前言¶
这是卷积神经网络学习路线的第19篇文章,主要为大家介绍一下旷世科技在2017年发表的ShuffleNet V1,和MobileNet V1/V2一样,也是一个轻量级的卷积神经网络,专用于计算力受限的移动设备。新的架构利用两个操作:逐点组卷积(pointwise group convolution)和通道混洗(channel shuffle),与现有的其他SOTA模型相比,在保证精度的同时大大降低了计算量。ShuffleNet V1在ImageNet和MS COCO上表现出了比其他SOTA模型更好的性能。论文原文见附录。
介绍¶
当前很多CNN模型的发展方向是变得更大,更深,这让深度卷积神经网络的准确率更高,但难以运行在移动设备上,针对这一问题,许多工作的重点放在对现有预训练模型的剪枝,压缩或使用低比特表示。
这篇论文提出的ShuffleNet基于探索一个可以满足受限条件的高效基础网络架构。论文发现先进的架构如Xception和ResNetXt在小型网络模型中效率较低,因为大量的1*1卷积耗费了大量时间。论文提出了逐点群卷积(pointwise group convolution)帮助降低计算复杂度;但如果只使用逐点群卷积会有副作用,所以论文还提出了通道混洗(channel shuffle)帮助信息流通。基于这两种技术,论文构建了一个名为ShuffleNet的高效架构,相比于其他先进模型,对于给定的计算复杂度预算,ShuffleNet允许使用更多的特征映射通道,在小型网络上有助于编码更多信息。
相关工作¶
-
高效模型设计:卷积神经网络在CV任务中取得了极大的成功,在嵌入式设备上运行高质量深度神经网络需求越来越大,这也促进了对高效模型的研究。例如,GoogleNet增加了网络的宽度,复杂度降低很多。SequeezeNet在保持精度的同时大大减少了模型的参数和计算量,ResNet利用高效的bottleneck结构实现了惊人的效果。Xception中提出深度可分离卷积概括了Inception序列。Mobilenet利用深度可分离卷积构建的轻量级模型取得了先进的成果。ShuffleNet的工作是逐点组卷积和深度可分卷积。
-
模型加速:模型加速有很多方向,有网络剪枝,减少通道数,量化或者因式分解计算中的冗余等,ShuffleNet的工作专注于设计更好的模型来直接提高性能,而不是加速或转换。
方法¶
针对组卷积的通道混洗¶
现代卷积神经网络会包含多个重复模块。其中,最为先进的网络例如Xception和ResNeXt将有效的深度可分离卷积或组卷积引入block中,在表示能力和计算消耗之间取得了很好的折中。但是我们注意到这两个设计都没有充分使用1\times 1的逐点卷积,因为这需要很大的计算复杂度。例如,在ResNeXt中3\times 3卷积配有逐点卷积(1\times 1),逐点卷积占了93.4%的multiplications-adds。
在小型网络中,昂贵的逐点卷积造成有限的通道之间充满约束,这会显著的降低计算损失。然而,如果多个组卷积堆叠在一起,会产生一个副作用:某个通道的输出信息会从一小部分输入通道导出,如下图(a)所示,这样的属性降低了通道组之间的信息流通,降低了信息的表示能力。如果我们允许组卷积能够得到不同组的输入数据,即下图(b)所示效果,那么输入和输出通道会是全关联的。具体实现的话,我们就可以对于上一层输出的通道做一个混洗操作,如下图c所示,再分为几个组,和下一层相连。
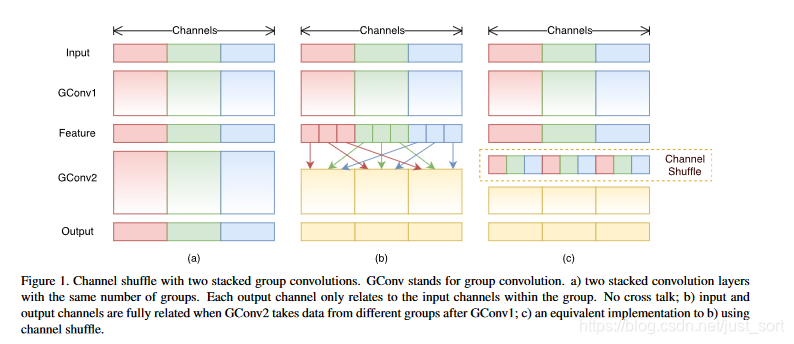
通道混洗的算法过程如下:
