CVPR 2023 LargeKernel3D 在3D稀疏CNN中使用大卷积核
CVPR 2023 | LargeKernel3D:在3D稀疏CNN中使用大卷积核¶
解读:Freedom
Paper title: LargeKernel3D: Scaling up Kernels in 3D Sparse CNNs
Paper: https://arxiv.org/pdf/2206.10555.pdf
Code: https://github.com/dvlab-research/LargeKernel3D
导读¶
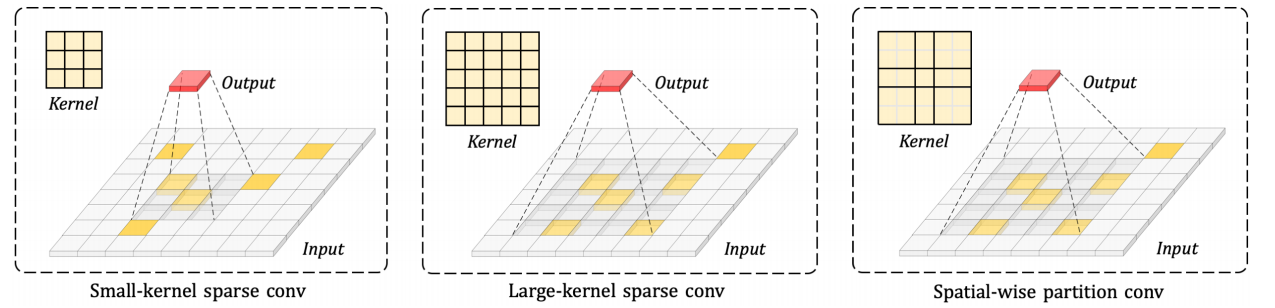
2D CNN 使用大卷积代替小卷积,增大了卷积核的感受野,捕获到的特征更偏向于全局,效果也得到了提升,这表明较大的 kernel size 很重要。但是,当直接在 3D CNN 中应用大卷积核时,那些在 2D 中成功的模块设计在 3D 网络效果不好,例如深度卷积。为了应对这一重要挑战,本文提出了空间分区卷积及其大的 kernel size 模块,它避免了原始 3D 大卷积核的优化和效率问题。
本文的大卷核 3D CNN 网络 LargeKernel3D 在语义分割和对象检测的 3D 任务中取得了显着改进。它在 ScanNetv2 语义分割任务上实现了 72.8%的mIOU,在 NDS nuScenes 目标检测基准上达到了 73.9% 的 mIoU,在 nuScenes LIDAR 排行榜上排名第一。通过简单的多模式融合,性能进一步提升至 74.2% NDS。此外,LargeKernel3D 在 Waymo 3D 对象检测上可以将卷积核扩大到 17×17×17 大小。首次证明大卷积核对于 3D 视觉任务是可行且必不可少的。
简介¶
3D任务中普遍使用3D稀疏卷积网络进行特征提取,一些方法使用 Transformer进行编-解码。由于后者的全局和局部自我注意机制能够从大空间范围内捕获上下文信息,这对前者的有效感受野提出了挑战。相比之下,常见的 3D 稀疏 CNN 受到了限制。2D CNN中,有一系列结合大卷积核提高有效感受野范围的方法,例如,ConvNeXt 采用 7×7 深度卷积,RepLKNet 使用 31×31 的超大卷积核。但是由于3D 和 2D 任务之间的差异,这些方法并不能直接用于3D 稀疏 CNN 。因此,3D 大核 CNN 设计难点主要分为两个方面:(1)效率问题 增大3维立方卷积核时,参数量和计算负担的增长速度比 2D CNN 快得多。比如,卷积核从 3x3x3 变为 7×7×7 时,模型大小增加了不止 10 倍;(2)优化问题 相比2D数据集,3D数据基准规模没那么大,通常只包含不超过一千个场景。同时,3D 点云是稀疏的,而不是密集的,这导致优化大卷积核的参数比较困难而造成过拟合问题。
