With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations¶
1. 论文信息¶
论文题目:With a Little Help from My Friends: Nearest-Neighbor Contrastive Learning of Visual Representations
论文收录:ICCV-2021
论文作者:Debidatta Dwibedi, Yusuf Aytar , Jonathan Tompson , Pierre Sermanet , and Andrew Zisserman.
2. 背景介绍¶
对比学习(contrastive learning)是被看作是一种自监督学习方法(SSL,Self-supervised Learning),本质上是为了在数据标签的设定下为数据学习到一个良好的表示。因此,对比学习本质上仍然可以看做是一种表示(representation)学习。
首先简单介绍一下对比学习和广为人知的MoCo算法:
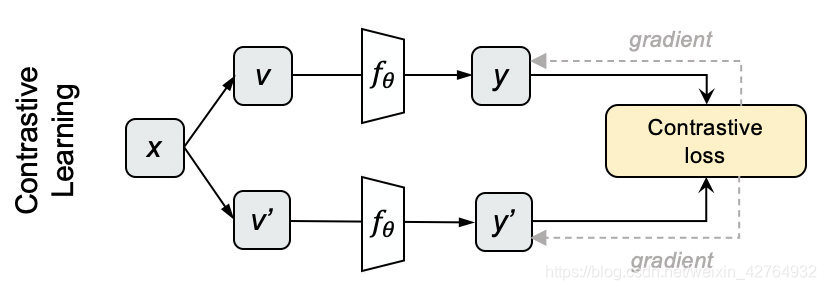
具体步骤如图所示:
-
采样N个图片,用不同的数据增强方法为每个图片生成两个view
-
分别将他们输入网络,获得编码表示y和y’。
-
对上下两批表示两两计算cosine,得到NxN的矩阵,每一行的对角线位置代表y和y’的相似度,其余代表y和N-1个负例的相似度。对每一行做softmax分类,采用交叉熵损失作为loss,就得到对比学习的损失了。
MoCo采用的对比学习损失函数就是InfoNCE loss,以此来训练模型,公式如下:
\tau 表示温度系数。
然后又有了更为直接的SimCLR:
Google的研究人员发现:
- 数据扩充的组合在有效的预测任务中起着关键作用;
- 在表征和对比损失之间引入可学习的非线性变换,大大提高了学习表示的质量;
- 与有监督的学习相比,对比学习需要更大batch size和训练轮数。
通过结合这些发现,SimCLR能够大大胜过在ImageNet上先前的自我监督和半监督学习的方法。
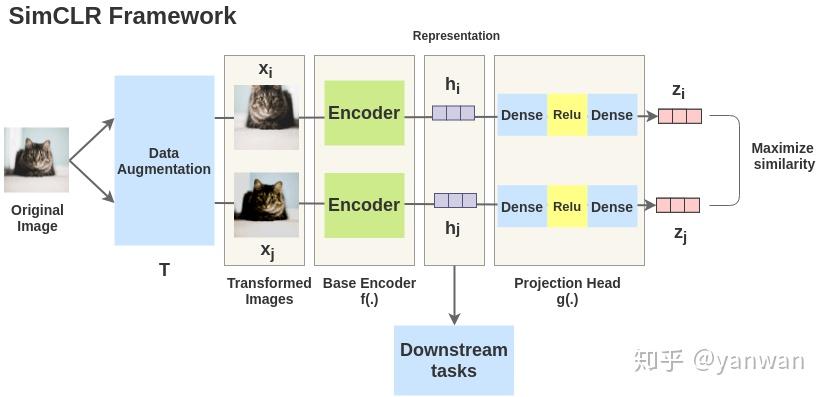
loss function为:
回顾完了两个影响力比较大的对比学习算法,让我们来再了解一下更更更经典的KNN算法:
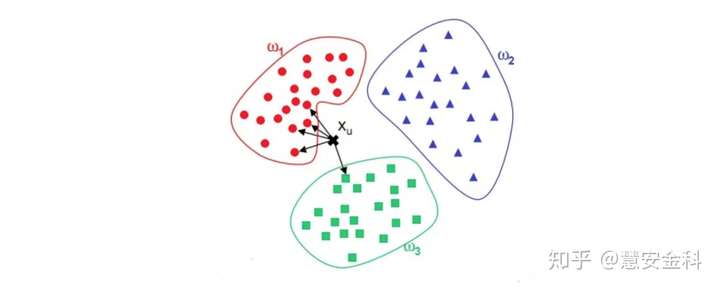
KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
KNN应该是最简单最经典的无监督算法,而对比学习(Contrastive Learning)则是当下比较流行的无监督学习范式。本文将这两者结合,取得了非常有意思的效果。
可以参考:
https://zhuanlan.zhihu.com/p/158023072
3. 介绍¶
本文首先从人的认知视角出发:一个人如何理解一种新鲜的感官体验?当人们看到新事物的图片,比如渡渡鸟时,他们的脑子里会想些什么?即使没有被明确告知渡渡鸟是什么,他们也可能会在渡渡鸟和其他类似的语义类之间形成联系;例如,与大象或老虎相比,渡渡鸟更像鸡或鸭。这种将新的感官输入与原有感官进行对比和比较的行为在潜意识里经常发生,在人类快速获取认知能力的过程中起着关键作用。在这项研究中,作者团队展示了在以前见过的例子中发现项目相似性的能力如何提高自我监督表征学习的性能。
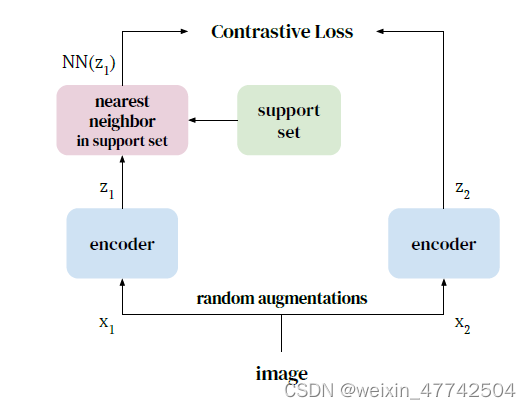