- 对一个卷积层分为g组,每组有n个通道
- reshape成(g, n)
- 再转置为(n, g)
- Flatten操作,分为g组作为下一层的输入。
- 通道Shuffle操作是可微的,模型可以保持end-to-end训练。
混洗单元¶
在实际过程中,我们构建了一个ShuffleNet Unit(混洗单元),便于后面组合为网络模型。
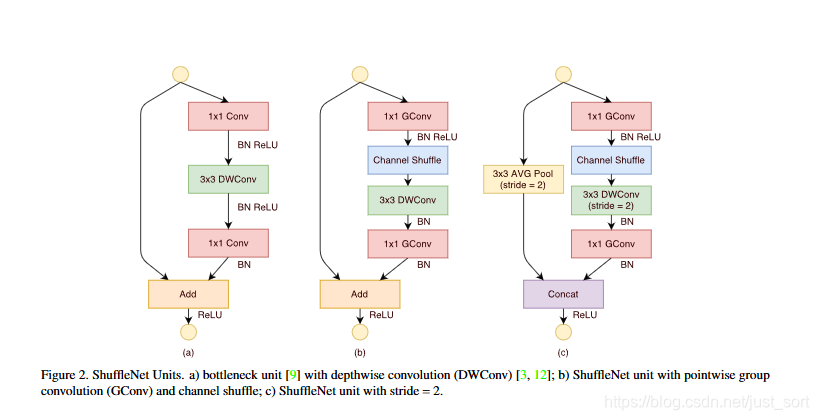
- Figure2 a是一个残差模块。对于主分支部分,我们可以将其中标准卷积3\times3拆成深度可分离卷积。我们将第一个1\times1卷积替换为逐点组卷积,再做通道混洗如图(b)。
- Figure2 a是ShuffleNet Unit,主分支最后的1\times1卷积改成1\times1组卷积,为了适配和恒等映射做通道融合。配合BN层和ReLU激活函数构成基本单元。
- Figure2 a是做下采样的ShuffleNet unit,这里主要做了2点修改,在辅分支加入了步长为2的3\times 3平均池化,原本做元素相加的操作转为了通道级联,这扩大了通道数,增加的计算成本却很少。归功于逐点群卷积和通道混洗,ShuffleNet Unit可以高效的计算。相比于其他先进的单元,在相同设置下复杂度较低。例如,给定输入大小h\times w\times c,通道数为c,对应的bottleneck的通道数为m。那么:
- ResNet Unit需要hw(2cm+9m^2)FLOPS计算量。
- ResNeXt 需要hw(2cm+9m^2/g)FLOPS计算量。
- ShuffleNet Unit只需要hw(2cm/g)+9mFLOPS计算量。 其中g表示组卷积数目。
网络结构¶
在上面的基本单元的基础上,论文提出了ShuffleNet的整体架构:
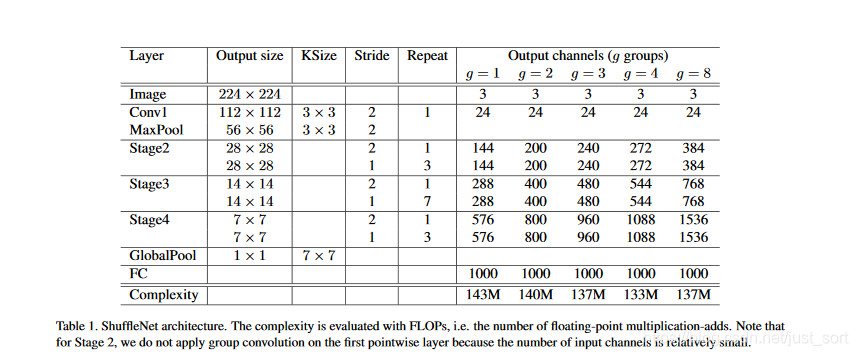
整个架构主要分为3个阶段:
- 每个阶段的第一个block的步长为2,下一阶段的通道翻倍。
- 每个阶段内除了步长,其它的超参数保持不变。
- 每个ShuffleNet Unit的bottleneck通道数为输出的¼
这里主要是给出一个基准线。在ShuffleNet Unit中,参数g控制逐点卷积的连接稀疏性(即分组数),对于给定的限制下,越大的g会有越多的输出通道,这帮助我们编码信息。定制模型需要满足指定的预算,我们可以简单的使用放缩因子s控制通道数,ShuffleNets\times即表示通道数缩放到s倍。
实验¶
实验在ImageNet的分类数据集上做评估,大多数遵循ResNeXt的设置,除了两点:
- 权重衰减从1e-4降低到了4e-5
- 数据增强使用较少的aggressive scale增强 这样做的原因是小网络在模型训练的过程中经常会遇到欠拟合而不是过拟合问题。
逐点卷积的重要性¶
为了评估逐点卷积的重要性,比较相同复杂度下组数从1到8的ShuffleNet模型,同时论文通过放缩因子s来控制网络宽度,扩展为3种:
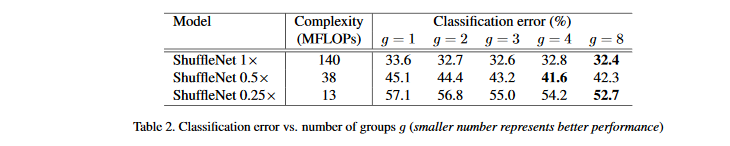
从结果来看,有组卷积的一致比没有组卷积的效果好。注意组卷积可允许获得更多通道的信息,我们假设性能的收益源于更宽的特征映射,这帮助我们编码更多信息。并且,较小的模型的特征包含更少的特征映射,这意味着可以从更多的特征映射上获益。
表2还显示,对于一些模型,随着g增大,性能上有所下降。意味着组数增加,每个卷积滤波器的输入通道越来越少,损害了模型,损害了模型的表示能力。
