IBN-Net: 提升模型的域自适应性¶
本文解读内容是IBN-Net, 笔者最初是在很多行人重识别的库中频繁遇到比如ResNet-ibn这样的模型,所以产生了阅读并研究这篇文章的兴趣,文章全称是: 《Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net》。IBN-Net和SENet非常相似:
- 可以方便地集成到现有网络模型中。
- 在多个视觉任务中有着出色的表现,如分类、分割。
- 拿到了比赛第一名,IBN-Net拿到了 WAD 2018 Challenge Drivable Area track ,一个分割比赛的第一名。SENet拿到了最后一届ImageNet比赛的冠军。
1. 概述¶
IBN-Net出发点是:提升模型对图像外观变化的适应性。在训练数据和测试数据有较大的外观差异的时候,模型的性能会显著下降,这就是不同域之间的gap。比如训练数据中的目标光线强烈,测试数据中的目标光线昏暗,这样一般效果都不是很好。
之前有一个群友就是在研究一个域的数据如何迁移到另外一个分布不一致的域中的问题,当时认为在机器学习中训练的数据和测试数据的分布应该尽可能一致,这样才符合要求。但是实际应用中不可避免遇到训练数据无法将所有情况下(色调变化,明暗变化 )的数据都收集到,所以如何提升模型对图像外观变化的适应性、如何提高模型在不同域之间的泛化能力也是一个非常值得研究的课题。
IBN-Net能够有效提升模型在一个域中的效果(比如cityscapes-真实场景的数据),同时可以做到不fine-tuning就可以泛化到另外一个域中(比如GTA5-非真实场景的数据)。
文章主要有三个贡献:
- 通过深入IN和BN,发现IN对目标的外观变化具有不变性,比如光照、颜色、风格、虚拟和现实,BN可以保存内容相关的信息。
- IBN-Net可以应用到现有的STOA网络架构中,比如DenseNet, ResNet, ResNeXt, SENet等网络中,可以再不增加模型计算代价的情况下,有效提升模型的效果。
- IBN-Net域适应能力非常强,在cityscape数据集训练的模型,不需要再GTA5上fine-tuning就可以有比较可观的效果。


2. 方法¶
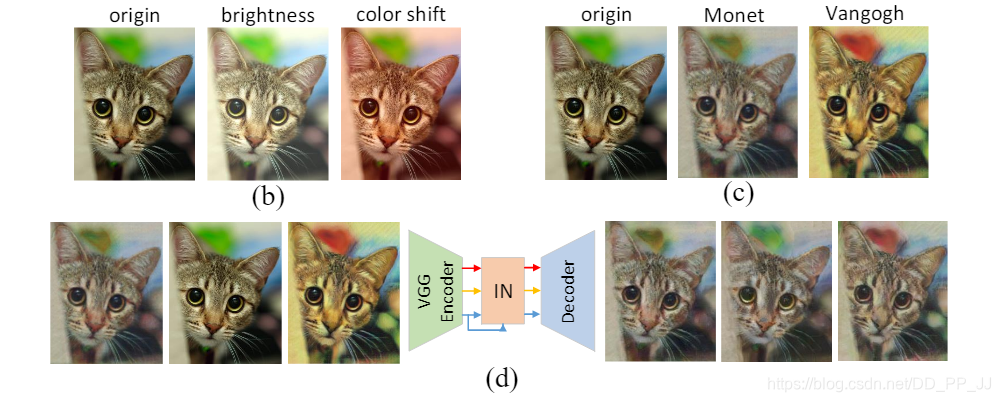
(b) 图是对原图进行亮度调整和色彩平移©图是对原图使用了两种风格化方法 (d)图是对©图使用Instance Norm以后的结果,这说明IN可以过滤掉复杂的外观差异。
通常IN用于处理底层视觉任务,比如图像风格化,而BN用于处理高层视觉任务,比如目标检测,图像识别等。IBN-Net首次将BN和IN集成起来,同时提高了模型的学习能力和泛化能力。
