【域自适应】Graph-Relational Domain Adaptation
ICLR 2022: Graph-Relational Domain Adaptation
图关系领域的适应性
1. 论文信息¶
标题:Graph-Relational Domain Adaptation
作者:Zihao Xu, Hao he, Guang-He Lee, Yuyang Wang, Hao Wang
原文链接:http://wanghao.in/paper/ICLR22_GRDA.pdf
代码链接:https://github.com/ZrrSkywalker/PointCLIP
2. 引言¶
现有深度学习模型都不具有普适性,即在某个数据集上训练的结果只能在某个领域中有效,而很难迁移到其他的场景中,因此出现了迁移学习这一领域。其目标就是将原数据域(源域,source domain)尽可能好的迁移到目标域(target domain),Domain Adaptation任务中往往源域和目标域属于同一类任务,即源于为训练样本域(有标签),目标域为测集域,其测试集域无标签或只有少量标签,但是分布不同或数据差异大。主要分为两种情景:
-
homogeneous 同质:target 与 source domain 特征空间相似,但数据分布存在 distribution shift
-
heterogeneous 异构:target 与 source domain 特征空间不同
(参考:https://blog.csdn.net/qq_39388410/article/details/111749346)
现有的DA方法倾向于强制对不同的domain进行对齐,即平等地对待每个域并完美地对它们的特征进行align。然而,在实践中,这些领域通常是异质的;当源域接近目标域时,DA可以预期工作良好,但当它们彼此相距太远时就效果不那么令人满意。问题就在于,它们把各个domain当成相互独立的,从而无视了domain之间的关系。
这样的话,它们在学encoder的时候,就会盲目地把所有不同domain的feature强制完全对齐。这样做是有问题的,因为有的domain之间其实联系并不大,强行对齐它们反而会降低预测任务的性能。而其实这种异质性通常可以用图来捕捉,其中域实现节点,两个域之间的邻接可以用边捕捉。

例如,本文举了一个非常有趣的例子,为了捕捉美国天气的相似性,我们可以构建一个图,其中每个州都被视为一个节点,两个州之间的物理接近性产生一条边。在那里还有许多其他的场景,在这些场景中,领域之间的关系可以通过图自然地捕获。所以如果给定一个域图,我们可以根据图调整域的适应性,而不是强制让来自所有域的数据完美对齐,而忽略这种图的结构。其实在对domain graph这一比较重要的概念做出定义之后,就可以比较清晰地勾勒出本文提出的方法了。我们只需要对传统的adversarial DA方法做一下简单的改动:
- 传统的方法直接把data x作为encoder的输入,而我们把domain index u以及domain graph作为encoder的输入。
- 相比于传统的方法让discriminator对domain index进行分类,而我们让discriminator直接重构(reconstruct)出domain graph。
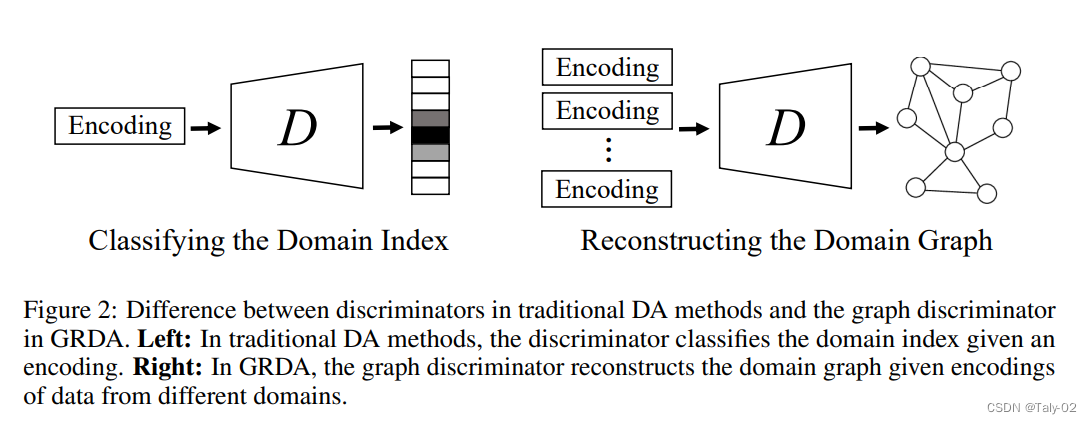
论文的贡献在于:
- 提出使用图来描述域关系,并开发图-关系域适应(GRDA)作为第一个在图上跨域适应的通用对抗性的domain adaption方法。.
