引言¶
本文重新回顾了常规卷积的设计,其具有两个重要性质,一个是空间无关性,比如3x3大小的卷积核是以滑窗的形式,滑过特征图每一个像素(即我们所说的参数共享)。另外一个是频域特殊性,体现在卷积核在每个通道上的权重是不同的。
我们对以上的设计原则进行了"反转",设计了一种 involution(内卷???)的操作,一方面能降低模型的参数量,另一方面也能提升模型性能,还能和最近很火的自注意力机制联系起来。该模块在各大图像任务上都有不错的性能提升。
简单回顾卷积¶
最初的神经网络都是由一层层全连接层网络叠加起来,对于简单的任务来说参数量还好。但是对于图像任务,动辄几百上千的像素,则全连接层的参数量会十分巨大。如果是全连接层处理二维图像,那么大致形式如下
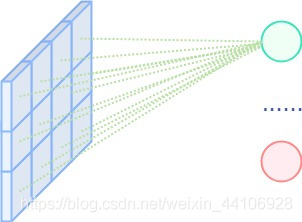
而卷积神经网络考虑了局部连接性,只考虑了局部的像素,从而让参数量大大减少,形式如下
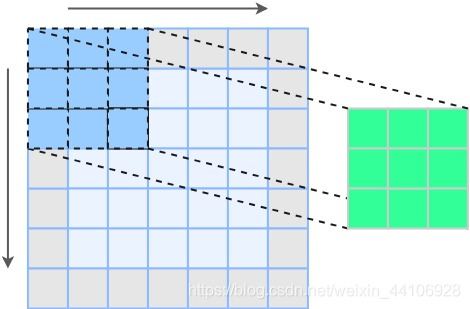
由于常规卷积核是对所有输入通道进行计算,在起初的一些低算力设备上计算损耗还是很大,Alexnet提出分组卷积,对输入通道进行分组,然后单独卷积,形式如下
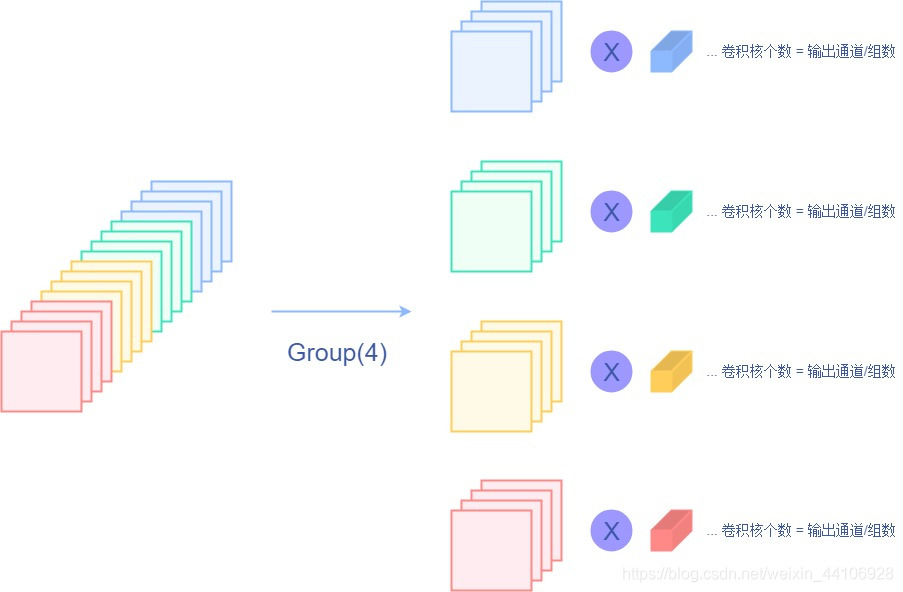
而谷歌提出的Depthwise Conv则将分组卷积推向了极端——分组数是输入通道数目,即每个输入通道单独卷积,形式如下
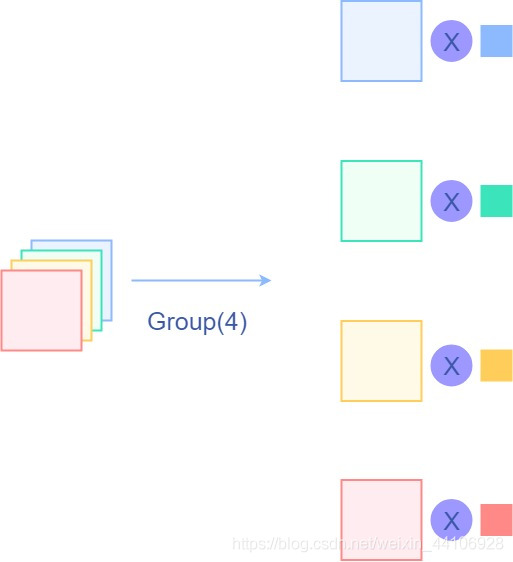
卷积核形式的演进还是基于通道做的,最基础的两个性质空间无关性和频域特殊性依旧没有改变。而Involution操作给出了一个不同的思路。
Involution的设计原则¶
Involution的设计原则就是颠倒常规卷积核的两个设计原则,即从空间无关性,频域特殊性转变成空间特殊性,频域无关性
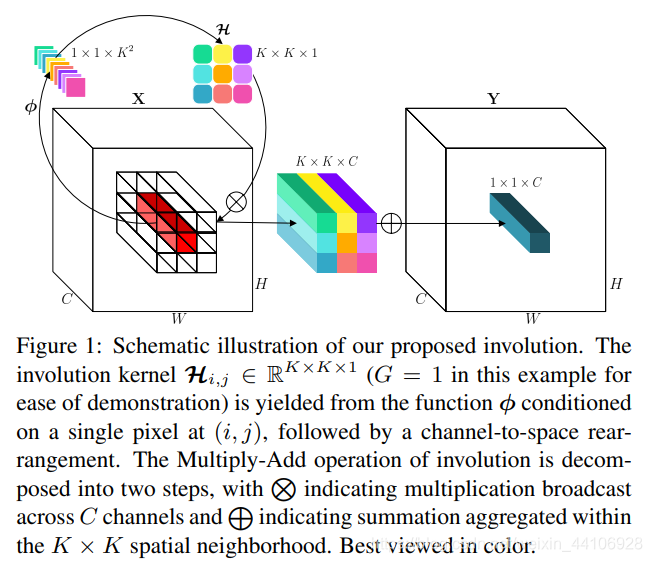
