前言¶
近期,Transformer和MLP结构抛弃了CNN的归纳偏置,冲击着视觉领域。其中视觉MLP开山作MLP-Mixer抛弃了卷积,自注意力的结构,仅使用全连接层。 为了对不同的Patch进行交互,除了常规的channel-mixing MLP,还引入了额外的token-mixing(也就是将特征图转置下,再接MLP)。这些方法为了达到优异的性能,需要在大型数据集上预训练。
为此我们分析了其中的token-mixing,发现其等价于一个拥有全局感受野,且空间特异性的Depthwise卷积,但这两个特性会引入过拟合的风险。
为此我们提出了Spatial-shift MLP结构,我们抛弃了token-mixing的过程,而引入了空间移位操作,它具有局部感受野,并且是spatial-agnostic。
回顾MLP-Mixer¶
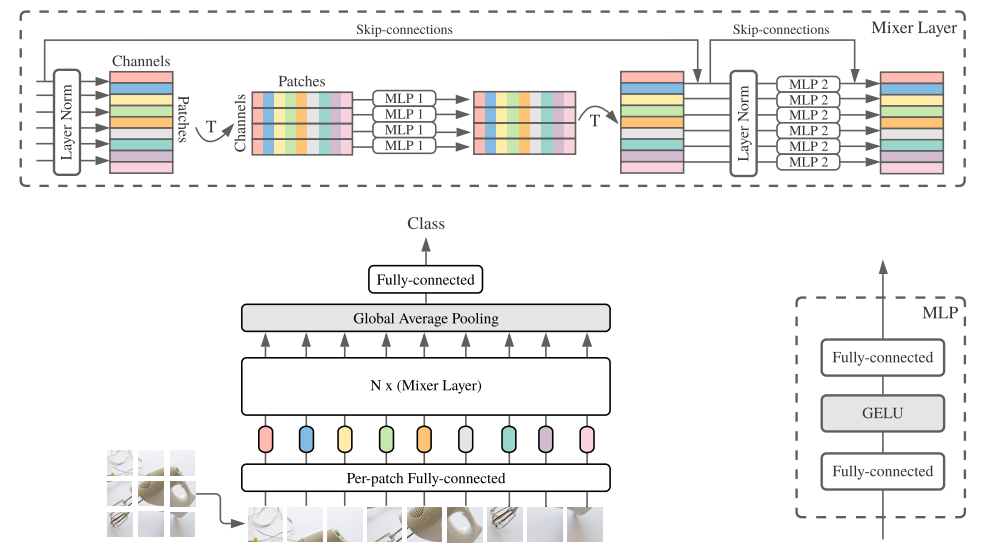
这里先简单介绍下MLP-Mixer的原理
- 首先跟ViT一样,把图片切成多个patch,并进行一个Embedding操作
- 经过一层LayerNorm
- 对特征图进行转置,从
N, P, C转置为N, C, P - 经过MLP结构,这两步也叫
token-mixing - 再转置回来,加入残差连接
- 经过一层LayerNorm,再经过MLP结构,这叫
channel-mixing - 加入残差连接
整个流程如图所示:
与Depthwise卷积的联系¶
熟悉Depthwise卷积的同学都知道,它是分组卷积的一个特例,即每次卷积只对输入的一个通道进行处理,也就是说与其他通道并没有交互。
这里简单画了个图,假设我们输入时一个4x4的图片,我们以2x2的patch切下来,并且做转置。
其中P表示Patch,C表示Channel
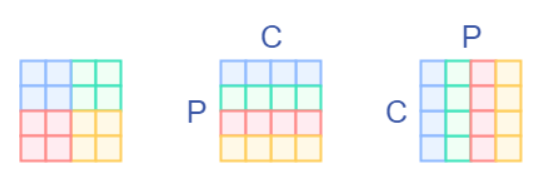
然后我们接如一个全连接层,这里其实就是做一个矩阵乘
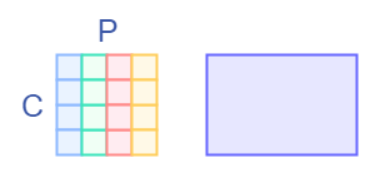
