提升分类模型acc(一):BatchSize&LARS¶
【GiantPandaCV导读】在使用大的bs训练情况下,会对精度有一定程度的损失,本文探讨了训练的bs大小对精度的影响,同时探究LARS是否可以有效的提升精度。
论文链接:https://arxiv.org/abs/1708.03888
论文代码: https://github.com/NVIDIA/apex/blob/master/apex/parallel/LARC.py
知乎专栏: https://zhuanlan.zhihu.com/p/406882110
一、引言¶
如何提升业务分类模型的性能,一直是个难题,毕竟没有99.999%的性能都会带来一定程度的风险,所以很多时候我们只能通过控制阈值来调整准召以达到想要的效果。本系列主要探究哪些模型trick和数据的方法可以大幅度让你的分类性能更上一层楼,不过要注意一点的是,tirck不一定是适用于不同的数据场景的,但是数据处理方法是普适的。本篇文章主要是对于大的bs下训练分类模型的情况,如果bs比较小的可以忽略,直接看最后的结论就好了(这个系列以后的文章讲述的方法是通用的,无论bs大小都可以用)。
二、实验配置¶
- 模型:ResNet50
- 数据:ImageNet1k
- 环境:8xV100
三、BatchSize对精度的影响¶
所有的实验的超参都是统一的,warmup 5个epoch,训练90个epoch,StepLR进行衰减,学习率的设置和bs线性相关,公式为lr = \frac{BatchSize}{256} * baselr,优化器使用带有0.9的动量的SGD,baselr为0.1(如果采用Adam或者AdamW优化器的话,公式需要调整为lr=\frac{BatchSize}{512} * baselr),训练的数据增强只有RandomCropResize,RandomFlip,验证的数据增强为Resize和CenterCrop。
训练情况如下:
-
lr调整曲线如下:
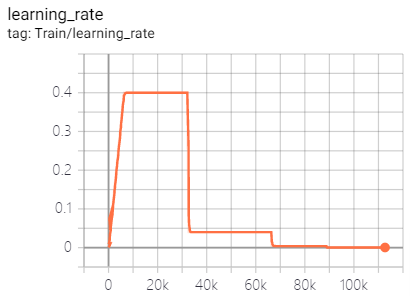
-
训练曲线如下:
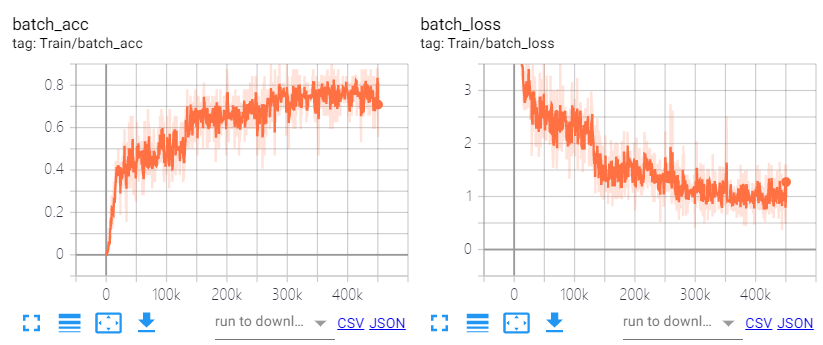
-
验证曲线如下:
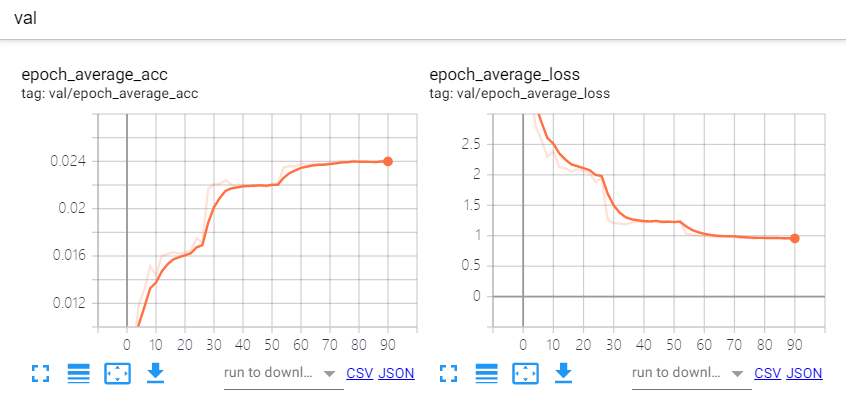
我这里设计了4组对照实验,256, 1024, 2048和4096的batchsize,开了FP16也只能跑到了4096了。采用的是分布式训练,所以单张卡的bs就是bs = total_bs / ngpus_per_node。这里我没有使用跨卡bn,对于bs 64单卡来说理论上已经很大了,bn的作用是约束数据分布,64的bs已经可以表达一个分布的subset了,再大的bs还是同分布的,意义不大,跨卡bn的速度也更慢,所以大的bs基本可以忽略这个问题。但是对于检测的任务,跨卡bn还是有价值的,毕竟输入的分辨率大,单卡的bs比较小,一般4,8,16,这时候统计更大的bn会对模型收敛更好。
实验结果如下:
| 模型 | epoch | LR | batchsize | dataaug | acc@top1 |
|---|---|---|---|---|---|
| ResNet50 | 90 | 0.1 | 256 | randomcropresize,randomflip | 76.422% |
| ResNet50 | 90 | 0.4 | 1024 | randomcropresize,randomflip | 76.228% |
| ResNet50 | 90 | 0.8 | 2048 | randomcropresize,randomflip | 76.132% |
| ResNet50 | 90 | 1.6 | 4096 | randomcropresize,randomflip | 75.75% |
很明显可以看出来,当bs增加到4k的时候,acc下降了将近0.8%个点,1k的时候,下降了0.2%个点,所以,通常我们用大的bs训练的时候,是没办法达到最优的精度的。个人建议,使用1k的bs和0.4的学习率最优。
四、LARS(Layer-wise Adaptive Rate Scaling)¶
1. 理论分析¶
由于bs的增加,在同样的epoch的情况下,会使网络的weights更新迭代的次数变少,所以需要对LR随着bs的增加而线性增加,但是这样会导致上面我们看到的问题,过大的lr会导致最终的收敛不稳定,精度有所下降。
LARS的出发点则是各个层的更新参数使用的学习率应该根据自己的情况有所调整,而不是所有层使用相同的学习率,也就是每层有自己的local lr,所以有:
这里,l表示的是第几层,\eta表示的是超参数,这个超参数远小于1,表示每层会改变参数的confidence,局部学习率可以很方便的替换每层的全局学习率,参数的更新大小为:
