Scaling Language-Image Pre-training via Masking¶
1. 论文信息¶
标题:Scaling Language-Image Pre-training via Masking
作者:Yanghao Li, Haoqi Fan, Ronghang Hu, Christoph Feichtenhofer, Kaiming He
原文链接:https://arxiv.org/abs/2212.00794
2. 介绍¶
要说近期在计算机视觉社区引起较大轰动的工作,CLIP和MAE一定榜上有名。CLIP是一种基于对比文本-图像对的预训练方法或者模型。作为一种基于对比学习的多模态模型,CLIP与CV中经典的对比学习方法:MoCo和SimClr不同,它是利用文本-图像对进行训练,通过对比学习,让模型学习到文本-图像对的配对关系。而MAE(Masked Autoencoders)是计算机视觉任务里一种重要的自监督方法,通过随机mask输入图片的部分patches,然后重构这些缺失的像素,可以学习到表征能力较强的特征。它的思想和实现都比较简单,而且具有较强的扩展性。其实概括来讲CLIP就是通过对比学习的方式建立语言和图像的联系,MAE就是mask很高比例的patches,制造高难度的学习任务来增强feature的表征能力。而两者看起来毫不相关,但这篇文章却提供了一个角度来把这两个伟大的工作进行结合。
今年NeurIPS的时间检验奖颁给了AlexNet,转眼间有监督的预训练已经兴起十年了,CLIP为我们揭示了视觉语言预训练的潜力,语言监督的视觉预训练是今天赋予各种任务以新的动力。这种已经被建立为一种简单而强大的学习表示的方法。预训练的CLIP模型因其显著的泛化性和迁移性得到了诸多关注:它们具有很强的zero-shot;它们在文本到图像生成方面展示了前所未有的质量(DALEE-E);预训练的encoder可以改进多模态甚至单模态的各种任务的性能。但是众所周知CLIP训练实在非常耗时,需要非常多的GPU资源训练非常长的一段时间,按照ImageNet的数据量计算,大概有10000多个ImageNet epoch,需要花费上千个GPU日,这使得大家难以重新根据自己的需求训练新的CLIP。而怎么使得这种强大的视觉语言模型能够高效地完成训练就是一个非常值得关注的问题了。
