综述¶
为了解决移动端CNN部署,我们开发出一种新型的网络结构GhostNet
我们通过一系列简单的线性变换来生成所谓的Ghost 特征图
这种ghost特征图能揭示隐藏的信息
通过两种架构ghost module 和 ghost bottleneck可以构造出我们的轻量级网络,表现也超越了Mobilenet
介绍¶
近年来有许多减小模型大小方法提出,其中一系列方法是对丢弃不重要的参数丢弃,然而这种思想导致轻量化网络极大受限于预训练的网络模型
另外一种主流方法就是通过改变网络架构来达到减小网络模型的目的
代表性的有mobilenet,引入depthwise和pointwise这两个操作大大减少卷积计算量
shufflenet则引入通道混排,来减少计算量
在训练有素的深度神经网络的特征图中,丰富甚至冗余的信息常常保证了对输入数据的全面理解
我们的方法¶
传统的卷积计算有如下公式
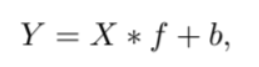
X是输入,f则是卷积核,b则是偏置
卷积计算的计算量是
n*h*w*c*k*k
n是输出特征图的通道数
h,w则是输出的长,宽
c是输入通道数
k是卷积核大小
当通道数很大的时候,卷积带来的计算量往往是很大的
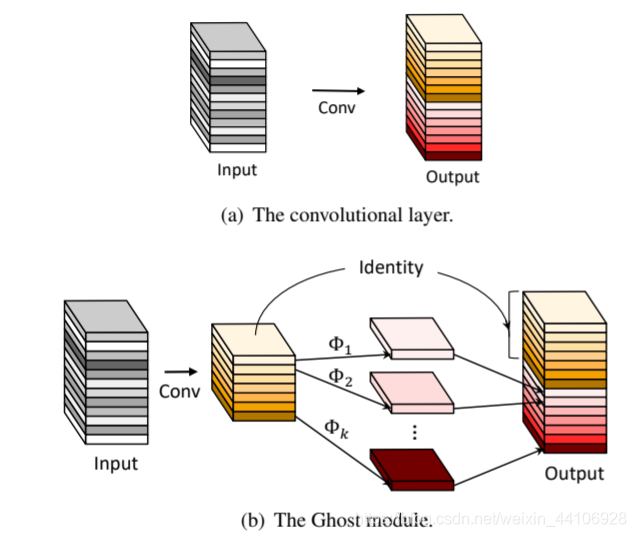
我们认为生成多张特征图不一定需要如此庞大计算量的卷积操作
而是在一部分内在特征图中做一些线性变换
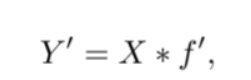
首先我们用预先的卷积操作,生成m张特征图
为了简单起见,我们省略了偏置项bias
然后对后续的特征图做线性变化
下面的公式是压缩率计算比
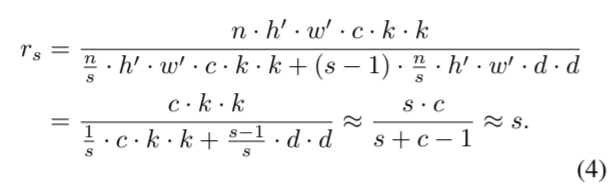
分子是卷积的计算量
分母则是ghost模块的计算量
分母第一项是指做了一个输出通道较小的卷积操作,第二项则是对这个特征图做线性变换
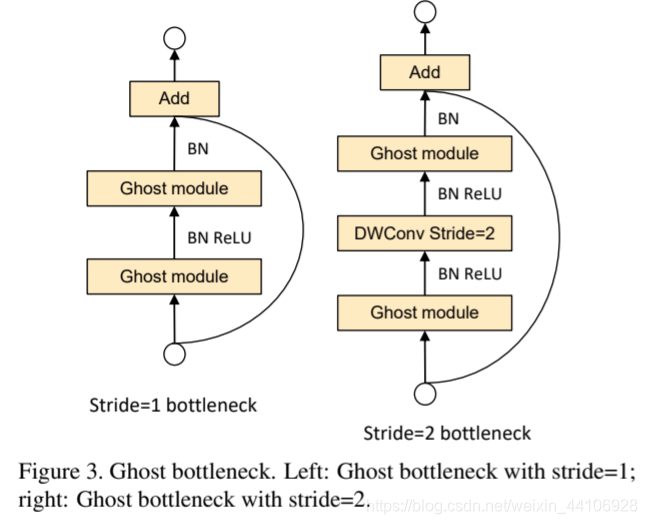
两个主要的Ghostmodule模块
代码分析¶
作者已经将代码开源在Github上
https://github.com/iamhankai/ghostnet
这里我直接复制pytorch版本的代码来解析
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel), )
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
y = torch.clamp(y, 0, 1)
return x * y
这个没啥好说的,就是全局池化接两个全连接层进行缩放,然后将全连接层得到的结果通过clamp函数限制在0,1之间,然后与输入张量相乘
def depthwise_conv(inp, oup, kernel_size=3, stride=1, relu=False):
return nn.Sequential(
nn.Conv2d(inp, oup, kernel_size, stride, kernel_size//2, groups=inp, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
接下来就是文中说的ghost模块了 primary_conv是预先卷积,他的输出通道数为 output_channel / ratio
然后是简单的线性变换cheap_operation 他是对预先卷积模块的每张特征图都做一遍卷积 因此他的groups就是init_channels 他输出通道数是new_channels
这两个模块加在一起生成的通道数就是init方法里面定义的self.oup
前向传播部分就是先对输入张量预先卷积,然后对特征图做变换,最后concat到一起输出
class GhostBottleneck(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):
super(GhostBottleneck, self).__init__()
assert stride in [1, 2]
self.conv = nn.Sequential(
# pw
GhostModule(inp, hidden_dim, kernel_size=1, relu=True),
# dw
depthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False) if stride==2 else nn.Sequential(),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
GhostModule(hidden_dim, oup, kernel_size=1, relu=False),
)
if stride == 1 and inp == oup:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
