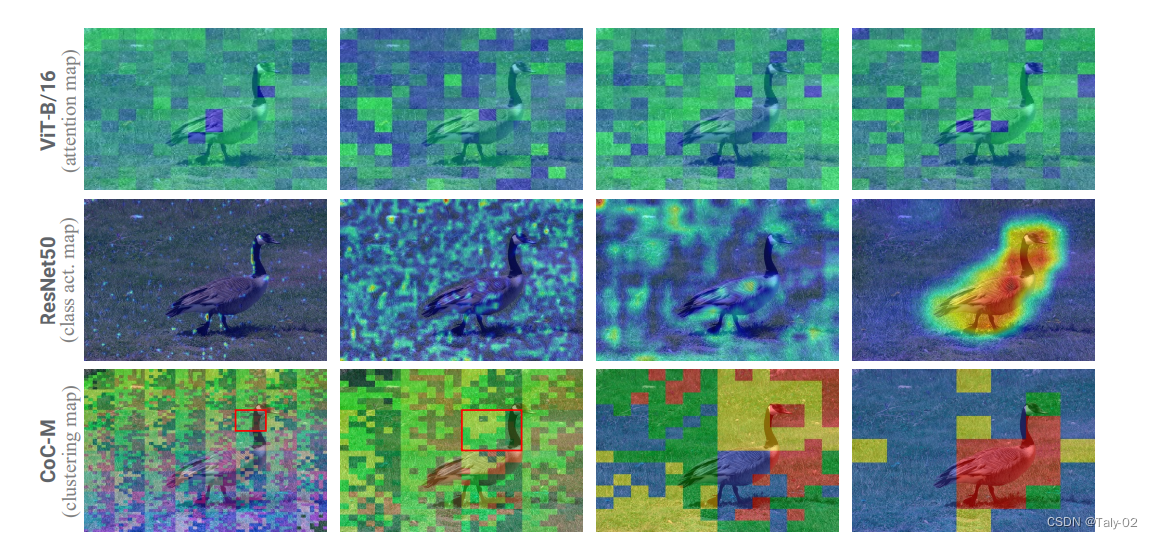
观察可视化效果图,可以发现新方法显然具有更强的激活性能,attention map相较于ViT具有较高的解释性。
5. 结论¶
论文介绍了 Context Cluster,这是一种用于视觉表示的新颖特征提取范例。 受点云分析和 SuperPixel 算法的启发,作者将图像视为一组无组织的点,并采用简化的聚类方法来提取特征。 在图像解释和特征提取操作方面,Context Cluster 从根本上不同于 ConvNets 和 ViTs,我们的架构中不涉及卷积或注意力。 值得一提的是,作者没有追求 SOTA 性能,而是表明论文提出的的上下文集群网络可以在多个任务和领域上取得与 ConvNet 和 ViT 基线相当甚至更好的结果。 最值得注意的是,我们的方法显示出有前途的可解释性和泛化特性。 希望学术界可以考虑 Context Cluster 可以被视为除了卷积和注意力之外的一种新颖的视觉表示方法。
本文总阅读量次