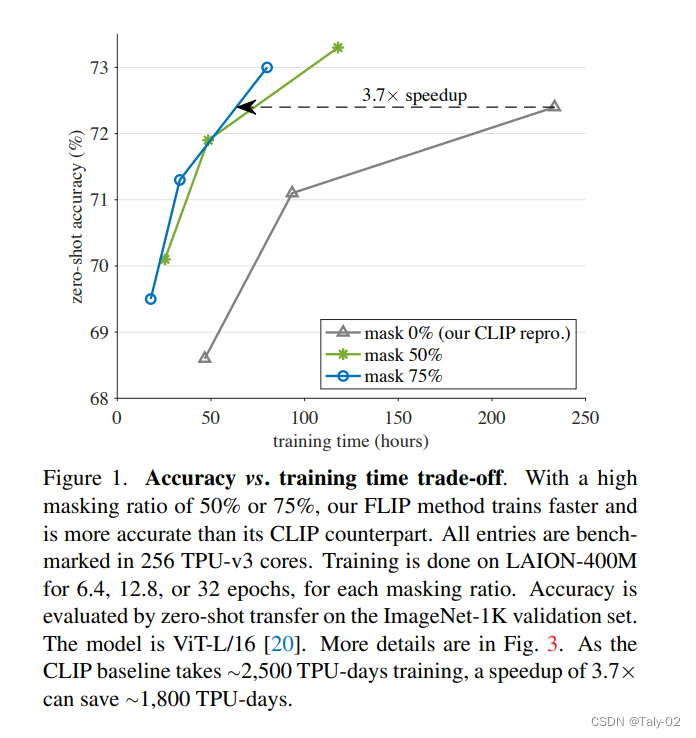
首先看下效果,本文提出的模型能在保证acc相似的情况下,提升3.7倍的速度,还是很显著的。本文的工作其实还是比较有kaiming组的风格的,就是简单有效风格的又一次体现。虽然在vision-language pre-training的论文里,一些已经引入了Masking的思想,但是大家都是把模型和结构都是往更复杂的做,比如 reconstruction loss和 contrastive loss进行结合,然后统一优化。其实CLIP和MAE主打的概念都是简洁高效,但这种应用思路显然背离了这种初衷。 FLIP做了一个很简单的事儿,就是在 CLIP 的极简结构上,使用了类似 MAE 的 Mask 方案,来减少 Image Encoder 的计算量,从而提高CLIP训练的效率。
我们提出了一种简单的 Fast Language-Image Pre-training (FLIP)方法来进行高效的训练。和MAE的模式相同,我们在训练过程中随机去除大量图像补丁。这种设计引入了“我们如何仔细观察一组图像文本对”与“我们能处理多少个图像文本对”之间的权衡。"我们能处理多少个样本对"使用屏蔽,我们可以:(i)在相同的时钟训练时间下学习更多的样本对特征,(ii)在相似的内存占用下,在每一batch对更多的样本对进行对比学习。根据经验,处理更多样本对的好处大大超过了每个样本编码的退化,所以带来了 favorable trade-off。
3. 方法¶
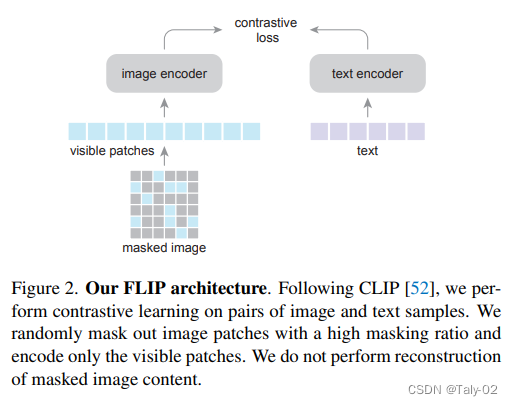
简而言之,论文提出的新方法简单地mask了CLIP训练中的输入数据,减少了计算量。如图。在上图场景中,mask的好处在于减少了训练计算的cost。直观地说,这导致了我们对样本编码的密集程度与作为学习信号比较的样本数量之间的权衡。通过引入mask,可以:
-
在相同的训练时间下,进行更多的图像-文本对的对比学习,获得更好的泛化特征。