可以看到在做矩阵乘的时候,左边矩阵参与运算的只有每一行元素,而每一行元素都是单一的通道,这和Depthwise的操作是一致的。
此外,Depthwise卷积也保留了卷积的局部,空间共享性。而token-mixing操作则是引入了全局性质,不同空间上,对应的权重也不一样。因此我们可以认为token-mixing是Depthwise的一个变体。
Spatial Shift MLP怎么做?¶
想要去掉token-mixing操作,那就需要找到一个能够加强各个Patch间联系的操作。受视频理解模型TSM启发,TSM通过时序移位操作,建模相邻帧的时序依赖关系。Spatial Shift MLP引入空间移位操作,来增强各个Patch的联系。
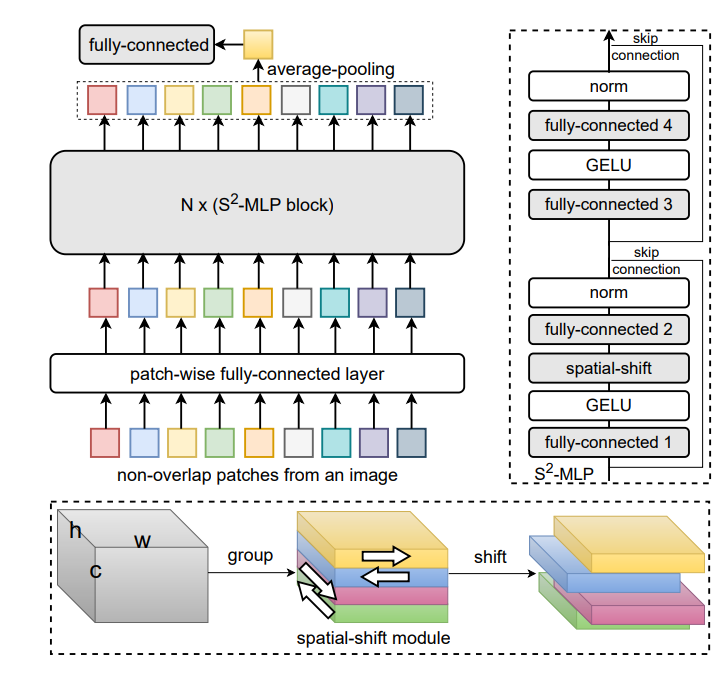
Spatial shift operation¶
首先我们给定一个输入X,其形状为W, H, C
然后将该输入在通道维度上进行分组,这里我们只移动四个方向,因此分为四组,然后每一组为W, H, C/4。
接着是对每组输入进行不同方向的移位操作,以第一组为例子,我们在W维度上移一格,第二组在W操作反着移一格。同理另外两组在H维度上进行相同操作。一段伪代码如下所示:
def spatial_shift(x):
w,h,c = x.size()
x[1:,:,:c/4] = x[:w-1,:,:c/4]
x[:w-1,:,c/4:c/2] = x[1:,:,c/4:c/2]
x[:,1:,c/2:c*3/4] = x[:,:h-1,c/2:c*3/4]
x[:,:h-1,3*c/4:] = x[:,1:,3*c/4:]
return x
而这四个移位操作,其实等价与四个固定权重的分组卷积,各卷积核权重如下所示:
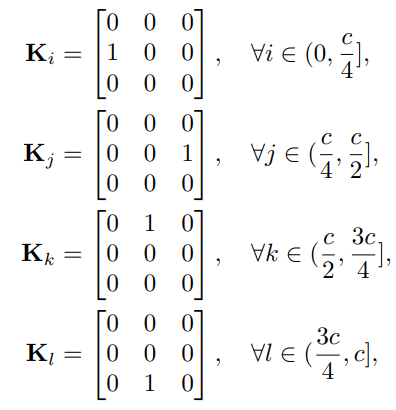
整个Spatial-shift Block和MLP-Mixer的Block差不多,这离不过多阐述,可以参考上面的示意图。
复杂度分析¶
这里只分析整个Block的复杂度。
给定输入通道为c, Block中需要扩增维度,我们定义扩增后的维度为\bar{c} = 4c