与SGD联合使用的算法如下:

LARS代码如下:
class LARC(object):
def __init__(self, optimizer, trust_coefficient=0.02, clip=True, eps=1e-8):
self.optim = optimizer
self.trust_coefficient = trust_coefficient
self.eps = eps
self.clip = clip
def step(self):
with torch.no_grad():
weight_decays = []
for group in self.optim.param_groups:
# absorb weight decay control from optimizer
weight_decay = group['weight_decay'] if 'weight_decay' in group else 0
weight_decays.append(weight_decay)
group['weight_decay'] = 0
for p in group['params']:
if p.grad is None:
continue
param_norm = torch.norm(p.data)
grad_norm = torch.norm(p.grad.data)
if param_norm != 0 and grad_norm != 0:
# calculate adaptive lr + weight decay
adaptive_lr = self.trust_coefficient * (param_norm) / (
grad_norm + param_norm * weight_decay + self.eps)
# clip learning rate for LARC
if self.clip:
# calculation of adaptive_lr so that when multiplied by lr it equals `min(adaptive_lr, lr)`
adaptive_lr = min(adaptive_lr / group['lr'], 1)
p.grad.data += weight_decay * p.data
p.grad.data *= adaptive_lr
self.optim.step()
# return weight decay control to optimizer
for i, group in enumerate(self.optim.param_groups):
group['weight_decay'] = weight_decays[i]
2. 实验结论¶
| 模型 | epoch | LR | batchsize | dataaug | acc@top1 | trust_confidence |
|---|---|---|---|---|---|---|
| ResNet50 | 90 | 0.4 | 1024 | randomcropresize,randomflip | 75.146% | 1e-3 |
| ResNet50 | 90 | 0.8 | 2048 | randomcropresize,randomflip | 73.946% | 1e-3 |
| ResNet50 | 90 | 1.6 | 4096 | randomcropresize,randomflip | 72.396% | 1e-3 |
| ResNet50 | 90 | 0.4 | 1024 | randomcropresize,randomflip | 76.234% | 2e-2 |
| ResNet50 | 90 | 0.8 | 2048 | randomcropresize,randomflip | 75.898% | 2e-2 |
| ResNet50 | 90 | 1.6 | 4096 | randomcropresize,randomflip | 75.842% | 2e-2 |
可以很明显发现,使用了LARS,设置turst_confidence为1e-3的情况下,有着明显的掉点,设置为2e-2的时候,在1k和4k的情况下,有着明显的提升,但是2k的情况下有所下降。
LARS一定程度上可以提升精度,但是强依赖超参,还是需要细致的调参训练。
四、结论¶
- 8卡进行分布式训练,使用1k的bs可以很好的平衡acc&speed。
- LARS一定程度上可以提升精度,但是需要调参,做业务可以不用考虑,刷点的话要好好训练。
五、结束语¶
本文是提升分类模型acc系列的第一篇,后续会讲解一些通用的trick和数据处理的方法,敬请关注。
本文总阅读量次