在这项工作中,和经典的对比学习一致,作者把实例辨别这一经典设定当成代理任务。希望通过这样做,可以让模型学习更好的特征,这些特征对不同的视角、变形,甚至类内变化都是不变的。single instance positives的好处已经在(Supervised contrastive learning)中得到了证实,尽管这些工作需要类标签或多种模式(RGB帧和流)来获得不适用于我们无监督表征学习。基于聚类的方法,如大名鼎鼎的Kaiming的MoCo,也提供了一种single instance positives的方法,但假设整个类别是正样本可能会由于早期的过度泛化而损害性能。相反,论文提出在学习的表示空间中使用最近的邻居作为正样本进行对比学习。我们通过鼓励相同样本的不同视角和拉近nearest neighbor在latent space中的距离来学习到更好的表征。通过论文提出的方法的方法,Nearest-Neighbour Contrastive Learning of visual Representations(NNCLR),该模型可以推广到现有数据增强方案可能无法覆盖的新数据点。换句话说,样本在embedding space中nearest neighbor充当了小的语义扰动,它们不是一个虚假合成的样本,而代表了数据集中实际的语义样本。
4. 方法¶
这一部分介绍NNCLR,它提出使用最近邻(NN)作为positive样本来改进对比学习中的实例识别。
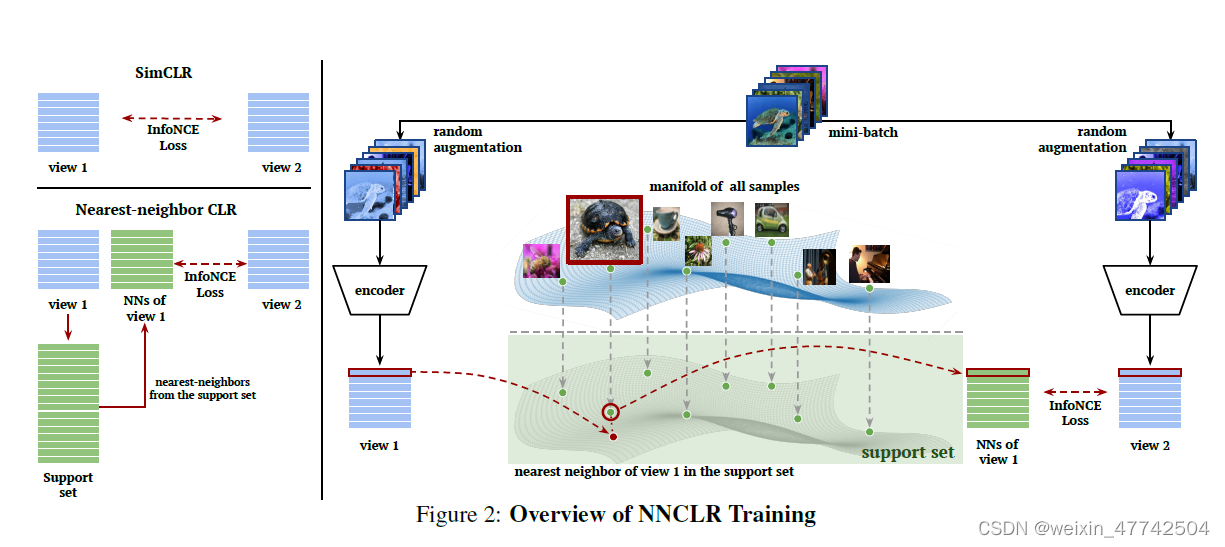
