NeurIPS19 用分类模型完成生成任务
NeurIPS19:Image Synthesis with a Single (Robust) Classifier 用分类模型完成生成任务
1. 论文信息¶
标题:Image Synthesis with a Single (Robust) Classifier
作者:Shibani Santurkar, Andrew Ilyas, Dimitris Tsipras, Logan Engstrom, Brandon Tran, Aleksander Madry
链接:https://proceedings.neurips.cc/paper/2019/hash/6f2268bd1d3d3ebaabb04d6b5d099425-Abstract.html
代码:https://github.com/MadryLab/robustness_applications
2. 引言¶
介绍一篇关于概率生成模型非常有意思的工作,保持了Aleksander Madry一如既往的风格。众所周知,深度学习彻底改变了计算机视觉问题的的研究范式,提供了很多原来大家想完成但没有机遇完成的工作。而这场演化确是从判别模型开始的,像Alexnet、VGG、ResNet这些工作取得的非凡进展,引发了深度学习范式的扩展。
而慢慢地,大家的注意力也从包括更复杂的任务,如图像生成和图像到图像的转换这种生成式的任务。但这种生成模型在很大程度上都是基于非常复杂的,而且基于特定任务的技术,例如GAN和VAE。所以可能就目前的进展来看,生成任务的范式是比较复杂的,但是果真所有的生成任务都这么复杂么?本文提供了一个比较新颖的角度。
本文提供了一种方法,仅凭基本分类工具就足以解决各种图像合成任务,包括generation、inpainting、image-to-image translation、super-resolution、interactive image manipulation。论文提出的整个框架都是基于每个数据集的单个分类器,而且仅仅只涉及执行一个简单的输入操作:使用梯度最大化地下降使预测的类分数。
因此,这一较为通用的方法比较易于实现和训练。其实论文提出方法最关键的成分是adversarially robust classifiers。此前,其实就有模型观察到观察到,将鲁棒模型在输入上的损失最大化,将导致其他类的状态更接近真实的分布(maximizing the loss of robust models over the input leads to realistic instances of other classes)。
因此,基于这种结论,论文的研究结果建立了健壮的分类器作为语义图像操作的强大manipulation。为了突出核心方法本身的潜力,论文的实验中有意采用一种通用的分类设置,而没有任何额外的优化。
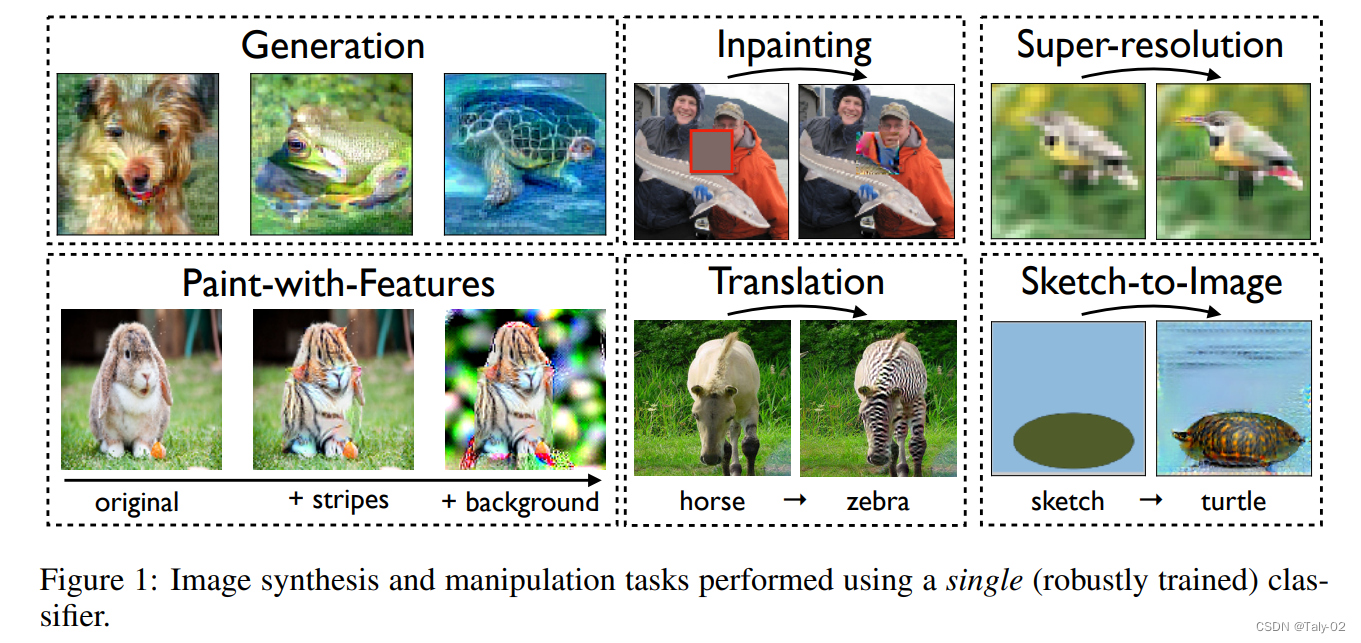
2. 方法¶
论文首先介绍了作为Input Manipulation的Robust Models,