卷积神经网络存在下采样层,导致各个阶段的特征图长宽会变化。既然要与空间域联系起来,那么第一个问题是如何参数化一个Invotion的卷积核。一个很自然的想法就是设置一个函数 \phi,让他根据输入的张量,输出一个跟特征图长宽相关的张量,再把它作为卷积核。
该函数公式写为
在实际的代码中,作者用一个类似BottleNeck的形式,可以通过控制缩放比例调整参数量,用两个1x1卷积对通道进行缩放,最后一个卷积输出通道数为(K * K * Groups),其中K代表后续involution卷积核大小,Groups代表involution操作的分组数。(如果遇到需要下采样的情况,则接一个步长为2的平均池化层。),最后我们可以得到一个形状为N(K * K * Groups)H*W的张量,下面是这部分操作的代码
...
reduction_ratio = 4
self.group_channels = 16
self.groups = self.channels // self.group_channels
self.conv1 = ConvModule(
in_channels=channels,
out_channels=channels // reduction_ratio,
kernel_size=1,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'))
self.conv2 = ConvModule(
in_channels=channels // reduction_ratio,
out_channels=kernel_size**2 * self.groups,
kernel_size=1,
stride=1,
conv_cfg=None,
norm_cfg=None,
act_cfg=None)
def forward(self, x):
weight = self.conv2(self.conv1(x if self.stride == 1 else self.avgpool(x)))
...