为了增加我们latent space的丰富度,论文提出使用最近邻来获得更多样化的正样本对。这需要保持一个代表完整数据分布的embedding。增强 (z_{i}, z{i}^{+}) 形成正对。相反,我们建议使用zi在支持集Q中的最近邻来形成正对。在图2中,我们对这个过程进行了图示。与SimCLR类似,我们从小batch中获得负样本对。
基于SimCLR,可以定义NNCLR的损失函数为:
NN表示选取最近邻的操作符:
5. 实验分析¶
像之前对比学习实验一样,作者固定了NNCLR对图片编码得到的2048维度的embedding,并且将其输入到分类器中,观察实验结果。
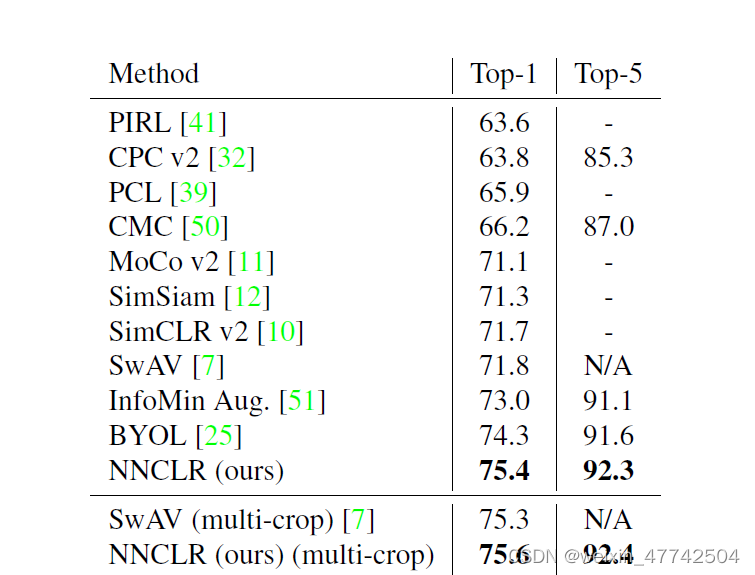
自然是取得了比较好的效果,其实再ImageNet这样的数据集上,取得这样的提升已经非常amazing了。
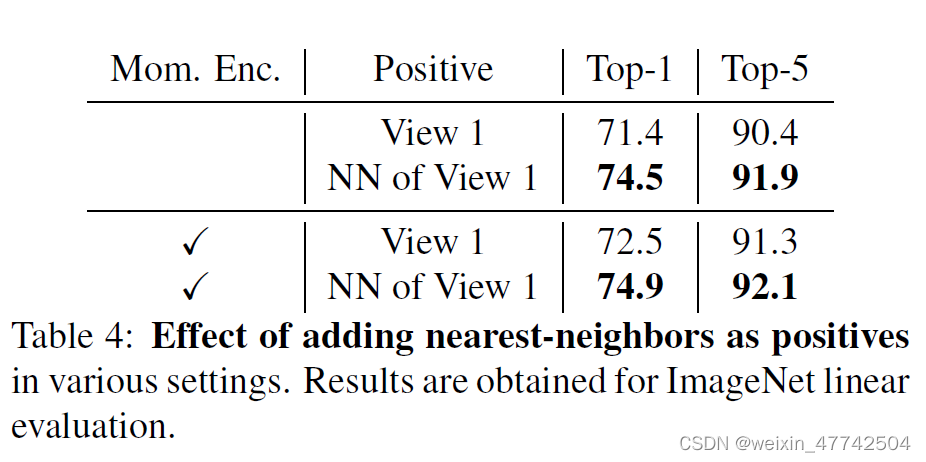
可以看到采用数据增广还是非常有效的,因为这可以增加数据的多样性,使得NN的搜索更加准确。

个人觉得这是实验部分最有意思的一组实验,因为NNCLR利用kNN这种方式有效增强了正样本对的多样性,所以对数据增广的依赖度没有SimCLR和BYOL那么强。
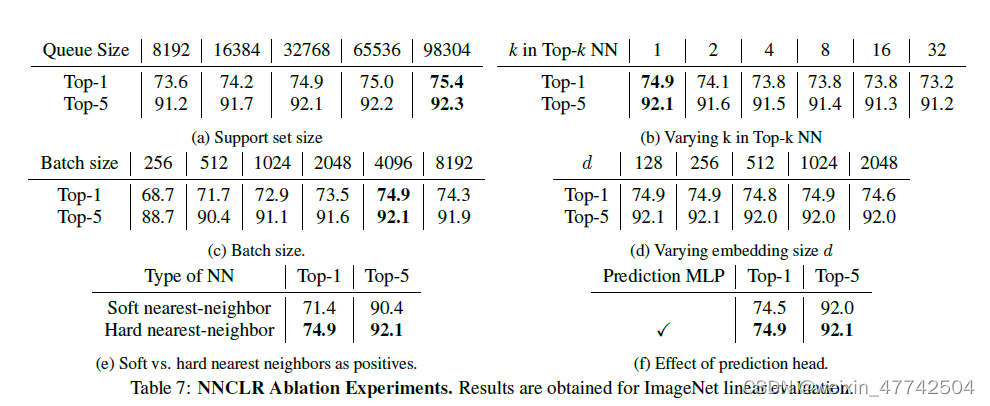
然后就是各种超参数的消融实验。各种结果都还比较符合认知。值得注意的是NN数量越小则越性能越好,这个结论很好理解,毕竟k越小,则正样本对本身的距离也就越小,本身从属同一样本对的概率也就越大,不容易出现nosie。
6. 结论¶
论文提出了一种方法,以增加多样性的对比自我监督学习。我们通过使用支持集中KNN作为postive sample来做到这一点。NNCLR在多个数据集上实现了最先进的性能。我们的方法也大大减少了对数据增强技术的依赖。
本文总阅读量次