作者提出空间分区卷积作为 3D 大核设计。通过在空间相邻位置之间共享权重,代替通道级组的深度卷积。如图 1 所示,空间分区卷积通过对邻近空间进行分组将大内核(例如 7×7)重新映射为小内核(例如 3×3),而整个空间大小保持不变。具体说来,就是将内核分成不同的部分,由于每个部分的权重共享,位置信息可能会变得模糊,因此,使用相对位置编码作为偏差来补充丢失的位置信息。关于效率问题,它占用很少的模型尺寸来保持参数与小内核的参数相同。此外,与普通的大型内核对应物相比,所需延迟更低。至于优化挑战,空间维度之间的权重共享为参数提供了更多更新和克服过度拟合问题的机会。
贡献¶
本文的贡献主要有以下几点:
(1) 提出了 LargeKernel3D 神经网络结构,通过组合多个较小的卷积核构成的一个较大的卷积核,从而显著提高了网络的精度,同时保持相对较小的参数量;
(2) 在几个常见的3D数据集上,LargeKernel3D 都表现出了优于其他最先进的3D稀疏卷积神经网络的表现;
(3) 提出了相对位置编码作为偏差来补充丢失的位置信息,解决权重共享导致的模糊问题。
通过这些贡献,这篇论文在3D卷积神经网络领域提供了一种高效而准确的解决方案,为3D图像分析和视觉任务提供了有用的工具。
3D Sparse CNNs¶
3D 稀疏卷积神经网络是一种针对三维图像数据的神经网络,专门用于处理稀疏(或称为稀有)的三维数据,例如医学图像、点云数据等。与传统的全连接卷积神经网络不同,稀疏卷积神经网络仅对稀疏空间进行计算。这种方法将必要的信息与无关的信息分离开来,避免处理输入数据中多余的零值点,从而可以显著减少计算成本,更有效地利用计算资源,并提高对不均匀或无规则的空间数据的识别能力。
3D 稀疏CNN的构建与传统的3D卷积神经网络相似,在其基础上引入了稀疏输入和输出,以及乘法卷积(或称为空间卷积)操作。稀疏卷积同时考虑了空间和特征通道之间的关系,这允许它更好地处理具有复杂空间结构的数据。与稠密数据相比,空间中的稀疏数据包含较少可处理的有效数据点,3D稀疏CNN在前向计算过程中会自动选取非零节点作为计算节点,采用特殊的卷积操作(如空间卷积、乘法卷积等)更好的利用稀疏数据中的特征。
方法 Method¶
Spatial-wise Partition Convolution¶
一般,卷积核可以看作是一个3D矩阵,由输入通道C_{in}、输出通道C_{out}和卷积核维度K组成。假设卷积核大小为k,那么在2D卷积中,卷积核维度K=k^2;同理,在2D卷积中,卷积核维度K=k^3。深度卷积沿通道维度共享权重,分组数=输入通道。逐点卷积将内核大小固定为 1,这通常作为深度卷积的联合层来调整输出通道。
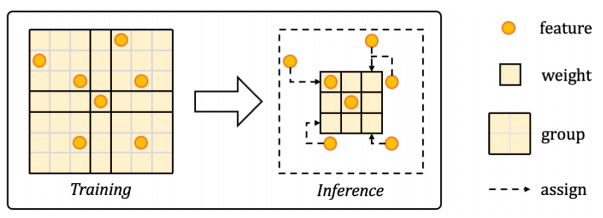
本文所提的3D 大卷积 CNN 的空间分区卷积。它在卷积核上的空间维度 K 之间共享权重,而不是在通道维度之间共享权重。也不同于 SGC,后者根据输入特征划分空间组。这里通过在邻近空间之间共享权重,将原始的大卷积核从 7×7 分组为 3×3。由于输入特征是稀疏的,为了避免卷积核扩大带来的额外开销,在推理过程中直接使用小核层,并将其特征分配区域扩大到大核范围(如图 3 所示),由于权重共享操作,它大大节省了乘法,从 343 次减少到 27 次。