下面就会拿这个weight来做当作一个卷积核,对x卷积。
读到这里可能会比较奇怪,为什么卷积核形状长这样,我们常见的卷积核应该是(C_in, C_out, K, K)。这其实也是这篇工作的关键之处,上面我们提到他这里注重的是频域无关性,空间特殊性。因此它分组卷积的做法是 每一组内的特征图共享一个卷积核的参数,但是 同一组内,不同空间位置,使用的是不同的卷积核。
原文是 an involution kernel located at the corresponding coordinate (i, j), but shared over the channels.
这段比较费解,我画了一个简单的示意图
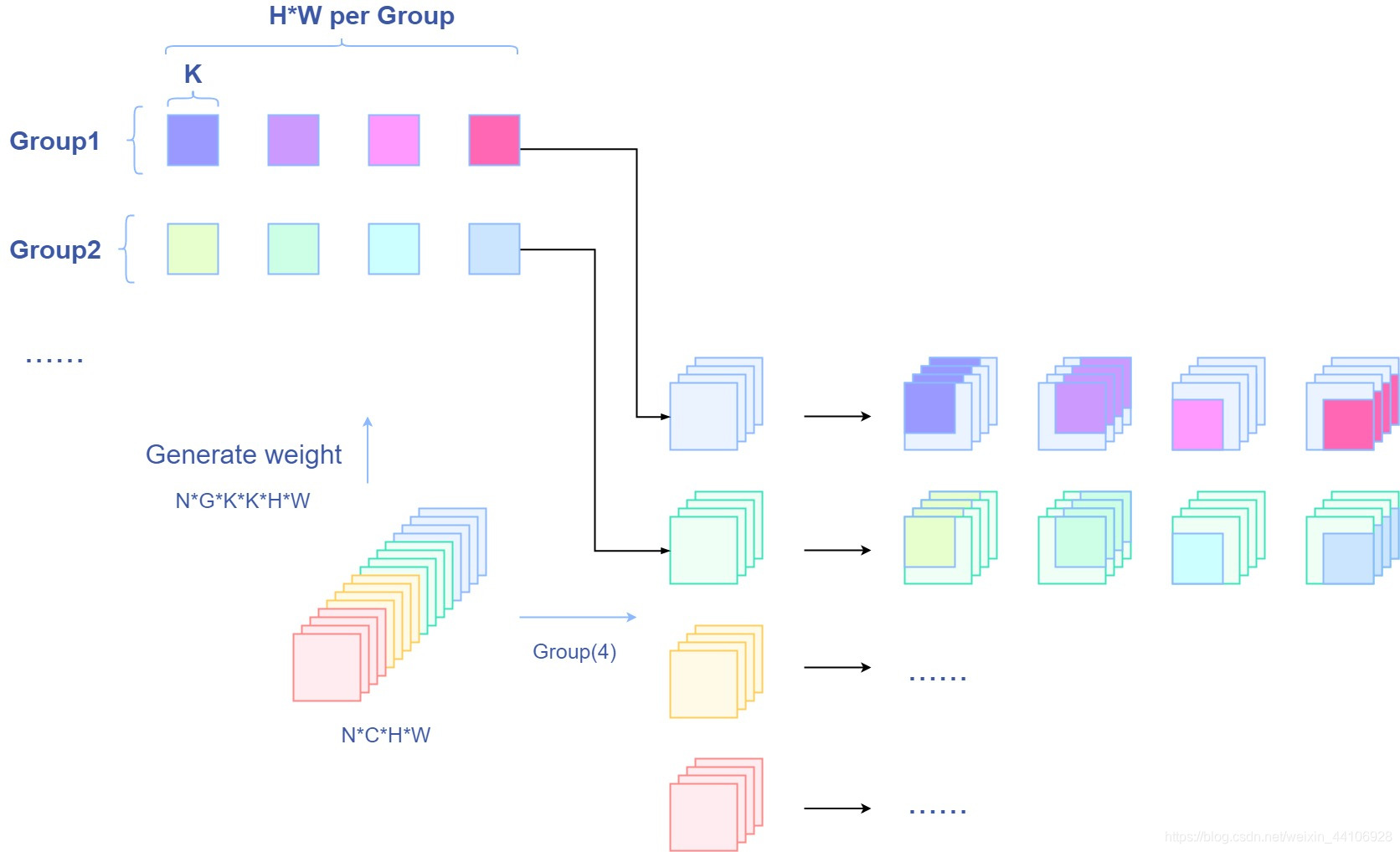
为了方便演示,这里设置N为1,特征图通道为16个,分组数为4,ksize=3
首先输入特征图被分为四组,每组有4个特征图 之前经过两次1x1卷积,我们得到了involution所需的权重,形状为(N, Groups, ksize * ksize, H, W), 在该例子中为(1, 4, 3 * 3, H, W) ,那么分配给每个组的,就是一个(1, 3 * 3, H, W),不考虑Batchsize的话,那么每组就有H * W个3x3的卷积核。
在通道维上,每组的特征图共享一个卷积核,而在同一组的不同空间位置,使用不同的卷积核。
处理完后,再把各组的结果拼接回来,下面是完整的involution操作代码
import torch.nn as nn
from mmcv.cnn import ConvModule
class involution(nn.Module):
def __init__(self,
channels,
kernel_size,
stride):
super(involution, self).__init__()
self.kernel_size = kernel_size
self.stride = stride