这里全连接层参数都带有偏置项
前面两个全连接层不改变通道数,因此这两个参数量为
接着一个全连接层需要扩增维度,参数量为
最后全连接层将维度恢复回来,参数量为:
总的参数量为:
得到总参数量,我们可以很容易得到FLOPS,我们假设输入特征图有M个Patch,则一个Block的FLOPS为:
实验结果¶
我们分别设计了wide和deep两种结构,主要区别在全连接层通道数量和Block的数量
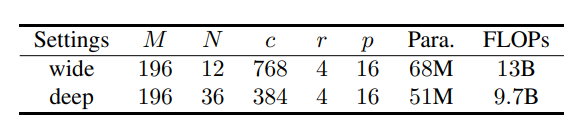
下面是实验对比,基于ImageNet-1K数据集训练

在没预训练的情况下,表现还是不错的
消融实验¶
常规的Block数目,通道数的消融实验这里省略,有兴趣的读者可以翻下原文。我们这里看下其他几个有意思的实验。
消融实验的数据集为ImageNet的子集ImageNet100,因此准确率会和前面的结果不一样
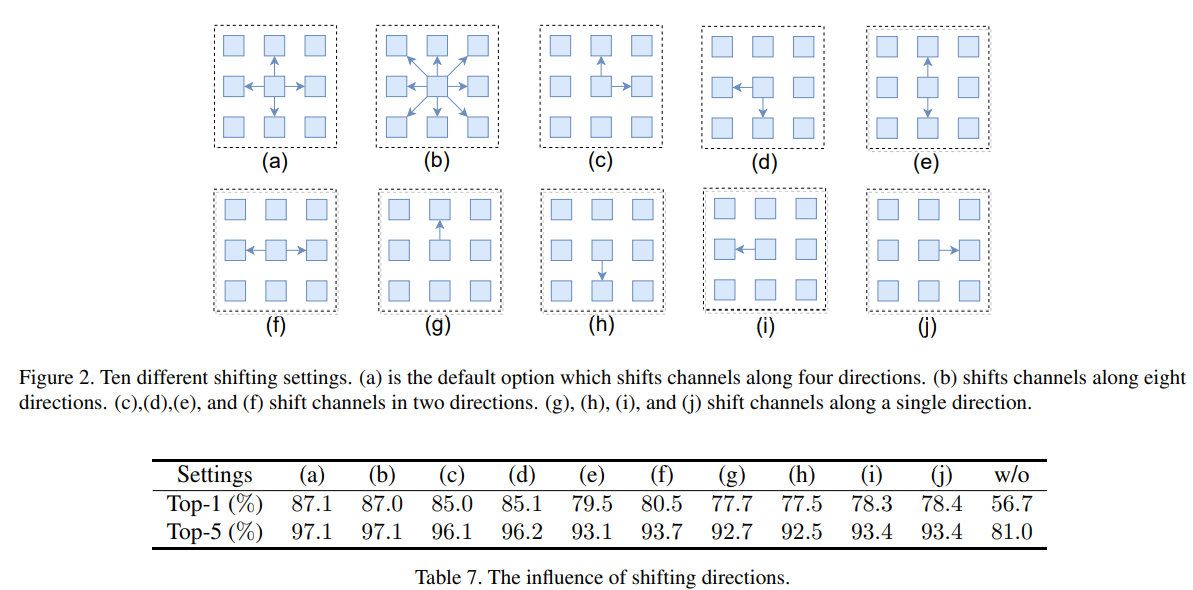
首先是shift操作的消融实验,作者是基于八个方向shift进行对比,发现还是上下左右这四个方向移位效果最好
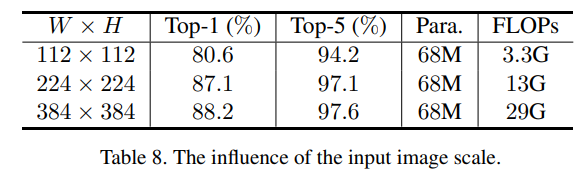
增大输入图像尺寸能大幅提升准确率,同时增加很多运算量
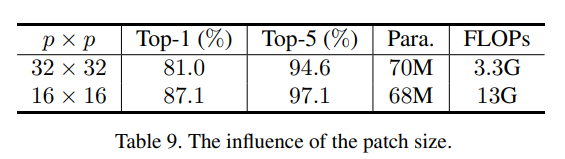
Patchsize变小也能大幅提升准确率,比较小的patch能有助于获取细节信息,但是增加了patch数量,模型FLOPS也大幅增加
总结¶
之前没写MLP-Mixer是因为我觉得谷歌又玩起那套祖传JFT预训练的骚操作,普通人根本玩不了,没有实用价值。随着不断的探索,研究者加入一些适当的偏置能够减少对大数据集的依赖(跟ViT那套是不是很相似?)。这篇工作思想也很朴实,借鉴了TSM的移位操作,来给MLP加入空间相关的偏置,在ImageNet1K也能得到不错的效果,个人还是希望能有一个更朴实高效的移动端MLP模型供我这种没卡的穷人使用。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次