前言¶
紧接着上篇的MobileNet V1,Google在2018年的CVPR顶会上发表了MobileNetV2,论文全称为《MobileNetV2: Inverted Residuals and Linear Bottlenecks》,原文地址见附录。
MobileNet-V2的来源¶
Mobilenet-V1的出现推动了移动端的神经网络发展。但MobileNet V1主要使用的Depthwise Conv(深度可分离卷积)虽然降低了9倍的计算量,但遗留了一个问题是我们在实际使用的时候训练完发现kernel有不少是空的。当时我们认为,Depthwise每个kernel dim相对于普通Conv要小得多,过小的kernel_dim, 加上ReLU的激活影响下,使得神经元输出很容易变为0,然后就学废了(因为对于ReLU来说,值为0的地方梯度也为0)。我们还发现,这个问题在定点化低精度训练的时候会进一步放大。所以为了解决这一大缺点,MobileNet-V2横空出世。
MobileNet-V2的创新点¶
反残差模块¶
MobileNet V1没有很好的利用残差连接,而残差连接通常情况下总是好的,所以MobileNet V2加上残差连接。先看看原始的残差模块长什么样,如Figure3左图所示:
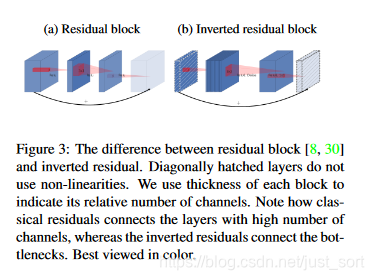
在原始的残差模块中,我们先用1\times 1卷积降通道过ReLU,再用3\times 3空间卷积过ReLU,再用1\times 1卷积过ReLU恢复通道,并和输入相加。之所以要1\times 1卷积降通道,是为了减少计算量,不然中间的3\times 3空间卷积计算量太大。所以残差模块k是沙漏形,两边宽中间窄。
而MobileNet V2提出的残差模块的结构如Figure 3右图所示:中间的3\times 3卷积变为了Depthwise的了,计算量很少了,所以通道可以多一点,效果更好,所以通过1\times 1卷积先提升通道数,再用Depthwise的3\times 3空间卷积,再用1x1卷积降低维度。两端的通道数都很小,所以1x1卷积升通道或降通道计算量都并不大,而中间通道数虽然多,但是Depthwise 的卷积计算量也不大。本文将其称为Inverted Residual Block(反残差模块),两边窄中间宽,使用较小的计算量得到较好的性能。
最后一个ReLU6去掉¶
首先说明一下ReLU6,卷积之后通常会接一个ReLU非线性激活函数,在MobileNet V1里面使用了ReLU6,ReLU6就是普通的ReLU但是限制最大输出值为6,这是为了在移动端设备float16/int8的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活函数不加限制,输出范围0到正无穷,如果激活函数值很大,分布在一个很大的范围内,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。MobileNet V2论文提出,最后输出的ReLU6去掉,直接线性输出。理由是:ReLU变换后保留非0区域对应于一个线性变换,仅当输入低维时ReLU能保留所有完整信息。
网络结构¶
这样,我们就得到 MobileNet V2的基本结构了。下图左边是没有残差连接并且最后带ReLU6的MobileNet V1的构建模块,右边是带残差连接并且去掉了最后的ReLU6层的MobileNet V2构建模块:
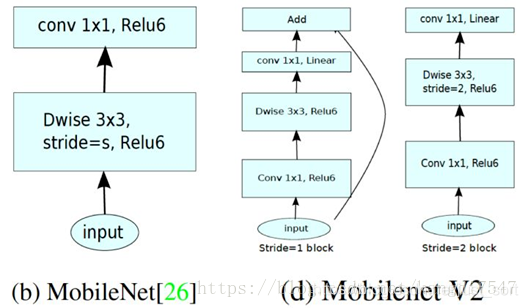
网络的详细结构如Table2所示。

其中,t是输入通道的倍增系数(即是中间部分的通道数是输入通道数的多少倍),n是该模块的重复次数,c是输出通道数,s是该模块第一次重复时的stride(后面重复都是stride等于1)。
实验结果¶
通过反残差模块这个新的结构,可以使用更少的运算量得到更高的精度,适用于移动端的需求,在 ImageNet 上的准确率如Table4所示。
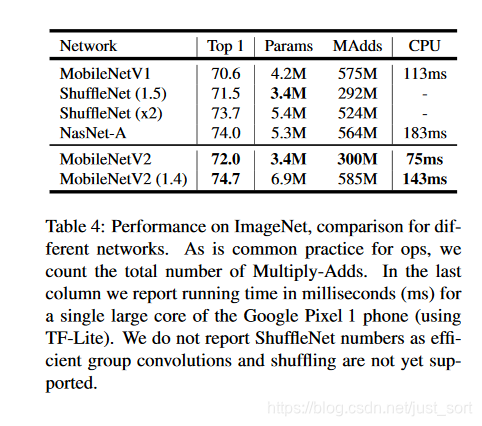
可以看到MobileNet V2又小又快。并且MobileNet V2在目标检测任务上,也取得了十分不错的结果。基于MobileNet V2的SSDLite在COCO数据集上map值超过了YOLO V2,且模型大小小10倍,速度快20倍。

总结¶
- 本文提出了一个新的反残差模块并构建了MobileNet V2,效果比MobileNet V1更好,且参数更少。