self.channels = channels
reduction_ratio = 4
self.group_channels = 16
self.groups = self.channels // self.group_channels
self.conv1 = ConvModule(
in_channels=channels,
out_channels=channels // reduction_ratio, # 通过reduction_ratio控制参数量
kernel_size=1,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'))
self.conv2 = ConvModule(
in_channels=channels // reduction_ratio,
out_channels=kernel_size**2 * self.groups,
kernel_size=1,
stride=1,
conv_cfg=None,
norm_cfg=None,
act_cfg=None)
if stride > 1:
# 如果步长大于1,则加入一个平均池化
self.avgpool = nn.AvgPool2d(stride, stride)
self.unfold = nn.Unfold(kernel_size, 1, (kernel_size-1)//2, stride)
def forward(self, x):
weight = self.conv2(self.conv1(x if self.stride == 1 else self.avgpool(x))) # 得到involution所需权重
b, c, h, w = weight.shape
weight = weight.view(b, self.groups, self.kernel_size**2, h, w).unsqueeze(2) # 将权重reshape成 (B, Groups, 1, kernelsize*kernelsize, h, w)
out = self.unfold(x).view(b, self.groups, self.group_channels, self.kernel_size**2, h, w) # 将输入reshape
out = (weight * out).sum(dim=3).view(b, self.channels, h, w) # 求和,reshape回NCHW形式
return out
实验结果¶
作者基于ResNet模型,将Bottleneck模块的中间卷积块,替换成7x7大小的involution操作。改进后的模型称为RedNet
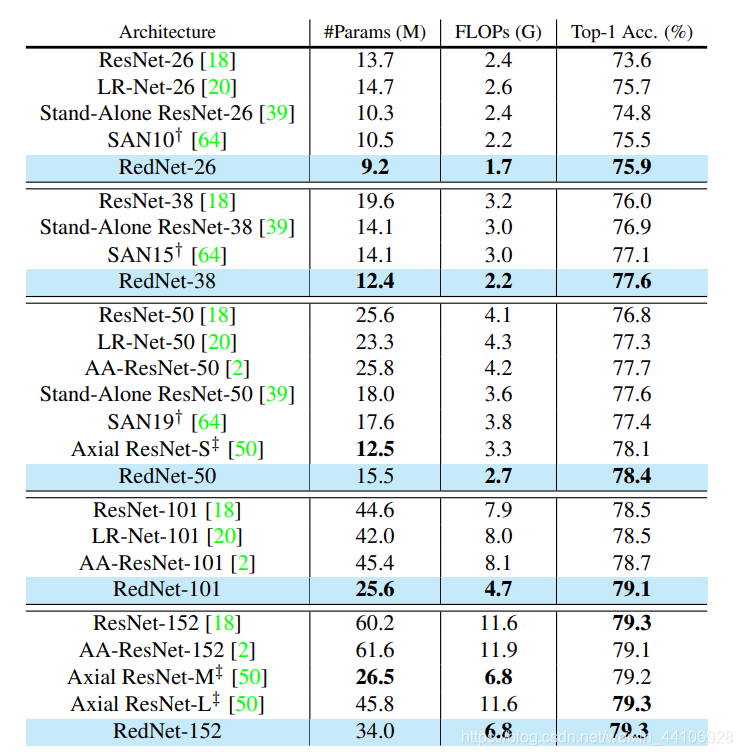
可以看到实验结果还是很不错的,不仅压缩了网络参数,在中小网络也能提升模型精度。(但我更好奇的是实际运行的速度,如每秒能处理多少图片),在其他图像任务上也有提升,这里就不放出来了,有兴趣的读者可以去读下原文。
对于Involution操作的分组数,Kernel大小,作者也做了相关消融实验
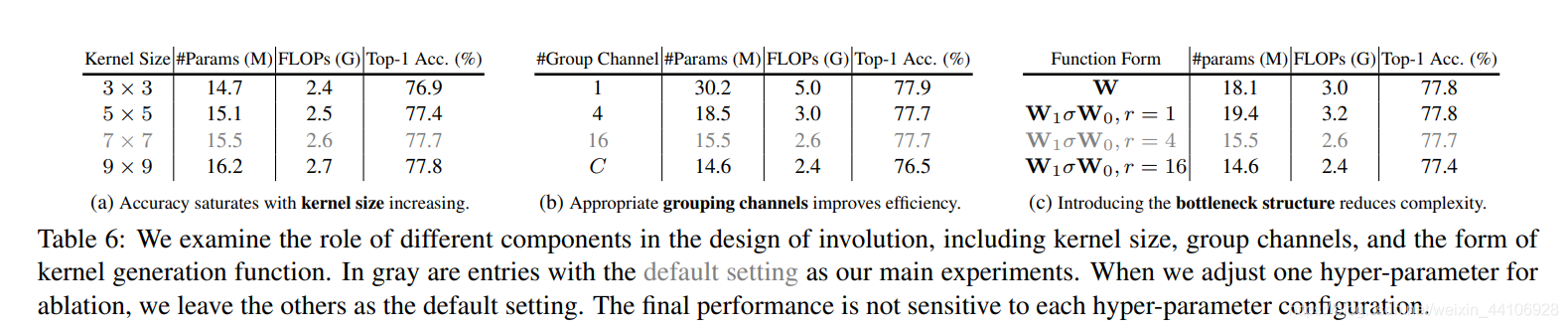
可以看到从3x3到7x7,精度是稳定提高的,但是加到9x9以后提升有限。为了平衡参数量和精度,作者选择了7x7大小的Kernel,分组通道数为16,生成Kernel的卷积模块里,reduction参数设为4。
总结¶
这篇论文还是挺有意思的,作者阵容也很豪华,其中包括SENet的作者HuJie。现在的卷积核改进基本都是从通道维度去做,而这篇工作颠覆了这种思想,跟常规卷积反着来,做了一个自己卷自己的内卷操作。
论文还提到了这个操作和自注意力机制的关系,但是笔者并没有读太懂,就没有阐述(还望相关作者解答下)。作者还留了一些坑,我未来也很期待NAS在该模块上更多的探索。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次