Kernel-wise Position Encoding¶
邻近空间之间共享权重,会导致局部细节模糊。随着核大小增加,这个问题越来越严重。为了解决该问题,首先初始化位置权重,让输入的特征查询对应位置的位置权重,最后进行相加:
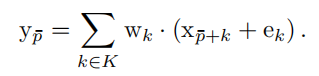
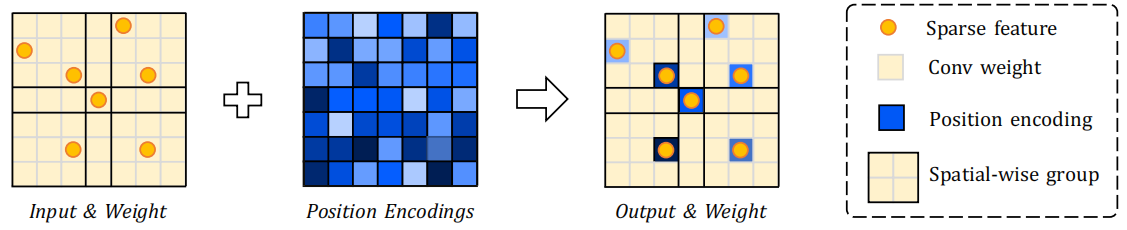
这步的本质是将具有相对位置信息的偏差添加到输入特征中。如下图,SW-LK Conv由一个大核空间分区卷积和一个可学习的 Position Encodings 组成。Position Encodings 用于弥补大卷积核的细节捕获能力。
实验¶
首先比较了普通 3D 子流形稀疏卷积与本文卷积之间的效率,随着卷积核增大,普通3D卷积的参数量和延迟都急剧上升,而本文的方法效率要高得多。

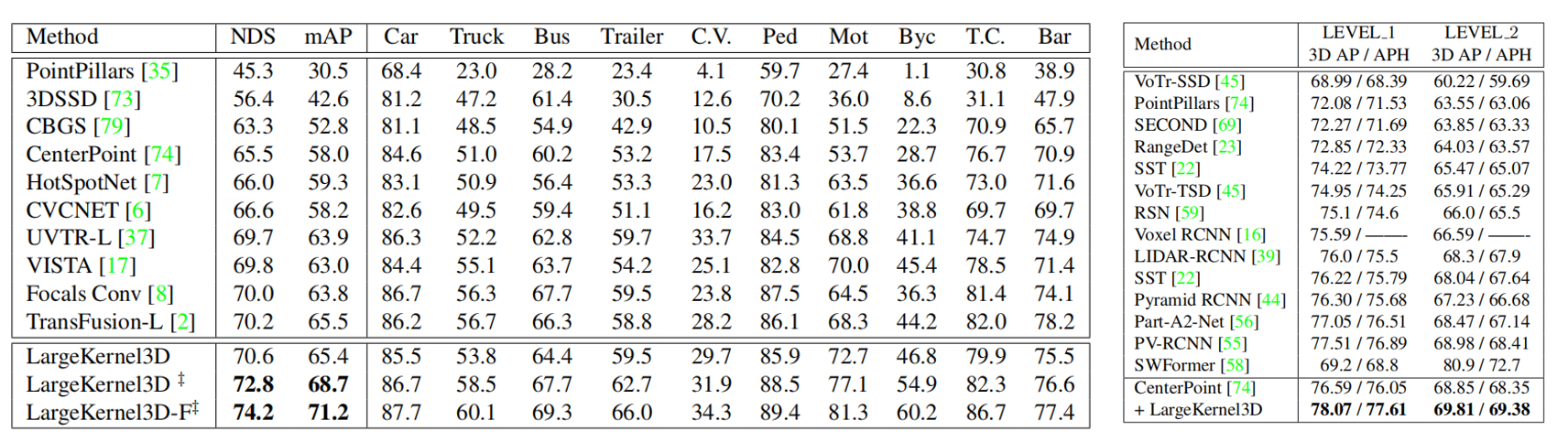
作者在 3D 分割和检测两个下游任务上,进行了验证。检测任务使用的是 nuScenes(左), Waym (右)两个数据集,对比情况如下,可以看到使用LargeKernel3D ,精度最高。其中,LargeKernel3D 将 CenterPoint 提高到 70.6% 和 72.8% NDS,无论有没有进行测试增强,两者都优于其他的 LIDAR 方法。多模态模态 LargeKernel3DF 进一步提高到 74.2% NDS 和 71.2% mAP。
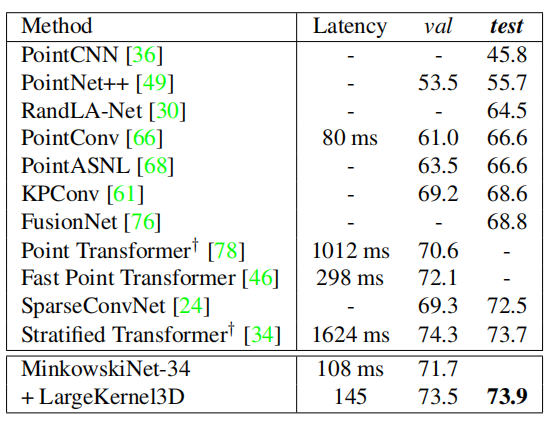
下面是分割任务上的对比情况,在测试集上,本文方法达到SOTA。 MinkowskiNet 是 ScanNetv2 中最先进的方法, SW-LK Conv(本文方法) 进一步提高了它的性能。
然后是消融实验,作者对MinkowskiNet-34 和 ScanNetv2 上各种技术和核大小等进行了实验,LargeKernel3D 是有效的。

结论 Conclusion¶
这篇论文与 2D CNN 中的大卷积核有本质区别,深入研究了 3D 卷积网络的大卷积的设计。所提的专为 3D 大内核设计的空间分区卷积 (SW Conv),有效地解决了普通 3D 大核 CNN 中的效率和优化问题。基于这种设计,进一步提出了用于 3D 语义分割和对象检测的 SW-LK Conv 和相应的 LargeKernel3D。这种3D 大核网络在语义分割和目标检测任务上都取得了不错的改进,并首次展示了可以高效且有效地实现 3D 大内核。但是本文方法也存在局限性,例如 LargeKernel3D 在 3D 语义分割和对象检测基准测试中主要依赖于手工设计的空间内核大小。这些大小对于其他数据集或任务可能不是最优的,具体取决于整体场景大小和数据稀疏性。其他基于ENAS等搜索技术可能会有帮助,可以尝试一下。
本文总阅读量次