- 本文最难理解的其实是反残差模块中最后的线性映射,论文中用了很多公式来描述这个思想,但是实现上非常简单,就是在 MobileNet V1微结构(bottleneck)中第二个1\times 1卷积后去掉 ReLU6。对于低维空间而言,进行线性映射会保存特征,而非线性映射会破坏特征。
Pytorch代码实现¶
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
planes = expansion * in_planes
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
self.shortcut = nn.Sequential()
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out = out + self.shortcut(x) if self.stride==1 else out
return out
class MobileNetV2(nn.Module):
# (expansion, out_planes, num_blocks, stride)
cfg = [(1, 16, 1, 1),
(6, 24, 2, 1), # NOTE: change stride 2 -> 1 for CIFAR10
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
def __init__(self, num_classes=10):
super(MobileNetV2, self).__init__()
# NOTE: change conv1 stride 2 -> 1 for CIFAR10
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(1280)
self.linear = nn.Linear(1280, num_classes)
def _make_layers(self, in_planes):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1]*(num_blocks-1)
for stride in strides:
layers.append(Block(in_planes, out_planes, expansion, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.relu(self.bn2(self.conv2(out)))
# NOTE: change pooling kernel_size 7 -> 4 for CIFAR10
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
附录¶
- 论文原文:https://arxiv.org/abs/1801.04381
- 参考资料:https://blog.csdn.net/kangdi7547/article/details/81431572
推荐阅读¶
- 快2020年了,你还在为深度学习调参而烦恼吗?
- 卷积神经网络学习路线(七)| 经典网络回顾之AlexNet
- 卷积神经网络学习路线(八)| 经典网络回顾之ZFNet和VGGNet
- 卷积神经网络学习路线(九)| 经典网络回顾之GoogLeNet系列
- 卷积神经网络学习路线(十)| 里程碑式创新的ResNet
- 卷积神经网络学习路线(十一)| Stochastic Depth(随机深度网络)
- 卷积神经网络学习路线(十二)| 继往开来的DenseNet
- 卷积神经网络学习路线(十三)| CVPR2017 Deep Pyramidal Residual Networks
- 卷积神经网络学习路线(十四) | CVPR 2017 ResNeXt(ResNet进化版)
- 卷积神经网络学习路线(十五) | NIPS 2017 DPN双路网络
- 卷积神经网络学习路线(十六) | ICLR 2017 SqueezeNet
- 卷积神经网络学习路线(十七) | Google CVPR 2017 MobileNet V1
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次