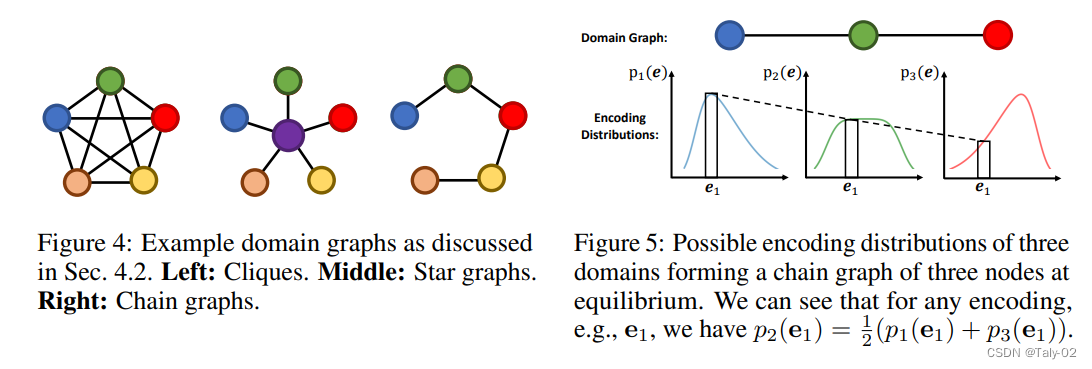
- 理论分析表明,在balance状态下,当域图为clique时,提出的方法能保持均匀对齐的能力,而对其他类型的图则能实现对齐。
- 最后通过充分的实验验证了方法在合成和真实数据集上提出的方法优于最先进的DA方法。
3. 方法¶
首先明确下本文的应用场景,他关注的是共N个域的无监督domain adaption setting。每个domain 都有一个离散域索引,属于源域索引集或目标域索引集。域之间的关系用一个域图来描述,其邻接矩阵a = [Aij],其中图中的i和j个索引节点(域)。
已知来自源域(uf E Us)的标记数据(x, y,u),来自目标域(u, EUt)的未标记数据[x_t, u_t=1],以及由A描述的域图,我们希望预测来自目标域的数据的标记[yte1]。注意,域图是在域上定义的,每个域(节点)包含多个数据点。
概述。我们使用对抗学习框架跨图关系域执行适应。本文提出的方法主要由三个成分组成:
-
编码器E,它以数据和相关域索引u和邻接矩阵a作为输入,生成编码。
-
预测器F,它基于编码ei进行预测
- 图判别器D,它指导编码适应图关系域。
3.1 Predictor¶
定义优化的loss为:
where the expectation \mathbb{E}^s is taken over the source-domain data distribution p^s(\mathbf{x}, y, u) \cdot h_p(\cdot, \cdot) is a predictor loss function for the task (e.g., L_2 loss for regression).
3.2 Encoder and Node Embeddings¶
给定一个输入元组(x, u, A),用编码器E首先根据域索引和域的graph计算一个embedding的graph domain,然后将z和x,y输入到神经网络中,得到最终的编码e。 理论上,任何节点的索引的embedding都应该同样有效,只要它们彼此不同,所以为了简单起见,论文通过一个重构损耗预先训练embeddings:
where \sigma(x)=\frac{1}{1+e^{-x}} is the sigmoid function.
3.3 Graph Discriminator¶
where \widehat{\mathbf{z}}_1=D\left(E\left(\mathbf{x}_1, u_1, \mathbf{A}\right)\right), \widehat{\mathbf{z}}_2=D\left(E\left(\mathbf{x}_2, u_2, \mathbf{A}\right)\right) are the discriminator's reconstructions of node embeddings. The expectation \mathbb{E} is taken over a pair of i.i.d. samples \left(\mathbf{x}_1, u_1\right),\left(\mathbf{x}_2, u_2\right) from the joint data distribution p(\mathbf{x}, u).
更具体的模型实现细节可以参考原文的附录。
3.5 Theory¶
论文阐述并证明了两个观点:
-
用的是adversarial training,本质上是在求一个minimax game的均衡点(equilibrium)。在传统的DA方法上,因为discriminator做的是分类,我们可以很自然地证明,这个minimax game的均衡点就是会完全对齐所有domain。在任何domain graph的情况下,当GRDA训练到最优时是可以保证不同domain的feature会根据domain graph来对齐,而不是让所有domain完全对齐。
-
传统的DA方法,其实是提出的GRDA的一个特例。这个特例其实非常直观:传统的DA方法(完全对齐所有domain)会等价于当GRDA的domain graph是全连接图(fully-connected graph or clique)时的情况。
4. 实验¶
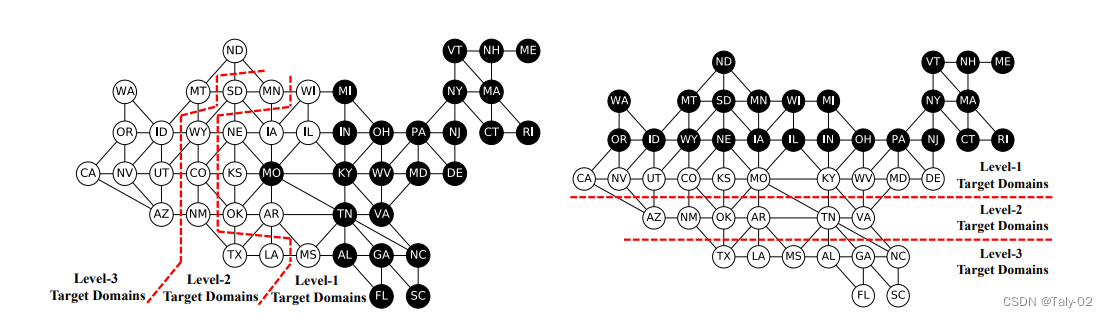
论文构造了一个15个domain的toy dataset及其对应的domain graph(如下图的左边)DG-15。可以看到,GRDA的accuracy可以大幅超过其他的方法,特别是其他方法在离source domain比较远(从domain graph的角度)的target domain的准确率并不是很高,但GRDA却能够保持较高的准确率。

5. 结论¶
在本文中,论文确定了graph-relational domains的自适应问题,并提出了一种通用的DA方法来解决这一问题。我们进一步提供了理论分析,表明我们的方法恢复了经典DA方法的一致对齐,并实现了其他类型图的非平凡对齐,从而自然地融合了由域图表示的域信息。实证结果证明该方法非常有效
本文总阅读量次