此外,IBN-Net设计原则是:
- 在网络的浅层同时使用IN和BN
- 在网络的深层仅仅使用BN
作者做了一个实验,下图展示了随着网络深度的变化,特征差异的变化情况:
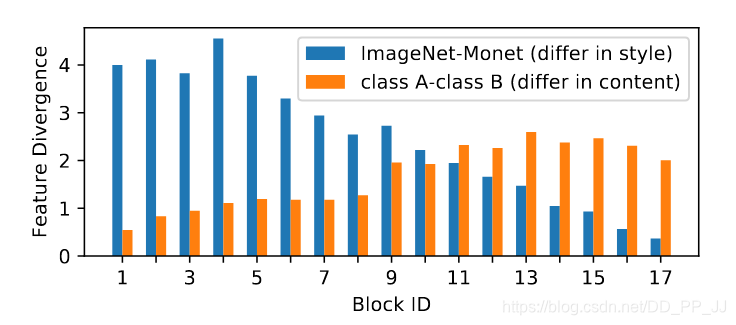
蓝色代表外观差异带来的特征差异,橙色代表图片内容之间的特征差异。可以看出在浅层是由外观差异带来的特征差异,这部分可以使用BN和IN联合起来解决;在深层网络,外观差异带来的特征差异已经非常小了,内容之间的差异是主导地位,所以这部分使用BN来解决。
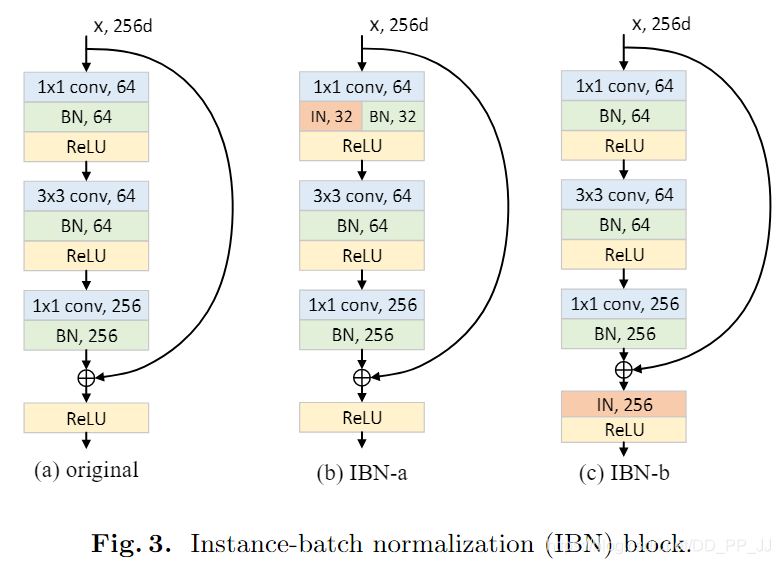
这部分是论文的核心,作者提出了两个结合BN和IN的模块,IBN-a和IBN-b。(a)图其实是ResNet中的一个残差模块,(b)和©图都是在此基础上融入了IN和BN
- 具体哪个算浅层哪个算深层?
ResNet由4组残差块组成,在IBN-Net的改进中,仅仅在Conv2_x, Conv3_x, Conv4_x三个块中加入IN,Conv5_x不进行改动。
- IBN-a的改动理由:
第一,在ResNet论文中说明了恒等映射路径的必要性,所以IN应该添加在残差路径上。
第二,残差网络可以用以下公式来表达:
其中的F(x,\{W_i\})是为了能够得到与恒等映射路径对齐的特征,所以IN被添加在残差模块中第一个卷积以后,而不是最后一个卷积以后,这样可以防止特征出现不对齐的问题。
第三,根据之前提到的设计原则,浅层应当同时使用BN和IN,所以选择将一半通道通过BN计算,另一半通道通过IN进行计算。
- IBN-b的改动理由:
为了更充分地利用IN来提高模型的泛化的能力,对IBN-a进行了改进。作者认为目标的表观信息将保留在残差路径或者恒等映射路径上,所以可以考虑将IN直接添加在加法之后。同时需要说明的是和IBN-a不同,IBN-b使用的范围是(Conv2_x和Conv3_x)
除了上述两种BN和IN结合方法,作者还探索出更多变体,如下图所示:
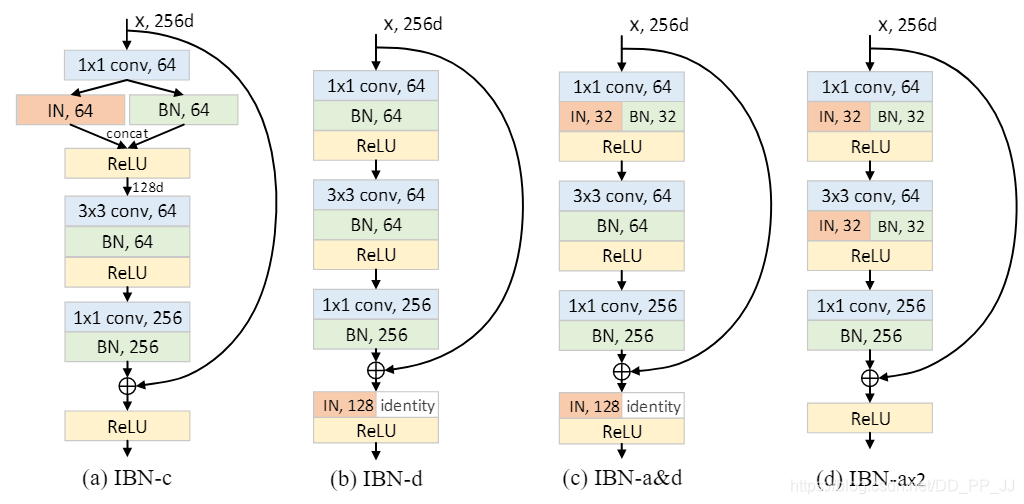
(a)图中,IBN-c的做法是将IN和BN分成两路,然后将得到的特征进行concate。
(b)图中,IBN-d的做法是在IBN-b基础上进行了改动,对其中一半通道的feature map施加IN。
©图中,IBN-a&d的做法很显然结合了IBN-a和IBN-d
(d)图中,IBN-ax2在IBN-a基础上,多增加了一对BN和IN,用于测试添加更多BN和IN是否能够提升模型泛化能力。
IBN-a和IBN-b代码:
这部分代码来自: https://github.com/pprp/reid_for_deepsort
IBN-a:
class IBN(nn.Module):
def __init__(self, planes):
super(IBN, self).__init__()
half1 = int(planes / 2)
self.half = half1
half2 = planes - half1
self.IN = nn.InstanceNorm2d(half1, affine=True)
self.BN = nn.BatchNorm2d(half2)
def forward(self, x):
split = torch.split(x, self.half, 1)
out1 = self.IN(split[0].contiguous())
out2 = self.BN(split[1].contiguous())
out = torch.cat((out1, out2), 1)
return out
IBN-b:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, IN=False):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(
planes,
planes,
kernel_size=3,
stride=stride,
padding=1,
bias=False
)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(
planes, planes * self.expansion, kernel_size=1, bias=False
)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.IN = None
if IN:
self.IN = nn.InstanceNorm2d(planes * 4, affine=True)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
if self.IN is not None:
out = self.IN(out)
out = self.relu(out)
return out
3. 实验¶
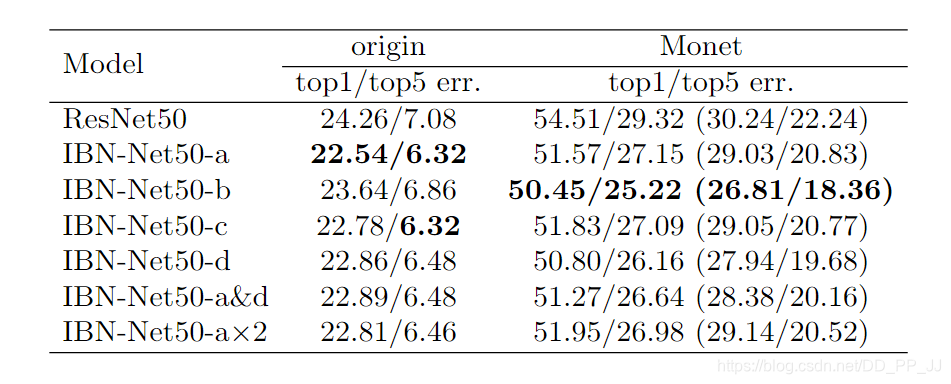
可以看到,IBN-a可以提升在原先域(训练数据)内的泛化能力,比原来ResNet50要高1-2个百分点。IBN-b可以提升在目标域(训练数据中未出现的数据)的泛化能力,可以看到要比ResNet50提高4个百分点。