值得注意的是,对于小型的ShuffleNet 0.25\times,组数越大性能越好,这表示对于小模型更宽的特征映射更有效。受此启发,在原结构的阶段3删除2个单元,即表2中arch2结构,放宽对应的特征映射,明显新的架构效果要好得多。
有通道混洗和没有通道混洗¶
Shuffle操作是为了实现多个组之间信息交流,下表表现了有无Shuffle操作的性能差异:
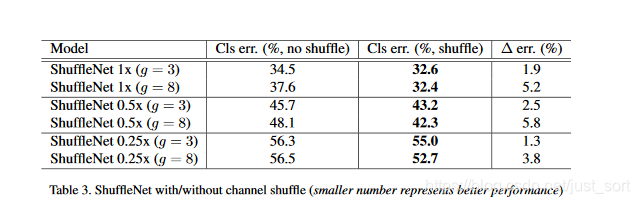
三个不同复杂度下带Shuffle的都表现出更优异的性能,尤其是当组更大(arch2, g=8),具有shuffle操作性能提升较多,这表现出Shuffle操作的重要性。
和其他结构单元做比较¶
我们对比不同Unit之间的性能差异,使用表1的结构,用各个Unit控制阶段2-4之间的Shuffle Unit,调整通道数保证复杂度类似。

可以看到ShuffleNet的表现是比较出色的。有趣的是,我们发现特征映射通道和精度之间是存在直观上的关系,以38MFLOPs为例,VGG-like, ResNet, ResNeXt, Xception-like, ShuffleNet模型在阶段4上的输出通道为50, 192, 192, 288, 576,这是和精度的变化趋势是一致的。我们可以在给定的预算中使用更多的通道,通常可以获得更好的性能。
上述的模型不包括GoogleNet或Inception结构,因为Inception涉及到太多超参数了,做为参考,我们采用了一个类似的轻量级网络PVANET。结果如下:
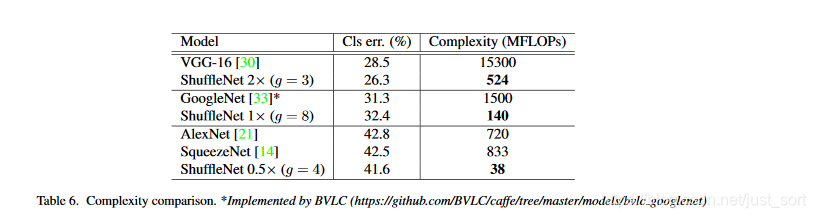
后面的我就不说了,都是一些速度和精度对比。
结论¶
论文针对现多数有效模型采用的逐点卷积存在的问题,提出了组卷积和通道混洗的处理方法,并在此基础上提出了一个ShuffleNet unit,后续对该单元做了一系列的实验验证,证明了ShuffleNet的结构有效性。
附录¶
- 论文原文:https://arxiv.org/pdf/1707.01083.pdf
- 参考资料1:https://blog.csdn.net/u011974639/article/details/79200559
推荐阅读¶
- 快2020年了,你还在为深度学习调参而烦恼吗?
- 卷积神经网络学习路线(七)| 经典网络回顾之AlexNet
- 卷积神经网络学习路线(八)| 经典网络回顾之ZFNet和VGGNet
- 卷积神经网络学习路线(九)| 经典网络回顾之GoogLeNet系列
- 卷积神经网络学习路线(十)| 里程碑式创新的ResNet
- 卷积神经网络学习路线(十一)| Stochastic Depth(随机深度网络)
- 卷积神经网络学习路线(十二)| 继往开来的DenseNet
- 卷积神经网络学习路线(十三)| CVPR2017 Deep Pyramidal Residual Networks
- 卷积神经网络学习路线(十四) | CVPR 2017 ResNeXt(ResNet进化版)
- 卷积神经网络学习路线(十五) | NIPS 2017 DPN双路网络
- 卷积神经网络学习路线(十六) | ICLR 2017 SqueezeNet
- 卷积神经网络学习路线(十七) | Google CVPR 2017 MobileNet V1
- 卷积神经网络学习路线(十八) | Google CVPR 2018 MobileNet V2
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次