-
在相同的内存下,获得一个更大的batch。大的batchsize对于对比学习还是非常重要的。论文并没有引入MIM的代理任务,但是还是取得了一定的性能提升。
在这两方面,实验说明论文提出的新方法都有一定的优势。具体的mask设定可以参考论文的介绍,这里就不对细节过多的展开了。
4. 实验¶
论文提出的方法非常简单而且好理解,对于实验的分析才有助于我们理解mask在视觉语言对比学习中的重要价值。
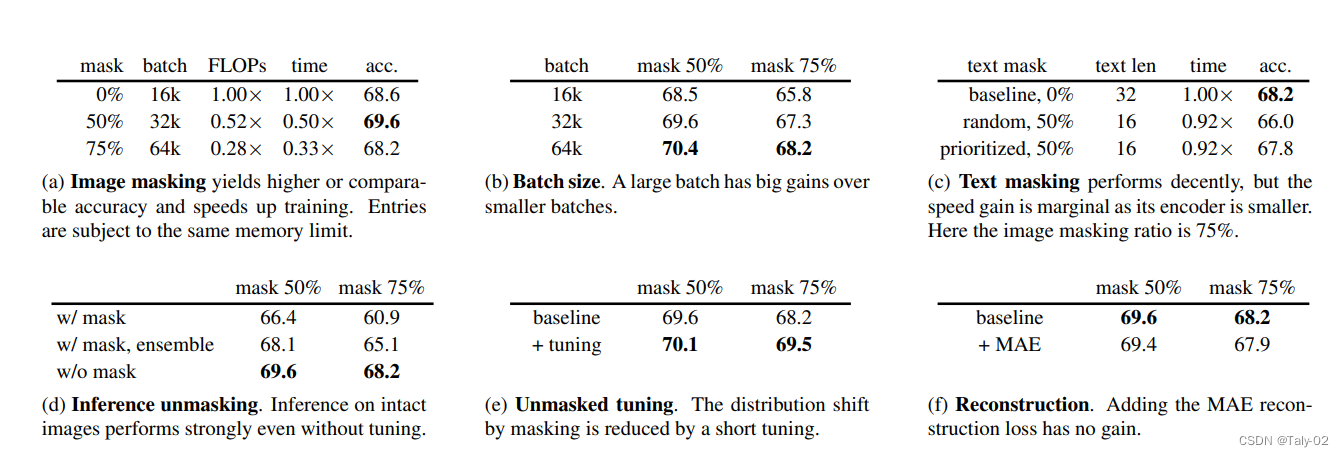
- a:mask增大同时增大batchsize有助于增加速度,而且zero-shot的acc变化不是特别大。
- b:增大batchsize有助于泛化性的提升
- c:mask掉text会掉点。这个暂时没有很明确的解释,但是也为新研究提供了方向。
- d:进行unmask不进行tuning会表现的更好
- e:进行tuning可以有效地提点,而且mask越多提点越明显
- f:引入MAE的重建loss并不能改进性能。
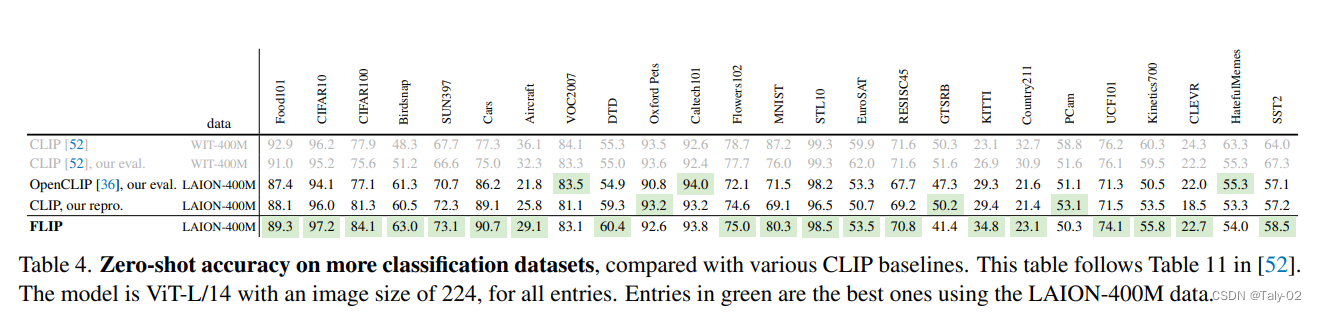
FLIP训练出的模型也有较好的迁移性。
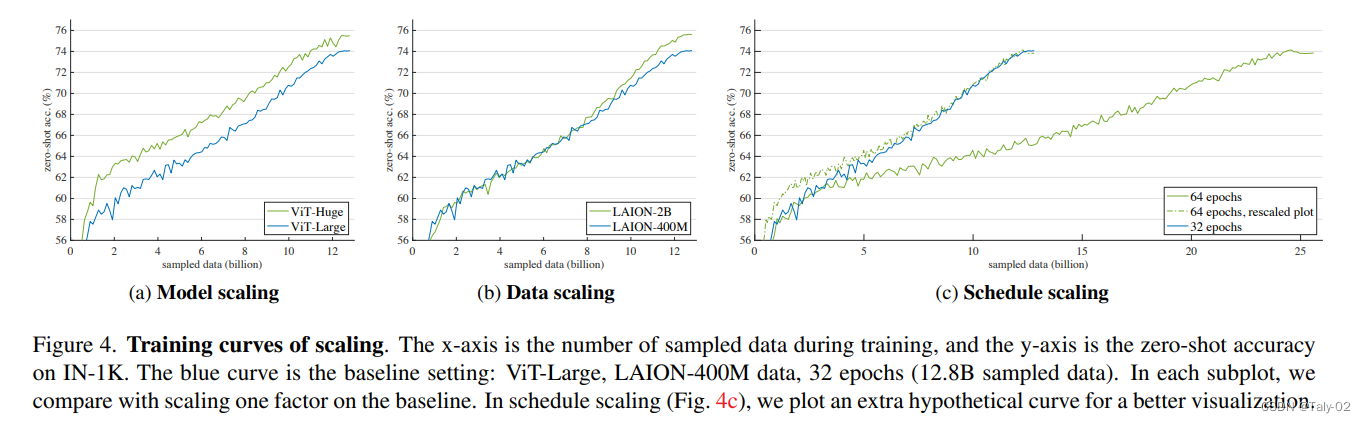
FLIP 就属于在算法层面继续去优化,使得我们可能可以继续去做 scale-up。这个工作里,在模型尺寸,数据尺寸和训练时长进行了探索。可以观察到FLIP是怎么带来涨点的:FLIP增大模型尺寸和增大数据规模都能显著地涨点,FLIP增大训练时长的涨点几乎就非常有限了。所以FLIP也为未来的预训练提供了方向:增大模型尺寸和训练数据的规模。
5. 结论¶
语言是一种比传统的label更有力的监督形式。语言为监督提供了丰富的信息。因此,要想在语言监督训练中取得良好的效果,扩展模型和增加信息是非常重要的。本文恰恰提供了一种高效的训练方式。这篇工作的研究表明,在相同的LAION数据上,FLIP的表现优于预先训练的CLIP。通过比较几种基于LAION的模型和原始基于WIT的模型,可以观察到训练前的数据在一些任务中产生了巨大的差距。本文为以后的训练模式提供了新角度。
本文总阅读量次