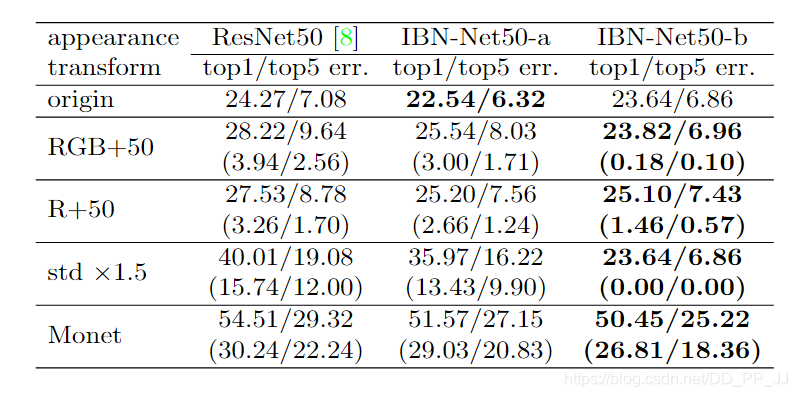
上图是采用了不同的外观转换比如RGB直接+50,R+50等方法,可以发现,依然遵从上一条发现,IBN-a可以提升原有域的泛化能力,IBN-b可以提升目标域的泛化能力,可以看到除了Monet风格化对IBN-b影响稍大,其他几种影响非常之小。

可以看到,IBN-a最好是施加在前三个block中,效果最好。
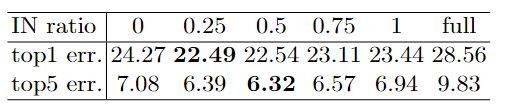
这个比例是IN/BN, 可以看出IN/BN=0.25的时候top1 最好,IN/BN=0.5的时候top5最好,一般默认还是设置为0.5.
以上是分类问题,再来看看分割问题,cityscape数据集和GTA5数据集上的结果如下:
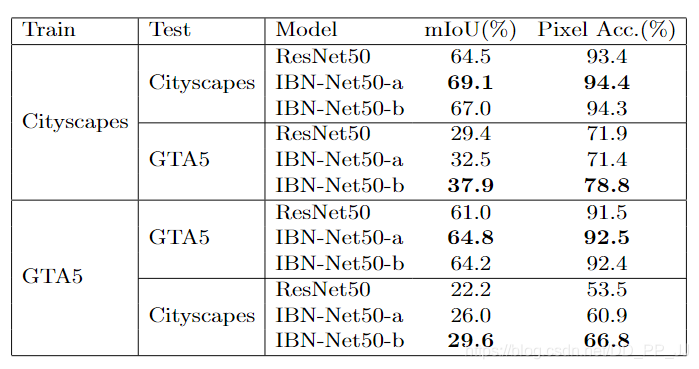
可以看到,训练集和测试集来自同一个数据的时候,IBN-a模型的mIoU是能够比原模型ResNet50高4个百分点。而训练集和测试集不同的时候,IBN-b模型更占优势,说明IBN-b能够在跨域的问题上表现更好。
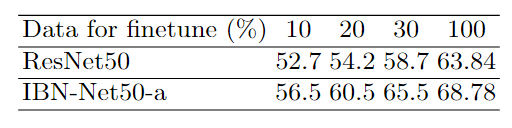
上图的实验还可以证明IBN-a和ResNet50同时在目标域进行fine tuning, IBN-a微调的效果要远远好于ResNet50。
4. 总结¶
IBN-Net中有几个重要结论,在总结部分梳理一下:
-
IBN-Net在浅层同时使用IN和BN,深层网络仅仅使用BN。
-
IBN-Net中有两个出色的模型IBN-a和IBN-b,IBN-a适用于当前域和目标域一致的问题,比如说提升ResNet50的分类能力,可以用IBN-a,并且IBN-a微调以后结果是比原模型结果更好的。
- IBN-b适合使用在当前域和目标域不一致的问题,比如说在行人重识别中,训练数据是在白天收集的,但是想在黄昏的时候使用的时候。这也是为何IBN-Net在行人重识别领域用的非常多的原因。
- cityscape和GTA5这个实验非常有说服力,证明了IBN-Net的泛化能力,效果提升非常明显,在分割问题上对模型带来的提升效果更大。
5. 参考¶
https://arxiv.org/pdf/1512.03385
https://arxiv.org/pdf/1807.09441
https://github.com/XingangPan/IBN-Net
https://github.com/pprp/reid_for_deepsort/tree/master/models
本文总阅读量次