其实从这个视角来看,我们可以将鲁棒优化看作是将先验编码到模型中,防止它依赖于输入的难以察觉的特征。的确,也就是说,这种训练方式可以通过鼓励模型对小扰动不铭感,从而使得Robust training的预测变化与输入变化的显著性相对应。事实上,当我们最大化一个Robust Models的特定类面对目标攻击的敏感概率时,这种现象也会出现——参见图2中的说明。
这表明,稳健的模型表现出更多与人类一致的梯度,更重要的是,我们可以通过对模型输出执行梯度下降来精确控制输入中的特征。在接下来的工作中,论文阐释了鲁棒模型的这一特性足以在不同的图像合成任务集上获得良好的性能。论文还是反复强调,要获取和自然数据domain相近质量的质量其实只需要充分利用分类模型就行了,GAN和VAE这些模型虽然取得了不错的效果,但是还是对分类模型的潜力有所忽略。
3.1 Realistic Image Generation¶
讲了这么多绕来绕去的,那论文优化目标是什么呢(中文解释起来太复杂也可能不准确,还是看原文):

其实就是做了一个非常简单的假设,使得模型能够利用class-conditional distribution的混合高斯的多元模型中,重建出相应的图像,优化目标就是使得符合最小的期望。那么效果如何呢,作者随机选取了异步的的可视化:

3.2 Inpainting¶
对于inpainting,是指恢复具有大区域被mask掉的图像。也就是说给定一个图像x,在一个对应于二值掩码m的区域中的内容进行补充,inpainting的目标是以一种相对于图像其余部分感知上合理的方式恢复丢失的像素。作者发现,简单的feed分类器,当经过robust的训练时,可以成为这类图像重建任务的强大工具。
其实根据上一部分我们的描述,其实可以发现我们的目标也是使用鲁棒的模型来恢复图像中缺失的特征。为此,我们将优化图像,使底层真实类的分数最大化,同时也迫使其在未损坏的区域与原始一致。具体来说,给定一个训练在未损坏数据上的鲁棒分类器,和一个带有标签y的损坏图像z,然后对优化目标进行求解:
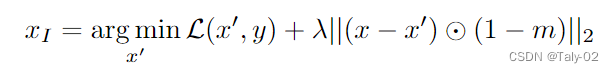
可以发现效果确实还不错:

3.3 Image-to-Image Translation¶
这个其实就跟3.1非常类似了。在本节中,我们将演示鲁棒分类器为执行这种图像到图像转换提供了一种新的方法。关键是(robustly)训练分类器来区分源域和目标域。从概念上讲,这样的分类器将提取每个领域的显著特征,以便做出准确的预测。然后,我们可以通过直接最大化目标域的预测得分来翻译来自源域的输入。

3.4 Interactive Image Manipulation¶

这个的优化目标和3.2类似。
4. 结论¶
在这项工作中,我们利用基本分类框架来执行广泛的图像合成任务。特别是,我们发现基本分类器学习到的特征足以完成所有这些任务,前提是该分类器具有adversarially robust。然后,论文非常生动地展示这种insight如何产生一个简单、可靠、直接可扩展到其他大型数据集的toolkit。事实上,与GAN这些方法不同的是,我论文的方法实际上受益于扩展到更复杂的数据集——只要底层分类任务丰富且具有挑战性,分类器就可能学习更细粒度的特征。实际上,鲁棒性可能为构建一个与人类更加一致的机器学习工具包提供了一条道路。
本文总阅读量次