depthwise_conv(inp, inp, 3, stride, relu=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
return self.conv(x) + self.shortcut(x)
这段代码就是bottleneck的部分,参照上面的图就看的明白了
最后代码是整个GhostNet构成
class GhostNet(nn.Module):
def __init__(self, cfgs, num_classes=1000, width_mult=1.):
super(GhostNet, self).__init__()
# setting of inverted residual blocks
self.cfgs = cfgs
# building first layer
output_channel = _make_divisible(16 * width_mult, 4)
layers = [nn.Sequential(
nn.Conv2d(3, output_channel, 3, 2, 1, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True)
)]
input_channel = output_channel
# building inverted residual blocks
block = GhostBottleneck
for k, exp_size, c, use_se, s in self.cfgs:
output_channel = _make_divisible(c * width_mult, 4)
hidden_channel = _make_divisible(exp_size * width_mult, 4)
layers.append(block(input_channel, hidden_channel, output_channel, k, s, use_se))
input_channel = output_channel
self.features = nn.Sequential(*layers)
# building last several layers
output_channel = _make_divisible(exp_size * width_mult, 4)
self.squeeze = nn.Sequential(
nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1)),
)
input_channel = output_channel
output_channel = 1280
self.classifier = nn.Sequential(
nn.Linear(input_channel, output_channel, bias=False),
nn.BatchNorm1d(output_channel),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(output_channel, num_classes),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.squeeze(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def ghost_net(**kwargs):
"""
Constructs a MobileNetV3-Large model
"""
cfgs = [
# k, t, c, SE, s
[3, 16, 16, 0, 1],
[3, 48, 24, 0, 2],
[3, 72, 24, 0, 1],
[5, 72, 40, 1, 2],
[5, 120, 40, 1, 1],
[3, 240, 80, 0, 2],
[3, 200, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 480, 112, 1, 1],
[3, 672, 112, 1, 1],
[5, 672, 160, 1, 2],
[5, 960, 160, 0, 1],
[5, 960, 160, 1, 1],
[5, 960, 160, 0, 1],
[5, 960, 160, 1, 1]
]
return GhostNet(cfgs, **kwargs)
if __name__=='__main__':
model = ghost_net()
model.eval()
print(model)
input = torch.randn(32,3,224,224)
y = model(input)
print(y)
总结¶
总的来说这篇论文是基于前人对网络压缩的改进 在mobilenet上取depthwise舍去pointwise 取得更好的性能 在论文实验部分中也超越了mobilenetv3,也算是一款sota模型了
本文总阅读量次